
転職サービスにおけるデータ分析基盤の構築事例 - AWS Innovate - Data Edition

2021 年 8 月 19 日(木)に開催された、AWS Innovate – Data Editionにて、 CTOの大谷が「転職サービスにおけるデータ分析基盤の構築事例」というテーマで、ミイダス インフラチームのチャレンジについて発表しました。
セッション概要
転職サービスにおけるデータ分析基盤の構築事例
スカウト型転職サービス「ミイダス」におけるデータ分析基盤の構築事例についてお話します。 ミイダスではサービスのメインDBとして Amazon Aurora MySQL を活用しています。データ分析基盤の構築以前は、サービスのログデータを読み込み専用の Aurora インスタンスに格納して活用していました。開発者が慣れている SQL で、ログデータの検索や集計が行えるためです。
サービスの成長に伴いログデータ量が多くなり、それによって SQL を使ったデータ抽出に時間がかかるようになりました。その課題を解決するために、S3 を中心としたデータ分析基盤の構築に着手しました。
データ分析基盤においては、AWS DMS, Amazon S3, AWS Glue, Amazon Redshift, Amazon QuickSight などの AWS サービスを活用しています。各 AWS サービスの選定理由、活用方法についてご紹介します。
ミイダス株式会社 VPoE 大谷 祐司

※ 登壇収録時の撮影の様子です。メイクとヘアセットをしっかりとしていただきました(笑)
転職サービスにおけるデータ分析基盤の構築事例
皆さんこんにちは。
ミイダス株式会社 CTO の大谷と申します。本日は転職サービス ミイダス における
データ分析基盤の構築事例ということで、お話をしていきたいと思います。

それでは本編の方に入ります。まず簡単に私の自己紹介をさせていただくと
私はミイダス株式会社 CTO の大谷と申します。
今 開発チームの組織づくり、技術広報 採用など幅広くミッションとして担っています。
またプロダクトの価値を高めるための、開発チーム全体のミッション策定ということも行っています。
私はミイダスの立ち上げからいる立ち上げメンバーですので、サービスの成長ということを
これまでずっと見てきました。
ご存知ない方も多いかと思うんですけども、転職サービス ミイダス について簡単にお話をしたいと思います。
転職サービス「ミイダス」について

ミイダス は 2015 年にリリースをされたスカウト型の転職サービスになります。
今 70 万人の転職を希望するユーザーと、20 万社にご利用いただいていて、継続的に成長しているサービスになっています。

世の中に転職サービスはたくさんあると思うんですけど、私たちの特徴としましては
求職者 採用企業、両方に診断を受けていただいて、その診断結果のデータを元に最適な転職先をマッチングするということ。
これはアセスメントを使ったリクルーティングというふうに呼んでるんですけども、これを行うことによって企業 求職者 お互いにフィットする適材適所の採用実現ということを目指しています。
私たちは ミイダス株式会社として、今運営をしてるんですけれども、元々パーソルグループのパーソルキャリアの 1 事業として新規事業として立ち上がったサービスになります。

その後 2019 年に独立してミイダス株式会社となって、今は独立した会社として運営しているんですけれども、従業員数は 300 名、そのうちエンジニアデザイナーは70 名ほどいる組織で運営をしてるような形になっています。
ではまず データ分析基盤の構築の事例に入る前にミイダス のインフラとデータベースについて、簡単にご紹介をしておきたいと思います。
ミイダス のインフラとデータベース
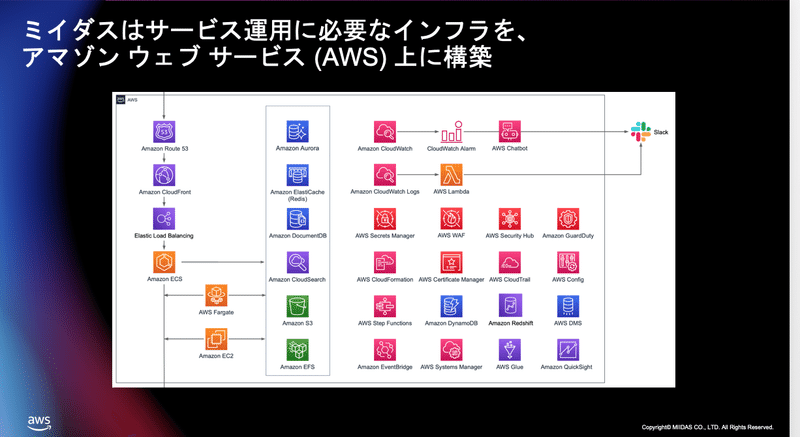
今ご覧になっているのはミイダス のインフラの全体の構成図になるんですけれども
ご覧のように ミイダス はサービス運用に必要なインフラを全てアマゾン ウェブ サービス上に構築をしています。
かなり様々なサービスを組み合わせて活用してますので詳細の説明は時間の関係で割愛するんですけれども、例えばコンテナの活用を進めていて、EC2 からより負荷分散ができるコンテナを活用していたりとか、ストレージに関してもAurora だけに限らずに例えば DocumentDB だったりElastiCache だったりとか様々なマネージドサービスを組み合わせて
インフラ構築をしてるのが特徴かなというふうに思います。

