
はじめに
2023年10月の1ヶ月間、AI事業本部、極予測AI予測チームで CA Tech Job というインターンシッププログラムに参加させていただきました東京大学大学院情報理工学研究科修士1年の武智將平(@shoheiKU)です。普段の研究では機械学習を利用した予測モデル構築やデータサイエンスのようなことをしています。今回のインターンシップで研究では出会うことの少ない、機械学習モデルをサーバーに組み込む場合の手法や並列化について触れることができました。この記事では Apache Beam を利用した並列化及び、Tensorflow の SavedModel というサービングに適した保存形式について触れます。
タスクについて
極予測AI予測チームはクリエイティブデザインから広告効果を予測する機械学習モデルを構築し、サービスとして提供するチームです。 タスクスタート時点での問題点として 広告テキストの量が多い場合、テキストの特徴量変換が画像処理に比べて時間がかかることがありました。 時間的ボトルネックであることに加えて、計算を回すためのコストの面でも問題となっていました。 高速化に向けた改善手法として現状 Apache Beam の DoFn API で実装されている予測パイプラインのコンポーネントを RunInference API に置き換えることを考え、その実装に取り組みました。
Apache Beam
Apache Beam とは基本的なデータ処理の並列化を行える SDK を提供するオープンソースプロジェクトです。Apache Beam の基本思想として
- PCollection: データセットを In-memory データのように利用できるようにしてくれるもの。
- PTransform: 1つの PCollection を入力として受け取り、データを各 element ごとに処理し、その結果を PCollection に返すパイプラインの演算処理。
があります。 DoFn や RunInference API も PTransform の一つです。 これらを利用して Pipeline を構築し処理を記述していきます。 Python、 Go、 Javaなど様々な言語で SDK が提供されており、Pipeline を記述できます。 また並列化実行環境として Apache Flink、 Apache Spark、 Google Dataflow などを利用することができます。 ローカル環境で実行もできるためテスト実行も容易にできる点も魅力だと思います。 機械学習のためにも利用できます。
SavedModel
RunInference API を使う上で問題になった Tensorflow SavedModel について説明します。 機械学習モデルを利用する場合に Python を利用できる環境でなかったり、他の言語によってバックエンドが構築されている場合は多くあります。 このような Python 環境に依存しない推論システムを提供するため SavedModel は利用されます。 Python上で利用することに加えて Tensorflow Serving のようなサービングシステム、 Rust や JavaScript など別言語からの利用も可能です。
SavedModel で直面した問題
基本的にサービングのための保存形式であるため、 Python 上で読み込んでしたとしても元の Tensorflow モデルとは基本的に異なります。 そのため次のようなことが起こります。 モデルを SavedModel として保存し、再び読み込んでも同じ呼び出しが使えないといったことが起こっています。 以下例として、HuggingFace の TFBertModel を利用します。
import tensorflow as tf
from transformers import TFBertModel
model_name = "bert-base-uncased"
saved_model_path = "saved_model/bert_base_uncased"
input_ids = tf.cast([[8667, 27688, 3169, 1592, 11549, 1291, 106]], dtype=tf.int32)
# read a model from HuggingFace
model = TFBertModel.from_pretrained(model_name)
output = model(input_ids)
# save the model
model.save(saved_model_path)
# read the model again from SavedModel
saved_model = tf.keras.models.load_model(saved_model_path)
output2 = saved_model(input_ids) # error occurs
エラーの原因
根本的にはモデルクラスが完全には一致していないからということになります。 SavedModel には関数の呼び出し情報に signature_def や Concrete Functions の input 情報を使います。 ここで input 情報として Python のモデルとして保持されていた情報が SavedModel のために自動的に定式化されておりここでは Default 引数などに合わせていくつかの Option が作成されています。 自動で作成された __call__ 関数の signature_def の shape が (None, 5) となっており (バッチ数, input_id の次元) です。 自動で作成された signature_def の shape の推論が失敗しており、この関数に対して (1, 7) の input_id を入れることでエラーとなっています。 本来ここでは (None, None) もしくは (None, input_id より十分大きい固定長) であるべきです。
解決方法
serving_default を利用する。serving_default に対してデータを投げると正しく実行してくれます。 ここでも shape は (None, 5) なので shape 自体は異なりますが option が他にないため正しく動きます。 気になる場合は saved_model を作成するときに signature_def として定義を与えることができます。 以下 WA (Work Around) です。
saved_model_path = f"path/to/saved_model"
input_ids = tf.cast([[8667, 27688, 3169, 1592, 11549, 1291, 106]], dtype=tf.int32)
model = tf.saved_model.load(saved_model_path)
output = model.signatures["serving_default"](input_ids)
ParDo と RunInference
