
 本記事は 夏休みクラウド自由研究 8/26付の記事です。 本記事は 夏休みクラウド自由研究 8/26付の記事です。 |
「夏休みクラウド自由研究」ということで、Microsoft Azure の Azure AI サービスの TTS (Text to speech) / STT (Speech to text) を使って LLM (gpt-4o-mini) と音声で会話してみようと思います。
準備
まずはいろいろ試せるように、Azure AI Studio をセットアップします。
Azure AI Studio は Azure AI 関連サービス (Azure ML や Azure OpenAI なども含む) を一元的にエンドツーエンドで管理できるようにしてくれます。すべてを集めてきてくれており、簡単に使えていろいろ捗るので、目的からは必須ではありませんが使ってみます。
Azure AI Studio ハブの作成
Azure AI Studio ハブは、次の 2 つの方法で作成できます。
- Azure AI Studio (ai.azure.com) から作成する
- Azure Portal (portal.azure.com) から作成する
1 は必要最低限のパラメーターで作成できるため簡単ですが、ネットワーク設定などのエンタープライズ利用においては必須の設定ができなかったりしますので、まじめに使うときは 2 で作成いただくのがよろしいかと思います。
※ 今回は特にカスタマイズしたいこともないのですが、どんな設定があるか見たいので、 2 で設定内容などを眺めながら作成します。
※ なお、Azure OpenAI 利用申請は終わっている前提です。
作成手順 (クリック)
| Azure Portal の検索バーで Azure AI Studio を検索してアクセスします。 | 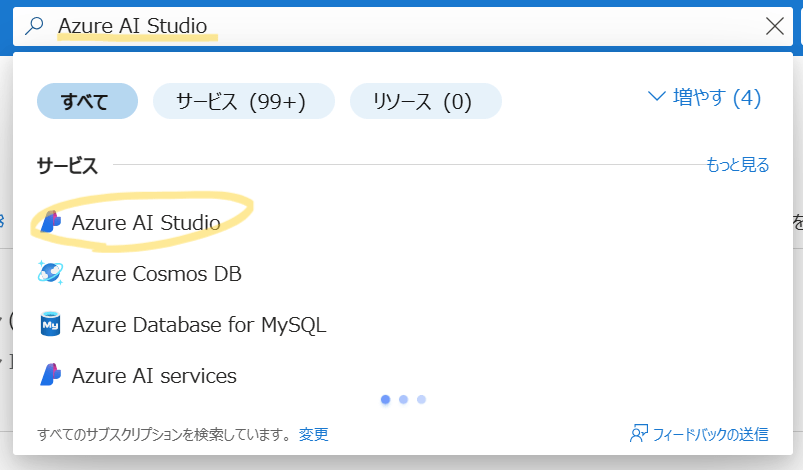 |
| 「新しい Azure AI ハブ」をクリックします。 | 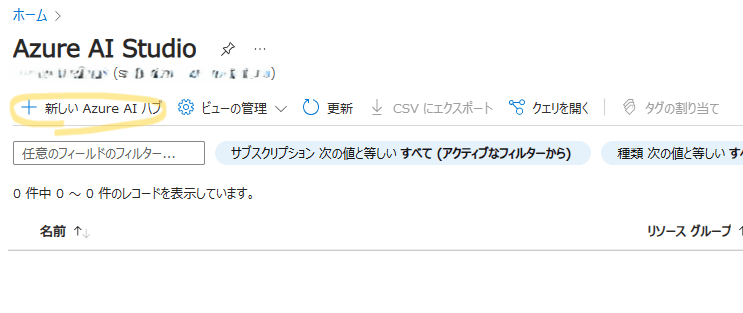 |
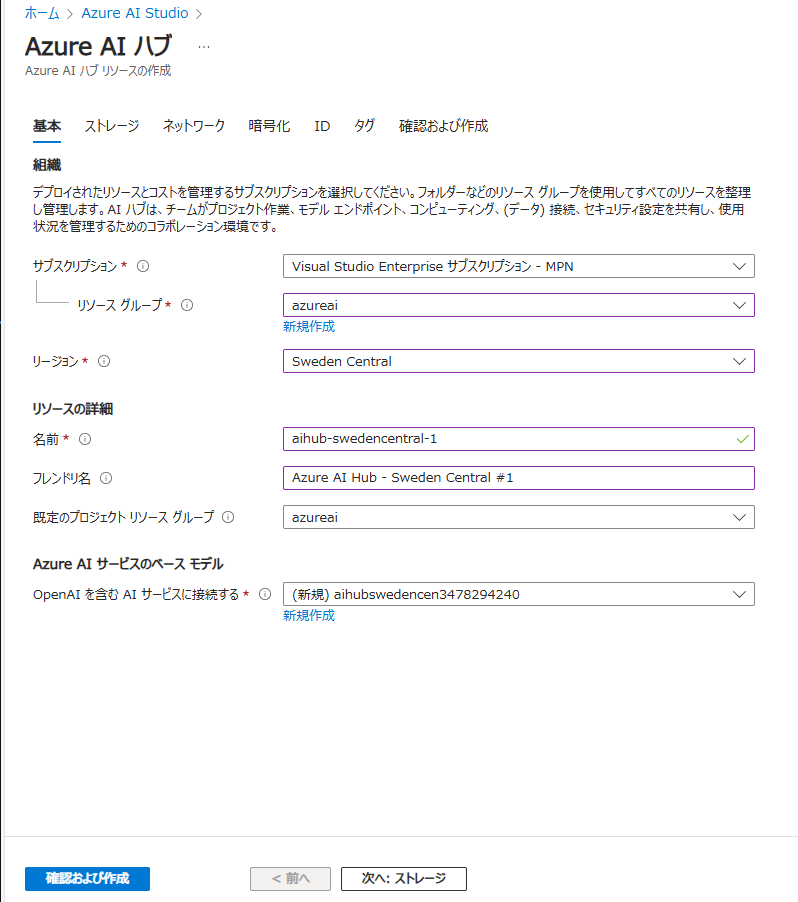
基本設定を行い、「次へ」をクリックします。
|
 |
