Amazon Web Services ブログ
あなたのモデルは最適ですか? Amazon SageMaker Canvas の高度なメトリクス deep dive
ビジネスアナリストであれば、顧客の行動を理解することは、おそらく最も重要なことの1つです。顧客の購入決定の背後にある理由とメカニズムを理解することで、収益の拡大を促進できます。一方で、顧客の喪失 (一般に顧客解約と呼ばれる) は常にリスクを伴います。顧客が離脱する理由についてのインサイトを得ることも、利益と収益を維持するためにも同様に重要です。
機械学習 (ML) は貴重なインサイトを提供できますが、Amazon SageMaker Canvas が導入されるまでは、顧客離れ予測モデルを構築するには ML の専門家が必要でした。
SageMaker Canvas はローコード/ノーコードのマネージドサービスで、コードを 1 行も記述しなくても多くのビジネス上の問題を解決できる ML モデルを作成できます。また、まるでデータサイエンティストであるかのように、高度な指標を使用してモデルを評価できます。
前提条件
この記事で説明されているタスクのすべてまたは一部を実装する場合は、SageMaker Canvas にアクセスできる AWS アカウントが必要です。SageMaker Canvas、顧客離れ予測モデル、およびデータセットに関する基本事項については、「Amazon SageMaker Canvas を使用したコーディング不要の機械学習による顧客離れの予測」を参照してください。
モデル性能評価の概要
一般的なガイドラインとして、モデルのパフォーマンスを評価する必要がある場合、新しいデータを見たときにモデルが結果をどれだけうまく予測できるかを測定することです。この予測は推論と呼ばれます。まず、既存のデータを使用してモデルをトレーニングし、次に、まだ見ていないデータに基づいて結果を予測するようにモデルを呼び出します。モデルがこの結果をどの程度正確に予測するかが、モデルのパフォーマンスを理解するうえで重要です。
モデルが新しいデータを見ていないとしたら、予測が良いか悪いかをどうやって知ることができるでしょうか?つまり、結果が既に分かっている過去のデータを実際に使用して、その値をモデルの予測値と比較するというものです。これは、過去のトレーニングデータの一部を取っておき、モデルが予測した値と比較できるようにすることで可能になります。
顧客離れ(カテゴリ分類の問題)の例では、多くの属性(各レコードに 1 つ)を持つ顧客を説明する履歴データセットから始めます。Churn と呼ばれる属性の 1 つは True でも False でもかまいません。これは、顧客がサービスを辞めたかどうかを表すものです。モデルの精度を評価するために、このデータセットを分割し、一方の部分 (トレーニングデータセット) を使用してモデルをトレーニングし、もう一方の部分 (テストデータセット) の結果を予測するようにモデルを呼び出します (顧客を離脱する顧客かそうでないかに分類)。次に、モデルの予測をテストデータセットに含まれる正解データと比較します。
高度なメトリクスの解釈
このセクションでは、モデルのパフォーマンスを理解するのに役立つ SageMaker Canvas の高度なメトリクスについて説明します。
混同行列