そしてメインのデータベースとしてはAmazon Aurora を MySQL として活用しています。
3 タイプのデータベースのインスタンスタイプを持っていまして用途によって使い分けています。
メインとなるのが Writer データベースこれが ミイダス のコアです。様々なマスターデータがこの中に入って、ミイダス のサービスを支えています。
そして万が一そこのデータベースに何かあった時にフェイルオーバーができるように全く同じインスタンスサイズの Reader を 1 台用意しています。
そしてそれに加えて複数の小さなインスタンスサイズでReader をたくさん用意しています。
用途としましては他サービスとの連携にデータを渡す時だったりとか簡単なデータ確認だったりとかそういったものに使っています。
こういった用途別のデータベースのタイプを用意することによってコストと柔軟性 そして信頼性ということを両立させているのが特徴かなというふうに考えております。
転職サービスにおけるデータの特徴というものを簡単にご説明したいと思います。

転職サービスにおけるデータの特徴としましては「転職するユーザー」求職者というふうに呼んでるんですけども、求職者と あとは企業の求人数、その掛け合わせによってデータが増えていくような特性を持っています。
求職者は企業の求人に応募して、企業は求職者にスカウトを打って、その掛け合わせがデータサイズというふうになるわけになります。
今 1 番多いスカウトのデータベースでだいたい数 10 億件のデータを持っています。
またその掛け合わせによって生まれたデータが洗い替えが必要なってくるということが1 つの特徴かなというふうに思います。
ミイダス の特徴でもあるんですけれども、スカウトを打ったデータについては個人が新しいスキルを習得したりまた企業が採用要件を変えたりすることによってそのデータの更新というものが発生してきます。
これがそれなりの量を発生するので、データの洗い替えという事にパフォーマンスを必要とするようなデータベースの特性になっています。
また メール通知などのバッチがたくさん動いてるんですけども、例えば「企業の採用担当者が朝来た時に昨日はどんな新しい登録ユーザがいるのかというのを確認したい」と、そういった企業の人の流れに合わせて時間が切られているようなバッチがたくさんあります。
結構スケジュールがシビアなものが多いので、それに耐えるためにパフォーマンスをシビアに見ながらデータベースのチューニングをしているというような状況になります。
Aurora に限らず用途別にいくつかストレージを活用しています。
例えば求人情報だったりとか全文検索されるテキストデータこんな条件で募集してますとかこんな人探してますとかというふうな、テキストデータに関してはCloudSearch を活用して検索できるようにしています。
また頻繁に洗い替えが必要なスカウト情報などはインメモリで高速に処理をしたいのでElastiCache Redisを活用してます。
これを使ってデータの洗い替えというものを高速に行っています。
