こんにちは、株式会社カケハシのデータサイエンティストの保坂です。
データ分析をやっていると、典型的な処理、よく使う処理を再度使い回せるようにしたり、他のメンバーに共有したくなることはないでしょうか?さらにこのような処理を適宜みんなが自由に拡張でき、デグレがないようになっていたらどんなに良いことでしょう。 カケハシのデータサイエンティストはDatabricksを使って多くの分析業務を行っているので1、これがDatabricksの中だけで実現できれば、データサイエンティストにとってとても便利な環境になるのではないか?と考え、試行錯誤してみた結果、ごく簡単なものですがやりたいことを概ね実現できる環境を作ることができたので、ご紹介いたします。
なぜDatabricksだけで実現したいのか?
改めて実現したいことを列挙します。
- 典型的な処理、よく使う処理を再度使い回せるようにしたり、他のメンバーに共有したい
- 誰でも処理を自由に拡張できるようにしたい
- デグレが起こらないようにしたい
これを実現しようとすると、真っ先にGitHubを使う方法が思い浮かびます。具体的には以下の様なものです。
- GitHubにリポジトリを作成し、典型的な処理、よく使う処理のコードをバージョン管理する
- GitHubフローのような方法でコード修正を行い、Pull Requestを出してコードレビューを受けてからマージする
- GitHub Actionsで自動テストを行い、コードのデグレが起きていないことをチェックする
しかし私は、GitHubによるコード管理はシステム開発においては理想的な方法だと思いますが、データサイエンティストやその主な業務であるデータ分析においては、必ずしも理想的なものではない場合があると感じています。以下その理由を挙げます。
データサイエンティストはGitHubの利用経験がない・少ないことがある
データサイエンティストの中にはGitHubを使わない業務に従事されている・いた方も多くいらっしゃいます。 とくにビジネスサイドに近いご経験の方はそういったことが多いのではないでしょうか。
実際カケハシのデータサイエンティストの中にもそのような方がいらっしゃいます。そういった方々がGitHubを使わずとも上記の様なことが実現できると嬉しいです。
あくまで試行錯誤や分析のための道具の管理なので、GitHubによる開発フローは負荷が大きい
品質をおろそかにするつもりはないが、GitHubよりはややスピード感や柔軟性を重視した環境のほうがデータサイエンティストにとっては合っているのではないかということです。
