dbt-snowflake で delete+insert の incremental model を実装する際には join の爆発に気をつけよう
はじめに
こんにちは、Finatextグループのナウキャストでデータエンジニアをしているけびん(X: @Kevinrobot34 )です。Snowflake と dbt そして Terraform を使ってデータ分析基盤の構築をするとともに、POSデータのパイプラインの開発・運用を行っています。
POSデータの弊社のパイプラインは Snowflake と dbt で実装されているのですが、POSのトランザクションデータは大きく、差分更新するために incremental model を使っていました。その際に爆発的なjoinによりパフォーマンスの問題が起きてしまいました。今回の記事ではその詳細と対策の話を書いていきます。
incremental model とは
dbt は、例えば select 文を書いた hoge.sql というファイルを用意しておくと、そのselect 文を CTAS ( CREATE TABLE AS SELECT ) でラップしたSQLにコンパイルし、DWH上で簡単にELTを実行できるようにしてくれるツールです。
dbt は基本的にはテーブルを毎回洗い替えてしまうので、シンプルで分かりやすい一方、データ量が大きいテーブルだと毎回洗い替えするわけにもいきません。いわゆる差分更新をやりたくなるわけですが、dbt の incremental model を使えば実現できます。
is_incremental() というマクロを使うことで、初回の実行時には where 文を外しデータの全量をスキャンし、二回目以降の実行時には where 文により差分だけスキャンしてその分を更新する、というような仕組みです。
詳細は以下のドキュメントなどを参照してください。
また弊社のエンジニアが dbt incremental model と冪等性に関する記事も書いておりますのでご覧ください!
POSデータの概要
Point Of Salesの略で、「いつ」「どこで」「何が」「いくつ」「いくらで」売れたかというデータです。これらの情報が全国のスーパーマーケットやドラッグストアから集められております。
弊社が取り扱っているPOSデータはヒストリーも長くデータの量が大きいので以下のような incremental model を dbt-snowflake を利用して実装していました。
{{
config(
materialized="incremental",
unique_key=["data_date"],
cluster_by=["data_date"],
incremental_strategy="delete+insert",
)
}}
select
data_date::date as data_date,
store_code,
jan_code,
sales::int as sales,
quantity::int as quantity,
from {{ source("pos", "transaction") }}
{%- if is_incremental() %}
where
data_date >= dateadd(
day, {{ var('time_lag') }}, (select max(data_date) as max_data_date from {{ this }})
)
{%- endif %}ある日付の購買データは、その後一定期間は訂正されることがあるため、更新されうる期間の分のデータは削除し、最新のデータをインサートするという delete+insert による incremental model として実装していました。
このSQLモデルを実行すると、当然初回実行時はテーブルを0から作成するので遅いのですが、二回目以降も非常に遅いことが分かりました。
この事象を改善するためには dbt がコンパイルした実際のクエリがどのようなもので、それがどのようにSnowflake上で実行されているかを理解するのが大事でした。
Incremental model の挙動
実際にコンパイルされたSQLと向き合ったり、dbtの実装を観察すると、delete+insert の incremental model の場合には以下のように3ステップで実行されていることがわかりました。
