こんにちは、カケハシのデータ基盤チームでデータエンジニアをしている伊藤と申します。
カケハシでは全社的なデータ活用基盤のプラットフォームとしてDatabricksを採用し、運用して1年以上経過しました。
我々のチームではバッチ/ストリーム処理のDatabricks Workflowを50個以上作成し、分析用データとして社内提供をしております。
ワークフローのデプロイに関しては、Databricks CLIとGitHub Actionsを組み合わせて自前で実装していましたが以下に挙げた課題を感じておりました。
- Databricks CLIに渡すJSON定義を書くことのコストの高さ
- 可読性の低さ
- 冗長なコードの増幅
- Delta Live TablesやPythonタスクの対応
自前のデプロイに限界を感じていた頃、dbxというDatabricks Labsが公開しているDatabricks専用のCLIツールの存在を知り、 我々が感じていた課題を解決してくれたので、今回はdbxを使用したDatabricks Workflowのデプロイについて紹介していきます。
dbxとは
Databricks Labsが開発しているDatabricks専用のCLIツールを拡張し、ワークフロー開発とデプロイを簡素化してくれるオープンソースツールです。 deploy, launchコマンドでワークフローのデプロイと実行処理を抽象化してくれます。
dbxの利点
環境の切り替えが可能
deployコマンドに--environmentオプションを指定することで、workflowをデプロイしたい環境を制御することが可能です。
This command deploys workflow definitions to the given environment.
弊社ではDatabricks Workspaceをdev, prodで分けて運用しているので複数環境にまたがるデプロイ時には活躍してくれます。
deployでワークフローの新規作成/更新に対応
Databricks CLIを使用していた頃は、ワークフローの新規作成/更新の判定を自前のロジックで組んでいたためコードが複雑で可読性が低下していましたが、 dbxでは、Databricks Workflowのデプロイ時に新規作成/更新をよしなにやってくれるので複雑なロジックを組む必要がなくなりました。
冗長性のあるコードの排除
deployコマンドに--deployment-fileでワークフローのジョブ定義を(YAML)渡してあげることができます。
Deployment configuration will be taken from the deployment file, defined in --deployment-file.You can specify the deployment file in either JSON or YAML or Jinja-based JSON or YAML.
YAMLでジョブ定義を書けるので、JSONではできなかった繰り返し項目をAnchorとして定義して継承することで冗長なコードの排除ができます。
Databricks CLIにJSON定義を渡していた時は、環境分だけ定義が複製され、冗長的なコードで溢れていました。
Delta Live Tablesの対応
dbxのデプロイがDelta Live Tablesに対応しています。 Delta Live TablesとUnity Catalogの連携がPublic Previewになり、 社内ではDelta Live Tablesを使用してETL処理を組むのを推奨しているのでdbxのデプロイにDelta Live Tablesがサポートされているというのもdbx導入の決め手の1つでした。
dbxとGitHub Actionsを使用したDatabricks workflow作成の全体像
ワークフローのデプロイをGitHub Actions上で行うときのイメージ図になります。
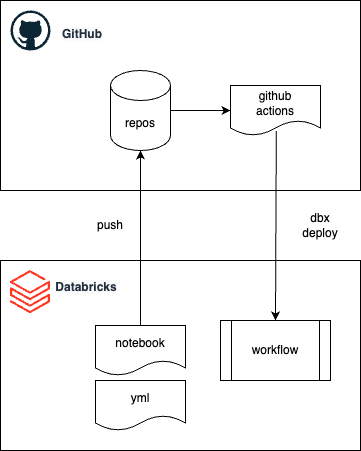
ソースコードとジョブ定義をGitHubにPushすることで、GitHub Actionsが動き、ジョブ定義のYAMLをdbxに渡すことでワークフローをDatabricks Workflowをデプロイします。
ディレクトリ構成
├── .dbx
│ └── project.json
├── .github
│ └── workflows
│ └── dbx_deploy.yml
└── sample
├── deployment_variables.yml
├── deployment_workflow.yml
└── src
└── test_script.py
設定ファイル
dbxを利用するための設定値ファイルでdbx configureコマンドで得られるアウトプットと同じです。
.dbx/project.json
{ "environments": { "dev": { "profile": "dev", "storage_type": "mlflow", "properties": { "workspace_directory": "/Shared/dbx/projects/tmp", "artifact_location": "dbfs:/dbx/tmp" } } }, "inplace_jinja_support": false, "failsafe_cluster_reuse_with_assets": false, "context_based_upload_for_execute": false }
スクリプト
サンプル用に標準出力するプログラムをDatabricksのsharedフォルダー配下に格納します。
print("test")
yml変数
変数群に関しては以下のように別ファイルで管理して、ymlから読み出せるようにしています。
sample/deployment_variables.yml
--- ACCESS_CONTROL: user_name: "service principal id" permission_level: "IS_OWNER" CLUSTER_POLICY_ID: some policy id
ジョブ定義
YAMLの文法に関してはこちらを参考にさせていただきました。