求職者に紐付いた画面表示をする求人情報などについては1 つの ID に対して大きなデータが紐付いてきますので、これを Amazon DocumentDB MongoDB のマネージドサービスを活用して、データの大容量のものを保持をして且つ高速にインアウトとするということを実現をしてます。」
このように私たちのサービスを快適に使ってもらうためにAWS の複数のストレージを組み合わせてサービスを展開してるということこれが特徴というふうに考えております。
そして本時の本題であるデータ分析基盤の話に入りたいと思います。
データ分析で抱えていた課題
もともと私たちはデータ分析でいくつかの問題を抱えていました。
私たちが準備していたデータ分析の基盤というか手法なんですけれども、
Aurora のデータを Reader に移してそこの Reader に対してSQL を使ってデータ分析集計を行って、主要な KPI を把握したりだったりとかサービスの状態を見たりということを行っていました。
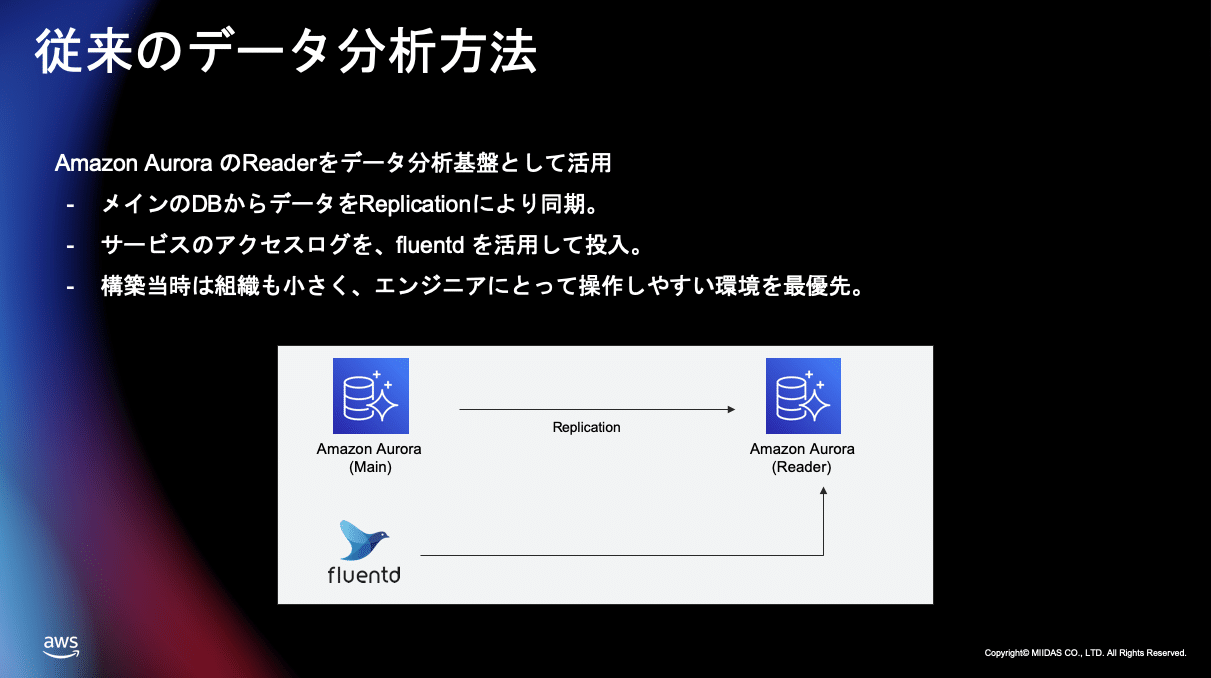
Aurora のレプリケーションを活用して行なっていましたまたユーザーがサービス上どういうふうにアクションしたか、というふうなログについてはfluentd を活用してこれも Aurora に流し込んでいました。
これ構築した当初はサービス規模も小さくまたエンジニア組織もすごく人数が限られていたので、基本的にはエンジニアがデータ分析をできればいいというふうな思想で構築をしています。
エンジニアにとって操作しやすいという環境を最優先して作ったものになります。

これメリットとデメリットがありまして、メリットとしてはエンジニアが普段使っているSQL を使ってデータ分析ができますので、すごくエンジニアライクなエンジニアドリブンで依頼を受けてデータを分析するということ。
これに対してはすごく早くできていました。
また、データベースの中にメインの RDB のデータと行動ログこれが一緒に入って構造化されて入っていましたので、SQL を使って行動ログとデータベースのデータを Join して一気に抽出するとかこういったこともできていました。
逆にデメリットとしましては、SQL ベースでデータを抽出をするのでデータ容量が増えてくるとそれにつれてパフォーマンスの悪化ということが起こっていました。
また SQL や RDB の知識が必要になりますのでエンジニア以外の方がデータを触ろうと思ってもすごくハードルが高くて、基本的にはエンジニアに依頼をしてエンジニアが作業するというふうなフローでデータ抽出分析ということを行っていました。
リリース当初 ミイダス 開始当初はこれでも良かったんですけれどもサービスが成長してくるにつれて、データを正しく見てそこに対してクイックに打ち手を打っていくことが
サービス成長にとって不可欠だということを意思決定をして、データ分析基盤をしっかり作って快適な状態で素早く PDCA を回そうということを意思決定をして、分析基盤の構築に取り組んでいきます。
そしてデータ分析基盤の構築に入りました。
データ分析基盤の構築

