こんにちは。XI 本部 AIトランスフォーメーションセンター所属の山田です。
本記事は「 電通国際情報サービス Advent Calendar 2023 」の12月19日(火)の回の記事になります。
私たちのチームでは、データベースAzure CosmosDB for MongoDB (RU) を採用したアプリケーション開発を行っています。
開発を進める中でつまづいたり失敗も多く「使う前に知っていれば苦労しなかったのに…」と思うことが何度かありました。
そこで本記事では「失敗から学ぶ Azure Cosmos DB for MongoDB (RU) の歩き方」と題して、それらの内容を紹介したいと思います。
- 前提 Azure CosmosDB for MongoDB (RU) とは?
- Azure CosmosDB の NoSQL API について知っておこう
- Azure CosmosDB の公式ドキュメントの読み方について知っておこう
- サーバレスとプロビジョニングされたスループットの違いを把握しておこう
- RU/s の制限はデータベース単位とコレクション単位が存在することを知っておこう
- サポートされていない命令や制限があることを知っておこう
- Azure CosmosDB for MongoDB の拡張コマンドについて理解しておこう
- バックアップポリシーを慎重に検討しよう
- O/Rマッパーは障壁となる場合があることを理解しておこう
- シャーディングによるRUの制限および容量の制限を知っておこう
- コレクション設計は慎重にしておこう
- 診断設定とフルテキストクエリは有効にしておこう
- $explain コマンドについて知っておこう
- まとめ
前提 Azure CosmosDB for MongoDB (RU) とは?
前提の話になりますが、Azure CosmosDB は複数の API をサポートしているフルマネージドのデータベースサービスです。
Azure Cosmos DB for MongoDB はAzure Cosmos DBのAPIのひとつで、Azure Cosmos DBをMongoDBデータベースのように操作するものになります。
このAzure Cosmos DB for MongoDBには「RUベースのアーキテクチャ」と「vCoreベースのアーキテクチャ」の2種類が存在しており、本記事では「RUベースのアーキテクチャ」を扱います。本記事ではこちらをAzure Cosmos DB for MongoDB (RU) と表記しています。
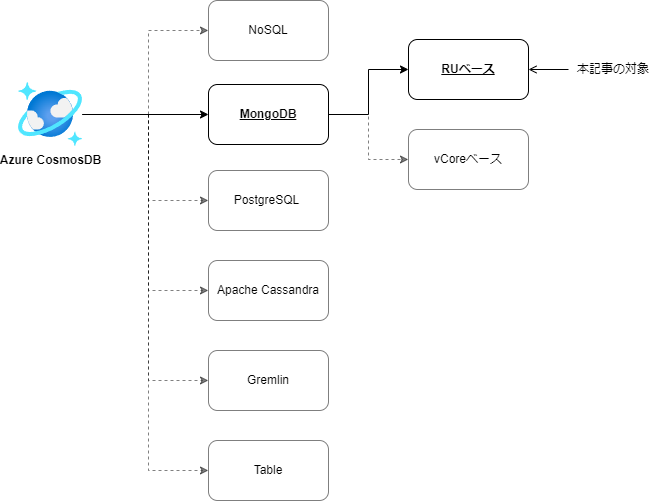
以下からは、本題である Azure Cosmos DB for MongoDB (RU) をプロダクションで使うにあたって、知っておけばよかったことや注意点などを経験をもとに記載しています。
Azure CosmosDB の NoSQL API について知っておこう
Azure Cosmos DB for MongoDB (RU) について扱うと述べたのに、なぜ NoSQL APIの話が出てくるのか疑問に思われた方もいるかもしれません。
しかしこれには事情があります。NoSQL API は Azure ComsosDBのネイティブ実装であり、Azure CosmosDBの特徴的な機能は、NoSQL APIをベースに実装されています。
Azure Cosmos DB for MongoDB (RU) は Azure CosmosDB for NoSQL を MongoDB の API を通して操作できるラッパーのようなものであり、Azure CosmosDB for NoSQL について知っておくことで仕様や制限についてより理解できます。
そのため、Azure CosmosDB for NoSQL のドキュメントも一通り確認しておくことを強くおすすめします。
また Azure CosmosDB for NoSQLについては、Microsoftの資格試験「DP-420: Microsoft Azure Cosmos DB を使用したクラウドネイティブ アプリケーションの設計と実装」が用意されているので、こちらの資格取得を通してキャッチアップをするのもよい方法です。
重要なのは、Azure Cosmos DB for MongoDB (RU) が純粋な MongoDB の実装ではなく、 Azure CosmosDB for NoSQL をベースとした実装であることを知っておくことで仕様への理解が進むということです。
Azure CosmosDB の公式ドキュメントの読み方について知っておこう
Azure CosmosDB は API ごとに使える機能の違いが存在します。
