
インフラアラートの運用を改善した話

はじめに
Hi everyone!
SREチームに所属している渡邉です!
私は現在新卒採用メディア「ONE CAREER」のEmbedded SREとして、SLOの監視文化の浸透やAWSを使ったインフラ基盤の改善に取り組んでいます。
「Embedded SRE」とは、特定の開発チームと並走しながら一体となって開発と運用を担うSREの役割のことです。
久しぶりのテックブログの投稿になりますが、今回は「ONE CAREER」も含めて弊社全サービスのインフラアラートの運用改善における取り組みについて共有します!
インフラアラート運用における課題
もともとワンキャリアの本番環境のインフラアラートを通知するSlackチャンネルは以下のような構成になっていました。
emergency(システムがダウンしており、緊急で対応が必要)
アラートの内容
Route53 healthcheckの外形監視に失敗した時にトリガーするサービスのダウンタイムアラート
本番環境のECSサービスとrdsインスタンスの平均CPU使用率・Memory使用率が閾値を超えた時のリソース不足アラート
対応ルール
アラートがきたら10分以内に対応する
特定の対応手順は特になし
irregular(システムに異常があるがダウンしているわけではなく、対応は緊急ではない)
アラートの内容
ECSのタスクコンテナが異常停止(exitCodeが0以外で終了)した時にトリガーするアラート
対応ルール
特に無し
ただ、この構成でインフラアラートを運用している中で様々な課題が見えてきました。
Route53 healthcheckを利用したダウンタイムアラートでは、us-east-1のリージョンの外形監視メトリクスを使用するため、ダウンタイムアラートがトリガーしても実際はサービスが動いていることがある
タスクの死活監視では、異常停止は検知できる一方で、タスクコンテナの起動失敗が検知できていなかった(これが原因でインシデントの特定に時間がかかったことがあった)
システム異常アラートのメッセージがわかりづらい。そもそも何のアラートなのか理解が難しい
emergencyチャンネルにCPUやメモリ等の監視の通知も流していたため、クリティカルなアラートに対する感度が下がり、対応が遅れてしまうことがあった
課題に対するアクション
他にもアラート運用の課題はあるのですが、上記4つの課題を改善するために行ったことをご紹介します。
1.外形監視サービスをRoute53 healthceckからDatadog Synthetics API Testへ移行
DatadogのSynthetics API Testは、成功条件やアラートをトリガーさせる条件を柔軟に指定させ、テストするリージョンを東京に絞ることができます。今回の要件の1つでもあった「東京」リージョンで発生したアラートのみをトリガーさせることも可能となりました。
また、ダウンタイムアラートをサービスごとに分けることができるので、各開発チームメンバーが担当しているサービスのアラートに注力することができました。

2. タスクの起動失敗を検知するアラートを設定した
EventBridgeを使い、ECSタスクが起動に失敗したら検知するように実装しました。
さらに起動に失敗したかどうか見分けるため、ログのStoppedReasonが“TaskFailedToStart”であることを条件にしました。
そして、EventBridgeのイベントログをLambdaに転送し、LambdaからアラートメッセージをSlackに送るようにしました。
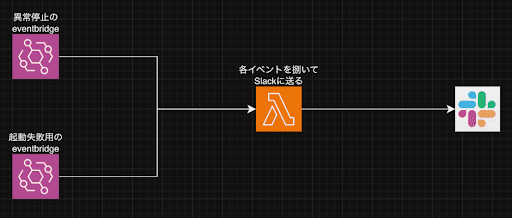
3. Lambdaでアラートメッセージを読みやすくした
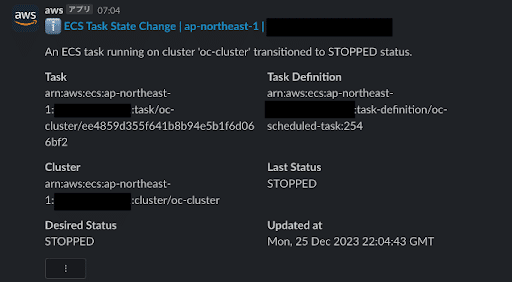
もともとECSタスクの死活監視アラートは、Lambdaではなく直接EventBridgeからSlackへアラートを飛ばすようにしていました。しかし、これではアラートメッセージがわかりづらく、アラートがトリガーしても調査するために動き出しづらい運用になっていました。
↓不要な情報が多く、何が原因で異常停止したかがわからない

