

機械学習 (ML) は、短期間のうちに多くの企業で欠かせない存在となりました。ほぼすべての業界で瞬く間に ML の導入が進んだのは、企業の戦力を大きく強化できるからです。新しいデータが届いたらすぐに学習して理解できるうえ、過去のデータは新しいツールや手法で見直すことができます。ML はデプロイ後も成長し、対応するユースケースを拡大しさらに多くのデータを取り込んでいきます。この際、ML モデルを最新の状態に保つ作業、新しいデータでトレーニングする作業、修正して再トレーニングしたモデルをテストする作業が技術チームの重荷にならないようにする必要があります。
このチュートリアルでは、このような ML ワークフローを自動化する継続的インテグレーション (CI) パイプラインの作成方法について説明します。説明に使うサンプルプロジェクトは、自動化したワークフローを使用してモデルの作成、トレーニング、テスト、パッケージ化を行うものです。本チュートリアルでは、このワークフローを複数のステージに分解し、ML コードに変更を加えたときに各ステージがトリガーされるようにします。また、オンサイトのハードウェアを増強することなく、クラウドホスト型の GPU リソースを使用して ML ワークフローをスピードアップさせる方法についても説明します。—
次回の記事では、ML モデル向けの継続的デリバリー (CD) パイプラインの設定を取り上げ、デプロイの自動化とスケジュール設定や、ML システムの監視と再トレーニングについて説明する予定です。
CI の概要および CD を ML モデルとワークフローに役立てる方法
ML ワークフローは、データを収集するデータプラットフォームと分析システム、データを受け取ってシステムに保存するデータパイプライン、データを使用できるように整えて準備するユーザーやプロセスなど、いくつもの要素から成り立っています。これらの要素を揃えたら、ML モデルの出力が専門家の観点で有用なものになるまで、データを使ってトレーニングを何度も繰り返します。これは、人間と人工知能の両方が協力し、互いが互いの能力を強化し合う生命体のようなものです。
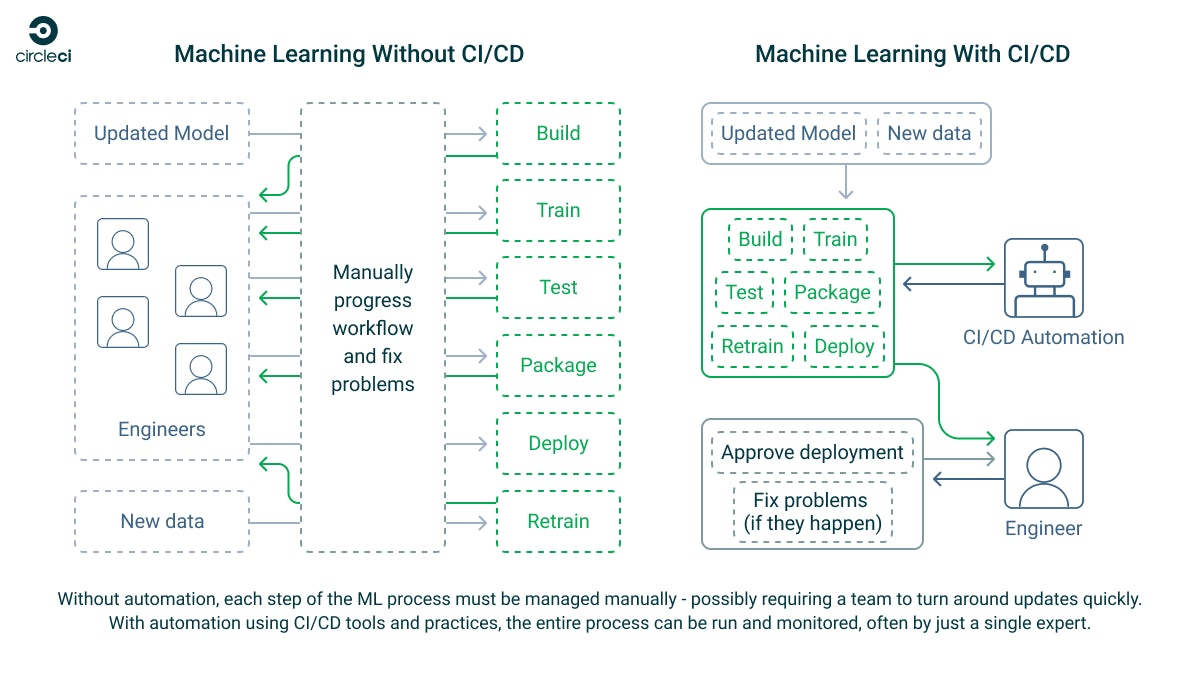
ML システムの効果は、適切な MLOps 手法を実践できるかどうかにかかっています。 MLOps は、今ではソフトウェア開発の基礎となっている、定評のある DevOps 手法から生まれたものです。モデルの品質とモデルから得られる結果は、そのトレーニングと再トレーニングの速度、およびトレーニングに使うデータの品質に左右されます。これらの速度と品質はいずれも、CI/CD パイプラインを実装して ML ワークフローを管理することで、大幅に向上させることができます。
CircleCI は、ML 開発でよくある課題を解決できる、ML ワークフローの自動化に最適な CI/CD プラットフォームです。CircleCI は柔軟であり、ユーザー独自のパイプラインを作成できます。パイプラインではほとんどすべてのタスクを、クラウド上にホストされ任意の OS とソフトウェアが稼働するマネージド実行環境で実行することも、および セルフホストランナーによりローカルハードウェアで実行することもできます。Git を基盤にしているため、CI/CD パイプラインを既存のツールと統合できます。プロジェクトに CircleCI コンフィグファイルを追加すれば、すぐに自動化を始められます。
サンプルユースケースシナリオ: TensorFlow の画像認識 ML ワークフロー

このチュートリアルの目的は、ML タスクを自動化する CI/CD パイプラインの作成方法を説明することであり、ML モデルの作成方法は扱いません。手順をシンプルにするために、TensorFlow が用意しているサンプル ML ワークフローを使用します。このサンプルのコードでは、Keras と MNIST のサンプルデータを使用して画像を識別するモデルを作成し、モデルをテストし、パッケージ化します。 このチュートリアルのパート 2 にて、パッケージ化したモデルを利用するために TensorFlow Serving にデプロイし、テストし、再トレーニングするワークフローを作成します。
実際に使用するツールと ML ワークフローはみなさんのユースケースごとに異なると思いますが、ここで説明する CI/CD 手法はどのような ML システムにも当てはめることができます。どの ML プラットフォームで実行する場合でも、システムがどれほど複雑でも、ワークフローをステップに分解して、CircleCI で自動化できます。
サンプル ML ワークフローと CircleCI パイプライン
サンプルコードを詳しく確認したい方は、このチュートリアル用のリポジトリをご覧ください。リポジトリには、以下に示すとおり、ML ワークフローを手動で構成し実行するために必要な手順とスクリプトに加え、そのプロセスを自動化する CircleCI コンフィグファイルが含まれています。