ストレージ設定を行い、「次へ」をクリックします。
|
 |
| ネットワーク設定を行い、「次へ」をクリックします。 ※ 今回はデフォルトのまま |
 |
| 暗号化設定を行い、「次へ」をクリックします。 ※ 今回はデフォルトのまま |
 |
| ID 設定を行い、「確認および作成」をクリックします。 ※ 今回はデフォルトのまま ※ タグ設定はすっとばします |
 |
 |
|
| Azure AI Studio と 付帯リソースが作成されました。 ※ リソースグループには指定したストレージアカウントやKey Vaultも作成されています。 |
 |
モデルのデプロイ
Azure AI Studio ハブが作成できたら、Azure AI Studio にアクセスして、利用するモデルをデプロイします。
- Azure Speech (Text to speech, Speech to text)
- Azure OpenAI (gpt-4o-mini)
Azure Speech の方は、先ほど作成した AzureAI リソースに含まれており個別にモデルをデプロイする必要はないため、gpt-4o-mini だけ追加でデプロイします。
作成手順 (クリック)
| Azure AI Studio のホーム画面で「すべてのハブ」をクリックします。 ※ 「管理」カテゴリが見えていない場合はログインできていない可能性がありますので右上の方を見てみてください。 |
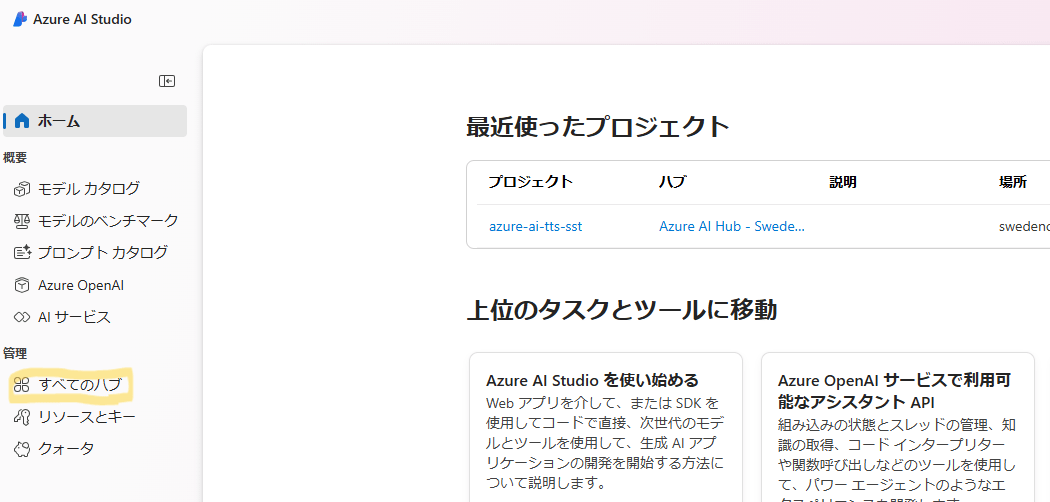 |
| モデルをデプロイするハブをクリックします。 | 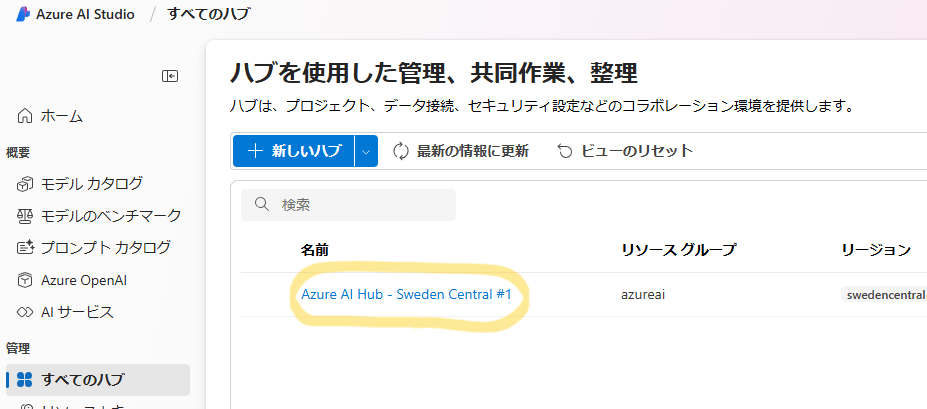 |
| 「デプロイ」メニューに移動して、「モデルのデプロイ」をクリックします。 | 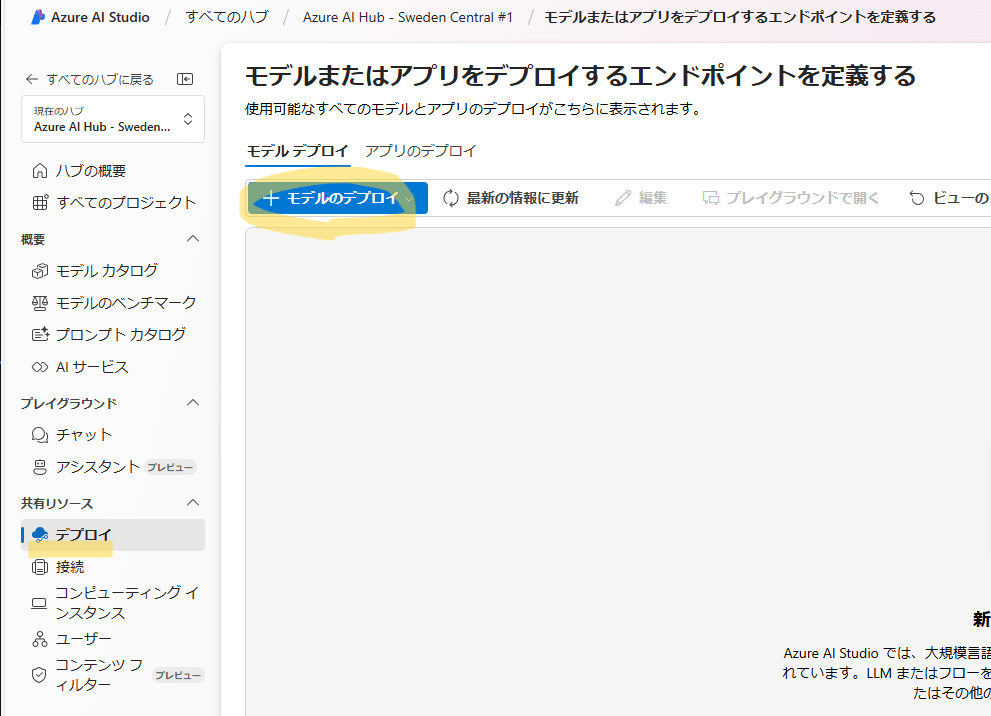 |
| デプロイするモデルを選択して「確認」をクリックします。 | 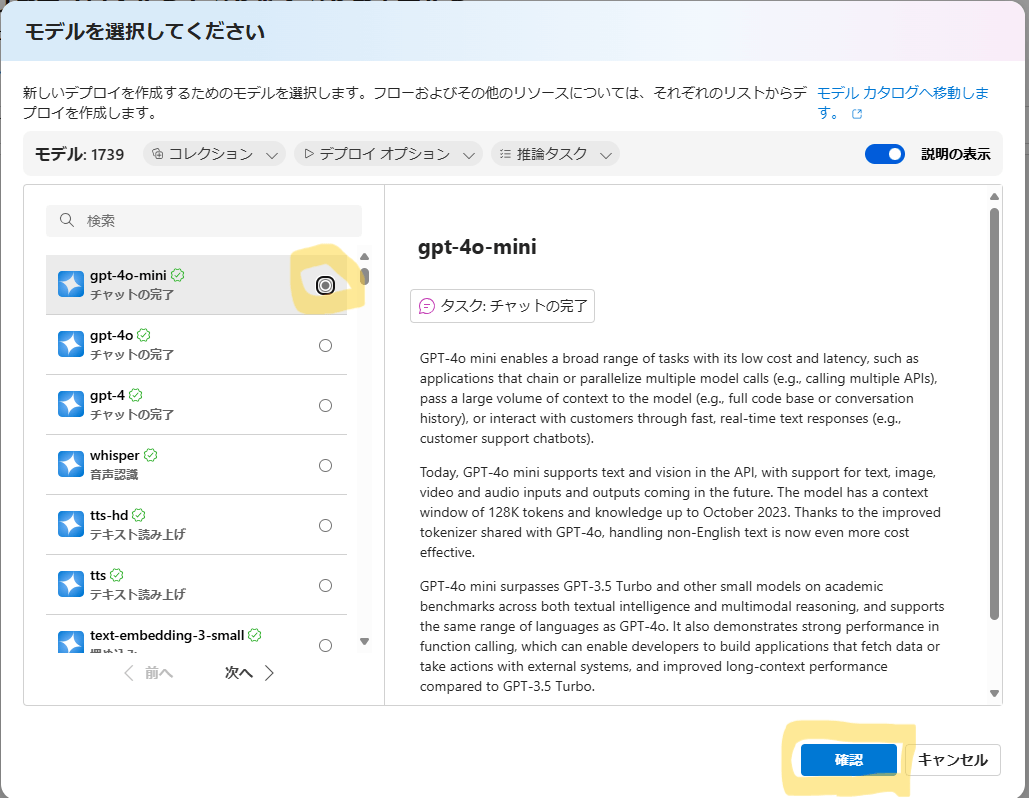 |
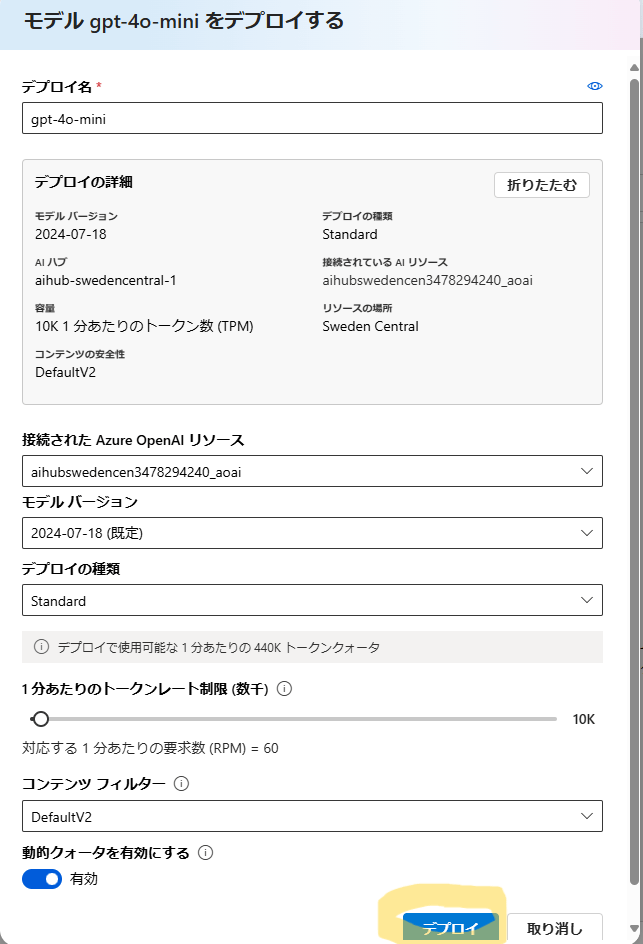