解決したかった課題は 2 つあります。
1 つ目は SQL を使って分析をするのでパフォーマンスが悪くデータが増えるにつれて分析にかける時間が非常に長くかかるようになってきました。
分析業務に徐々に支障が出るようになってきて分析者が快適にデータを見れないような
そういった状況になってきていました。ですので データ分析基盤を作ることによって快適な環境というものを作ろうということを決めました。
それを実現するためにマネージドサービスAWS のマネージドサービスをフル活用して分析基盤をしっかりと、今 快適であり将来的にも快適な状態を作りたいというふうに決めました。

そして解決したかった 2 つ目の課題なんですけれども、従来の SQL を使ったデータ分析
エンジニアにとっては普段使ってる SQL でデータ分析ができるということで非常にとっつきやすかったんですけれども、もっと多くの人がそれこそ企画とかマーケとかそういった方たちも、データ分析に時間を使ってもらいたい。データ分析に興味を持ってもらってデータを触れるようにしたい。というふうに考えました。
そのために 従来の SQL ベースではなくてWeb ベースでインターフェースを用意して、開発者以外もデータ分析ができるそういった状態を作りたいというふうに思いました。
そこで我々こういった構成でデータ分析基盤を構築しました。
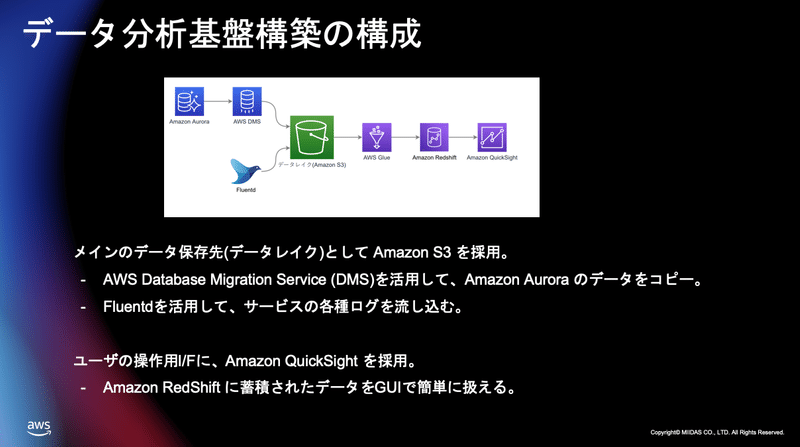
メインのデータ保存先に S3 を選択をしAurora のデータベースからデータを流し込んで、そして行動ログについてはこれまでと同じようにfluentd を使ってデータを流し込むんですけれども、従来はがっちり構造化をしてデータを流し込んでいたものを雑多な状態で fluentd を使ってデータを入れられるような、俗に言うデータレイクと言われると思うんですけれども、そういったものを作ってそこにデータを蓄積するようにしました。
Aurora からのデータコピーにはDMS を活用してます。
また、ユーザーの操作インターフェースに Amazon Redshift そして Amazon QuickSight を利用しています。
Amazon Redshift に最終的にデータを構造化されたデータを蓄積をしそこを Amazon QuickSight を使って操作するようなイメージになります。
マネージドサービスをかなり今回活用をしてデータ分析基盤を作ったんですけども、その選定ポイントと工夫したポイントについてお話ししたいと思います。
サービス選定のポイント

