
はじめに
こんにちは、PS本部C&A部開発オペレーション部門の8G3Tです。AI映像解析ソリューションCOTOHA Takumi Eyesの技術開発や運営保守に取り組んでいます。チームの開発メンバーは6月18日から22日の間に開催されたコンピュータービジョン分野のトップカンファレンスであるCVPR2023にリモートで参加しました。本記事ではCVPR2023に採択された視覚・言語のマルチモーダル技術に関して、私たちが興味深く感じた論文をピックアップしてご紹介します。
なお、今回の学会参加はイノベーションセンターのメディアAIチームと連携して実施しました。NeRF技術(ニューラルネットワークベースの微分可能な3次元レンダリング手法)に関する論文のご紹介や検証結果については、以下のメディアAIチームが取りまとめた記事をぜひご覧ください。
目次
視覚言語マルチモーダル技術の概要
人間の学習は本質的に多様なモーダリティを備えており、複数の感覚を合わせて処理することによって新しい情報への理解を深めることが可能となります。近年、コンピュータービジョン分野においてもマルチモーダルのAI技術が急速に発展し、広く注目を集めています。
特定の画像処理タスクのデータセット(例:画像分類)で学習したユニモーダルAIと比較して、画像と自然言語の大規模データで学習したマルチモーダルAIの汎化性能が高く、チャレンジングなフューショットやゼロショットの画像認識タスクにおいて優れた性能を示しました。画像生成のStable Diffusionや質問応答のGPT-4といった汎用性の高いマルチモーダルAIサービスは人間の知的作業全般に変革をもたらしつつあり、マルチモーダルAIの性能向上が求め続けられています。
今回はマルチモーダルAIの画像・映像認識性能を向上させる取り組みに関する最新論文とマルチモーダルAIをベースに新たに提案されたタスクについてご紹介します。
画像・映像認識性能の向上に関する論文
Improving Commonsense in Vision-Language Models via Knowledge Graph Riddles 1
概要
背景:
既存のVLモデルには、人工的な一般知能に向けた重要な要素である常識的知識/推論能力(例えば「レモンは酸っぱい」)が欠けている。 下の画像の例では酸っぱい味がするものに対応する画像として既存のVLモデルがレモンではなくチョコレートケーキを選んでしまっている。
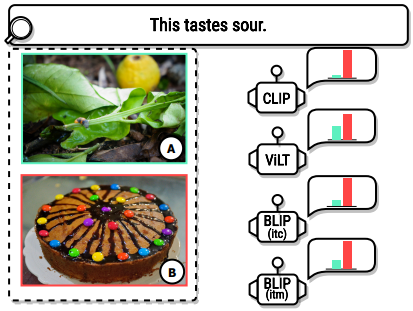
原論文 Figure 1 から引用 この現象の原因の重要な一つとして、既存の大規模なVLデータセットにはあまり常識的な知識が含まれていないことがある。通常のVLデータセット(例えばCOCOやCC 12M)には、名詞や(画像内の実体を直接説明するような)説明形容詞が多く含まれ、動詞や助詞は通常のテキストに比べて少ない。このような分布の違いは、言語のみのモデルとは異なり、VLモデルが純粋にデータセットを拡大することによって、常識的な能力を獲得することは不可能かもしれないことを示唆している。
また、視覚的な質問応答や生成タスクによってコモンセンス能力を評価する既存のベンチマークは、訓練に広く適用できず、データサイズも限られている。これらベンチマークは既存のVLモデルの多くには適合しておらず、下流タスクに移行することなく、VLモデルの常識的知識を自動的に直接比較することは、未解決の課題である。
Contribution:
- 視覚言語モデルにおけるコモンセンス能力を改善する手法を提案
提案手法
- 知識グラフを利用しコモンセンスで補強された画像とテキストのペアを生成するデータ増強手法であるDANCEを提案
下図は知識グラフを利用したデータ生成法を示している。

💡 コモンセンス知識グラフ(ConceptNet)を(エンティティ、関係、エンティティ)の三つ組み形式にしそれらをエンティティの1つを含む画像と対にする。
💡 その画像に含まれるエンティティの名前を、例えば「このアイテム」のような指示代名詞で隠す。
💡 3つ組みから説明文を生成する。
生成されたデータは画像とテキストのペア形式のためほとんどのVLモデルの学習に容易に適用できる。
学習段階でエンティティ間の関係をモデルに記憶させることで、推論段階でそのようなデータ補強が不要。
データペア生成パイプラインは、既存の統合されたコモンセンス知識ベースと、視覚言語モデルの大規模かつ多様な学習データを活用し、自動的かつスケーラブルである。
※ ConceptNet(ConceptNet):
専門家、クラウドソーシング、ゲームなどさまざまなソースから作成された8Mのノードと21Mのエッジを持つ、一般的で統合されたコモンセンス知識グラフ。
検索にもとづくより広く適応可能な新しいコモンセンスベンチマークを提案
提案ベンチマークにはCOCOデータセットとConceptNetを用いて上記手順で生成された画像-テキストペアを利用する。
提案ベンチマークはテキスト-画像検索と画像-テキスト検索に分けられ、前者はコモンセンスを必要とする記述に最も合致する画像を検索するもので、後者はその逆。
既存の常識的知識を用いて新しい知識を推論する汎化能力をさらに評価するために、テスト集合を知識がトレーニング集合に現れるtest-seenと、対応する関係がトレーニングに存在しないtest-unseenに分割する。 (例えば「パイナップルがピザに乗っている」という知識と「ピザハットがピザのメーカーの1つである」という知識を学習していた場合、モデルが 「パイナップルはピザハットに必要かもしれない 」と推論できるか)
生成されたデータセット
下図は既存のVLデータセットと生成されたデータセット、およびConceptNetにおける品詞分析結果を示している。
既存のデータセット(COCOやCC 12M)のテキストで最も頻出する単語は名詞であり、対照的に、知識ベースConceptNetにはより多くの動詞があり、エンティティ間の関係に関する豊富な情報を含んでいる。こうした分布違いがVLモデルのコモンセンス能力欠如に繋がっていると考えられ、提案するDANCE拡張データは、既存のVLデータよりも有意に多くのコモンセンスを提供。