SageMaker Canvas は混同行列を使用して、モデルが予測を正しく生成することを視覚化するのに役立ちます。混同行列では、予測値を実際の過去 (既知の) 値と比較するように結果が整理されます。次の例は、 positive と negative を予測する 2 つのカテゴリの予測モデルで混同行列がどのように機能するかを説明しています。
- True positive — 正解ラベルがpositiveの場合、モデルはpositiveを正しく予測しました
- True negative — 正解ラベルがnegative場合、モデルはnegativeを正しく予測しました。
- False positive — 正解ラベルがnegativeの場合、モデルは誤ってpositiveと予測しました。
- False negative — 正解ラベルがpositiveの場合、モデルは誤ってnegativeと予測しました。
次の画像は、2 つのカテゴリの混同行列の例です。この顧客離れ予測モデルでは、実際の値はテストデータセットから得られ、予測値はモデルに問い合わせて得られます。
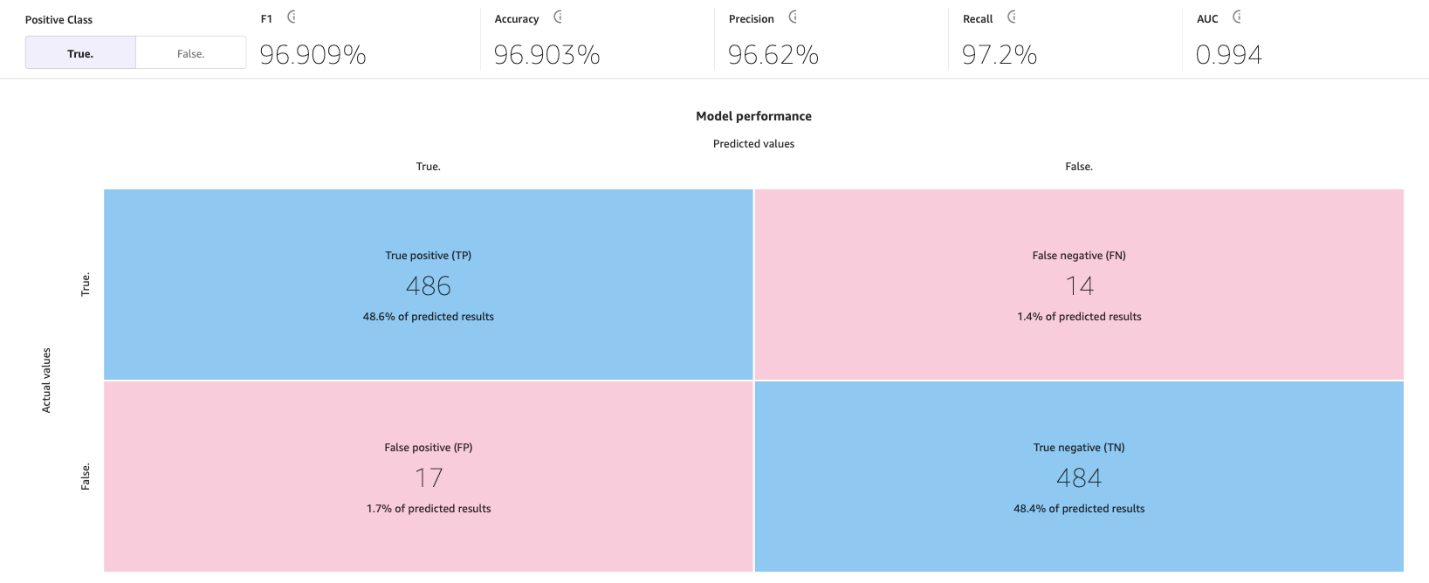
正解率
正解率は、テストデータセットのすべての行またはサンプルのうち、正しい予測のパーセンテージです。True と予測された真のサンプルと、False と正しく予測された偽サンプルを、データセット内のサンプルの総数で割ったものです。
モデルがどのくらいの割合で正しく予測したかわかるため、理解しておくべき最も重要な指標の1つですが、場合によっては誤解を招く可能性があります。例えば:
- クラスの不均衡 — データセット内のクラスが均等に分布していない(あるクラスのサンプル数が不均衡で、他のクラスのサンプル数が非常に少ない)場合、正解率は誤解を招く可能性があります。このような場合、データごとに過半数のクラスを予測するだけのモデルでも、高い正解率となってしまいます。
- コスト考慮型の分類 — アプリケーションによっては、クラスごとに誤分類のコストが異なる場合があります。たとえば、ある薬物が病状を悪化させる可能性があるかどうかを予測する場合、偽陰性(たとえば、その薬物が実際にはその薬物を使用すると悪化するにもかかわらず、悪化しない可能性を予測)は、偽陽性(たとえば、実際には悪化しないのにその薬を使用することで悪化する可能性があると予測すること)よりもコストがかかる可能性があります。
精度(Precision)、再現率(recall)、F1スコア(F1 score)
精度は、予測されるすべての陽性(TP+FP)に対する真陽性(TP)の割合です。陽性の予測のうち、実際に正しかったものの割合を測定します。
再現率は、実際の陽性(TP + FN)すべてに対する真陽性(TP)の割合です。モデルによって陽性と正しく予測された陽性例の割合を測定します。
F1 スコアは、精度と再現率を組み合わせたもので、両者のトレードオフのバランスを取った単一のスコアになります。精度と再現率の調和平均として定義されています。
F1 score = 2 * (精度 * 再現率) / (精度 + 再現率)
F1のスコアの範囲は0〜1で、スコアが高いほどパフォーマンスが優れていることを示します。F1 スコアが 1 の場合は、モデルが完全な精度と完全な再現率の両方を達成したことを示し、スコアが 0 の場合は、モデルの予測が完全に誤っていることを示します。