- ml ディレクトリ: いくつかの Python スクリプトに分割されたサンプル ML ワークフローが含まれています。
- これらのスクリプトを実行するには、デプロイサーバーの詳細を指定した .env ファイルをプロジェクトのルートディレクトリに配置する必要があります。リポジトリには、このファイルのサンプルが用意されています。
- tools ディレクトリ: ML ワークフローを実行するための環境設定、ワークフローのローカルテスト、TensorFlow Serving サーバーの構成に使用する各種 Bash スクリプトが含まれています。
- .circleci ディレクトリ: ML スクリプトを呼び出す CircleCI パイプラインを定義した CircleCI
config.ymlが含まれています。
前提条件とインストール手順
このチュートリアルの自動 ML パイプラインをビルドするには、以下のものが必要です。
- CircleCI アカウントとプロジェクト
- CircleCI の導入方法と使い方については、CircleCI クイックスタートガイドをご覧ください。
- このチュートリアル用のサンプルリポジトリをお使いの GitHub アカウントでフォークし、CircleCI プロジェクトのベースにしてください。
- CircleCI セルフホストランナー
- ローカルマシンを使用するか、規模の大きなワークロード用に自動スケーリングデプロイに組み込む形でセットアップしてください。
- このチュートリアルのサンプルリポジトリのコードは、Ubuntu 22.04 でテスト済みです。
- CircleCI のマネージドクラウドコンピューティングリソース (GPU を含む) を利用してもかまいません。
- トレーニングしパッケージ化したモデルを保存する SSH アクセス対応サーバー
- モデルをここにアップロードして保存し、後で TensorFlow Serving にパブリッシュします (このチュートリアルのパート 2 で説明します)。
- ランナーがネットワーク上のこのマシンにアクセスできる必要があります。
Python の依存関係
このサンプルの ML スクリプトは Python で書かれています。
ランナーに、Python、pip、Python venv が必要です。これらをインストールするには、Ubuntu で次のターミナルコマンドを実行します。
sudo apt install python3 python3-pip python3-venv
ML スクリプトの手動テスト
ml ディレクトリのスクリプトをローカルで実行してテストする場合、README の「Test this project locally」セクションの手順に従って仮想環境と必要なパッケージをインストールします。なお、このリポジトリのスクリプトは、すべてのコマンドをプロジェクトのルートディレクトリから実行することを前提としています。
ML ワークフローを構築する
ML ワークフローを自動化するうえで重要なのは、ワークフローを複数のステップに分解することです。こうすると、各ステップを順番に呼び出したり、ステップが相互依存していない場合は並列に実行したり、各ステップの結果を監視したりできます。エラーが発生した場合も、自動的にロールバックや再トレーニングを行い、担当のチームメンバーに対応を求める通知を送ることができます。
このチュートリアルのベースになっている TensorFlow のサンプルは、元は 1 つの Python スクリプトとして記述されたものですが、今回は自動化のために以下の複数のスクリプトに分割してあります。
1. データの準備
これは、あらゆる ML ワークフローに含めるべき重要なステップです。データ処理に取りかかる前にはその内容を理解しなければならず、データを活用する前にはデータから異常値を除外しなければなりません。
ML モデルが正しく動作していることを確認できないと、モデルが効果的であるとは言えません。ML モデルのテスト用にあらかじめ内容を把握して整理したデータがなければ、モデルの精度を確認できません。さらに、モデルのトレーニングや再トレーニングに使用する信頼の置けるデータソースも必要です。
2.構築
ML モデルの構築プロセスは、データの収集、検証、調査に加え、分析しインサイトを得るプログラムの構築という、複数のステップから成ります。
このサンプルでは、構築ステップで一定量のデモデータをインポートして準備し、次のステップで行う既存の Keras Sequential モデルのトレーニングに備えます。 実際のシナリオでは、独自のデータを用意することになります。
このステップ用の Python コードは ml/1_build.py にあります。
3.トレーニング
このステップでは、入念に準備した、結果のわかっている高精度のデータをモデルに与え、学習を開始させます。そのためには、構築ステップのトレーニングデータを使用します。