下図は既存のさまざまな知識ベースデータセットとの比較を示している。提案ベンチマークは規模が大きく、幅広い知識を含んいる。

下図は提案ベンチマークにおける既存モデルと人手によるスコアの比較を示している。提案ベンチマークでは人手のスコアと既存モデルのスコアに大きな乖離がある。

結果
下図は事前学習、ファインチューニングそれぞれにDANCEによるデータ増強を適用した場合のスコア比較を示している。いずれの場合もDANCEによるデータ増強によりスコアが改善していることがわかる。
また、test-unseenデータについても、大きな改善が観察される⇒DANCEの事前学習がモデルのコモンセンス能力を向上させるだけでなく、既存のコモンセンス知識に基づいて新しい知識に汎化する能力を強化することを示している。
加えて、コモンセンスをあまり含まないCOCO検索のバニラベンチマークでもその精度は維持されるか、それ以上の精度となる。このことは、DANCEがコモンセンス能力を高めると同時に、一般的な視覚言語表現を学習することを示している。

下図は既存のコモンセンスベンチマーク(OK-VQA)での比較を示している。こちらもDANCEで事前学習したモデルでは精度が改善していることが分かる。

上図は定性分析の結果を示している。右の画像(OK-VQA)の例では既存モデルが「風船を満たしているものは何か」という質問に正しく答えられていないのに対し、提案手法による事前学習を行ったモデルは正しく答えられている。

💡 実際ConceptNetを見ると以下のような知識があるのでこういったコモンセンスが活かされているのではと考えられる。

下図はより多くのベンチマークにおいて他のVLモデル(ALBEF)と比較した結果を示している。
提案ベンチマークでは大きな精度向上が見られるほか、VQA(標準的な視覚的質問応答)やNLVR(画像ペアに関するキャプションの真偽を分類)は特別コモンセンスを対象としているわけではないにもかかわらず精度が改善している。

今後の課題
人間のような知能を実現するためには、常識的な知識を認識するだけでは不十分である。
⇒モデルは、現実のシナリオにおける数学的・物理的計算のような推論ができなければならず、これは既存のVLモデルではまだ弱く、既存の常識的知識ベースには含まれていない。
RA-CLIP: Retrieval Augmented Contrastive Language-Image Pre-training 2
概要
- 背景:
- 自然言語と画像を結びつけて対比学習を行うCLIP手法は、色々なコンピュータービジョン分野のタスクにおいて優れた汎用性能があるため注目されている。
- CLIPでは一定の精度を達成するために多くのデータから視覚的概念を学習(記憶)することが必要で、限られたデータでの精度向上が課題として挙げられている。
- Contribution:
- 本論文では、RA-CLIPという手法を提案し、同じ学習データ量で大幅にzero-shot画像分類のタスクにおいて+12.7%(Top-1)の精度向上を実現。
- RA-CLIP:より豊富な情報量を持たせるように画像特徴量を拡張する手法。
- テキスト特徴量のほうは画像特徴量と比べて情報量が少ないため、拡張しても有用な情報量だけ(拡張によりノイズも入ってしまう)を増やすことが難しいとablation studyの実験によって判明。
- 本論文では、RA-CLIPという手法を提案し、同じ学習データ量で大幅にzero-shot画像分類のタスクにおいて+12.7%(Top-1)の精度向上を実現。
提案手法

- 上図は全体の処理の流れを示している:
- 入力画像に対して、学習セットとは別の参照セットから関連画像とテキストの複数のペアをRAM(Retrieval Augmented Module)というモジュールで画像エンコーダーによって抽出した画像特徴量を拡張し、より豊富な情報量を持つ画像特徴量にすることで大幅なzero-shot精度の向上を実現。
- テキスト側の処理はCLIPとは同じ、テキストエンコーダーで特徴量を抽出する。
- RA-CLIPとオリジナルCLIPの違いをイメージしやすいようにたとえると、テスト段階でCLIPは暗記・理解できた概念にしか正しく答えられないという特徴に対して、RA-CLIPは問題に関連する参考情報を見ながらテストを受けられるので、限られた学習でさまざまな概念をきちんと理解できていなくても、CLIPと比較して得点が上がるという特徴があると考えられる。
- 入力画像と関連する画像・テキストペアの検索の実現:
- 入力画像と参照セットにおける画像の特徴量を教師なし学習したViTモデル(DINO)で抽出し、類似度が高い上位Kの画像と対応するテキストを参照セットから取得。また、学習段階ではこの特徴抽出モデルのパラメータは凍結される。

- 上図はRAMの処理の流れを示している:
(ViT:DINO)と
(Transformer:SentenceT)はそれぞれ事前に学習したシングルモーダルのエンコーダーで、パラメータはRA-CLIPの学習段階で更新されない。
、
を抽出し、Multi-head Attention blockによって埋め込み特徴量
、
を生成し、最終的に拡張された
を取得。
実験
- データセット(baseline):
- 参照セット:YFCC15Mからランダムサンプリング(1.6 millionの画像・テキストペア)
- 学習セット:YFCC15Mその他のデータ(13 million の画像・テキストペア)
下図は学習データセットの例を示している。

- テストデータ:
- ImageNetやCIFAR100といったimage classificationのテストデータセットでzero-shot推論
- モデル構造:
- 画像エンコーダー:ViT-B/32 特徴量次元数768
- テキストエンコーダー:BERT-base 特徴量次元数768
結果
下図は定量評価の結果を示している。