F1スコアは、モデルのパフォーマンスをバランスよく評価します。精度と再現率を考慮して、陽性事例を正しく分類し、偽陽性と偽陰性を回避するモデルの能力を反映した、より有益な評価指標となります。
たとえば、医療診断、不正検知、感情分析では、F1が特に重要です。医療診断では、特定の疾患または状態の存在を正確に特定することが重要であり、偽陰性または偽陽性は重大な結果をもたらす可能性があります。F1スコアでは、精度(陽性症例を正しく特定する能力)と再現率(すべての陽性症例を発見する能力)の両方が考慮され、疾患の検出におけるモデルの性能をバランスよく評価できます。同様に、実際の不正事例の数が非不正事例と比較して比較的少ない不正検出(不均衡なクラス)では、真陰性の事例の数が多いため、精度だけでは誤解を招く可能性があります。F1スコアは、精度と再現率の両方を考慮して、モデルが不正なケースと非不正的なケースの両方を検出する能力を包括的に測定します。また、感情分析では、データセットのバランスが取れていないと、ポジティブな感情クラスのインスタンスを分類する際のモデルのパフォーマンスが精度に正確に反映されない可能性があります。
AUC (area under the curve)
AUC メトリクスは、すべての分類閾値においてポジティブクラスとネガティブクラスを区別する二項分類モデルの能力を評価します。閾値とは、モデルが 2 つのクラス間の判断に使用する値で、サンプルがクラスに含まれる確率をバイナリ判定に変換します。AUC を計算するには、さまざまな閾値設定にわたって真陽性率 (TPR) と偽陽性率 (FPR) をプロットします。TPR は実際のすべての陽性に対する真陽性の割合を測定し、FPR は実際の陰性すべてのうちで偽陽性の割合を測定します。結果として得られる曲線は、受信者動作特性 (ROC) 曲線と呼ばれ、さまざまな閾値設定での TPR と FPR を視覚的に表しています。AUC 値は 0 ~ 1 の範囲で、ROC 曲線の下の領域を表します。AUC 値が高いほどパフォーマンスが良く、分類モデルが完璧であれば AUC は 1 になります。
次のグラフは、TPR を Y 軸、FPR を X 軸とした ROC 曲線を示しています。曲線がプロットの左上隅に近づくほど、モデルはデータをカテゴリに分類しやすくなります。
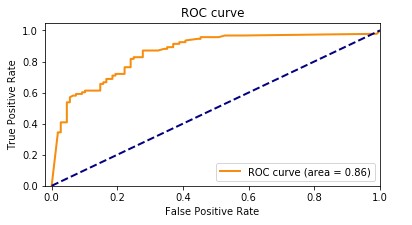
わかりやすくするために、例を見てみましょう。不正検出モデルについて考えてみましょう。通常、これらのモデルは不均衡なデータセットからトレーニングされます。これは、通常、データセット内のほとんどすべてのトランザクションが不正ではなく、不正とラベル付けされたトランザクションはごくわずかであるためです。この場合、精度だけではモデルのパフォーマンスを十分に捉えられない可能性があります。不正ではないケースの多さに大きく影響され、誤解を招くような高い精度スコアにつながるからです。
この場合、AUCは、モデルが不正な取引と不正でない取引を区別する能力を包括的に評価できるため、モデルのパフォーマンスを評価するためのより良い指標となるでしょう。さまざまな分類閾値における真陽性率と偽陽性率のトレードオフを考慮に入れて、より微妙な評価ができます。