まずは AWS Database Migration ServiceDMS についてなんですけれども、用途としましてはAurora のデータを S3 にコピーする際に利用しています。
選定理由については、マネージドサービスですので耐障害性など信頼性が高くまた Aurora の処理に影響を与えずにデータコピーができる、データをコピーする際にメインの処理 メインのサービスに影響を与えないということがポイントになりました。
また大容量データのスピーディーなマイグレーションをサポートしており私たち転職サービスにおいて、かなり大容量のデータを持ってるんですけどもそれをクイックにスピーディーにコピーできるということがポイントになりました。
きっかけとしては弊社のインフラエンジニアがデータレイクハンズオンに参加した際に、お勧めということでご紹介をいただいて、実際使ってみると非常に良かったので採用に至ったという背景があります。
いくつかの工夫してるポイントがあるんですけれども、これ 1 つのタスクだけだと目標時間内にデータコピーが終わらないので、大きいテーブルなどを複数のタスクに分けて並列処理をしてデータコピーをするようにしてます。
リリース当初については、メモリー不足でデータコピーが止まってしまった、という事例がいくつかあったんですけども、それを防ぐために敢えて大きめのインスタンスを用意して、データの増減に対して柔軟に対応できるような状態を作っています。
データコピーの開始 終了エラー発生時などは、チャットボットを使ってSlack にデータを流しておりアラートを流しており、Slack 上で今のデータコピーの状態というものを見れるようにしてます。
私たちアグレッシブに機能追加だったりとかデータベースのスキーマ変更ということを行っているような開発組織の文化がありまして、それに対応するためにAurora のテーブルスキーマの変更に対して、DMS ルールを自動的に生成する仕組みを作ってます。
これによって Amazon Aurora のスキーマ変更に対してデータマイグレーションをスムーズに行えるようなこんな仕組みを作っています。
そして AWS Glue を採用しています。

用途としましてはS3 に蓄積されているデータをこれ Aurora からコピーしたデータがメインなんですけども、これに対して MySQL の型からPostgreSQL の型に変換するということを行ってます。
私たちは転職サービスをやってますので個人情報を多く持ってます。
個人情報を安全に扱わなければいけない、というふうに考えてまして、そのために S3 のデータに個人情報やその他重要なデータというものをマスクをするような処理を行ってます。
マスクをして Redshift に流して分析するということやってるんですけども、そこのマスクの処理にAWS Glue を活用しています。
加工したデータを Redshift に流し込むということこれも AWS Glueを使って行っています。
選定理由ですが、サーバレスで手軽に活用できるというところと、フォーマット柔軟性が非常に高く、またデータの変更に強いということが採用のポイントになりました。
工夫してるポイントとしましてはGlueJob という単位でデータを扱うんですけれどもそれを 3 つのステージに分けて扱っています。
1 つ目がデータレイクの更新
2 つ目がデータのマスク処理
3 つ目がそのデータを Redshift に流し込むという
この 3 つのステージに切ってまして、ステージごとに最適な並列実行数、また処理のパフォーマンスを最適化するDPU の調整ということを行っています。これによって大容量データでもパフォーマンス高くスピーディに S3 のデータを Redshift に流し込むということが実現できています。
次に Amazon Redshift Amazon QuickSight になるんですけれども、これはデータの可視化、分析ということを行ってます。

これについては当初 別の GUI も検討したりもしたんですけれども、結論は選択をして非常に良かったなというふうに思っています。
この組み合わせがすごくいいなというふうに思ってまして、Redshift と QuickSight の組み合わせがすごくいいなと思ってまして、優れた UI とパフォーマンス これの両立が高いレベルでできてるなというふうに感じてます。
また従来行っていた SQL を使ったデータ分析と比較をして、これもリリース当初エンジニアがすごく驚いたんですけども、数 10 倍からものによっては数 100 倍のパフォーマンスでデータ分析 抽出ができてます。
これ本当に選んで良かったと思いますしこの選択がすごく正しかったなというふうに、今でもすごく強く思っています。
工夫したポイントとしましてはデータの特性用途に合わせて最適な分散キー と ソートキー、これを Redshift に設定をしていますまた Aurora のテーブルスキーマ、これ頻繁に変わるんですけれども、スキーマ情報をもとにRedshift のテーブルを自動生成する仕組みこれを自前で構築してまして、これを使うことによってサービスの進化に合わせた最適な分散環境というものが半自動的にできるようなこういった状態を作れています。
以上が私たちがデータ分析基盤を作った経緯だったりとか構成だったりとか、また選定ポイントだったりの話だったんですけれども、データ分析基盤を作ることによってより良い影響 想定外の影響があったのでご紹介したいと思います。
データ分析基盤の構築による影響