- CLIPとRA-CLIPのbaseline(ID1 & ID5)では同じ量の学習データセットを利用していたが、zero-shotの画像分類テストの結果はRA-CLIPの方が精度が高く(+15.8%)、提案手法の有効性を示した。
- 複数の画像分類データセットにおいてzero-shot/linear probe(学習済みのエンコーダーを凍結して新たにclassification headを学習する)の平均精度がそれぞれ+12.7%/+6.9%向上され、提案手法の導入により汎用性能の向上を実現した。

- 下図は定性評価の結果を示している。RA-CLIPが正しく識別できたケースの参照セット検索プロセスと識別結果から、RAMが正しい参考情報を用いて入力画像の特徴量をより豊かにできることを示している。

- 上図は参照セットの規模とzero-shot画像分類精度の関連性を示している。水平軸が対数スケールでプロットされているため、参照セットを拡張し続けると性能が飽和になってしまう。
Pros&Cons
- Pros:「参考資料持ち込み可能なテスト」により、限られた学習データセットでCLIPモデルの精度向上が実現できる。
- Cons:Vanilla CLIPと比較して、類似画像検索による特徴抽出や類似度算出の処理と、RAMモジュールの特徴量拡張処理(たとえるとテストの際に参考資料から関連情報を探すこと)が必要で、全体の計算量が増えてしまう。
Fine-tuned CLIP Models are Efficient Video Learners 3
概要
- 背景:
- CLIPやALIGNなどの事前学習済みの視覚言語(VL)モデルは、インターネットから集めてきた数億の画像・テキストペアを用いて学習し、分類、検出、セグメンテーションなどの多くのタスクにおいて強力な汎化性能とゼロショット能力を獲得した。しかし映像における情報量は画像より遥かに多いため、映像・テキストペアの学習データを用意するコストも膨大であり、映像タスクのためのCLIPをゼロから学習することはほぼ不可能である。従って、事前学習済みの画像言語モデルを映像ベースのタスクに適応することが必要となる。
- 最近の映像ベースのアプローチでは、空間的時間的モデリングのためにCLIPの表現を追加の学習可能なコンポーネントとして採用した。しかし、事前学習済みのCLIPエンコーダーをfine-tuneするとともに、新たに導入された時間モデリングコンポーネントがCLIPの汎化能力を妨げてしまう。
- Contribution:
- 画像ベースのCLIPを映像のタスクに適応させるためのViFi-CLIP(Video Finetuned CLIP)と呼ばれるベースラインを提案。CLIPのfine-tuningが映像特有の帰納バイアスを学習するのに十分であることを示した。
- 提案手法はzero-shot、base-to-novel generalization、few-shot、fully-supervised tasksを含む4つの異なる設定で実験した結果、SotA手法より優れた性能を示した。
- また、論文で提案した「Bridge&prompt」手法はアノテーション済みの学習データが少ない領域において、fine-tuningとプロンプト学習によりモダリティギャップを埋めることに成功し、手法の有効性を示した。
提案手法
下図は提案手法の処理流れを示している。

- CLIPの汎化性能を低下させるコンポーネントを新規追加せず、temporal pooling(average pooling)を用いた単純なフレームレベルの後期特徴集約により、CLIPの出力特徴量の時間的情報の取りまとめを実現。
- テキストエンコーダーでは、映像を表すプロンプト(例えば”a photo of a
”)を1つの埋め込み特徴量に変換し、映像との対応関係を利用して対比学習を行った。 - ViFi-CLIPでは、画像エンコーダーとテキストエンコーダー両方でfull fine-tuningを実施
実験
- ViFi-CLIPの汎化能力を分析するために、2つの問題設定で評価する:
- Zero-shot settingによるクロスデータセットの汎化性能の評価
- モデルはソースデータセットで訓練され、そのままダウンストリームの異なるデータセットに転移され評価する。
- Base-to-novel settingによる新しいクラスでの汎化性能の評価
- 提案されたベースと新しいクラスの分割は、全カテゴリを均等な2つのグループに分け、最も頻繁に発生するクラスをベースクラスとしてグループ化する。モデルはベースクラスで学習され、ベースおよび新しいクラスの両方で評価する。
- Few-shot setting
- データセットからK-shotのデータがランダムサンプリングされ学習に利用される。データセットのvalidation setで評価する。
- Fully-supervised setting
- データセットの全てのtraining setで学習し、test setで評価する。
- Zero-shot settingによるクロスデータセットの汎化性能の評価
結果
- 下図は定量評価の結果を示している。

- ViFi-CLIPの汎化性能が従来手法より高い
- Zero-shot settingでは、ゼロショットアクション認識に特化したシングルモーダル手法と画像ベースのマルチモーダルVLモデルを映像行動認識に適応させたモデルと比較して、ViFi-CLIPの方がクロスドメインでの精度が高い
- Base-to-novel settingでは、帰納バイアスを利用してコンポーネントを追加したモデルと比較して、ViFi-CLIPの方がベース精度と新しいクラスでの精度が高い


ViFi-CLIPの教師あり学習の性能も従来手法より優れている(または同レベル)
- Few-shot settingでは、ViFi-CLIPはshot数(K)の増加とともに精度が上がる傾向があり、全てのショットで従来手法より精度が優れていることを示している
- Fully-supervised settingでは、ViFi-CLIPは時間モデリングのために追加で設計された学習可能なコンポーネントを使用する手法と比較して同レベルの精度を達成
下図は定性評価の結果を示している。

- ViFi-CLIPの埋め込みは、より良い分離が実現され、CLIPの単純なfine-tuningだけでも適切な帰納バイアスを学習し、映像内の時間情報をモデル化するために専用のコンポーネントを持つ手法に対して競争力のある性能を発揮できることを示している

ViFi-CLIPは、時間的手がかりから物体間の関係やシーンのダイナミクスを学習し、高速移動する部分と物体に焦点を当てることで、ビデオ固有の情報をエンコードする能力を示している
下図は処理性能の評価結果を示している。