F1スコアと同様に、AUCはデータセットのバランスが崩れている場合に特に役立ちます。TPR と FPR のトレードオフを測定し、分布に関係なくモデルが 2 つのクラスをどれだけうまく区別できるかを示します。つまり、一方のクラスが他方のクラスよりも大幅に小さくても、ROC 曲線では両方のクラスを同等に考慮することで、モデルの性能をバランスよく評価できるということです。
その他の主要トピック
ML モデルのパフォーマンスを評価および改善するために利用できる重要なツールは、高度なメトリクスだけではありません。データ準備、特徴量エンジニアリング、特徴量重要度分析は、モデル構築に不可欠な手法です。これらのアクティビティは、生データから有意義なインサイトを抽出し、モデルのパフォーマンスを向上させる上で重要な役割を果たし、より堅牢で洞察に富んだ結果につながります。
データ準備と特徴量エンジニアリング
特徴量エンジニアリングは、生データから新しい変数 (機能) を選択、変換、作成するプロセスであり、ML モデルのパフォーマンスを向上させる上で重要な役割を果たします。入手可能なデータから最も関連性の高い変数や特徴量を選択するには、モデルの予測に寄与しない無関係な特徴量や冗長な特徴量を削除する必要があります。データの特徴量を適切な形式に変換するには、スケーリング、正規化、欠損値の処理が含まれます。最後に、既存のデータから新しい機能を作成するには、数学的な変換、さまざまな機能の組み合わせや相互作用、またはドメイン固有の知識に基づく新しい機能の作成を行います。
特徴量重要度分析
SageMaker Canvas は、データセット内の各列がモデルに与える影響を説明する特徴量重要度分析を生成します。予測を生成すると、列の影響を確認して、各予測に最も大きな影響を与える列を特定できます。これにより、どの特徴量を最終モデルに含めるべきか、どの特徴量を破棄すべきかについてのインサイトが得られます。列への影響度は、ある列が他の列と比較して予測を行う際にどの程度重要かを示すパーセンテージスコアです。列への影響が 25% の場合、Canvasは予測結果への影響を、その列が 25%、その他の列が 75% と重み付けします。
モデルの精度を向上させるためのアプローチ
モデルの精度を向上させる方法は複数ありますが、データサイエンティストと機械学習担当者は通常、前述のツールとメトリクスを使用して、このセクションで説明した2つのアプローチのうちのどちらか1つを使用します。
モデル中心のアプローチ
このアプローチでは、データは常に同じままで、望ましい結果が得られるようにモデルを繰り返し改善するために使用されます。このアプローチで使用されるツールには以下が含まれます。
- 関連する複数の機械学習アルゴリズムを試してみる。
- アルゴリズムとハイパーパラメーターのチューニングと最適化。
- さまざまなモデルアンサンブル法。
- 事前トレーニング済みモデルの使用 (SageMaker には ML 担当者に役立つさまざまな組み込みモデルや事前トレーニング済みモデルが用意されています)。
- AutoML は SageMaker Canvas が舞台裏で (Amazon SageMaker Autopilot を使用して) 行っていることであり、上記のすべてを網羅しています。
データ中心のアプローチ
