
はじめに
こんにちは。
rs_chankoです。
本格的に寒くなってきましたね。
スノーボードが楽しみな季節です。
全然関係ないので本題に入ります。
エンジニアたるもの、情報収集にSNSって欠かせないですよね。
私は気軽に使えるし、ユーザーも多いためTwitterをよく利用しています。
その昔、シュ○○。○○○○ーだとか、ザ○○○ドとか、
UserStreamsで常に新しいtweetが流れてくるクライアント、流行りましたよね。(流行りましたよね?)
私はそんなクライアントを使っていわゆる「ツイ廃」という人種でした。
ただ、APIの仕様変更だとかなんだとかでそのようなクライアントからも離れ、今は公式に落ち着いています。
当時は「API」ってなんぞや、と思いつつも、調べることも特にありませんでした。(高校生の頃の自分の欲のなさよ…)
最近、業務でAPIチックな実装に触れた時に突然このことを思い出したんですよね。
そして思いました。
「公式に慣れたとはいえ、自分の理想のクライアント作れたら、面白くね??」
ということで、今回はクライアント作成まではいきませんが、
ひとまずAPIで何かしてみようと言うことで初級編をやったので記事にしてみます。
使った物
準備
TwitterでAPIを利用するには、まず「利用申請」が必要になります。
この辺は結構いろんなサイトがあるので、参考にしました。
参考にしたサイトはこちら
これが完了してメールが届くと、ようやくAPIを使ったいろんなことができます。
ひとまず、このあと必要になる下記4つを取得します。
探すの結構苦労したんですが、実はまとまっていました。
下の画像の順に探っていくと全部取得できました。
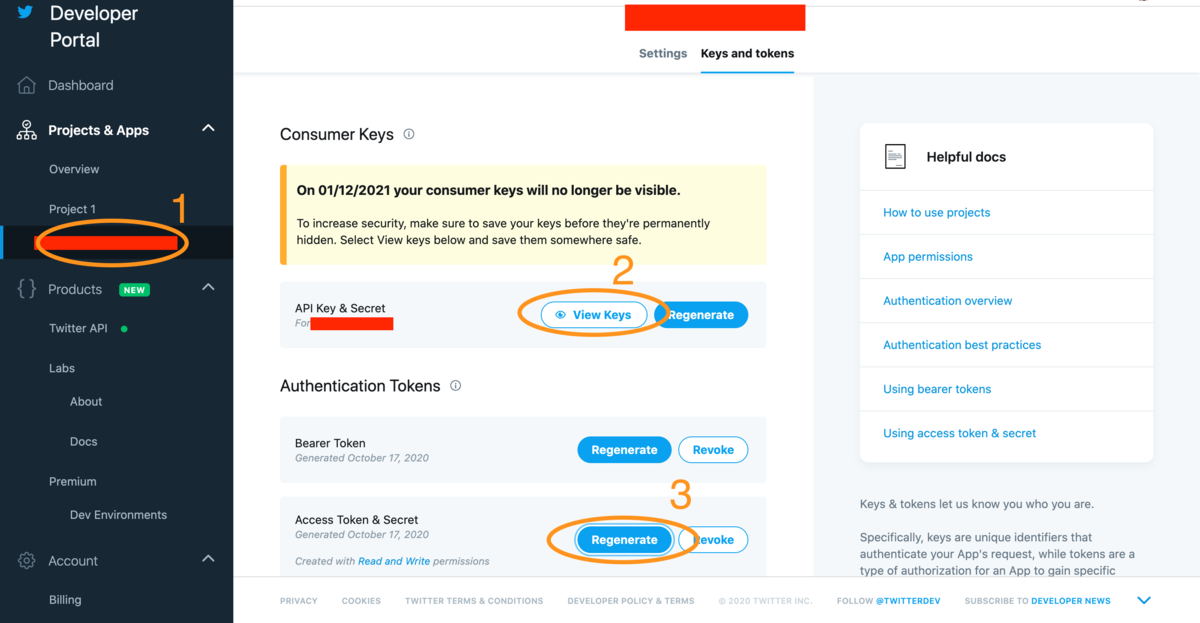
これらが取得できたら、早速コードを書いていきましょう
その1:tweetをする。
クライアントを作ってtweetが見れたところで、自分がtweetできなきゃ面白くないですよね。
なので、直書きでとりあえずtweetしてやる!といった感じで書いてみました。
#tweetを投稿 import tweepy # 準備で取得したキーを格納する consumer_key = "consumer_key" consumer_secret = "consumer_secret" access_token = "access_token" access_token_secret = "access_token_secret" # Twitterオブジェクトの生成 auth = tweepy.OAuthHandler(consumer_key, consumer_secret) auth.set_access_token(access_token, access_token_secret) api = tweepy.API(auth) # tweetを投稿 api.update_status("APIでツイートできた〜〜〜やった〜〜〜〜")