- 余計なコンポーネントを使用していないため、他の手法と比較してFLOPsが低く、トレーニングパラメータの規模も少なくなる。
Pros&Cons
- Pros:本論文で提案したViFi-CLIPのベースラインでは、ほとんどCLIPの構造を改変せず、シンプルなfine-tuningだけでもVanilla CLIPを映像ドメインに適応させることができる。精度と処理性能の両方において、映像内の時間情報をモデル化するために専用のコンポーネントを持つ従来手法より優れている。
- Cons:専用のコンポーネントを持つ手法と比較して、zero-shotの映像認識タスクにおいて汎化性能が優れている一方、教師あり学習の場合だと性能が下がることが確認される。
Top-Down Visual Attention from Analysis by Synthesis 4
概要
- 背景:
- 人間の注意方法
- トップダウン型注意:選ぶべき事前知識を持ち、注目すべきものをピックアップしそれ以外の情報を省くようにバイアスを掛けて見つけ出すこと
- ボトムアップ型注意:事前知識なく、他より明らかに目立つもの、異質なものなどを見つけ出すこと
- 先行研究では人の知覚システムにおけるボトムアップ型注意のメカニズムは合成による分析( Analysis by Synthesis )を実行した結果であるという仮説が立てられている
- 入力画像と画像の潜在的原因に関する高レベルの事前分布の両方に依存
- Analysis by Synthesisを通して異なるオブジェクトの低レベルの認識を事前知識として持ち、トップダウンの知識として定式化される
- 既存の研究は概念的なのでモデル設定の指針になりにくかった
- 人間の注意方法
- Contribution:
- 人間の視覚的なトップダウン型の注意方法とされているAnalysis by Synthesisを取り入れた手法(AbSViT, Analysis-by-Synthesis Vision Transformer)の利用により、VQA(Vision Q&A)やゼロショット検索といった画像に対する質問に関連する部分をアテンションするタスク、画像認識、セグメンテーションタスクで精度向上が実現できた。
提案手法
下図は提案手法の処理流れを示している。
(a)
・各ステップの操作は紫色、その他は灰色で色分けする。
・AbsviTはまず画像をフィードフォワード経路に通す。
・出力トークンは事前ベクトルξとの類似度によって重み付けす。
・デコーダを通して各自己注意モジュールにフィードバックされ、最終フィードフォワード実行のトップダウン入力となる。
(b)
・自己注意へのトップダウン入力は値行列に加えられるが、他の部分は変わらない。

下図は定性評価の結果を示している。
各画像に対して、ボトムアップ注意は両方の物体を強調する。
これに対して、異なるクラスプロトタイプを事前学習として用いることで、異なる物体に注目するようにトップダウン注意を制御でき、それに応じて分類結果も変化する。

データセット
VQAについては、VQAv2をトレーニングおよびテストに使用し、VQA-HATによって収集された人間の注意と注意マップを比較する。ゼロショット画像検索にはFlickr30Kを使用する。
画像分類については、ImageNet-1K(IN)で学習とテストを行い、IN-Cの破損画像、IN-Aの敵対的画像、IN-RとIN-SKの分布外画像でもテストを行う。セマンティックセグメンテーションについては、PASCAL VOC、Cityscapes、ADE20Kでテストしている。
下図はVision-Language Taskの結果を示している。


下図は画像の分類, ロバスト性の結果を示している。


トップダウンのアテンション設計から得られるオブジェクト中心の表現は、破損した画像、敵対的な画像、分布外の画像に対する汎化を可能にする。
結論
著者らは、視覚的なトップダウン型の注意方法であるAbS(Analysis-by-Synthesis)とスパース再構成の機能的等価性に関する先行研究から、 目的志向的なトップダウン変調を行うことで、AbSと同様のスパース再構築を最適化することを示した。その結果、トップダウン型の注意を再現できることを示した。 また、著者らは、AbSを変動的に近似するトップダウン変調ViTモデルであるAbSViTを提案した。AbsViTは制御可能なトップダウン注意を達成し、V&Lタスク、画像分類、ロバスト性においてベースラインよりも改善することを示した。
新たなタスクを提案した論文
Connecting Vision and Language with Video Localized Narratives 5
概要
- Vision&Languageのこれまでの研究
- Image Captioning:静止画に対して、キャプションの(一部の)単語をGrounding(結びつけ)
- Localized Narrative:アノテーターが自分で画像を説明しながら、説明している領域をマウスで指定→音声とマウスポインタが同期しているため、各単語の視覚的なGroundingが正確に行える
- Video Localized Narratives(本論文):静止画→動画に拡張
静止画と動画の違い
- 静止画:ある一瞬のみ記述 VS 動画:オブジェクト間の関係性や相互作用など一連のイベントを記述
動画の場合より詳細なNarrativeをアノテーション可能である。動画の脈略を参照できる可能性が増え、対象物のco-reference(共参照)問題の解決にもつながる(e.g. 同一の名詞(オウム)がNarrative中に複数回出現し、かつ異なるインスタンスを示す場合、オウムの細かな見た目の違いや動作などで参照先の曖昧性を回避できる)
Contribution:
- Video Localized Narrrativesをアノテーションするプロトコルを提案
- アクター(動画の登場人物;人、オウム、背景など)ごとに説明
- 受動関係が明確になることで複雑なイベントを正確に記述(e.g. 人がオウムを触る/オウムが人に触られている)
- キーフレームごとに説明
- 動画に対して説明しようとすると、顕著なオブジェクト(主役)のみを記述する可能性が高い
- アクター(動画の登場人物;人、オウム、背景など)ごとに説明
- 作成したデータセットをVideo Narrative Grounding (VNG)とVideo Question Answering (VQA)へ適用
- Video Localized Narrrativesをアノテーションするプロトコルを提案
従来のVideo Narrative Grounding (VNG)
- 下図はVNGのタスク定義を示している。
- 入力:映像、説明文(Narrative)、説明文中の名詞の位置
- 出力:参照されたオブジェクトのフレームごとのセグメンテーションマスク

