こちらの記事はカケハシ Advent Calendar 2023 Part2の17日目の記事になります。
はじめに
こんにちは、株式会社カケハシのデータサイエンティストの保坂です。
2023年9月より、これまで2つに分かれていたデータサイエンス系メンバーの属するチームが合併し、医薬品サプライチェーン事業およびPatient Engagement事業を担うPharma Divisionにおける横断データサイエンス組織となりました。さまざまなバックグラウンドや経験を持った方が集まったそれなりの規模の組織になってきているので、組織が小規模だった頃と比べて分析プロセスに関する考え方の違いが課題となることが増えてきました。それに伴い、組織共通なものとしていくことも想定して、一部のプロジェクトで分析プロセス・ルールを整備し始めたので、その一部をご紹介したいと思います。
横断データサイエンス組織ができるまでの経緯や背景についても近いうちにご紹介したいと思っています。
整備したルール
分析結果のデータやノートブック置き場を共通化する
カケハシではDatabricksを導入しており、ほとんどの分析をDatabricks上で行うので、横断データサイエンス組織用のワークスペース、Unity Catalogを設けてデータやノートブックを一元管理するようにしました。 Unity Catalogにデータを格納する際には、データの有用性・品質に応じて以下のようにデータベースを分けて管理するようにしています。
- 長期で使っていくもの(プロジェクトごと)
- 一時的なものだが他メンバーに共有するもの(プロジェクトごと)
- 個人用
Databricks社が提唱し、カケハシのデータ管理方針でも採用しているメダリオンアーキテクチャと似た考え方なので、今後そちらに統合していきたいと考えています。
分析のゴールに向けた議論が円滑に行えるような状況共有を行う
組織の統合に合わせて、一部のプロジェクトでは機械学習エンジニア職1 と データサイエンティスト職2 のメンバーが協力し合いながら分析を進めたり、1つの分析プロジェクトにより多くの人が関わるようにしました。
これまでより幅広い視点で意見を出し合ったり、議論が行われるようにするためにそうしたのですが、分析の背景や前提条件の確認に割かれる時間が増え、分析のゴールに向けた重要な議論に充分に時間を割くことができなくなることがわかってきました。
そこで、分析のゴールに向けた議論が円滑に行えるようにするために、共有すべき分析内容をルールとしてまとめることにしました。
- 背景・経緯・分析のゴール
- 分析内容サマリ
- 分析詳細
- 相談事項
- 結論・想定のネクストアクション
また分析詳細については以下のような情報を共有するようにし、他のメンバーも分析の妥当性や別の解釈の可能性を判断しやすくしました。
- 分析条件
- 利用テーブル
- データ期間
- フィルタリング・除外条件
- アウトプット説明
- アウトプットテーブル
- 利用ノートブック・クエリのURL
- データ件数
- 指標/列の定義
- 可能なら数式も
- 考察・わかったこと
データ分析においてはさまざまな加工を行って指標を作ることがありますが、日本語で加工内容を表現すると曖昧さが残ってしまう事が多いので、若干手間も増えるものの、数式も共有していこうとしています。たとえば集約処理では、どのような粒度の情報をどんな軸に渡って集約するのかを日本語で曖昧さなく表現するのは意外と大変だと思うのですが、数式であれば一目瞭然とできるかと思います。
- 日本語による表現の例: 各処方箋に含まれる各医薬品の処方量を集約し、日毎、医薬品毎の処方量の最大値を計算する