たとえば、データ分析を通じてわかったことによって次にやるべきことが大きく変化するので、作っていたものが丸ごと不要になることがあったり、まったく思っても見なかった形で拡張する必要が出てくることがあります。そのため不確実性の高い状況では極力手間をかけずに管理できることが望ましいです。 とはいえある程度分析が進んでくると、それまでに行ってきた分析を土台として次の分析を行う事が増えてくるので、土台となる分析のコードはよりしっかりとした管理に移行したいです。さらにツールを使い分けることなくシームレスにしっかりとした管理に移行できると最高です。
分析のプロセスがどんなふうに進んでいくか?については、こちらの記事 の「データと論理的な推論を併用して仮説検証を高速化する」のセクションでイメージ図を掲載しているので、そちらもご覧ください。
作った環境の構成図
Databricks WorkspaceとDatabricks Jobsを用いて以下のような環境を作りました。
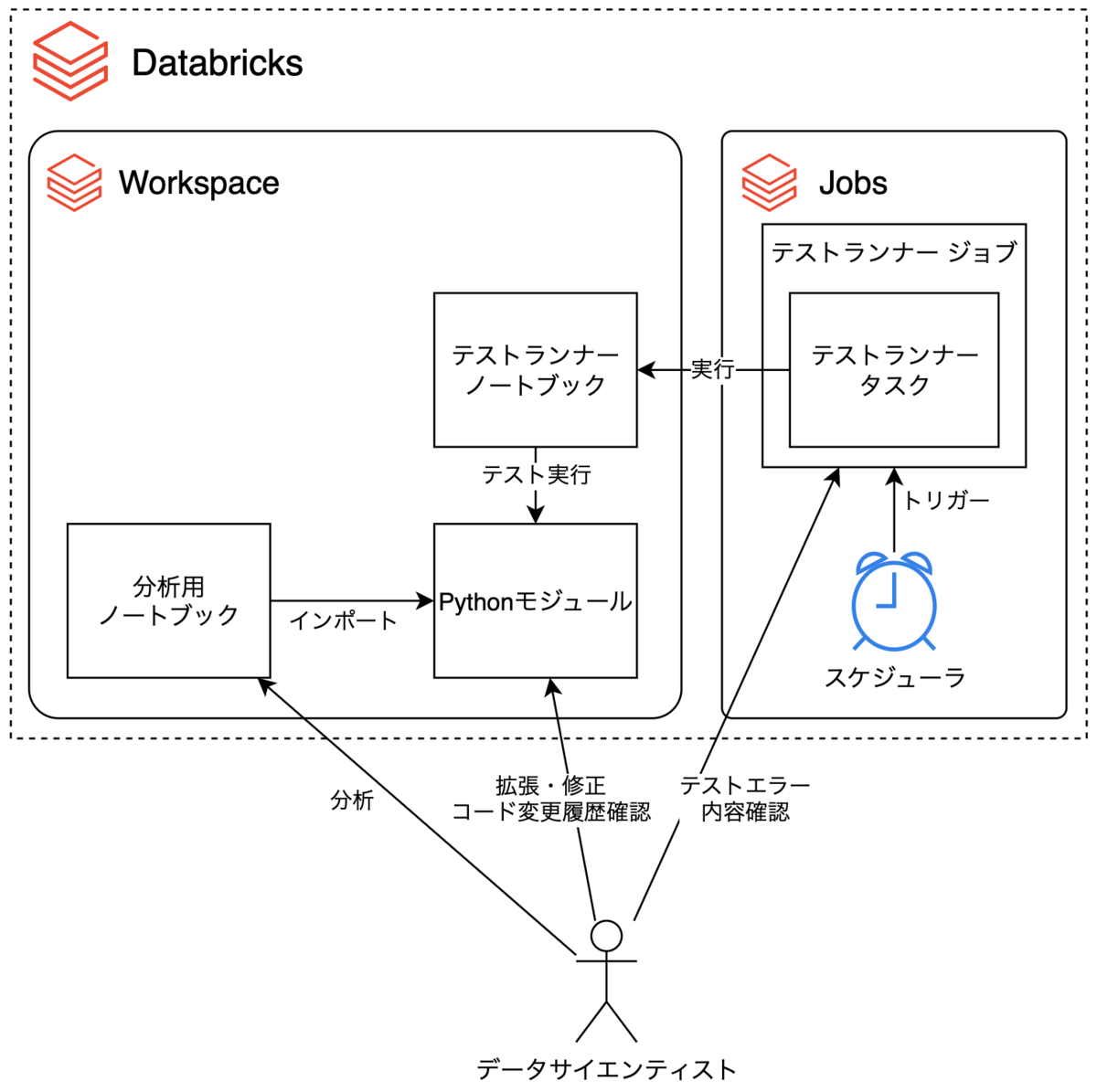
また、Workspace内には以下のようなディレクトリ構成でファイルを作成、配置しました。
|
+--notebooks
| +--hosaka
| | +--analysis <-- 分析用ノートブック
| +--nakao
| +--nakagawa
| ...
+--team_library
+--__init__.py
+--src
| +--__init__.py
| +--util.py
+--tests
+--__init__.py
+--test_util.py
+--test_runner <-- テストランナーノートブック
なお、Databricks上でpytestによりテストを行う方法については、こちら の記事を大変参考にさせていただきました。
できること
この環境を使うことで、データサイエンティストは以下の様なことを行う事ができます。
- ノートブックで分析するときに、共有のPythonモジュールをインポートして利用することができる
- 共有のPythonモジュールに機能を追加したり、修正したりすることができる
- 定期的に単体テストが実行され、失敗したテストの詳細を確認することができる
- テスト失敗の原因となった可能性のあるモジュールへの変更を確認する事ができる
環境の構築方法
分析用ノートブックからの共有モジュールの利用
分析用ノートブックからの共有モジュールを利用する部分について説明します。
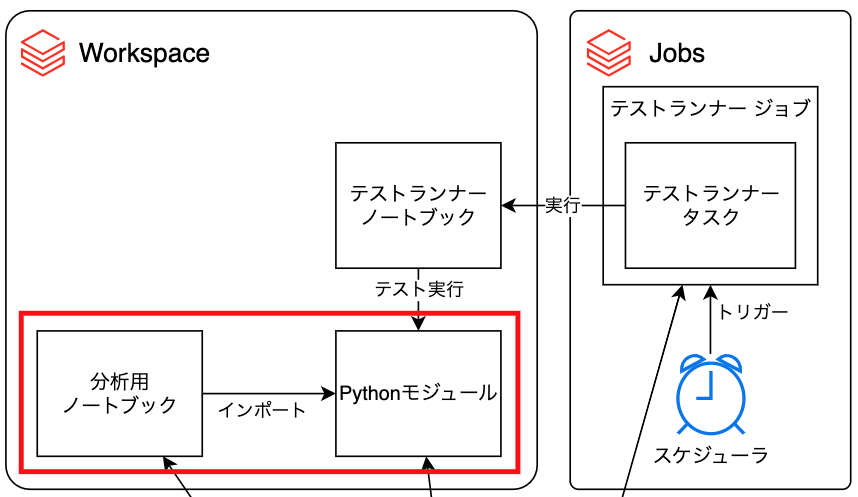
共有Pythonモジュールの作成