step1 — 差分に対応するテーブルを作成
最初のstepはシンプルで、sqlモデルのselect文をCTASでラップしたものを一時テーブルとして作成します。where文が含まれているので差分に対応したデータのみを含む一時テーブルとなります。
create or replace temporary table pos_transaction__dbt_tmp as (
select * from (
select
data_date::date as data_date,
store_code,
jan_code,
sales::int as sales,
quantity::int as quantity
from source_transaction
where
data_date >= dateadd(
day, -8, (select max(data_date) as max_data_date from pos_transaction)
)
) order by (data_date)
);※見やすさのためにDB名やスキーマ名を削除したり一部フォーマットしています。今後のSQLも同様です。
step2 — 差分テーブルと元テーブルを突き合わせ削除を実行
step1で用意した差分テーブルと元のテーブルを突き合わせます。このときのwhere文は unique_key の設定に従って実行されます。incremental_strategy が merge の際には unique_key はその名の通りユニークなキーとして利用されるのですが、 delete+insert の際にはただ単にこのstep2での突き合わせの条件となるというのがポイントです。
delete from pos_transaction
using pos_transaction__dbt_tmp
where (
pos_transaction__dbt_tmp.data_date = pos_transaction.data_date
);step3 — 増分テーブルをインサート
step1で作った差分テーブルを元テーブルにインサートします。
insert into pos_transaction (“DATA_DATE”, “STORE_CODE”, “JAN_CODE”, “SALES”, “QUANTITY”)
(
select “DATA_DATE”, “STORE_CODE”, “JAN_CODE”, “SALES”, “QUANTITY”
from pos_transaction__dbt_tmp
);実際のパフォーマンスの問題
Snowflake は Query History と Query Profile が非常に便利で、パフォーマンスの問題があったときの調査が非常にしやすいです。
今回も各 Step の Query Profile を眺めていたところ Step2のdeleteのところが以下の通り重いことがわかりました。
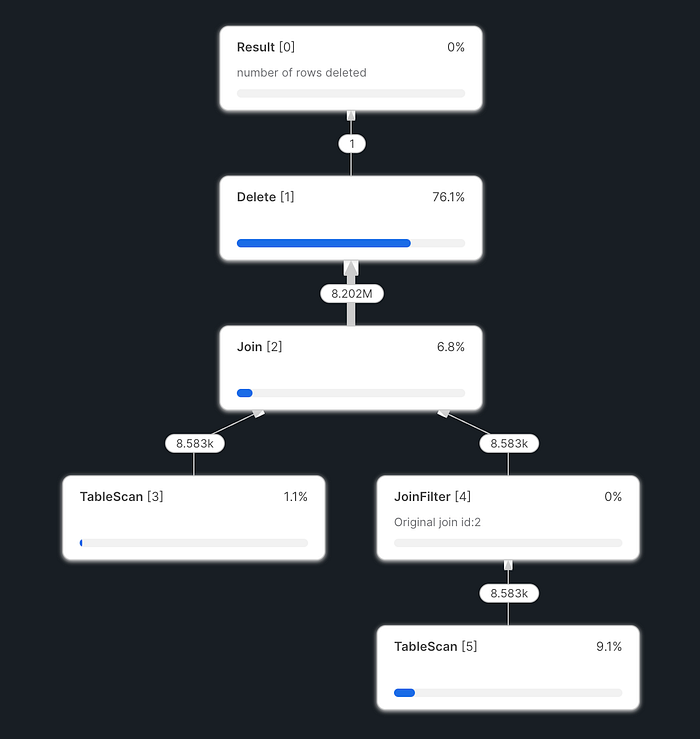
こちらを見てわかる通り、join後の行数が非常に大きくなっています。2つのテーブルで data_date が同じデータは多数存在し、それらのデカルト積でデータが作られてしまっているというようなイメージですね。Snowflake のドキュメントでも「爆発結合(Exploding Joins)」として紹介されています。
元々やりたかったことは、修正される可能性のある範囲の data_date のデータを単に削除することです。
dbt-adapters の実装に deep dive
joinの際に where で data_date のみが指定されてしまっているのが根本の原因です。そもそもこのクエリがどうやって生成されているか見てみましょう。dbtのコードとしてはこのあたりです。
{% macro default__get_delete_insert_merge_sql(target, source, unique_key, dest_columns, incremental_predicates) -%}
{%- set dest_cols_csv = get_quoted_csv(dest_columns | map(attribute="name")) -%}