Azure CosmosDB の機能として紹介されている場合でも、選択した API によってはサポートされていなかったり、他のデータベースシステムでサポートされていると思っているものが Azure CosmosDB ではサポートされていなかったりといったことがあります。
こういった違いを開発者が把握するために、Microsoft の公式ドキュメントの各ページでは、サポート対象の API が以下のように記述されています。
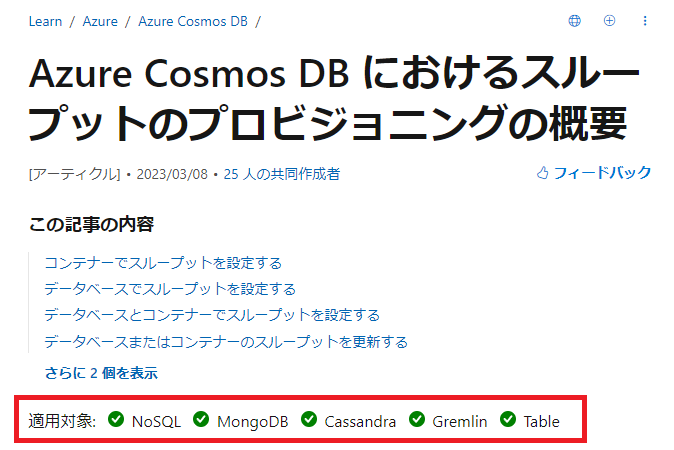
[スクリーンショット元記事] Azure Cosmos DB のコンテナーとデータベースにスループットをプロビジョニングする | Microsoft Learn
機能について調査を実施する場合は、ドキュメントのこの箇所を必ずチェックをするようにしましょう。
サーバレスとプロビジョニングされたスループットの違いを把握しておこう
Azure CosmosDB for MongoDB (RU) では、リソース作成時に容量モードを「サーバレス」と「プロビジョニングされたスループット」から選択する必要があります。
2つの容量モードは料金形態だけでなく、配置できるリージョンやストレージにも違いがあります。
この2つのモードはリソース作成後に変更できないため、事前に仕様について理解をしておく必要があります。
サーバレス
サーバレスは消費したRU量に応じてコストが発生する完全な従量課金モデルになります。
サーバレスモードを利用する場合、Azure CosmosDBは1つのAzureリージョンにしかデプロイできません。
また1つのコレクションに保存できるデータ量の最大値は1TBになります。
プロビジョニングされたスループット
プロビジョニングされたスループットでは、あらかじめ設定したスループット値に応じてコストが発生する課金モデルになります。
プロビジョニングされたスループットモードは、複数のAzureリージョンにデプロイ可能で、コレクションあたりに保存できるデータ量にも制限がありません。
スループット値は「手動」と「自動スケール」の2つがあり、手動の場合は400RU/sから、自動スケールの場合は1,000RU/sから設定ができます。
自動スケールの場合は、設定したスループット値の10%刻みでスケーリングが瞬時に行われます。
例えば、自動スケールでスループット値を最大 4,000RU/s とした場合は、400RU/s ~ 4,000RU/sの間でスケーリングが行われることになります。
また「手動」と「自動スケール」ではRU/sに対する料金が異なり、自動スケールでは1時間あたりの100RU/sに対する課金額が手動スケールの価格の1.5倍になります。
自動スケールでは、スループット値に対する10%分は定常的な課金が発生するので、スループット値に大きなRU/sを設定すればするほど定常的に支払うコストが高くなる点は要注意です。
RU/s の制限はデータベース単位とコレクション単位が存在することを知っておこう
プロビジョニングされたスループットの容量モードで Azure CosmosDB を利用する場合、スループットとして設定する RU/s の制限はデータベース全体と各コレクションの2つがあります。
データベース全体で RU/s の設定をする場合は、設定したデータベースに含まれるコレクションすべてで利用可能な RU/s が共有されます。これはスモールスタートしたプロジェクトで必要なコレクションの数の見積もりが難しい場合などに有効な設定です。
データベース全体で RU/s の設定をする場合は、特定のコレクションが過剰に RU を消費していると全体のスループットにも影響を及ぼすので注意が必要です。
コレクション単位で設定する場合は、各コレクション個別に RU/s を割り当てできるため、各コレクションのアクセスパターンに応じて最大のパフォーマンスが得られるように配分できます。
一方、コレクション単位に設定をする場合、新しいコレクションを作成する際に追加でスループット値を割り当てる必要があるため、コレクション数が増えるのに応じて定常コストが増加することになるため注意が必要です。
サポートされていない命令や制限があることを知っておこう
Azure CosmosDB for MongoDB(RU) でサポートされている MongoDB の命令には制限があります。
サポートされている命令などは以下のドキュメントで確認できます。
多くの命令が網羅されている印象はありますが、現状では特に集計コマンドについては制限が大きいです。
私たちはアプリケーションで集計処理を実装するユースケースがあったのですが、集計パイプラインの$lookup演算子が使えない問題に直面しました。この部分はfindクエリを複数回、発行することで回避しています。
