カケハシでデータサイエンティストをしている島吉です。
こちらの記事は カケハシ Advent Calendar 2023 の4日目の記事になります。
A/Bテストなど、ある2つのグループ(2群)の特徴に差があるのか検証したい場面があります。このとき、t検定などの仮説検定の手法を用いることで、有意差があるかどうかを判定できます。しかし、有意差があると判定されたときの2群間の差が、検証したい差の大きさと一致しているかどうかは、直感的にはわかりにくいと感じることがあります。そこで、仮説検定に代わる方法を調べてみたところ、ベイジアンA/Bテストという方法が見つかったので、それについて紹介します。
ベイジアンA/Bテスト
ベイジアンA/Bテストを用いることで、2群間の差を直感的に解釈できて、扱いやすいということがわかりました。ベイジアンA/Bテストは、さまざまな記事でも紹介されています。この手法は、ベイズ推論を用いることで、2群間の指標の差がどの程度の大きさになるのかを、確率であらわすことができます。たとえば、ある指標の平均値の差が10以上となる確率が90%など。これによって、ある薬を服用した患者・服用しなかった患者の間で検査項目の数値にどの程度の差があらわれたのか検証できたり、チェーン店で何らかの施策を実施した店舗・実施しなかった店舗の間で対象商品の売上にどの程度の差があらわれたのか検証できたりします。
ベイズ推論の手法とライブラリ
ベイズ推論の手法と、実装するためのライブラリを紹介します。ベイズ推論では、事前分布と尤度から事後分布を求めます。このとき、マルコフ連鎖モンテカルロ法(MCMC:Markov Chain Monte Carlo methods)を用いることで、複雑なモデルの事後分布を推論できます。MCMCを実装するためのライブラリは、さまざまなものが存在しますが、今回はPythonでNumPyroを使用しました。
ベイズ推論をサンプルデータに適用
乱数からサンプルデータを生成し、ベイズ推論を用いて2群間の差を検証したところ、平均値の差がどのくらいの大きさで分布しているのか、わかりやすい結果が得られました。プログラムの実装は、こちらの記事を参考にしました。
インストール
pip install numpyro
ライブラリのインポート
import numpyro import numpyro.distributions as dist from numpyro.infer import MCMC, NUTS from jax import random import numpy as np import math import matplotlib.pyplot as plt import seaborn as sns
乱数を用いたサンプルデータ生成
# 平均値が300、標準偏差が100の正規分布(サンプルサイズ100) np.random.seed(seed=1) data_A = np.random.normal(loc=300, scale=100, size=100) # 平均値が400、標準偏差が150の正規分布(サンプルサイズ100) np.random.seed(seed=2) data_B = np.random.normal(loc=400, scale=150, size=100)
モデルの定義
- 事前分布:今回は無情報事前分布として、一様分布を設定しました。
- 尤度関数:正規分布や指数分布、ベルヌーイ分布など、さまざまな確率分布から、観測データに合わせて適切なものを選択します。今回は正規分布を使用しました。
def model(data_A, data_B):
# 事前分布は一様分布を選択
loc_A = numpyro.sample("loc_A", dist.Uniform(-1000, 1000))
scale_A = numpyro.sample("scale_A", dist.Uniform(0, 1000))
loc_B = numpyro.sample("loc_B", dist.Uniform(-1000, 1000))
scale_B = numpyro.sample("scale_B", dist.Uniform(0, 1000))
# 平均値の差を定義
delta = numpyro.deterministic("delta", loc_B - loc_A)
# 尤度関数は正規分布を選択
with numpyro.plate("N_A", len(data_A)):
numpyro.sample("obs_A", dist.Normal(loc_A, scale_A), obs=data_A)
with numpyro.plate("N_B", len(data_B)):
numpyro.sample("obs_B", dist.Normal(loc_B, scale_B), obs=data_B)
MCMCで事後分布を推論
- MCMCを実行する際、引数に事後分布のサンプリング数などを指定します。
# サンプルデータの事後分布を求める mcmc = MCMC(NUTS(model), num_warmup=1000, num_samples=10000, num_chains=3) mcmc.run(rng_key=random.PRNGKey(seed=0), data_A=data_A, data_B=data_B) mcmc_samples = mcmc.get_samples() mcmc.print_summary()
平均値の差の事後分布のヒストグラムをプロット
- 平均値の差が所定の値(今回は50)以上となる確率を算出します。
# 平均値の差が閾値以上である確率を算出
threshold = 50
delta = mcmc_samples["delta"]
prob_greater_than_threshold = (delta>=threshold).mean()
# ヒストグラムをプロット
sns.set_style("darkgrid")
g = sns.displot(delta[delta>=threshold], binwidth=1, binrange=(threshold, math.ceil(max(delta))), color="red", alpha=0.5, edgecolor="none", label=f"Delta>={threshold}: Prob={prob_greater_than_threshold:.2f}")
g.map(sns.histplot, data=delta[delta<threshold], binwidth=1, binrange=(math.floor(min(delta)), threshold), color="blue", alpha=0.5, edgecolor="none", label=f"Delta<{threshold}: Prob={1-prob_greater_than_threshold:.2f}")
plt.xlabel("Delta")
plt.legend()
このようにベイズ推論のプログラムを実行することで、下の図のように、2群間の平均値の差がどのくらいの大きさで分布しているのか、直感的に知ることができました。具体的には、平均値の差の事後分布が50以上になる確率が94%という結果が得られました。
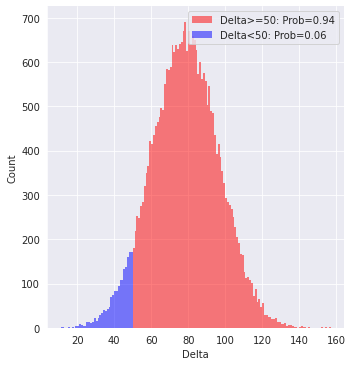
また、numpyro.diagnostics.hpdi()を使用することで、最高事後密度区間(HPDI:Highest Posterior Density Interval)を求めることもできます。今回、numpyro.diagnostics.hpdi(delta, 0.95)のように実行することで、平均値の差の事後分布のうち95%が[43.69〜114.77]の範囲に存在することがわかりました。
まとめ
ベイジアンA/Bテストについて調査し、実際に使用してみることで、以下のことがわかりました。
- ベイジアンA/Bテストを用いることで、2群間の差の大きさを直感的に解釈できる。
- 検証するデータに合わせて、事前分布や尤度関数に適切な確率分布を設定する必要がある。