{% if unique_key %}
{% if unique_key is sequence and unique_key is not string %}
delete from {{target }}
using {{ source }}
where (
{% for key in unique_key %}
{{ source }}.{{ key }} = {{ target }}.{{ key }}
{{ "and " if not loop.last}}
{% endfor %}
{% if incremental_predicates %}
{% for predicate in incremental_predicates %}
and {{ predicate }}
{% endfor %}
{% endif %}
);
{% else %}
delete from {{ target }}
where (
{{ unique_key }}) in (
select ({{ unique_key }})
from {{ source }}
)
{%- if incremental_predicates %}
{% for predicate in incremental_predicates %}
and {{ predicate }}
{% endfor %}
{%- endif -%};
{% endif %}
{% endif %}
insert into {{ target }} ({{ dest_cols_csv }})
(
select {{ dest_cols_csv }}
from {{ source }}
)
{%- endmacro %}これを見ると unique_key がシークエンスで渡されていると step2 の where 句が unique_key を直接比較する形になっている一方、 unique_key を文字列で指定するとそのキーを in で比較する形式に変わることが分かります。
そこで以下のようにconfigにおける unique_key の指定の仕方を変更してみました。
-- before
{{
config(
materialized="incremental",
unique_key=["data_date"],
cluster_by=["data_date"],
incremental_strategy="delete+insert",
)
}}
-- after
{{
config(
materialized="incremental",
unique_key="data_date",
cluster_by=["data_date"],
incremental_strategy="delete+insert",
)
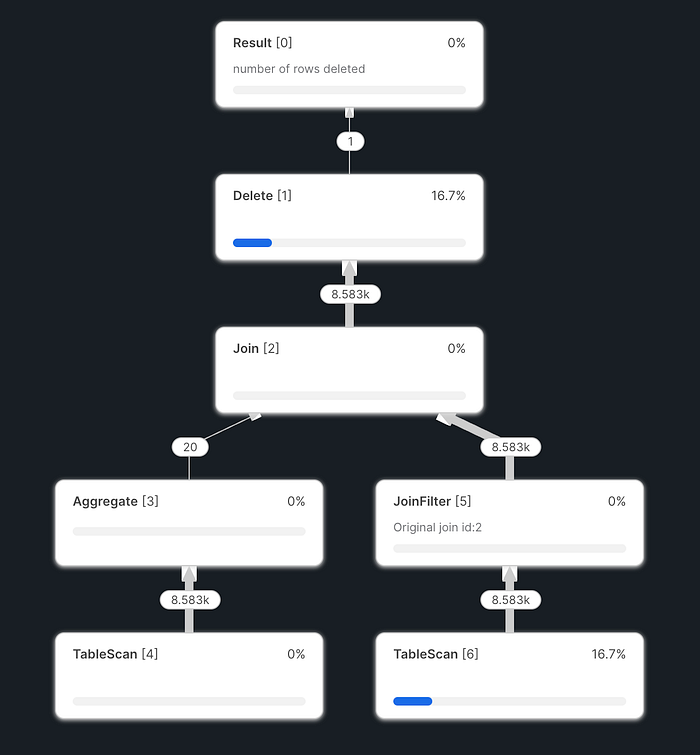
}}この新しいconfigで再度クエリを実行したところ、step2のデータの削除のクエリが以下のように変更されました。
delete from pos_transaction
where (data_date) in (
select (data_date) from pos_transaction__dbt_tmp
);これはまさに「更新されうる期間の分のデータは削除」というやりたかったことであり、また書き方も変わったことで爆発的なjoinもなくなりパフォーマンスも大幅に改善しました!
まとめ
- dbt-snowflake delete+insert の incremental model を実装する際には join の爆発に気をつけましょう!
- dbt は incremental model などの場合、意外と複雑なクエリを生成していたりするので、実際に実行されるクエリと向き合うことが大事です。dbtのコードを直接読むのも面白いのでおすすめです!
- Snowflake は Query Profile が便利なので、よく見てクエリの最適化に活かすのがおすすめです!
仲間を募集中です!
Finatextホールディングスでは一緒に働く仲間を募集中です!様々なエンジニア系のポジションがあるので気軽に覗いてみてください!
気になることがあれば気軽にXで @Kevinrobot34 にご連絡ください!