スクリプトはできる限り出力を詳細にし、有益な情報を得られるだけ得られるようにすることをお勧めします。コンソールへの出力は、CircleCI の Web インターフェースのログで表示できるので、簡単に監視とデバッグができます。
このステップ用の Python コードは ml/2_train.py にあります。
4.テスト
サンプル ML ワークフローで使用するトレーニングデータは、内容をすでに十分理解したものです。そのため、この既知の結果とトレーニングしたモデルの出力を比較することで、モデルの精度を確認できます。
チュートリアルのスクリプトでは、1_build.py で構築したトレーニングデータと比較して精度を確認します。精度が不十分な場合、例外がスローされて、CI/CD パイプラインが停止し、オーナーに通知が届きます。
このステップ用の Python コードは ml/3_test.py にあります。
5.パッケージ化
パッケージ化ステップでは、トレーニングしたモデルを別の環境で使用できるように準備します。具体的には、標準的な形式でエクスポートして移植可能にし、他の場所にデプロイして使用できるようにします。その後、後で使用するためにパッケージのステージング環境にアップロードします。
このサンプルでは、SSH 接続を使用してリモートサーバーにファイルをアップロードします。ML パイプラインをクラウド上だけで実行し、内部ネットワークの資産へのアクセスを禁止する場合は、AWS S3 Orb を使用して ML アーティファクトを CircleCI のクラウドコンピューティングリソースと自前のインフラストラクチャの両方がアクセスできる場所に保存します。
このステップ用の Python コードは ml/4_package.py にあります。
CircleCI の CI/CD で ML モデル構築を自動化する
ML プロセスを分解して、ワークフローを実行するためのスクリプトを作成したら (または、今回のサンプルのスクリプトをコピーしたら)、それを GitHub にパブリッシュして CircleCI プロジェクトとしてインポートします。
CircleCI コンフィグファイル
CircleCI コンフィグファイルのパスは .circleci/config.yml です。このファイルでは、コマンド、ジョブ、ステップ、ワークフローをそれぞれ定義し、自動 ML システムを構築します。サンプルの CircleCI コンフィグファイルには、テストと構築が可能な、完全に機能する自動 ML システムが含まれています。このサンプルコンフィグファイルで実行する機能を、以下に示します。
このコンフィグファイルの check-python コマンドは、CircleCI 実行環境でターミナルコマンドを実行する方法を示しています。このコマンドが失敗した場合、コマンドを呼び出したジョブとワークフローも失敗し、エラーが CircleCI に送信されて、オーナーに通知が届きます。
commands:
check-python:
steps:
- run:
command: python3 --version
name: Check Python version
コマンドはジョブ内で複数回再使用することも、1 回限りのステップとすることもできます。以下の install-build ジョブは、他の ML スクリプトを実行するための環境を準備しています。プロジェクトコードをチェックアウトし、前に定義した check-python コマンドで Python がインストールされているかどうかを確認した後、create-env コマンドを実行して必要なコンフィグファイルを作成します。そのうえで、Python 依存関係をインストールする一連のコマンドを実行した後、ML パイプラインの最初の構築ステップを実行します。
jobs:
install-build:
# For running on CircleCI's self-hosted runners - details taken from environment variables
machine: true
resource_class: RUNNER_NAMESPACE/RUNNER_RESOURCE_CLASS # Update this to reflect your self-hosted runner resource class details
steps:
- checkout # Check out the code in the project directory
- check-python # Invoke command "check-python"
- create-env
- run:
command: sh ./tools/install.sh
name: Run script to install dependencies
- run:
command: python3 ./ml/1_build.py