Azure CosmosDB for MongoDB の拡張コマンドについて理解しておこう
先に MongoDB のコマンドの中でサポートされていないものがあると説明しましたが、逆にAzure CosmosDB for MongoDB 固有の拡張コマンドも存在します。
実はAzure CosmosDB for MongoDB の機能をフルに活用するためには、この拡張コマンドについて理解する必要があります。
例えば、コレクションの作成時にコレクションに対してスループットを割り当てたりシャードキーの指定などの操作は拡張コマンドからしかできません。
| # | コレクション作成コマンド |
| MongoDB のネイティブコマンド | |
| CosmosDB の MongoDB 拡張コマンド | |
その他に純粋な MongoDB であれば、コレクションの作成とインデックスの作成は別々に行いますが Azure CosmosDB for MongoDB ではコレクション作成時にインデックスの指定ができます。
バックアップポリシーを慎重に検討しよう
バックアップポリシーには「定期的なバックアップ」と「継続的なバックアップ」の2つがあります。
「定期的なバックアップ」と「継続的なバックアップ」の大きな違いとしてデータ復旧方法があります。
「定期的なバックアップ」の場合、データ復旧のためには Azure サポートにチケットで依頼をする必要がありますが、「継続的なバックアップ」の場合はユーザー自身でデータ復旧を実施できます。
これだけ聞くと「継続的なバックアップ」の方が魅力的に思えるかもしれませんが、現状は「継続的なバックアップ」を利用する場合には機能的な制限があるので慎重に検討しておく必要があります。
Azure CosmosDB for MongoDBのバックアップポリシーに「継続的なバックアップ」を利用する場合、コレクションに対し、ユニークキーインデックスを後から追加することはできません。
O/Rマッパーは障壁となる場合があることを理解しておこう
アプリケーションからデータベースにアクセスする際に、O/Rマッパーを使いたいと考える開発者は多いと思います。
Azure CosmosDB for MongoDB(RU) の場合、安易に MongoDB の O/Rマッパーを使うと問題に直面する場合があります。
O/Rマッパーで、コレクションの作成やインデックス定義が行われる場合、通常の MongoDB の命令が裏で発行され、Azure CosmosDB 側に送られます。
命令は先の拡張コマンドではないため、Azure CosmosDB 側で実施したい設定と競合する、あるいは命令が通らずに失敗するといったことが起きます。
少なくとも、データベースの作成操作、コレクションの定義、インデックスの定義の操作については、Azure CosmosDB 拡張コマンドで行うことを強くおすすめします。
シャーディングによるRUの制限および容量の制限を知っておこう
Azure CosmosDB ではシャーディングによる分割によって、コレクションのスケーリングを実現しています。
コレクション内のシャーディングはコレクションのシャーディングキーによって分割されます。
シャーディングキーの値によって、ドキュメントは論理パーティション(シャード)に振り分けて保存がされます。
この1つの論理パーティションに保存できるデータは20GBという制約があります。
NoSQL API を利用する場合は、パーティションキー(シャーディングキー)を選択しなければコンテナ(コレクション)の作成ができないのですが、MongoDB API を利用する場合、シャーディングキーなしにコレクションを作成できます。
シャーディングキーがないコレクションの場合、コレクションは1つの論理パーティションにのみ保存されるためコレクションに保存されるデータ量は20GBに制限されます。
またスループットについても制限があり、シャーディングキーがないコレクションの場合、スループットに設定可能なRUは10,000RU/sという制限を受けることになります。これは論理パーティションよりも背後にある物理パーティション側の制約になりますが、1つの物理パーティションで提供可能なスループットが10,000RU/sでありシャーディングが行われない場合は、全てのデータは1つの物理パーティションにのみ保存されるため、この制限を直接受けることになります。
コレクション設計は慎重にしておこう
先に述べたシャーディングによるRUや容量の制限があることを考慮しながらコレクションを慎重に設計しましょう。
例えば、会社情報を保存するコレクション「companies」の設計をする場合を考えてみます。