#準備で取得したキーを格納するの部分には各自取得したキーをいれてください。
これを実行すると…
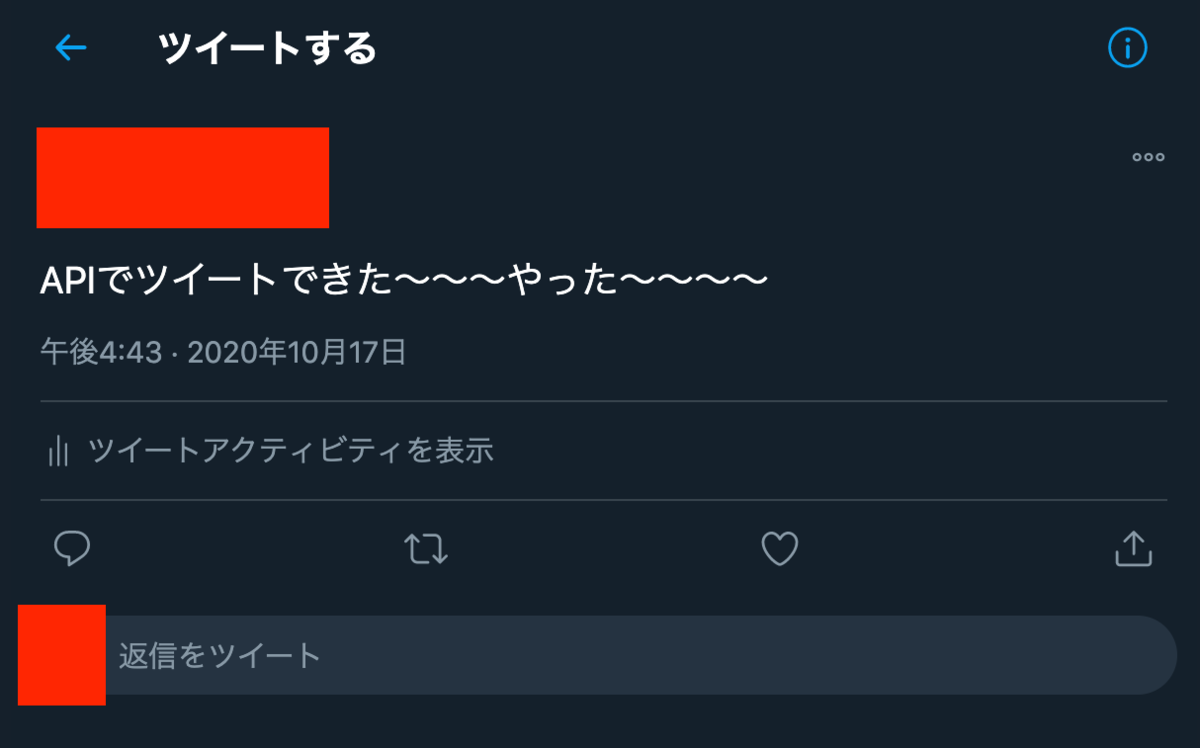
こんな感じで実際にtweetできました。
OAuth認証でAPI呼び出しする感じですね。
この段階で「お、意外と簡単やん。」と自信を付けさせてくれます。
APIってこう言うところが偉大ですよね。
その2:特定のユーザーのtweetを取得する。
今回は我らが@DevRakusのtweetを取得します。
最新の5tweetくらいを取得してみます。
import tweepy consumer_key = "consumer_key" consumer_secret = "consumer_secret" access_token = "access_token" access_token_secret = "access_token_secret" # Twitterオブジェクトの生成 auth = tweepy.OAuthHandler(consumer_key, consumer_secret) auth.set_access_token(access_token, access_token_secret) api = tweepy.API(auth) #tweetを取得 Account = "DevRakus" #取得したいユーザーのユーザーIDを代入 tweets = api.user_timeline(Account, count=5, page=1) for tweet in tweets: print('tweetId : ', tweet.id) # tweetのID print('tweetUser : ', tweet.user.screen_name) # ユーザー名 print('tweetDate : ', tweet.created_at) # 呟いた日時 print(tweet.text) # tweet内容 print('favo : ', tweet.favorite_count) # tweetのいいね数 print('retw : ', tweet.retweet_count) # tweetのRT数 print('='*80) # =を80個表示(区切り線)
これを実行すると…

こんな感じでtweetの取得ができた~~~~!