team_library/src/util.pyにチームで共有するPythonモジュールを作成します。この記事では、ごく簡単な関数mysumを例として定義しておきます。
from numbers import Number from typing import Iterable def mysum(numbers: Iterable[Number]) -> Number: s = 0 for num in numbers: s += num return s
分析用ノートブックの作成
notebooks/hosaka/analysisに分析用ノートブックを作成し、チーム共有のPythonモジュールにある関数をインポートして利用します。
内容がやや複雑なので、ノートブックのセルごとに分けて説明します。
モジュールサーチパスへの共有Pythonモジュールパスの追加
モジュールサーチパスに共有Pythonモジュールのパスを追加して、インポートが行えるようにします。 この例ではDatabricksの機能を利用してノートブックのパスを取得し、その相対パスとして共有Pythonモジュールのパスを表しています。このようにすることでモジュールのパスをノートブックにベタ書きする必要がなくなり、ディレクトリ名の変更に強くなります。
import sys import os # 開いているノートブックのパスを取得 notebook_path = dbutils.notebook.entry_point.getDbutils().notebook().getContext().notebookPath().get() prj_root = '/Workspace' + os.path.dirname(os.path.dirname(os.path.dirname(notebook_path))) sys.path.append(prj_root)
共有Pythonモジュールのインポート
共有Pythonモジュールからmysum関数をインポートします。分析の最中にモジュールへの修正、リロードを行う事があるかもしれないので、autoreload エクステンションを有効にしています。
%load_ext autoreload %autoreload 2 from team_library.src.util import mysum
モジュール関数の呼び出し
モジュールからインポートした関数を呼び出します。
mysum([100, 200, 300])
ノートブックからのpytestの実行
ノートブックからpytestを実行する部分について説明します。
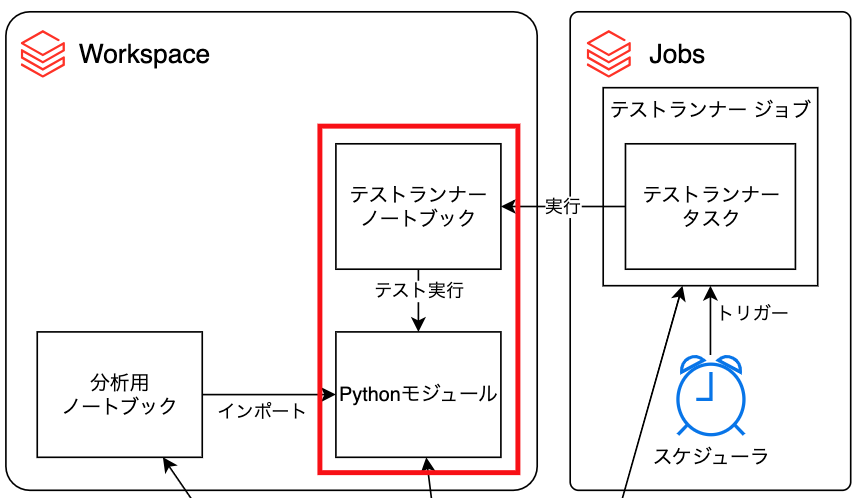
共通モジュールの単体テストの作成