このアプローチでは、データ準備、データ品質の向上、およびパフォーマンスの向上を目的としたデータの反復修正に重点が置かれています。
- モデルのトレーニングに使用したデータセットの統計情報の調査 (探索的データ分析 (EDA) とも呼ばれます)。
- データ品質の向上 (データクリーニング、欠損値の補完、外れ値の検出と管理)。
- 特徴量の選択。
- 特徴量エンジニアリング。
- データ拡張。
Canvasにおけるモデルパフォーマンスの向上
まず、データ中心のアプローチから始めます。モデルプレビュー機能を使用して最初の EDA を実行します。これにより、データ拡張、新しいベースラインの生成、そして最終的に標準ビルド機能を使用したモデル中心のアプローチによる最適なモデルの作成に使用できるベースラインが得られます。
この記事では通信携帯電話会社の合成データセットを使用します。このサンプルデータセットには 5,000 件のレコードが含まれており、各レコードには 21 の属性を使用して顧客プロファイルを記述しています。詳細については、「Amazon SageMaker Canvas を使用したコーディング不要の機械学習による顧客離れの予測」を参照してください。
データ中心のアプローチによるモデルプレビュー
最初のステップとして、データセットを開き、予測する列である Churn? を選択します。そして、Preview model を選択してプレビューモデルを生成します。
Preview model ペインには、プレビューモデルの準備が整うまでの進捗状況が表示されます。
モデルの準備が整うと、SageMaker Canvas は特徴量重要度分析を生成します。
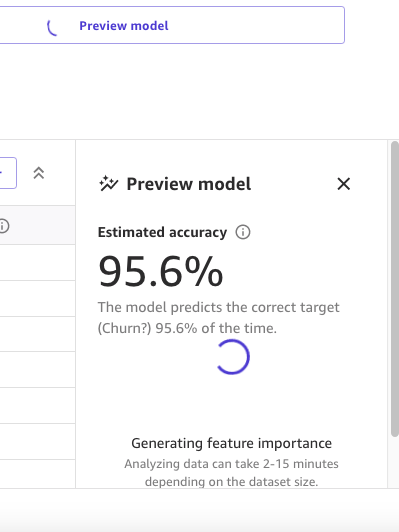
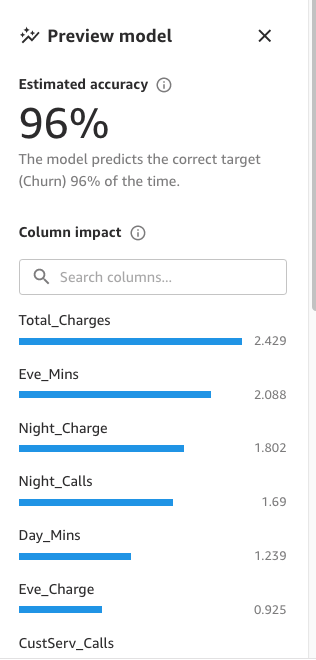
最後に、モデルプレビューの作成が完了すると、Preview model ペインにはモデルへの影響を含む列のリストが表示されます。これらの情報は、その特徴量が予測にどの程度関連しているかを理解するのに役立ちます。Column impact は、ある列が他の列と比較して予測を行う際にどの程度重視されているかを示すパーセンテージスコアです。次の例では、「Night Calls」列について、SageMaker Canvas はその列について 4.04%、その他の列では 95.9% と重み付けしています。値が大きいほど、影響も大きくなります。
ご覧のとおり、プレビューモデルの精度は 95.6% です。データ中心のアプローチを使用してモデルのパフォーマンスを改善してみましょう。データ準備を行い、特徴量エンジニアリングの手法を使用してパフォーマンスを向上させます。
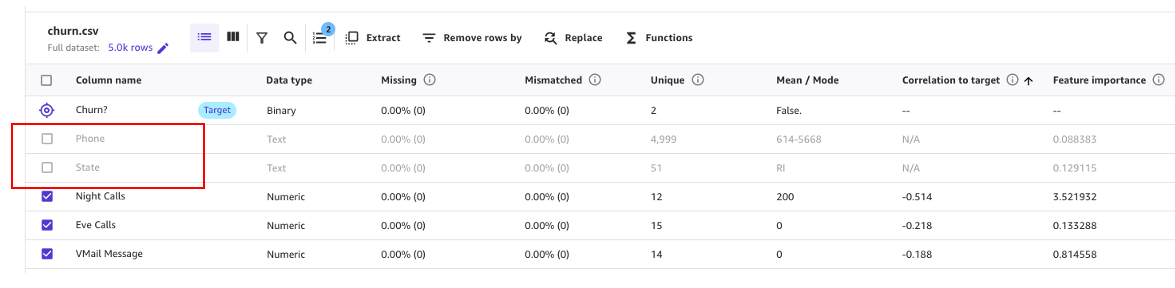
次のスクリーンショットに示すように、「Phone」列と「State」列が予測に与える影響は他の列に比べてはるかに小さいことがわかります。そのため、この情報を次のフェーズであるデータ準備のインプットとして使用します。

SageMaker Canvas には ML データ変換が用意されており、これを使用してデータをクレンジング、変換、モデル構築の準備を行うことができます。これらの変換はコードを書くことなくデータセットに使用でき、モデルレシピに追加されます。モデルレシピとは、モデル構築前にデータに対して実行されたデータ準備の記録です。