クライアント作ってユーザーページ開くときはこんな感じでtweet取得して表示する…
とかそんな感じなんですかね。
その3:検索ワードで引っかかったtweetをJSONファイルにする。
さっきのよりも、よりシステムチックにtweetを取得してみましょう。
今回は弊社の製品、楽楽精算と入ったtweetを検索してJSONファイルに仕立て上げようという魂胆です。
#tweetをファイルとして保存 import json import datetime import time from requests_oauthlib import OAuth1Session from pytz import timezone from dateutil import parser # 取得した各種キーを格納----------------------------------------------------- consumer_key = "consumer_key" consumer_secret = "consumer_secret" access_token = "access_token" access_token_secret = "access_token_secret" SEARCH_TWEETS_URL = 'https://api.twitter.com/1.1/search/tweets.json' RATE_LIMIT_STATUS_URL = "https://api.twitter.com/1.1/application/rate_limit_status.json" SEARCH_LIMIT_COUNT = 10 # セッション確立 def get_twitter_session(): return OAuth1Session(consumer_key, consumer_secret, access_token, access_token_secret) # キーワード検索で得られたtweetを取得する # max_idを使用して次の100件を取得 def search_twitter_timeline(keyword, since='', until='', max_id=''): timelines = [] id = '' twitter = get_twitter_session() params = {'q': keyword, 'count': SEARCH_LIMIT_COUNT, 'result_type': 'mixed'} if max_id != '': params['max_id'] = max_id if since != '': params['since'] = since if until != '': params['until'] = until req = twitter.get(SEARCH_TWEETS_URL, params=params) if req.status_code == 200: search_timeline = json.loads(req.text) for tweet in search_timeline['statuses']: # 次の10件を取得したときにmax_idとイコールのものはすでに取得済みなので捨てる if max_id == str(tweet['id']): print('continue') continue timeline = {'id': tweet['id'] , 'created_at': str(parser.parse(tweet['created_at']).astimezone(timezone('Asia/Tokyo'))) , 'text': tweet['text'] , 'user_id': tweet['user']['id'] , 'user_created_at': str(parser.parse(tweet['user']['created_at']).astimezone(timezone('Asia/Tokyo'))) , 'user_name': tweet['user']['name'] , 'user_screen_name': tweet['user']['screen_name'] , 'user_description': tweet['user']['description'] , 'user_location': tweet['user']['location'] , 'user_statuses_count': tweet['user']['statuses_count'] , 'user_followers_count': tweet['user']['followers_count'] , 'user_friends_count': tweet['user']['friends_count'] , 'user_listed_count': tweet['user']['listed_count'] , 'user_favourites_count': tweet['user']['favourites_count'] } # urlを取得 if 'media' in tweet['entities']: medias = tweet['entities']['media'] for media in medias: timeline['url'] = media['url'] break elif 'urls' in tweet['entities']: urls = tweet['entities']['urls'] for url in urls: timeline['url'] = url['url'] break else: timeline['url'] = '' timelines.append(timeline) else: print("ERROR: %d" % req.status_code) twitter.close() return timelines, id def write_tweet_to_file(timelines, dt): # 日付ごとにjsonで書き込み f = open("/Users/koichi/Documents/tweet/tweet-" + dt + ".json", "a") for timeline in timelines: json.dump(timeline , f , ensure_ascii=False , sort_keys=True # ,indent=4 , separators=(',', ': ')) f.write('\n') f.close() return ## メイン処理 timelines = [] # tweetID max_id = '' # 検索ワード keyword = '楽楽精算' # tweet取得対象日 start_dt = '20201104' start_dt = datetime.datetime.strptime(start_dt, '%Y%m%d') for i in range(7): dt = (start_dt - datetime.timedelta(days=i)).strftime('%Y-%m-%d') # print(dt) since = str(dt) + '_00:00:00_JST' until = str(dt) + '_23:59:59_JST' while True: # tweet検索 timelines, max_id = search_twitter_timeline(keyword, since, until, max_id) time.sleep(5) if timelines == []: break write_tweet_to_file(timelines, dt) if len(timelines) < SEARCH_LIMIT_COUNT: break
先ほどまで使っていたtweepyというライブラリではない方法で試してみました。
実行した結果は…

できたできた!
ただ、筆者はここで力尽きてしまったのでせっかくJSONにしたのにtweetの形にして復元みたいな
もう一段階の作業をやりませんでしたはできませんでした…
ただ、今回みたいなことをしたおかげで、
特定のワードが入ったtweetしか流れてこないTLみたいなのもできそうで面白そうですよね。
(普通に公式の検索機能と同じですが…)
おわりに
お恥ずかしながら、筆者はTwitterAPIで遊んでみようと思って初めてPythonを触りました。(環境構築からしました。)
Pythonってとても扱いやすくていい言語ですよね。(筆者は制約が多い方が好きですが)
APIも相まって、初級編としてはかなり扱いやすくてこれからいろいろ試してみたいなぁという気持ちになりました。
Python自体が未知の世界で、ほとんど参考にした記事の内容を拝借させていただきましたが、
とりあえずお試しに触ってみたい!という方の目に留まればよいと思います。
次回の記事ではもう少し完成形になるようなものを書けると…いいな…(将来の自分に期待)
以下の記事を参考にしています。
エンジニア中途採用サイト
ラクスでは、エンジニア・デザイナーの中途採用を積極的に行っております!
ご興味ありましたら是非ご確認をお願いします。

https://career-recruit.rakus.co.jp/career_engineer/カジュアル面談お申込みフォーム
どの職種に応募すれば良いかわからないという方は、カジュアル面談も随時行っております。
以下フォームよりお申込みください。
forms.gleイベント情報
会社の雰囲気を知りたい方は、毎週開催しているイベントにご参加ください! rakus.connpass.com