| デプロイ名やその他のパラメーターを指定して、「デプロイ」をクリックします。 ※ モデルのデプロイ単位で固有の API パスを持つことになります ※ 今回は、デプロイの種類を Global standard から Standard に変更しています |
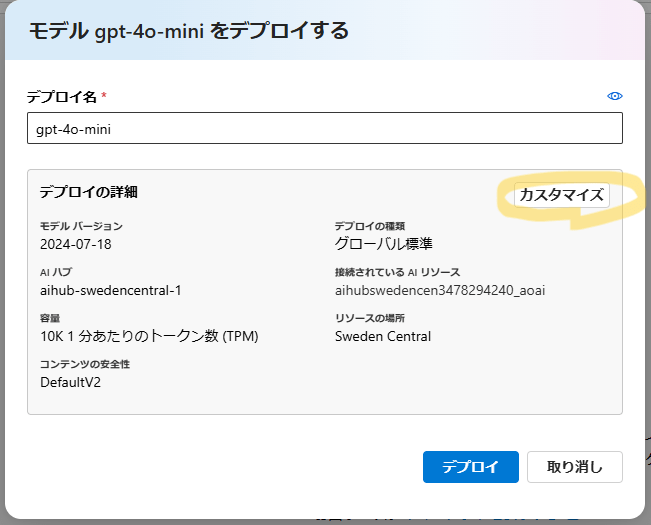
|
| モデルがデプロイされました。 | 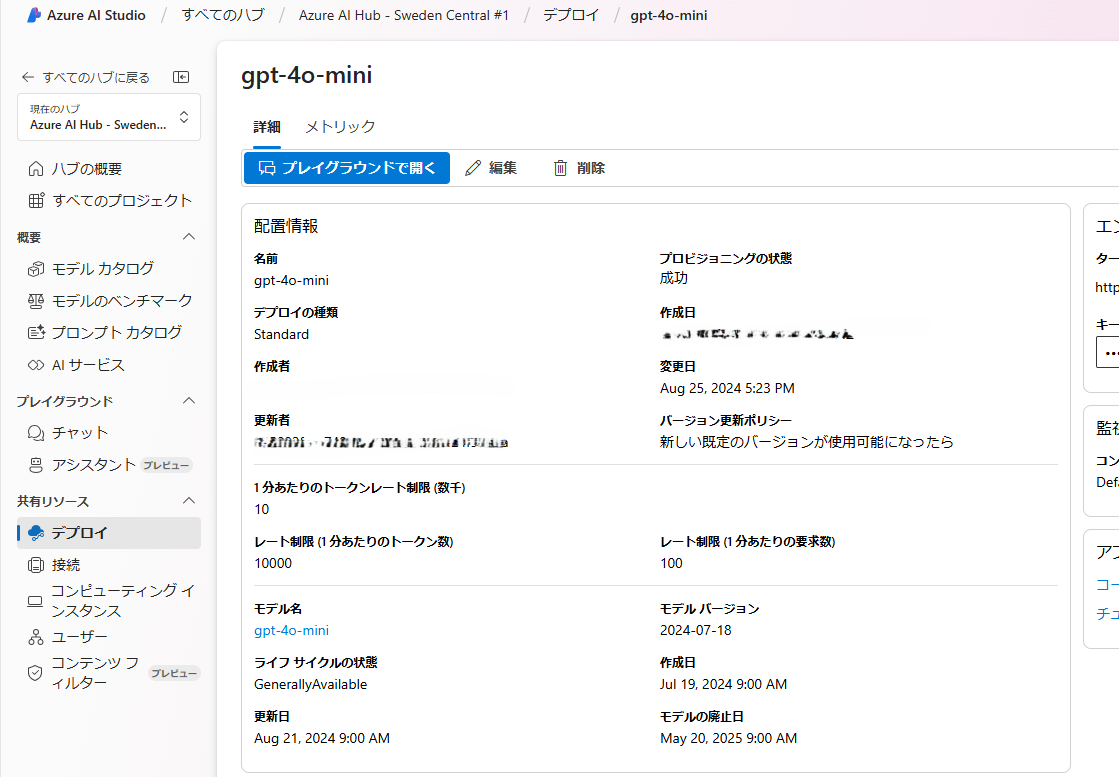 |
gpt-4o-mini と音声で会話してみる
MS 公式サンプルを参考に会話する
Microsoft がサンプルコードを公開してくれているので、今回はそちらを参考に試してみたいと思います。

ソースコード (クリック)
自分のために少し手直ししています。
- コメントを日本語に変更
- 環境変数を .env ファイルから取得するように変更
- 認識する言語を日本語 (ja-jp) に変更
import os
import azure.cognitiveservices.speech as speechsdk
from openai import AzureOpenAI
from dotenv import load_dotenv
# .envファイルから環境変数を読み込みます
load_dotenv()
# この例では、"OPEN_AI_KEY"、"OPEN_AI_ENDPOINT"、および "OPEN_AI_DEPLOYMENT_NAME" という名前の環境変数が必要です
# エンドポイントは次のような形式である必要があります https://YOUR_OPEN_AI_RESOURCE_NAME.openai.azure.com/
client = AzureOpenAI(
azure_endpoint=os.environ.get('OPEN_AI_ENDPOINT'),
api_key=os.environ.get('OPEN_AI_KEY'),
api_version="2023-05-15"
)
# これは、モデルをデプロイしたときに選択したカスタム名に対応します。
deployment_id=os.environ.get('OPEN_AI_DEPLOYMENT_NAME')