提案手法
- ベースライン(ReferFormer)を拡張
下図はReferFormerの処理流れを示している。
- ReferFormerは映像から特徴を抽出するためのVisual Encoderと、説明文から特徴(条件付きクエリ特徴)を抽出するためのText Encoderで構成される。
- Text Encoderから抽出した単語ごとの特徴量(
)をプールして、文全体の特徴量(
)とする
- Text Encoderから抽出した単語ごとの特徴量(
- これらの2つのモーダルの特徴量をDecodeしてフレーム毎のセグメンテーションマスクを得る
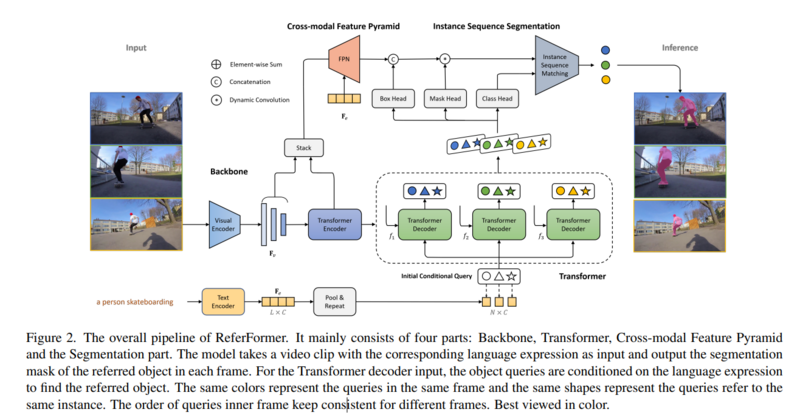
原論文 Figure 2 から引用 - ReferFormerは映像から特徴を抽出するためのVisual Encoderと、説明文から特徴(条件付きクエリ特徴)を抽出するためのText Encoderで構成される。
ReferFormerの課題
- 文全体の特徴を用いているが、これが有効なのは「文全体が1つのオブジェクトを記述する場合」
- VNGでは1つの動画に対して複数のアクター(オブジェクト)が存在するためそぐわない
- ReferFormer-VNG(提案手法)
- アクターごとのNarrativeの名詞に限定して単語ごとの特徴量(
)を抽出、それらをプールして文全体の特徴量とする。
- 2つの異なるオウムをセグメンテーションに分ける場合、最初の「オウム」のNarrativeの名詞に対してReferFormer-VNGを実行し、次の「オウム」は(1回目と異なる)Narrativeの名詞の特徴を使って2回目に実行する。
- 本論文ではMouse Traceは学習・評価には使っていない。VQAデータセットを作成する際のみに使用。
- アクターごとのNarrativeの名詞に限定して単語ごとの特徴量(
データセット
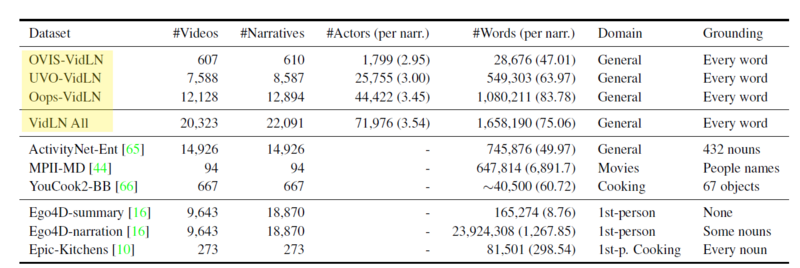
- 下図はVNGのデータセットを示している。既存データセットに対して、物体間の相互関係を含む状況説明(narrative)とその場所(マウス位置)を付与する。
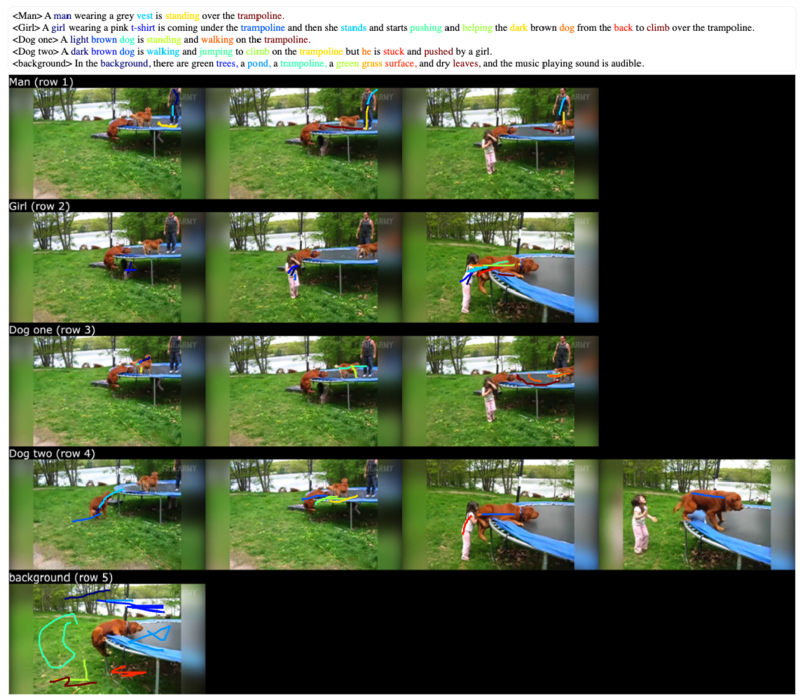
下図はOVIS/UVO-ViDLN(提案データセット)を示している。:
OVISとUVOに対して、状況説明(narrative)とその場所(マウス位置)を付与する
すべての単語(形容詞、動詞を含む)をマウス位置をトレースしてGrounding
原論文 Figure S1 から引用 下図は OVIS を示している。
- video segmentation用データセット(e.g. person, fish, vehicle, horse, sheep…)