name: Build the model
- persist_to_workspace:
# Workspaces let you persist data between jobs - saving time on re-downloading or recreating assets https://circleci.com/docs/workspaces/
# Must be an absolute path or relative path from working_directory. This is a directory on the container that is
# taken to be the root directory of the workspace.
root: .
# Must be relative path from root
paths:
- venv
- ml
- .env
- tools
ワークフローは複数のジョブで構成されます。ジョブは、順次実行することも、同時実行することもできます。build-deploy ワークフローでは、install-build ジョブ、train ジョブ、test ジョブ、package ジョブを実行します。このワークフローでは、ブランチフィルターを使用して、main ブランチに対してコミットが行われたときにのみワークフローを実行する方法を示しています。また、[requires](https://circleci.com/docs/ja/configuration-reference/#requires) オプションを使用してジョブの順次実行を指定する方法、および複数のジョブ名を後続ジョブの必須条件にして同時実行する方法も示しています。
workflows:
# This workflow does a full build from scratch and deploys the model
build-deploy:
jobs:
- install-build:
filters:
branches:
only:
- main # Only run the job when the main branch is updated
- train:
requires: # Only run the job when the preceding step in the ML process has been completed so that they are run sequentially
- install-build
# To demonstrate how to run two tests concurrently, we'll run the same test twice under different names - if either required test fails, the next job that requires them (in this case, package) will not run - https://circleci.com/docs/workflows/#concurrent-job-execution
- test:
name: test-1
requires:
- train
- test:
name: test-2
requires:
- train
- package:
requires:
- test-1
- test-2
ファイルは自分でパス .circleci/config.yml に作成することもできますが、CircleCI へのプロジェクトのインポート時に Web コンソールで作成することもできます (後者の方法には、構文チェックとスキーマバリデーションを行えるというメリットがあります)。CircleCI コンフィグファイルをローカルで作成する場合は、CircleCI コマンドラインツールを使ってコンフィグファイルをバリデーションしてから、変更をコミットすることをお勧めします。また、VS Code を使用する場合は、CircleCI 用 VS Code 拡張機能を使い VS Code 内で直接コンフィグファイルをバリデーションすることもできます。
必須のコマンド、ジョブ、ワークフローがすべて設定された完全版の CircleCI コンフィグファイルのサンプルについては、こちらをご覧ください。
CircleCI セルフホストランナーを作成する
このチュートリアルに用意されている CircleCI パイプラインのサンプルでは、すべてをCircleCI セルフホストランナー上で実行します。セルフホストランナーを使うと機密データがネットワーク外部に出ることがないため、この方式は実際の運用向きです。セルフホストランナーを構成し、.circleci/config.yaml コンフィグファイルにその詳細を入力する必要があります。