使用するデータ変換は、モデルを構築するときに入力データを変更するだけで、データセットや元のデータソースは変更しないことに注意してください。
SageMaker Canvas には、構築用のデータを準備するための以下の変換方法が用意されています。
- 日時抽出
- 列削除
- 行フィルター
- 関数と演算子
- 行の管理
- 列名変更
- 行削除
- 値の置換
- 時系列データの再サンプリング
まず、予測にほとんど影響がないことがわかった列を削除することから始めましょう。
例えば、このデータセットでは、電話番号はアカウント番号と同等です。他のアカウントが解約される可能性を予測する上では役に立たず、有害ですらあります。同様に、顧客の状態はモデルにあまり影響しません。Phone 列と State 列を削除して、Column name の下にあるチェックボックスの選択を解除しましょう。
次に、追加のデータ変換と特徴量エンジニアリングを実行してみましょう。
例えば、以前の分析では、顧客への請求金額が解約に直接影響することがわかりました。そこで、日中、夜、深夜、の国際電話の「料金」、「通話時間」、「通話回数」を組み合わせて、お客様への合計請求額を計算する新しい列を作成してみましょう。そのためには、SageMaker Canvas のカスタム数式を使用します。
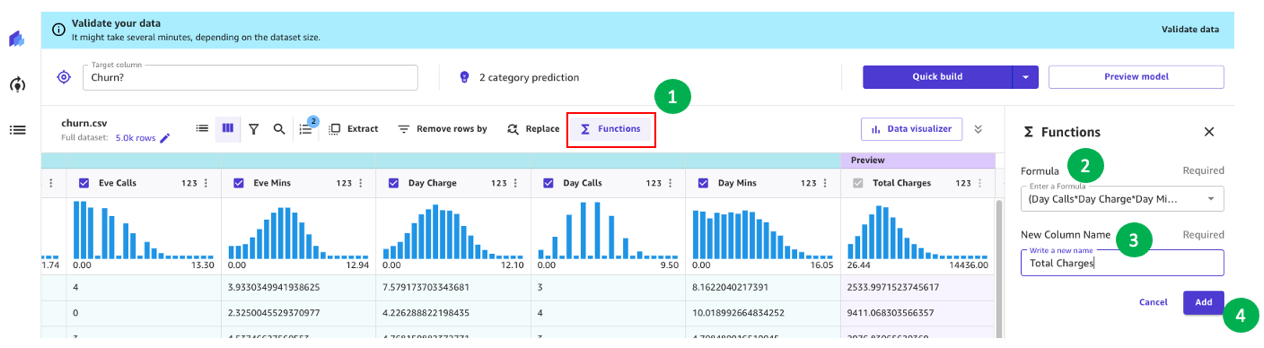
まず Functions を選択し、次に数式のテキストボックスに次のテキストを追加します。
(Day Calls*Day Charge*Day Mins)+(Eve Calls*Eve Charge*Eve Mins)+(Night Calls*Night Charge*Night Mins)+(Intl Calls*Intl Charge*Intl Mins)
新しい列に「合計料金」など適切な名前 を付け、プレビューが生成されたら Add を選択します。これで、モデルレシピは次のスクリーンショットのようになるはずです。
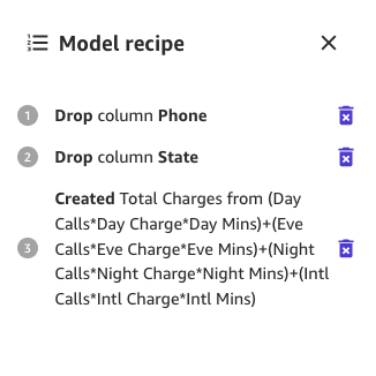
このデータ準備が完了したら、新しいプレビューモデルをトレーニングして、モデルが改善されたかどうかを確認します。もう一度 Preview model を選択すると、右下のペインに進行状況が表示されます。

トレーニングが終了すると、予測精度の再計算が行われ、新しい Column impact も作成されます。
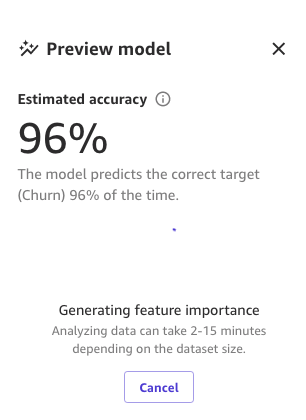
最後に、プロセス全体が完了すると、前に見たのと同じペインが、新しいプレビューモデルの精度で表示されます。モデルの精度が 0.4% (95.6% から 96% に) 向上したことがわかります。
MLはモデルのトレーニングプロセスにはある程度の確率性を導入しており、ビルドごとに異なる結果につながる可能性があるため、本記事の画像の数値は実際の数値とは異なる場合があります。
モデル中心のアプローチによるモデル作成
Canvasには、モデルを作成するための2つのオプションがあります。