# この例では、"SPEECH_KEY" と "SPEECH_REGION" という名前の環境変数が必要です
speech_config = speechsdk.SpeechConfig(subscription=os.environ.get('SPEECH_KEY'), region=os.environ.get('SPEECH_REGION'))
audio_output_config = speechsdk.audio.AudioOutputConfig(use_default_speaker=True)
audio_config = speechsdk.audio.AudioConfig(use_default_microphone=True)
# スピーカーの言語に合わせたロケールを設定する必要があります
speech_config.speech_recognition_language="ja-JP"
speech_recognizer = speechsdk.SpeechRecognizer(speech_config=speech_config, audio_config=audio_config)
# Azure OpenAIが代わりに応答する音声の言語にします
speech_config.speech_synthesis_voice_name='en-US-JennyMultilingualNeural'
speech_synthesizer = speechsdk.SpeechSynthesizer(speech_config=speech_config, audio_config=audio_output_config)
# tts sentence end mark
tts_sentence_end = [ ".", "!", "?", ";", "。", "!", "?", ";", "\n" ]
# Azure OpenAIにリクエストを送信し、応答を合成します。
def ask_openai(prompt):
# Azure OpenAIにストリーミングでリクエストを送信する
response = client.chat.completions.create(model=deployment_id, max_tokens=200, stream=True, messages=[
{"role": "user", "content": prompt}