セルフホストランナーの構成が完了したら、RUNNER_NAMESPACE と RUNNER_RESOURCE_CLASS を .circleci/config.yml ファイル内のすべての場所で適切に設定します。
machine: true
resource_class: RUNNER_NAMESPACE/RUNNER_RESOURCE_CLASS # Update this to reflect your self-hosted runner resource class details
ジョブごとに異なる実行環境を定義することもできます。コンピューティング負荷の高いジョブには CircleCI のクラウド GPU を使う場合などには、この方法が非常に役立ちます。このチュートリアルでは、手順を簡単にするために、1 つの環境だけを使用します。
CircleCI の環境変数を設定する
サンプルのコンフィグファイルを見ると、変数が使われていることに気づくと思います (先頭に $ 記号が付いています)。以下の 環境変数 を CircleCI で設定する必要があります。これらの環境変数は、パイプラインの実行時に Python で使う[.env](https://pypi.org/project/python-dotenv/){: target="_blank"} ファイルを生成するためにそれぞれの場所で使用され、ランナーのシークレットを取得します。
DEPLOY_SERVER_HOSTNAME
DEPLOY_SERVER_USERNAME
DEPLOY_SERVER_PASSWORD
DEPLOY_SERVER_PATH
認証情報や API キーなどのシークレットを、VCS にコミットしないように注意しください。環境変数は CircleCI パイプラインの実行時に挿入されます。そのため、コンフィグファイルをリアルタイムに作成でき、シークレットをコミットする必要はありません。
このサンプルでは、簡略化のため、SSH パスワード認証を使用します。本番環境では、証明書認証を使用して、ユーザーが必要なリソース以外にはアクセスできないよう制限することをお勧めします。さらにセキュリティを高めたい場合は、シークレットを一元的なシークレット管理システムに保管し、必要なタイミングで取得することを検討してください。
サンプルコンフィグファイルでは、次の CircleCI コマンドで .env ファイルを作成します。
commands:
create-env:
steps:
- run:
# Environment variables must be configured in a CircleCI project or context
command: |
cat \<<- EOF > .env
DEPLOY_SERVER_HOSTNAME=$DEPLOY_SERVER_HOSTNAME
DEPLOY_SERVER_USERNAME=$DEPLOY_SERVER_USERNAME
DEPLOY_SERVER_PASSWORD=$DEPLOY_SERVER_PASSWORD
DEPLOY_SERVER_PATH=$DEPLOY_SERVER_PATH
EOF
name: Create .env file containing secrets
こちらのサンプルを見て、どのような .env ファイルを作成するのかご確認ください。
ジョブ間でデータを永続化する
各ジョブは実行環境が異なることがあります。そのため、デフォルトでは、異なるジョブ間でデータは永続しません。CircleCI では、ワークスペースを使用してジョブ間でデータを永続化できます。サンプルコンフィグファイルに定義されているジョブでは、パス venv、ml、.env にあるデータとツールが変更時にワークスペースに永続化されます。
- persist_to_workspace:
# Workspaces let you persist data between jobs - saving time on re-downloading or recreating assets https://circleci.com/docs/workspaces/
# Must be an absolute path or relative path from working_directory.This is a directory on the container that is
# taken to be the root directory of the workspace.
root: .
# Must be relative path from root
paths:
- venv
- ml
- .env
- tools
ジョブを既存のワークスペースにアタッチすることで、必要なタイミングでそのデータが再度読み込まれます。
- attach_workspace:
# Must be absolute path or relative path from working_directory
at: .