Apache Beam の変換(Transform)に関連するAPIになります。ParDo (Parallel Do) API は一般的な変換を提供するAPIです。RunInference API は予測モデルに特化した並列化を提供するAPIです。 RunInference API ではモデル解釈性を高めてリソース利用を最適化し、PyTorch や TensorFlow など様々なフレームワークで使えます。 ともに推論を提供することができ、今回は前者で実装済みの推論コンポーネントを後者すなわち RunInference API に変更します。
以下にサンプルコードを示します。 モデルは先程保存した SavedModel を利用します。
ParDo
import apache_beam as beam
import tensorflow as tf
class Inference(beam.DoFn):
def __init__(self, model_path):
self.model_path = model_path
def setup(self):
self.model = tf.keras.models.load_model(model_path)
def process(self, element):
yield self.model.signatures["serving_default"](tf.reshape(element, [1, -1]))
if __name__ == "__main__":
model_path = "path/to/saved_model"
text_num = 1000
with beam.Pipeline() as pipeline:
(
pipeline
| "Create input data"
>> beam.Create(
[
tf.constant([8667, 27688, 3169, 1592, 11549, 1291, 106])
for _ in range(text_num)
]
)
| "Inference" >> beam.ParDo(Inference(model_path))
| beam.Map(print)
)
RunInference
import apache_beam as beam
from apache_beam.ml.inference import utils
from apache_beam.ml.inference.base import RunInference, PredictionResult
from apache_beam.ml.inference.tensorflow_inference import TFModelHandlerTensor
import tensorflow as tf
from typing import Any, Dict, Iterable, Optional, Sequence
def custom_inference_fn(
model: tf.Module,
batch: Sequence[tf.Tensor],
inference_args: Dict[str, Any],
model_id: Optional[str] = None,
) -> Iterable[PredictionResult]:
predictions = model.signatures["serving_default"](tf.stack(batch), **inference_args)
return utils._convert_to_result(batch, predictions, model_id)
if __name__ == "__main__":
model_path = "path/to/saved_model"
text_num = 1000
with beam.Pipeline() as pipeline:
(
pipeline
| "Create input data"
>> beam.Create(
[
tf.constant([8667, 27688, 3169, 1592, 11549, 1291, 106])
for _ in range(text_num)
]
)
| "Inference"
>> RunInference(
TFModelHandlerTensor(
model_path,
inference_fn=custom_inference_fn,
)
)
| beam.Map(print)
)
batch データを stack せずにモデルにいれる場合は次のように inference_fn を変更します。 一つのサンプルが複数のテキストを持つ場合などサンプル単位で batch が構成されていてその構造を壊したくない場合などに利用が考えられます。
def custom_inference_fn(
model: tf.Module,
batch: Sequence[tf.Tensor],
inference_args: Dict[str, Any],
model_id: Optional[str] = None,
) -> Iterable[PredictionResult]:
results = []
for data in batch:
predictions = model.signatures["serving_default"](
tf.reshape(data, [1, -1]), **inference_args
)
results.append(predictions)
return utils._convert_to_result(batch, results, model_id)
速度比較
input データは “Hello CyberAgent World!” をトークン化した list を1000個並べたものです。 ParDo と RunInference(stack なし) と RunInference(stack あり) の3つを比較します。 今回は Python backend で実行し、それぞれ10回実行し最大、最小、平均を報告します。
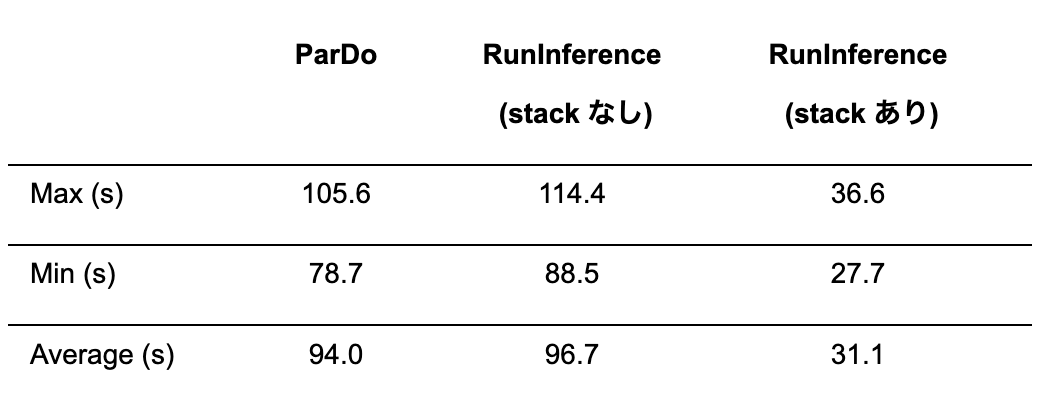
結果として ParDo と RunInference の API 自体の実行速度の差はほぼなく、batch による高速化の恩恵が大きいことがわかります。 上述した通りリソース管理の最適化により RunInference API を利用する場合はクラスター上で実行した時特に恩恵を受けます。 実際のマネージドクラスターで実行した時には、stack なしの場合であっても ParDo API の所要時間よりも短くなっています。
最後に
今回のインターンシップとしてはわからないことが多くかなり苦戦したという印象です。 サービングのためのモデル管理などは特に研究で触れることが一切ないため知識のキャッチアップを含めかなり時間がかかっていまいました。 自然言語処理やサービングについて触れられたことは非常に良い経験でしたし、ユーザーにサービスとして提供するための分散システム、学習パイプラインなど非常に勉強になることが多かったです。
メンターさんを始め、チームの方々には暖かく受け入れていただき、非常に多くのサポートを頂きました。 ここで改めて感謝を述べさせていただきます。