出典: http://songbai.site/ovis/ 下図は UVO を示している。
- video segmentation用データセット(e.g. person, car, chair, bottle…)

出典: UVO論文 Figure 3 Ego4D
- 一人称視点のみ
- 一部の名刺のみを矩形でGrounding
- Epic-Kitchens
- キッチン内のみ
- すべての名詞をピクセル単位でGrounding
実験
- 評価尺度:
&
Measure
- データセット
- OVIS-ViDLN, UVO-ViDLN
- 加算名詞のみを採用(e.g. car, parrot)し、stuff categories(e.g. sky, water)は除外。
Method/Dataset OVIS UVO Baseline(Full narrative) 22.9 25.8 Baseline(Noun) 25.7 35.6 Proposed(Best) 32.7 46.4
結論
著者らは、動画に対するキャプショングを解くためのデータアノテーションのプロトコルとデータセットを構築し、ベースラインの手法を提案した。 手法自体はシンプルで効果的ではあるものの、アクターの数だけReferFomer-VNGを実行するために複雑な説明文に対する計算コストが高い。
Visual Programming: Compositional visual reasoning without training 6
概要
背景:
- これまでの汎用AIシステムを構築するための主なアプローチはエンド・ツー・エンドで学習可能なモデルを用いた大規模な教師なし事前学習と、それに続く教師ありマルチタスク学習だった。しかしこのアプローチでは、各タスク用に整備されたデータセットが必要なので、汎用AIシステムに複雑なタスクを実行させるには、無限とも言えるデータセットが必要になる。したがって、このアプローチで汎用AIシステムを複雑なタスクが実行できるように拡張することは困難である。
例えばテレビ番組「ビッグバン★セオリー」に登場する7人のメインキャラクターをこの画像にタグ付けするというタスクを考える。 このタスクを実行するために、システムはまず指示の意図を理解し、顔を検出し、知識ベースからビッグバン★セオリーの主要登場人物のリストを取得し、登場人物のリストを使用して顔を分類し、認識された登場人物の顔と名前を画像にタグ付けするという一連のステップを実行する必要がある。 これらの各ステップを実行するさまざまな視覚システムや言語システムが存在するが、自然言語で記述されたこのタスク全体を実行することは、現状のエンド・ツー・エンドで訓練されたシステムの範囲を超えている。
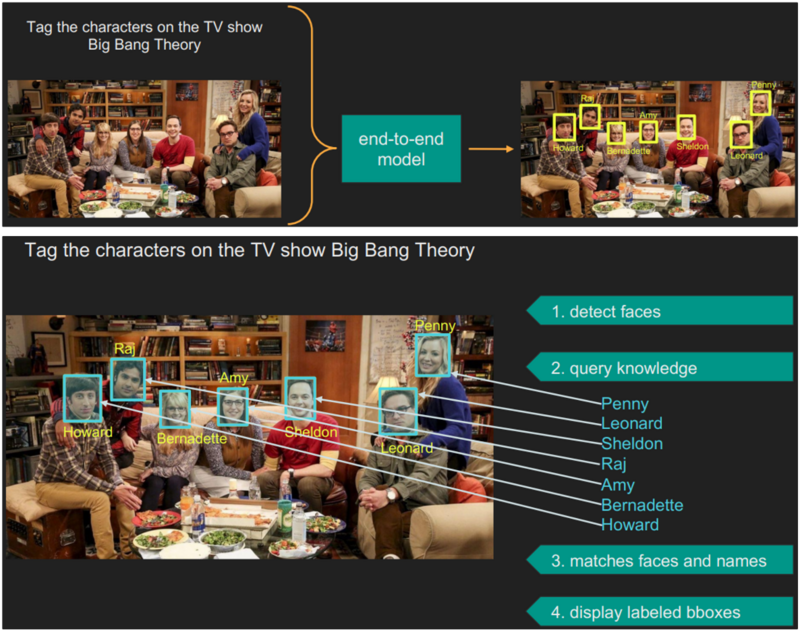
出典: https://cvpr2023.thecvf.com/media/cvpr-2023/Slides/22652.pdf
- これまでの汎用AIシステムを構築するための主なアプローチはエンド・ツー・エンドで学習可能なモデルを用いた大規模な教師なし事前学習と、それに続く教師ありマルチタスク学習だった。しかしこのアプローチでは、各タスク用に整備されたデータセットが必要なので、汎用AIシステムに複雑なタスクを実行させるには、無限とも言えるデータセットが必要になる。したがって、このアプローチで汎用AIシステムを複雑なタスクが実行できるように拡張することは困難である。
Contribution:
- 人々が実行したいと思うような複雑で多様なタスクに対応する汎用AIシステムを提案
提案手法
- 大規模言語モデルの文脈内学習能力を利用し、タスク固有のトレーニングを必要とせず、自然言語で記述されたタスクを、エンド・ツー・エンドに特化した学習済みモデルや他のプログラムで処理できるような単純なステップに分解することで、複雑で幅広いタスクに対応できる、VISPROGというシステムを提案。
- VISPROGは、ビジュアルデータ(単一の画像または画像のセット)と自然言語命令の入力からステップのシーケンス(VISPROGプログラム)を生成し、それを実行して解と包括的で解釈可能な根拠の両方を得る。
- 生成されたプログラムの各行は、市販のコンピュータビジョンモデル、画像処理サブルーチン、またはpython関数など幅広いモジュールのうちの1つを呼び出し実行することでプログラムの後続部分で消費される可能性のある中間出力を生成する。
下図の「Factual Knowledge Object Tagging」の例では、VISPROGによって生成された視覚的プログラムは、顔検出器、知識検索システムとしてのGPT-3、およびオープン語彙画像分類器としてのCLIPを呼び出して、目的の出力を生成する。