CircleCI ワークフローの実行が正常に完了したことを確認する
コードを Git ブランチにコミットするか、パイプラインのスケジュール実行がトリガーされたときに、CircleCI はコンフィグファイルを読み取り、ワークフローを実行するかどうかを決定します。
CircleCI ワークフローが実行されると、コンソールのすべての出力が CircleCI Web コンソールに表示されます。各ステップ、ジョブ、ワークフローのステータスが報告され、エラー発生時にはオーナーに通知が届きます。承認が必要な場合は、承認が行われるまでジョブが停止します。問題を修正したら、エラーの発生した箇所からジョブを再実行できます。
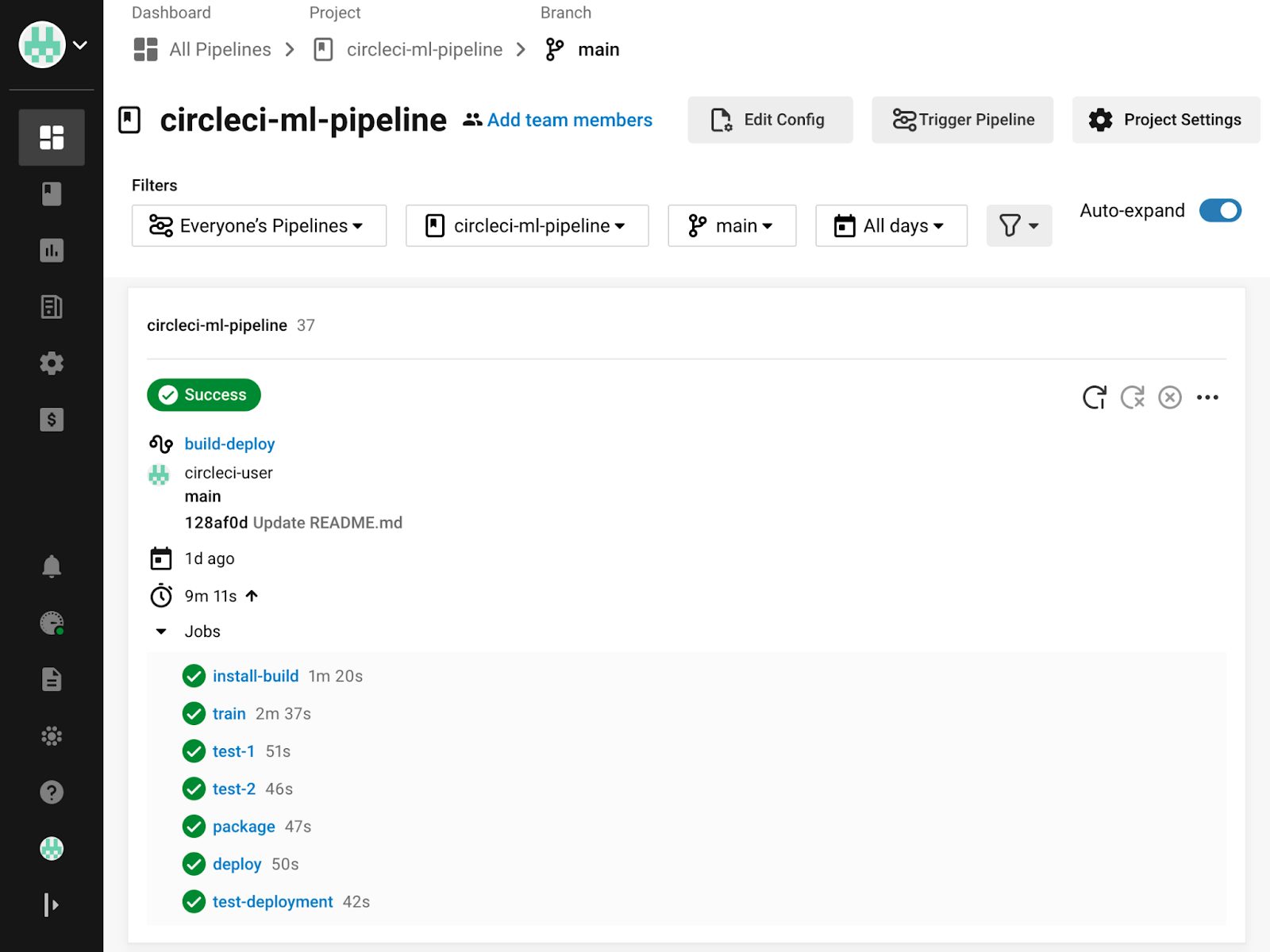
CircleCI パイプラインの監視について詳しくは、このチュートリアルの次回の記事で取り上げます。
CircleCI のマネージドクラウドコンピューティングリソースを使用しクラウド上で CI/CD ワークフローを実行する
このサンプルではこれまで、セルフホストランナーを使用してローカル環境でコマンドを実行してきました。この方法には、ネットワーク外部に出したくない機密データを扱う場合にはメリットがありますが、処理に使うローカルマシンを自分で用意しなければなりません。
CircleCI コンフィグファイルで実行環境として Docker、Linux VM (仮想マシン)、macOS、Windows、GPU、または Arm を指定すると、ML タスク (や CI/CD タスク) を CircleCI のマネージドコンピューティングリソースで直接実行できます。また、認証付きプルで独自の Docker イメージを使用できます。ホスティング環境は CircleCI のマネージドクラウドコンピューティング上で実行されるので、自分でハードウェアを用意する必要はありません。ワークフローは、自動プロビジョニングされたコンピューティングリソースを使ってオンデマンドで実行されます。
たとえば、ビルド済みの Python Docker コンテナでジョブを実行するには、コンフィグファイルのジョブの machine オプションと resource_class オプションを次のコードで置き換えます。
docker:
- image: cimg/python:3.11.4
クラウドコンピューティングを使用する際は、実行環境からデータにアクセスできるようにする必要があります。そのためには、SSH トンネリング、VPN、または CircleCI Orb を使用して、パブリッククラウド (AWS、Google Cloud Platform、Azure など) に保存されているリソースにアクセスします。よく使われる方法の 1 つは、ML モデルとデータを AWS S3 バケットに入れて共有するというものです。このようにすると、OIDC を使ってオンサイトインフラストラクチャと CircleCI から認証しアクセスできます。