そこで、既存のECSタスク異常停止用のEventBridgeとECSタスクの起動失敗用EventBridgeのイベントログをLambdaに転送し、Lambdaがそれぞれのイベントを捌いて必要な情報を2の構成図のようにSlackへ送信するシンプルな仕組みを作りました。
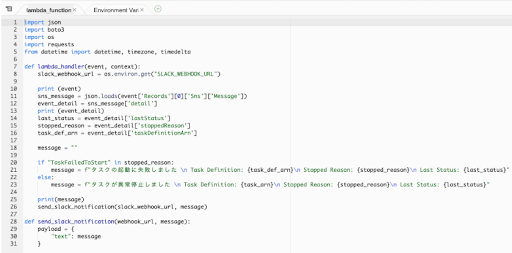
イベントログを受け取ったLambdaは、if文を使って異常停止か起動失敗かを判断します。
そこからそれぞれ対象のクラスターや異常停止・起動失敗した原因(ログの“StoppedReason”)をメッセージに追加しカスタマイズしました。
↓Lambdaのコード
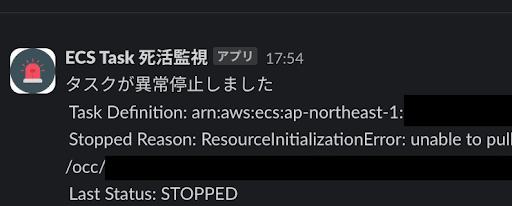
上記の変更を通じ、メッセージが必要な情報だけに整理され、ECSタスクの死活監視アラートを簡潔化することができました。
Before:
After:
4.本番環境のリソース不足のアラート場所をemergencyチャンネルからシステム異常チャンネルへ変更した
RDSインスタンスのCPUやメモリ使用率、ECSサービスのCPUやメモリ使用率が90%など閾値を超えても必ずしもサービスがダウンしているとは限りません。
そこで、ダウンタイムアラートなどリアルタイムでユーザーに影響が出るものはemergencyチャンネル、必ずしもユーザーに影響が出るものではない異常はシステム異常チャンネルにアラートを送信するように変更しました。
他にもアラート運用の改善に向けて実施したことを軽く記載しておきます!
emergency, システム異常チャンネルそれぞれでアラートがきた場合の対応手順マニュアルを作成した
システム異常チャンネルでアラートがきた時の対応方針がなかったため、対応期限と対応手順を指定した
運用を見直してみて大変だったこと
全サービスにおいて、タスクの死活監視アラートの実装が一番大変でした。異常停止した場合と起動に失敗した場合のイベントをできるだけシンプルな構造で処理して正確にアラートをトリガーさせる仕組みを考えることに一番時間がかかりました。
運用を見直してみての感想
インフラアラートの運用を見直したことで、以前ほとんど活用されてこなかったシステム異常チャンネルでアラートの対応が行われたり、担当していない他のプロダクトのアラートが混ざることによる注意の負荷が軽減されたかなと思います。
また、今回アラートの運用を見直す過程で良いアラートとは何か、不要なアラートが多いとどうなるかについて再度振り返ることができたので良い学びになったと思います。
いかがでしたか?アラート運用を見直す際にこの記事が参考になると嬉しいです!
▼ワンキャリアのエンジニア組織のことを知りたい方はまずこちら
▼カジュアル面談を希望の方はこちら

▼エンジニア求人票
この記事が気に入ったらサポートをしてみませんか?