ワークフローに設定するpermissionや、スケジュール設定、クラスター設定、通知先のメールアドレスなど、後続で出てくるworkflowで繰り返し設定するような項目をcustomブロックにanchorとして定義し、workflowsの定義で継承をすることで冗長性を排除しています。 envirnmentsブロックで環境を分けることで複数環境にまたがってデプロイができるようにしています。
sample/deployment_workflow.yml
build: no_build: true custom: ## anchorとして繰り返し項目を定義 access-control: &access-control access_control_list: - user_name: "{{ var['ACCESS_CONTROL']['user_name'] }}" ## 変数の参照 permission_level: "{{ var['ACCESS_CONTROL']['permission_level'] }}" workflow-schedule: &workflow-schedule schedule: quartz_cron_expression: "0 0 9 * * ?" timezone_id: "Asia/Tokyo" pause_status: "UNPAUSED" basic-cluster-props: &basic-cluster-props spark_version: "11.3.x-scala2.12" spark_env_vars: PYSPARK_PYTHON: "/databricks/python3/bin/python3" node_type_id: "md-fleet.xlarge" enable_elastic_disk: false data_security_mode: "SINGLE_USER" runtime_engine: "STANDARD" aws_attributes: first_on_demand: 0 availability: "SPOT" zone_id: "auto" sample-dev-static-cluster: &sample-dev-static-cluster new_cluster: <<: *basic-cluster-props policy_id: {{ var['CLUSTER_POLICY_ID'] }} ## 変数の参照 autoscale: min_workers: 1 max_workers: 2 environments: dev: ## 環境名でデプロイを切り替え workflows: - name: "test_daily_sample_data" <<: *access-control ## anchorで定義した項目の継承 <<: *workflow-schedule no_alert_for_skipped_runs: false tasks: - task_key: "sample_task" notebook_task: source: "WORKSPACE" notebook_path: "/Shared/test_script" ## スクリプトで定義したパスを設定します deployment_config: no_package: true job_cluster_key: "daily_sample_data_cluster" job_clusters: - job_cluster_key: "daily_sample_data_cluster" <<: *sample-dev-static-cluster format: MULTI_TASK
GitHub ActionsのWorkflow
特定のファイルにpushが走った契機でワークフローがデプロイされるようにしています。 処理自体は簡素で、pythonとdbxのセットアップをして、dbx deployコマンドでワークフローをデプロイしています。
これで、特定のファイルに修正が走った時にDatabricksにワークフローがデプロイされるようになります。
.github/workflows/dbx_deploy.yml
--- name: Deploy Workflows on: push: paths: - "sample/**" jobs: dev_deploy: runs-on: ubuntu-latest timeout-minutes: 5 env: DATABRICKS_HOST: "host名" DATABRICKS_TOKEN: "databricks access token" steps: - uses: actions/checkout@v3 - name: Set Up Python uses: actions/setup-python@v4 with: python-version: "3.x" - name: Set Up run: | python -m pip install --upgrade pip pip install dbx dbx --version - name: Deploy Workflows run: | dbx deploy --environment dev --deployment-file sample/deployment_workflow.yml --jinja-variables-file sample/deployment_variables.yml
まとめ
以上、dbxを使用したDatabricks Workflowのデプロイに関して紹介をさせていただきました。 自前で複雑なロジックを組んでいた時とは違って、dbxを導入したおかげで可読性は上がるし、バグは少なくなるしで開発体験が良くなりました。
dbxは大変便利なツールですが一方で参考になる情報がほとんどなく導入時は苦労しましたが、我々と同じような課題を持っている方の解決のご参考になれば幸いです。
今後はdbxに代わり、Databricks Asset BundlesがCI/CDの標準的なベストプラクティスになるので移行を検討中です。
最後に
データドリブンな組織を目指して、一緒に働いてくださる方はぜひ仲間になっていただきたいと思っております。