ワークスペースを使用して、ローカルデータをクラウドのワークロードに転送することもできます。CircleCI ワークフローでは、最小限の追加構成で、データをジョブ間で永続化ながら、ローカルランナーや CircleCI のマネージドクラウドコンピューティングで実行するように構成されたジョブを実行できます。
クラウドおよびローカルの ML タスクでの GPU リソースを活用する
リソースクラスを使用して CircleCI のクラウドコンピューティングで利用可能な CPU とメモリを指定する際には、ML タスクをクラウドでホストされた GPU 実行環境で実行することもできます。CircleCI で GPU リソースを使用する場合は、GPU 対応のマシンイメージをコンフィグファイルで指定します。
machine:
image: ubuntu-2004-cuda-11.4:202110-01
大量のデータを処理する必要があり、クラウドリソースを利用すると膨大なコストが発生してしまう場合は、独自のセルフホストランナーを使って自前の物理 GPU を利用することもできます。
GPU リソースを利用できる環境があり、その環境に ML プラットフォームが対応していれば、GPU リソースを活用するように ML パッケージを構成できます。TensorFlow でこの方式を使うには、こちらのガイドをご覧ください。アプリケーションのコンピューティング負荷が高くても、GPU ならすばやく処理できます。そのため、GPU は ML モデルの処理にぴったりです。
CI/CD による ML ワークフローの自動化でデータ分析の結果をコスト効率よく改善する
機械学習に利用できるデータの量は増加の一途をたどっています。それと同時に、(オンサイトとクラウドの両方で) データの保存や学習に利用できるストレージと処理能力も増えているため、あらゆる規模の組織で ML が活用できるようになりました。これらのデータを利用せず、最新の ML ツールや手法を活用しないと、これまでデジタルインフラストラクチャに費やしてきた投資が無駄になってしまいます。
CircleCI の CI/CD プラットフォームの使い道は、ソフトウェアの開発とテストに限りません。CircleCI は、自動化したパイプラインをビルド、デプロイできる表現力の高い Configuration as Code システムを備えており、ML タスクだけでなく、スクリプト化可能なタスクであればほぼすべてを自動化できます。MLOps ワークフローの構築をすぐに始めたいという方は、ぜひ CircleCI の無料プランに登録してください。毎月最大 6,000 分のビルド時間を無料で利用できます。
このチュートリアルのパート 2 では、CircleCI で継続的デリバリーパイプラインをセットアップして、ML モデルのデプロイ、監視、再トレーニングを自動化する方法について説明します。ぜひ、「 機械学習に CD を活用する: デプロイ、監視、再トレーニング」をご覧ください。