team_library/tests/test_util.pyに共有モジュールの単体テストを作成します。
from team_library.src.util import mysum def test_mysum_int() -> None: assert mysum([1, 2, 3]) == 6 def test_mysum_float() -> None: assert mysum([1.0, 2.0, 3.0]) == 6.0 def test_mysum_empty_list() -> None: assert mysum([]) == 0.0
テストを実行するノートブックの作成
team_library/tests/test_runnerにテストを実行するノートブック(テストランナーノートブック)を作成し、単体テストを実行させるようにします。
内容がやや複雑なので、ノートブックのセルごとに分けて説明します。
pytestパッケージのインストール
単体テストを実行させるために必要となるので、pytestパッケージをインストールします。
-qオプションを指定しておくとインストール時のメッセージが出力されないので、ノートブックの出力をきれいに保つことができます。
%pip install pytest -q
モジュールサーチパスへの共有Pythonモジュールパスの追加
モジュールサーチパスに共有Pythonモジュールのパスを追加して、インポートが行えるようにします。
import sys import os notebook_path = dbutils.notebook.entry_point.getDbutils().notebook().getContext().notebookPath().get() lib_path = '/Workspace' + os.path.dirname(os.path.dirname(notebook_path)) prj_root = lib_path + "/.." sys.path.append(prj_root)
.pycファイルの生成の抑制
Pythonはモジュールのインポート時にそれをコンパイルし、モジュールと同じディレクトリの __pycache__ ディレクトリに書き込みます。次回モジュールインポートを高速化するためです。
しかしノートブックからDatabricks Workspaceにファイルを書き込むことはできないようになっているようで、pytestからテスト対象モジュールをインポートする際にエラーが出てしまいました。

そのためpytestの実行前に.pycファイルの生成を抑制しておきます。