- 数式による表現の例: $ Y_{ 医薬品, 日付 } = \max_{ 処方箋 } ( a_{ 処方箋, 医薬品, 日付 } ) $
一部のメンバーで議論した内容は、他のメンバーにも認識齟齬のない形で共有する
プロジェクトでは基本的には全メンバーの集まるスタンドアップや、定例ミーティングで議論しながら分析を進めていきますが、一部のメンバーによる分科会を開いて詳細な議論をすることがあります。分科会での議論の内容や結論を他のメンバーに適切に共有できるように、以下の様なルールを設けました。
- 分科会の議事録を作成し、参加者内で認識齟齬や情報の不足がないことを確認する
- 全メンバーの集まるミーティングで改めて議事録を共有し、要点を簡単に説明する
スタンドアップや定例ミーティングの議事録は作成されているものの、分科会は少人数で比較的気軽に行うものであったためそれを作らないこともありました。しかし参加者毎に少し結論の認識齟齬がある場合があったり、結論だけでなく議論の経緯も含めて共有したほうが良い場合があったので、分科会でも議事録を取って共有することにしました。
データと論理的な推論を併用して仮説検証を高速化する
最後のものはやや抽象的ですが、プロジェクト内で発生するさまざまな仮説検証を高速かつ判断のミスなく行うための考え方を整理しています。
データサイエンスにおける仮説は、以下の様な構造をしていると考えることができます。
- 将棋の探索木のように仮説が木構造をしているが、木の構造は未知である
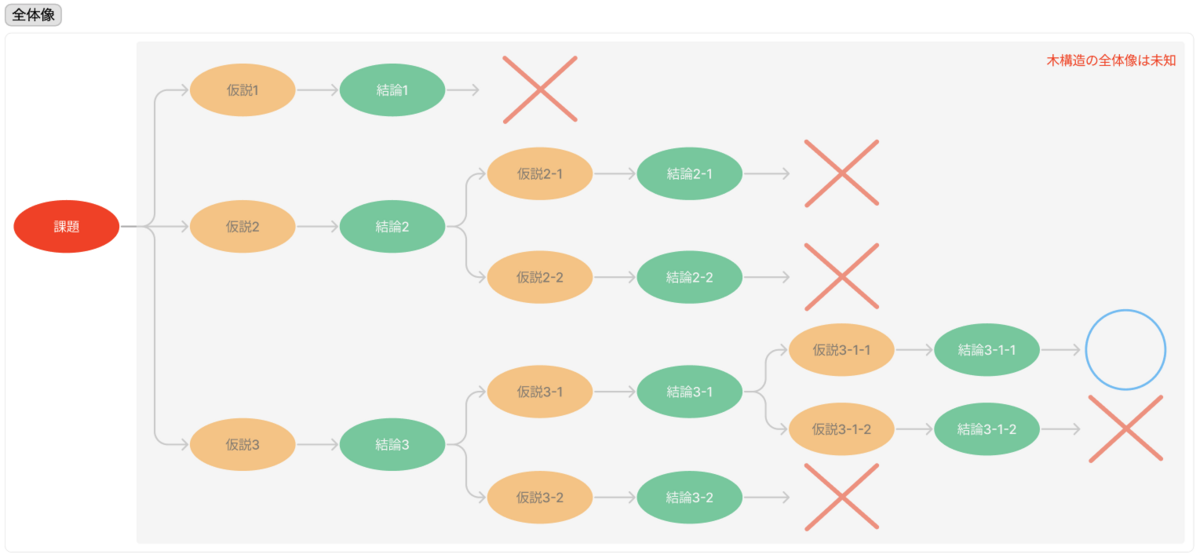
また、データサイエンスにおける仮説検証は、以下の様なプロセスと考えることができます。
- 仮説検証は、仮説の立案による木の構造の推測と仮説の良し悪しの評価を行いながら具体的な施策に至る葉を探していくこと
- 仮説の良し悪しの評価には、データ分析に基づく評価以外にもドメイン知識による評価や論理に基づく評価がある
- ドメイン知識による評価や論理に基づく評価は、明らかに良くない仮説を高速に判断するのに向いている一方、これらでは判断できないことやもある
- データ分析に基づく評価はデータがある事柄なら幅広く正確な評価ができる一方、手間が大きいことがある


これまでの分析ではstep1において候補となる仮説を充分に出さずに先に進んでしまう事があったり、step2において論理に基づく評価により高速な判断ができる場面でそれが活用できなかった場合があったので、以下のようなルールを設定しました。
- 仮説の候補は論理的、ドメイン知識的に導ける範囲で網羅的に出す
- ドメイン知識による評価や論理に基づく評価をできるだけ活用して、すべてを手間のかかり得るデータ分析に基づく評価にしない
まとめ
横断データサイエンス組織の共通的なものとしていくことを想定し、分析プロセス・ルールを整備し始めたので、その一部をご紹介しました。
色々とルールを決めると手間が増えたり堅苦しくなるかと思い、はじめはあくまで提案としていましたが、他の方々も賛同してくれ、ルールに則って情報共有をしてくれるようになりました。さらに、チームメンバーから新たなルールの拡充を提案いただくこともあり、チームを良くするために皆さんが積極的に行動してくれるとても良いチームだと感じています。
またこれにより、互いの成果物が一元的に蓄積、共有されるようになり、本質的な議論の時間を増やすことができていて、チームの生産性や意思決定の質が向上していると感じています。
これからデータサイエンス組織を立ち上げたり拡大していこうとされている方のご参考になれば幸いです。