組織にとって想定以上に良い影響がありました。
組織というのが企画チームだったりとか、マーケチームだったりとかも含めて組織というふうに定義してるんですけれども、多くの人がデータに興味を持ち自分で触ってみるということこれをやるようになりました。
従来の SQL でやっていた頃には考えられないような簡単さ手軽さでデータ分析ができるようになりましたので、QuickSight の見やすい UI、すごく直感的なインターフェイスによって多くの人が自分でデータ分析ができるようになりました。
従来はエンジニアに依頼をしてエンジニアが出してデータを渡すというふうにしている流れだったんですけども、自分でデータに興味を持って、どんどんどんどん 分析をして気になったものに対しては、どんどん深掘りしていくというこれができるようになりました。
これによって従来では実現できなかった欲しいデータを欲しい時に見ることによってサービスの改善スピードが大幅にアップをしました。
そしてそれによってPDCA サイクルが素早く回っていくようになって、組織文化そのものが大きく変わったな、大きくデータを中心に考える組織文化に変わっていったな、というふうに思っています。
またエンジニアチームにとってもすごく良い影響がありました。

マネージドサービスを活用したことによってインフラチームがデータ分析基盤、例えば SQL に投げた時のパフォーマンスに対して、チューニングをしていくといった、そういったことも含めて、データ分析基盤の運用に時間を取られること、これがすごく減りました。
そしてより創造的な作業に時間を取れるようになったことが、大きいなというふうに感じてます。
またエンジニアも従来であればSQL を職人的に作って抽出をするということが、これが日常的だったんですけども、そんなことをしなくてもUI 上でサクサクとデータ分析抽出ができるようになるので、データに興味を持って触ってみるということの敷居がすごく低くなりました。
これまでは依頼を受けてそれを抽出するといったデータ分析が、データに興味を持ってデータを見に行って より深掘りしていって、ファクトを見つけて改善に活かすということができるようになりましたので、エンジニアもデータドリブンなデータに興味を持ってデータを元にした開発優先度を決める、ということができるようになりました。
本当にこれは AWS のマネージドサービスのおかげだな、というふうに思ってるんですけれども、データ操作の敷居を下げることを実現したことによって、ミイダス にとってのデータ活用がより身近なものになったというふうに思っています。
というのが データ分析によってエンジニアチームに起こったもしくは全社にとって起こった良い影響になります。
最後に
そして最後になるんですけれどもマネージドサービスの活用が、サービス成長に本当に大きなポイントになってるなというふうに最近すごく思うことが多いです。

インフラの運用を AWS に任せられるので開発者がサービスの進化、サービスをもっと良くするということに集中できたなというふうに感じています。
また 負荷に合わせてスケールするという仕組みこれをあらかじめ用意しておけるので、常にサービスを操作するユーザーにとって最適な状態 快適な状況が作れてるなというふうに思っています。
何かあった時に そこに対して緊急対応するということも減りまして、何かあった時にはこういうふうにするということをあらかじめ予測して動けてるので、安心をしてインフラ運用を行えるような状態が作れてるかなというふうに思います。
また ユーザー自身、開発者自身が自分自身でできることこれが増えましたので、多くの人がインフラに興味を持ち触ってみる、そして課題解決をどういうふうにやればいいかっていうことを考えるようになった。これが AWS のマネージドサービスを使うことによって得られた大きなメリットだというふうに感じています。
これらの点からミイダス のサービス成長にとって、マネージドサービスの活用ということは不可欠だというふうに感じておりまして、これからも積極的にマネージドサービスを使っていって、ミイダス のさらなる成長ということを実現したいというふうに考えております。
ミイダス株式会社のデータ分析基盤構築事例のお話は以上になります。
ご清聴ありがとうございました。
ミイダス Tech について
ミイダスでは、様々な技術イベントを開催しています。connpassやYouTubeチャンネルでミイダスグループのメンバーになった方には、最新の開催情報やアーカイブの公開情報が届きますのでぜひご登録をお願いいたします。
イベントページ:https://miidas-tech.connpass.com/
Twitter:https://twitter.com/miidas_tech
この記事が気に入ったらサポートをしてみませんか?