import sys sys.dont_write_bytecode = True
テスト対象モジュールのインポート
テスト対象モジュールとそのテストモジュールを事前にインポートしておきます。
参考にさせていただいた記事 ではこのような処理は行われていなかったのですが、私の環境では事前にこの処理を行っておかないとpytest実行時にモジュールがロードできないエラーが発生したため、この処理を入れています。
%load_ext autoreload %autoreload 2 import team_library.src import team_library.tests
pytestによる単体テストの実行
pytestを呼び出して単体テストを実行させます。
import pytest retcode = pytest.main([lib_path, '-v', '--pyargs', '--doctest-modules']) assert retcode == 0, "テスト失敗"
pytest.main関数は実行した単体テストの一部が失敗したとしても例外を発生させませんが、
次にご紹介するテストランナージョブのためには、テストが失敗した際には例外が出るようになっている必要があります。
そこで、pytest.main関数の返り値によりテストの成否がわかることを利用して、テストが一部失敗した場合には例外が発生するようにしています。
Databricks Jobsを用いたテストランナージョブの作成
この構成ではテストランナージョブが定期的にテストランナーノートブックを実行し、自動テストを実現しています。このセクションではテストランナージョブの作成方法について説明します。
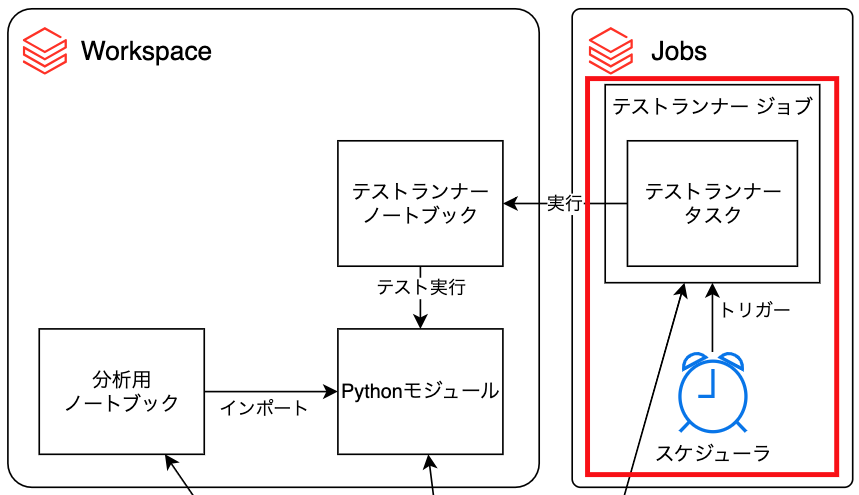
テストランナージョブの作成
Databricks Jobsの画面からジョブ作成を行うと、以下の様な画面が表示されます。 ジョブの中にテストランナーノートブックを実行するタスクを追加します。
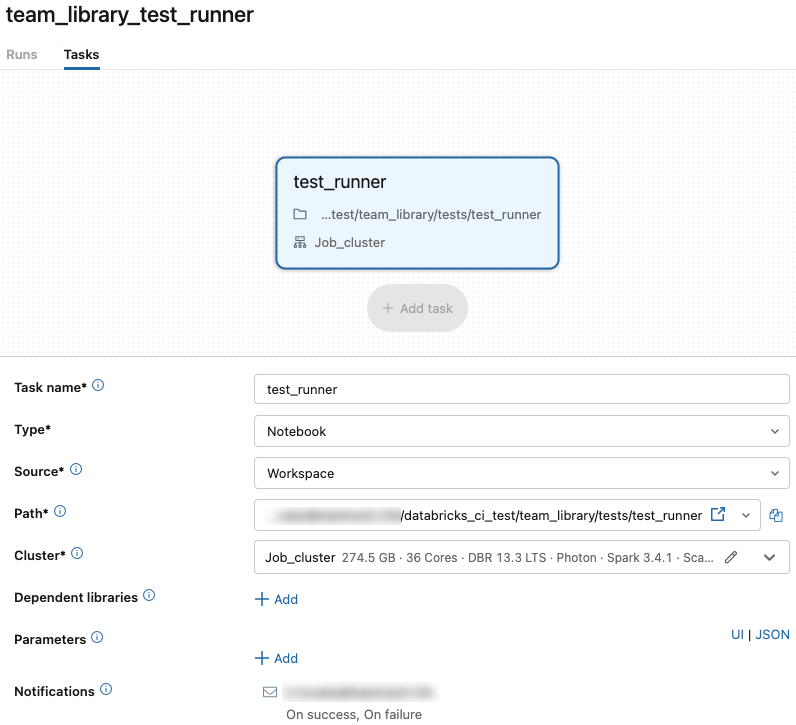
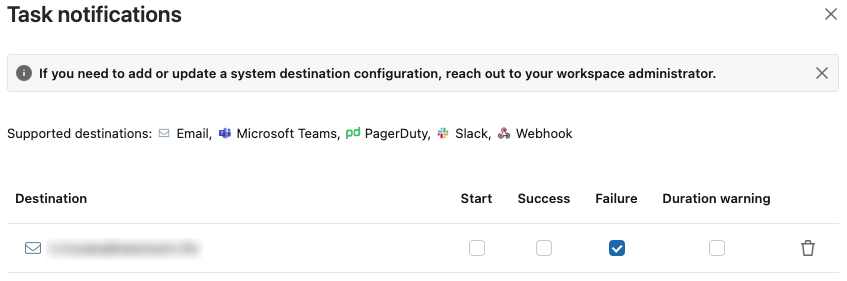
Notificationの設定で、テストの実行に失敗した際に通知を送る設定を行います。 この例ではメールによって通知する設定を行っていますが、他にもいくつかの方法に対応しているので、好みのものをご利用ください。
作成したジョブを保存したあと、ジョブのスケジュール設定で定期的にジョブが実行されるように設定します。

使い方
ユースケース毎にこの環境の使い方をご紹介します。
関数の追加、修正