各会社の所在地の国「country」をシャードキーにする場合、以下の画像のような形でデータが保存されます。
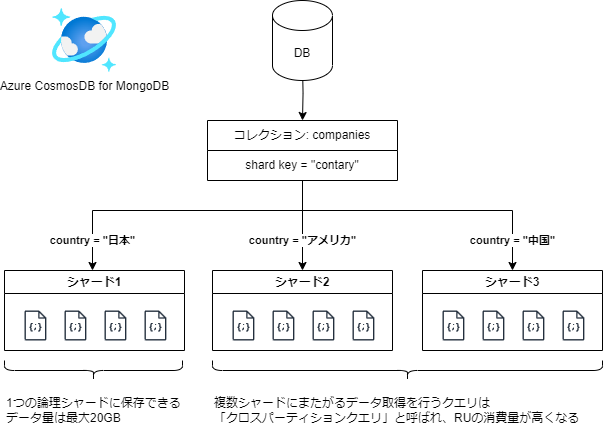
アプリケーションの要件によってはこの設計でも問題がないかもしれませんが、この設計は1つの国に20GBを超える会社情報がないことを仮定しています。
また国ごとにデータ数の偏りがあるため、特定のパーティションのデータ量が肥大化するホットパーティション問題のリスクもあります。
その他に複数の国をまたがってクエリをするユースケースがある場合、この設計だとクロスパーティションクエリによって RU の消費量が大きくなります。
このように比較的単純なデータでもコレクション設計を始めると悩むポイントがそれなりにあります。
時間を費やしすぎないためにもコレクション設計において気をつけるべきポイントを持っておくことが重要です。
私なりに意識するポイントを言語化しておくと以下のような観点になります。
- クエリパターンや保存するデータの特定を考慮してシャーディングキーを適切に選択しておく。
- シャーディングキーは後から追加することができないので十分にスケーリングできるように設計をしましょう。
- アプリケーションから発行するクエリパターンを把握しておくことでクロスパーティションクエリの発生を抑えることができます。
- ユニークインデックスの設計しておく。
- バックアップポリシーで「継続的なバックアップ」を選択した場合、後からユニークインデックスを追加することや変更することができないため先に設計をしましょう。
- 設計ミスをした際のプランを考えておく。
- どんなに避けようとしても設計ミスが起きることはあります。適切な設計パターンに対応するためのデータ移行方法を模索しておくのも重要です。
診断設定とフルテキストクエリは有効にしておこう
Azure CosmosDB for MongoDB ではフルテキストクエリを有効にすることで、すべてのクエリをログに記録できます。
少なくとも開発中は診断設定でフルテキストクエリを有効にして、診断設定から Log Analytics ワークスペースに流すように構成することをおすすめします。
フルテキストクエリを有効にすると Log Analytics ワークスペースではPIICommandText列で発行された具体的なクエリを見ることができるため、アプリケーションで発行されているクエリパターンの分析やスロークエリの発見ができます。
$explain コマンドについて知っておこう
先に診断設定とセットで問題となるクエリの分析方法を把握しておく必要があります。
Micorosfot の公式ドキュメントによると、Azure CosmosDB では RU の消費量が50を超えるかをスロークエリの大まかなガイドラインとしているようです。
Log Analytics を見て、RU の消費量が50を超えるクエリに対しては分析を行うようにしましょう。
この分析には MongoDB の $explainコマンドを利用します。
なお Azure CosmosDB for MongoDB での$explainコマンドで得られる結果は純粋な MongoDB とは異なるので注意が必要です。
実際の分析方法については以下の公式ドキュメントが参考になるため、ここでは紹介しませんが、$explainコマンドを使って分析をすることで、足りないインデックスを把握するなど改善のためのヒントを得ることができます。
まとめ
本記事では「失敗から学ぶ Azure Cosmos DB for MongoDB (RU) の歩き方」と題して、Azure Cosmos DB for MongoDB (RU) をプロダクションで使うにあたって知っておけばよかったことや注意点などを紹介しました。
本記事で紹介した内容のほとんどは公式ドキュメントにも記載されているのですが、実際は失敗するまでそれらの存在に気付かないことが多くあることを痛感しました。
なお Azure Cosmos DB for MongoDB (RU) は適切に設計を行った上で利用できれば、非常に高いスケール性能を得られるのでメリットを享受できるように使いこなしていきたいですね。
また純粋な MongoDB との違いも多いので、純粋な MongoDB を Azure で利用したい場合は、最近 GA された仮想コアベースの「Azure Cosmos DB for MongoDB (vCore)」の利用を検討するのが良いでしょう。
本記事の内容が何かの参考になれば幸いです。
執筆:@yamada.y、レビュー:寺山 輝 (@terayama.akira)
(Shodoで執筆されました)