- Standard build – 速度を犠牲にして精度を高める最適化されたプロセスから最適なモデルを構築します。Auto-ML を使用して、モデルの選択、ML のユースケースに関連するさまざまなアルゴリズムの試行、ハイパーパラメータの調整、モデルの説明可能性レポートの作成など、ML のさまざまなタスクを自動化します。
- Quick build – Standard build に比べてわずかな時間で単純なモデルを構築できますが、精度はスピードと引き換えられます。Quick Build は、データの変更がモデルの精度に与える影響をより迅速に把握するために反復試行を行う場合に役立ちます。
引き続き Standard build アプローチを使用してみましょう。
Standard build
前述したように、Standard build は、精度を最大化するために最適化されたプロセスから最適なモデルを構築します。
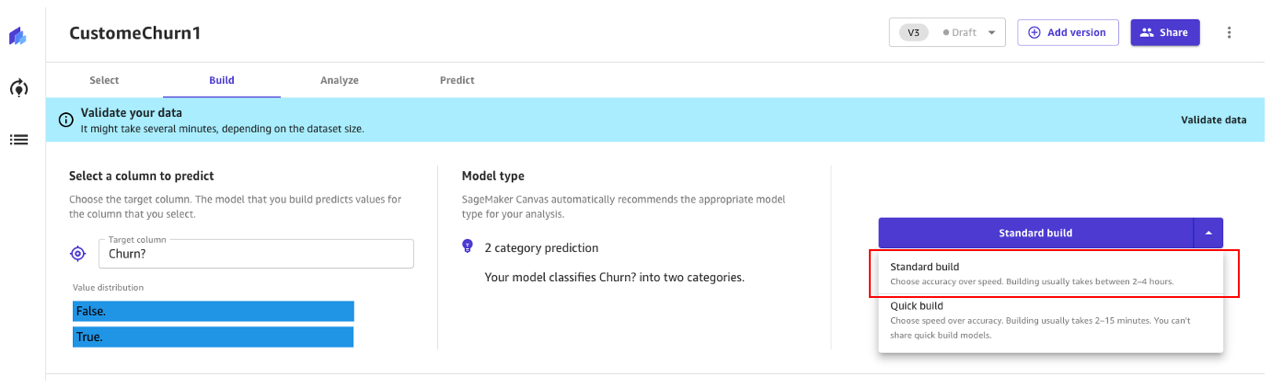
顧客離れ予測モデルのビルドプロセスには約45分かかります。この間、Canvasは何百もの候補パイプラインをテストし、最適なモデルを選択します。次のスクリーンショットでは、予想されるビルド時間と進行状況を確認できます。
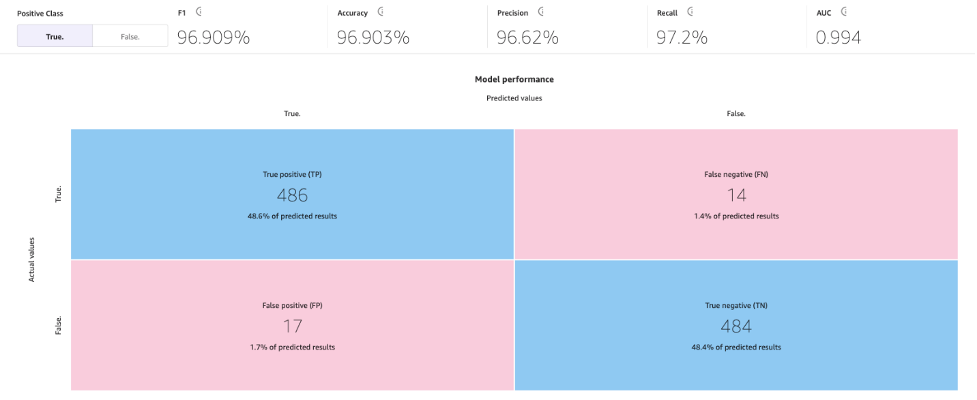
標準のビルドプロセスでは、ML モデルによってモデルの精度が 96.903% に向上しました。これは大幅な改善です。

advanced metrics を見る
Analyze タブを使用してモデルを調べてみましょう。Scoring タブで Advanced metrics を選択します。

このページでは、F1スコア、正解率、精度、再現率、AUCなどの高度なメトリクスと混同行列を組み合わせて表示します。
予測の生成
メトリクスが適切に表示されたので、 Predict タブでバッチ予測または単一 (リアルタイム) 予測のいずれかでインタラクティブな予測を実行できます。
次の 2 つの選択肢があります。
- このモデルを使用して、バッチ予測または単一予測を実行します。
- モデルを Amazon SageMaker Studio に送信して、データサイエンティストと共有します。
後片付け
記事の作業を実施後、セッション料金が発生しないようにするには、SageMaker Canvas からログアウトしてください。

まとめ
SageMaker Canvas には、コーディングや専門的なデータサイエンスや ML の専門知識を必要とせずにモデルの構築と精度を評価してパフォーマンスを向上させることができる強力なツールが用意されています。顧客離れ予測モデルを作成した例で見てきたように、これらのツールをデータ中心のアプローチと高度なメトリクスを使用するモデル中心のアプローチの両方と組み合わせることで、ビジネスアナリストは予測モデルを作成して評価できます。また、ビジュアルインターフェイスを使用すると、正確な ML 予測を自分で生成できます。参考文献に目を通し、これらのアプローチが他の種類のML問題にも適用可能であることを確認してみてください。
参考文献
- Predict customer churn with no-code machine learning using Amazon SageMaker Canvas