LLMによるプログラム生成
VISPROGは、GPT-3に自然言語で記述された命令と希望する高レベルプログラムの例をプロンプトし、GPT-3の文脈内学習能力を利用して、実際の命令用のプログラムを出力する。
下図は画像編集タスクに対するプロンプトを示している。これらコンテキスト内のプログラム例は手動で書かれており、通常、画像を添付することなく構築可能。
VISPROG プログラムの各行(プログラムステップ)は、モジュール名、モジュールの入力引数名とその値、出力変数名で構成される。GPT-3が各モジュールの入出力タイプや機能を理解できるように、説明的なモジュール名(例:"Select"、"ColorPop"、"Replace")、引数名(例:"image"、"object"、"query")、変数名(例:"IMAGE"、"OBJ")を使用。
これらのインコンテキストの例は、新しい自然言語命令とともにGPT-3に供給され、画像やその内容を観察することなく、VISPROGは入力画像上で実行可能なプログラム(下図の後段)を生成し、記述されたタスクを実行する。

モジュール
下図はVISPROGで実現可能な映像解析処理を示している。
VISPROGは現在、画像理解、画像操作(生成を含む)、知識検索、算術・論理演算などの機能を実現する20のモジュールをサポートしている。

VISPROGでは、各モジュールは下図の通りPythonクラスとして実装され、
(i)行を解析して入力引数名と値、出力変数名を抽出する
(ii)学習済みニューラルモデルを含む可能性のある必要な処理を実行し、出力変数名と値でプログラム状態を更新する
(iii)VISPROGの処理の流れを視覚的に確認できる
メソッドを持つ。
モジュールクラスを実装して登録するだけでVISPROG に新しいモジュールを追加することもできる。

プログラムの実行
プログラムの実行はインタープリターが行う。インタープリターは、以下のような流れで動作する。
(i)プログラムの状態(変数名とその値を対応付けた辞書)を入力で初期化
(ii)その行で指定された入力で正しいモジュールを呼び出しながら、プログラムを行ごとにステップ実行
(iii)各ステップの実行後、プログラム状態をステップの出力名と値で更新
視覚的根拠の提示
各モジュールクラスには、モジュールの入力と出力をHTMLスニペットで視覚的に要約するメソッドも用意されている。
インタープリターは、すべてのプログラムステップのHTML要約を繋ぎ合わせて、プログラムの論理的正しさを分析し最終的な出力を検査するために使用できる視覚的根拠(下図)を提示できる。
こうした視覚的な根拠は、ユーザーが失敗の理由を理解し、パフォーマンスを向上させるために自然言語命令を最小限に調整することも可能にする。

実験
VISPROGは、多様で複雑な視覚タスクに適用できる柔軟なフレームワークを提供する。 本実験では空間推論、複数画像に関する推論、知識検索、画像生成と操作の4つのタスクで評価を実施した。
各タスクで使用された入力、出力、およびモジュールは下図の通り。

Compositional Visual Question Answering
VISPROGの構成的で多段階の視覚的質問応答タスク(GQA)への適性を確認した。
GQAタスクのためのモジュールには、オープン語彙のローカライズ、VQAモジュール、バウンディングボックスの座標や空間的前置詞(above、leftなど)が与えられた画像領域を切り取る関数、ボックスを数えるモジュール、Python式を評価するモジュールなどがある。
例えば、「小さなトラックは、ヘルメットをかぶっている人々の左側にあるか、右側にあるか?」というような質問に対して、VISPROGは、まず「ヘルメットをかぶっている人々」をローカライズし、その人々の左側(または右側)の領域を切り出し、その側に「小型トラック」があるかどうかをチェックし、あれば「left」、なければ「right」を返す。
プロンプト作成ではトレーニングセットから31のランダムな質問に、希望するVISPROGプログラムを手動でアノテーションする。GPT-3には、GQAの各質問に回答するコストを削減するために、このリストからランダムに抽出された、より少ないサブセットを提供する。
Reasoning on Image Pairs (NLVR)
VQAモデルは単一の画像に関する質問に答えるように学習されるが、実際には、画像コレクションに関する質問に答えるシステムが必要とされるかもしれない。
例えば、あるユーザーが休暇中の写真アルバムを解析し、次のような質問に答えるようシステムに求めた場合:「エッフェル塔を見た翌日、私たちはどのランドマークを訪れたか?」
VISPROGが複数画像の学習データで訓練することなく、単一画像VQAシステムを使用して、複数画像を含むタスクを解決する能力をNLVRベンチマークで確認する。
通常、NLVRの課題に取り組むには、画像ペアを入力とするカスタム・アーキテクチャをNLVRの訓練セットで訓練する必要がある。対してVISPROGは、複雑なステートメントを、個々の画像に関するより単純な質問と、算術演算子および論理演算子を含むpython式と、画像レベルの質問に対する回答に分解することでこれを実現する。
プロンプト作成ではNLVRの訓練セットで、16のランダムなステートメントについてVISPROGプログラムをアノテーションする。これらの例のいくつかは冗長(類似したプログラム構造)であるため、4つの冗長なものを削除して12例のキュレートされたサブセットも作成する。
Factual Knowledge Object Tagging
名前も知らない画像の中の人物や物体(例えば有名人、企業のロゴ、人気の車とそのメーカー、生物の種等)を識別したい状況において、こうしたタスクを解決するには、人物、顔、物体をローカライズするだけでなく、外部の知識ベースで事実知識を調べ、分類のためのカテゴリーセットを構築する必要がある。
このタスクを、事実知識オブジェクト・タギング(Factual Knowledge Object Tagging)と呼び、VISPROGはGPT-3を暗黙の知識ベースとして使用する。例えばGPT-3に”テレビ番組「ビッグバン★セオリー」の主な登場人物をカンマ区切りで列挙せよ”といった自然言語プロンプトで問い合わせることでカテゴリーセットを生成し、得られたカテゴリーセットを、ローカリゼーションや顔検出モジュールによって生成された画像領域を分類するCLIP画像分類モジュールの分類先として利用する。
このタスク用には14のインコンテキストのプログラム例を作成する。(これらのインコンテキストプログラム例には画像は関連付けられていない)
Image Editing with Natural Language
テキストからの画像の生成はStable Diffusionなどのモデルにより、ここ数年で目覚ましい進歩を遂げているが、「Daniel Craigの顔を:pで隠す」(非特定化またはプライバシー保護)、「Daniel Craigのカラーポップを作成し、背景をぼかす」(オブジェクトの強調表示)などのプロンプトを処理することは、まだ難しい。
こうしたオブジェクトの置き換え等のような高度な編集を実現するには、まず関心のあるオブジェクトを特定し、置き換えるオブジェクトのマスクを生成し、元の画像とマスクおよびその位置に生成する新しいピクセルの説明を使用して、画像インペインティングモデル(本研究ではStable Diffusion)を呼び出す必要がある。VISPROGは、必要なモジュールとサンプルプログラムを備えていれば、こうした非常に複雑な命令を簡単に扱うことができる。
このタスクでは知識タグ付けと同様に、関連する画像のないインコンテキストの例を 10 個作成する。
結果
プロンプトサイズの影響
GQAとNLVRでは、インコンテキストの例が多いほど性能が向上することが下図から分かる。