team_library/src/util.pyに関数を追加したり、既存の関数を修正したりします。
team_library/tests/test_util.pyを編集してテストの追加、修正も忘れずに行います。team_library/src/util.pyにdoctestによるテストケースを作成してもよいでしょう。
def mysum(numbers: Iterable[Number]) -> Number: """渡されたリストの合計値を計算する関数 intとfloatが混ざっていたら返り値はfloatになる >>> mysum([1, 2.0, 3]) 6.0 """ s = 0 for num in numbers: s += num return s
テストの実行
テストランナージョブはスケジューラによる定期実行だけでなく、手動実行もサポートしているので、共有ライブラリを修正したらテストランナージョブを手動実行します。

テスト失敗原因の調査
テスト実行に失敗すると、設定した通知先に通知が届きます。

通知に含まれるリンクからエラー詳細画面を開くことができ、どのテストケースでエラーが発生したか確認できます。 エラー詳細画面にはテスト実行日時が記載されているので、これを覚えておきます。
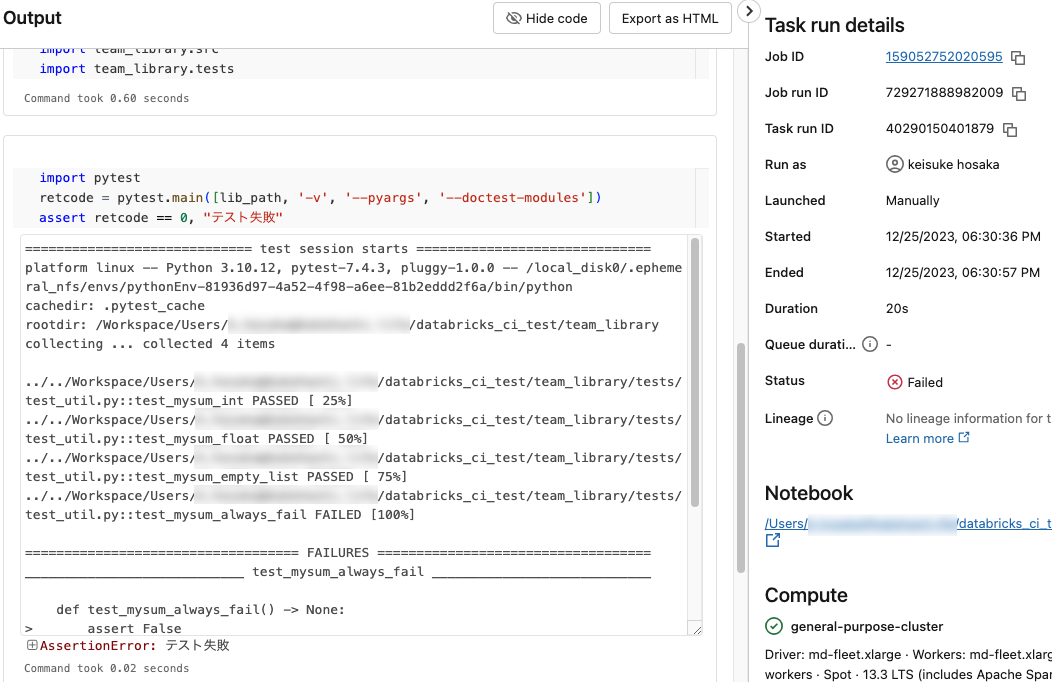
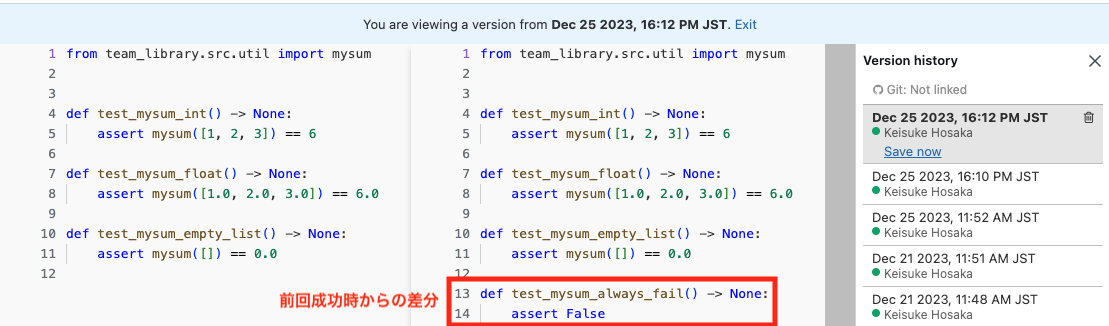
前回成功したテスト実行日時と、失敗したテスト実行日時の間に行われた変更によりエラーが混入した可能性が高いので、その間に行われた変更を確認します。 エラーに関連するファイルを開き、コードバージョン履歴の画面を表示させます。これを使っていつ頃のコード修正でエラーが混入したのかを調べる事ができます。
まとめ
GitHubを使わずDatabricksだけで以下の様なことを実現できる簡単な環境とその作り方をご紹介しました。
- 典型的な処理、よく使う処理を再度使い回せるようにしたり、他のメンバーに共有したい
- 誰でも処理を自由に拡張できるようにしたい
- デグレが起こらないようにしたい
GitHubに慣れていないデータサイエンティストがいらっしゃるが、品質を保ちやすい形でデータ分析におけるコード・処理の共有をしていきたい場合には有効な方法ではないかと思います。
また、今回環境構築を行ってみて、データ分析に必要な機能が直感的に使える形でオールインワンに搭載されているDatabricksだからこそできることだと感じました。引き続き色々とDatabricksを触ってみて、よりデータ分析がやりやすくなるように模索していきたいと思います。