- Build, Share, Deploy: how business analysts and data scientists achieve faster time-to-market using no-code ML and Amazon SageMaker Canvas
- Customizing and reusing models generated by Amazon SageMaker Autopilot
- Amazon SageMaker Canvas Immersion Day Workshop
- Manage AutoML workflows with AWS Step Functions and AutoGluon on Amazon SageMaker
著者について
 Marcos は、米国フロリダ州を拠点とする AWS シニア機械学習ソリューションアーキテクトです。その職務では、米国のスタートアップ企業のクラウド戦略を導き、支援し、リスクの高い問題に対処し、機械学習ワークロードを最適化する方法に関するガイダンスを提供しています。クラウドソリューション開発、機械学習、ソフトウェア開発、データセンターインフラストラクチャなど、テクノロジーに関する 25 年以上の経験があります。
Marcos は、米国フロリダ州を拠点とする AWS シニア機械学習ソリューションアーキテクトです。その職務では、米国のスタートアップ企業のクラウド戦略を導き、支援し、リスクの高い問題に対処し、機械学習ワークロードを最適化する方法に関するガイダンスを提供しています。クラウドソリューション開発、機械学習、ソフトウェア開発、データセンターインフラストラクチャなど、テクノロジーに関する 25 年以上の経験があります。
 Indrajit は AWS エンタープライズシニアソリューションアーキテクトです。彼の役職では、クラウドの導入を通じて顧客がビジネス上の成果を達成できるよう支援しています。マイクロサービス、サーバーレス、API、イベント駆動型パターンに基づいた最新のアプリケーションアーキテクチャを設計しています。DataOps と MLOps のプラクティスとソリューションを採用することで、顧客と協力してデータ分析と機械学習の目標を実現できるよう努めています。Indrajit は、サミットや ASEAN ワークショップなどの AWS の公開イベントで定期的に講演を行い、いくつかの AWS ブログ記事を公開しているほか、AWS でのデータや機械学習に焦点を当てた顧客向けの技術ワークショップも企画しています。
Indrajit は AWS エンタープライズシニアソリューションアーキテクトです。彼の役職では、クラウドの導入を通じて顧客がビジネス上の成果を達成できるよう支援しています。マイクロサービス、サーバーレス、API、イベント駆動型パターンに基づいた最新のアプリケーションアーキテクチャを設計しています。DataOps と MLOps のプラクティスとソリューションを採用することで、顧客と協力してデータ分析と機械学習の目標を実現できるよう努めています。Indrajit は、サミットや ASEAN ワークショップなどの AWS の公開イベントで定期的に講演を行い、いくつかの AWS ブログ記事を公開しているほか、AWS でのデータや機械学習に焦点を当てた顧客向けの技術ワークショップも企画しています。
翻訳は Solution Architect の Masanari Ikuta が担当しました。原文はこちらです。