また、NLVRでは、VISPROGの性能はGQAよりも少ないプロンプトで飽和しているが、これはNLVRのプログラムが必要とするモジュールがGQAよりも少なく、それらのモジュールを使用するためのデモがGQAよりも少ないためであると考えられる。
汎用能力
下図は各タスクにおけるVISPROGの結果を示している。
GQAとNLVRではプロンプト戦略を変更した場合の結果を合わせて報告している。また、知識タギングと画像編集ではプロンプトとして与える自然文命令のチューニングを行った場合の結果も報告している。

前者2つではVILTモデルとの比較を行っており、GQAではVILTモデルの性能を上回っている。NLVRでは性能が下回っているが、VISPROGはゼロショットでNLVRタスクを実行するのに対して、VILT-NLVRはNVLRでファインチューニングされているので、VILT-NLVRでの結果は性能の上限の目安であり、VISPROGがそれに近い精度であることがわかる。(GQAの方で精度が上回っているのはVISPROGが利用しているVQAモジュールがVILT-VQAのため)
後者2つでは既存モデルでは単体でこのようなタスクを行えるモデルがないことから特定のモデルとの比較はされていないが、一定のレベルでこれらタスクを実行できることと、命令チューニングによってさらなる性能向上が可能なことを示している。下図はVISPROGの現在のモジュールセットで可能な画像編集の例であり、幅広い操作が可能であることを示している。

視覚的根拠の有用性
VISPROG による視覚的根拠は、失敗例の徹底的な分析を可能にする。
下図は今回の4タスクにおいて約100サンプルずつエラー分析した結果を示している。GQAでは誤ったプログラムがエラーの主な原因であり、サンプルの16%に影響を及ぼしているということを示している。このことから、失敗した問題に類似した、より多くのインコンテクスト例を提供することによって、エラー発生率が改善される可能性があることが分かる。同様にNLVRではVQAモデルをNLVR用のより優れたVQAモデルに置き換えることで、知識タギングや画像編集タスクでは「リスト」と「選択」モジュールの実装に使用されるモデルを改善することで、エラーを大きく減らせると考えられる。

また、下図は視覚的根拠によって明らかになったローカリゼーションエラーが、ローカリゼーションモジュールにとってより良いクエリになるように、ユーザがどのように命令を修正するかを示した例である。(他にも例えば、知識検索のためのより良いクエリを提供することや、Selectモジュールのためのカテゴリ名を提供して、そのカテゴリに属するセグメント化された領域に検索を制限することが含まれる)
実際に知識タギングや画像編集の結果を見ると命令チューニングが性能向上に有効であることがわかる。

今後の課題
VISPROGのような汎用視覚システムの性能をさらに向上させるためにはユーザーのフィードバックを取り入れる新しい方法の研究が必要である。
最後に
本記事では、マルチモーダルAIに関するCVPR2023の論文をいくつかピックアップしてご紹介しました。NTT Comは今までユニモーダルAIの研究開発をメインに取り組んで、自動翻訳サービスCOTOHA Translatorや議事メモ作成をサポートするCOTOHA Meeting Assist、映像解析ソリューションCOTOHA Takumi Eyesといったサービスを展開してきました。今後はChatGPTなどのマルチモーダルAI技術の活用も視野に入れて、実証実験や研究開発を進めていきます。
- Ye, S., Xie, Y., Chen, D., Xu, Y., Yuan, L., Zhu, C., Liao, J. Improving Commonsense in Vision-Language Models via Knowledge Graph Riddles. In CVPR2023.↩
- Xie, C. W., Sun, S., Xiong, X., Zheng, Y., Zhao, D., Zhou, J. RA-CLIP: Retrieval Augmented Contrastive Language-Image Pre-Training. In CVPR2023.↩
- Rasheed, H., Khattak, M. U., Maaz, M., Khan, S., Khan, F. S. Fine-tuned clip models are efficient video learners. In CVPR2023.↩
- Shi, B., Darrell, T., Wang, X. Top-Down Visual Attention from Analysis by Synthesis. In CVPR2023.↩
- Voigtlaender, P., Changpinyo, S., Pont-Tuset, J., Soricut, R., Ferrari, V. Connecting Vision and Language with Video Localized Narratives. In CVPR2023.↩
- Gupta, T., & Kembhavi, A. Visual programming: Compositional visual reasoning without training. In CVPR2023.↩