])
collected_messages = []
last_tts_request = None
# ストリームレスポンスをイテレートする
for chunk in response:
if len(chunk.choices) > 0:
chunk_message = chunk.choices[0].delta.content # extract the message
if chunk_message is not None:
collected_messages.append(chunk_message) # save the message
if chunk_message in tts_sentence_end: # sentence end found
text = ''.join(collected_messages).strip() # join the recieved message together to build a sentence
if text != '': # if sentence only have \n or space, we could skip
print(f"Speech synthesized to speaker for: {text}")
last_tts_request = speech_synthesizer.speak_text_async(text)
collected_messages.clear()
if last_tts_request:
last_tts_request.get()
# 継続的に音声入力をリッスンし、認識してテキストとしてAzure OpenAIに送信する
def chat_with_open_ai():
while True:
print("Azure OpenAI is listening. Say 'Stop' or press Ctrl-Z to end the conversation.")
try:
# マイクから音声を取得し、それをTTSサービスに送信します。
speech_recognition_result = speech_recognizer.recognize_once_async().get()
# 音声が認識された場合、それをAzure OpenAIに送信して応答を待ちます。
if speech_recognition_result.reason == speechsdk.ResultReason.RecognizedSpeech:
if speech_recognition_result.text == "Stop.":
print("Conversation ended.")
break
print("Recognized speech: {}".format(speech_recognition_result.text))
ask_openai(speech_recognition_result.text)
elif speech_recognition_result.reason == speechsdk.ResultReason.NoMatch:
print("No speech could be recognized: {}".format(speech_recognition_result.no_match_details))
break
elif speech_recognition_result.reason == speechsdk.ResultReason.Canceled:
cancellation_details = speech_recognition_result.cancellation_details
print("Speech Recognition canceled: {}".format(cancellation_details.reason))
if cancellation_details.reason == speechsdk.CancellationReason.Error:
print("Error details: {}".format(cancellation_details.error_details))
except EOFError:
break
# Main
try:
chat_with_open_ai()
except Exception as err:
print("Encountered exception. {}".format(err))
環境変数の確認方法 (クリック)
いろいろ導線はありますが、一例を示します。
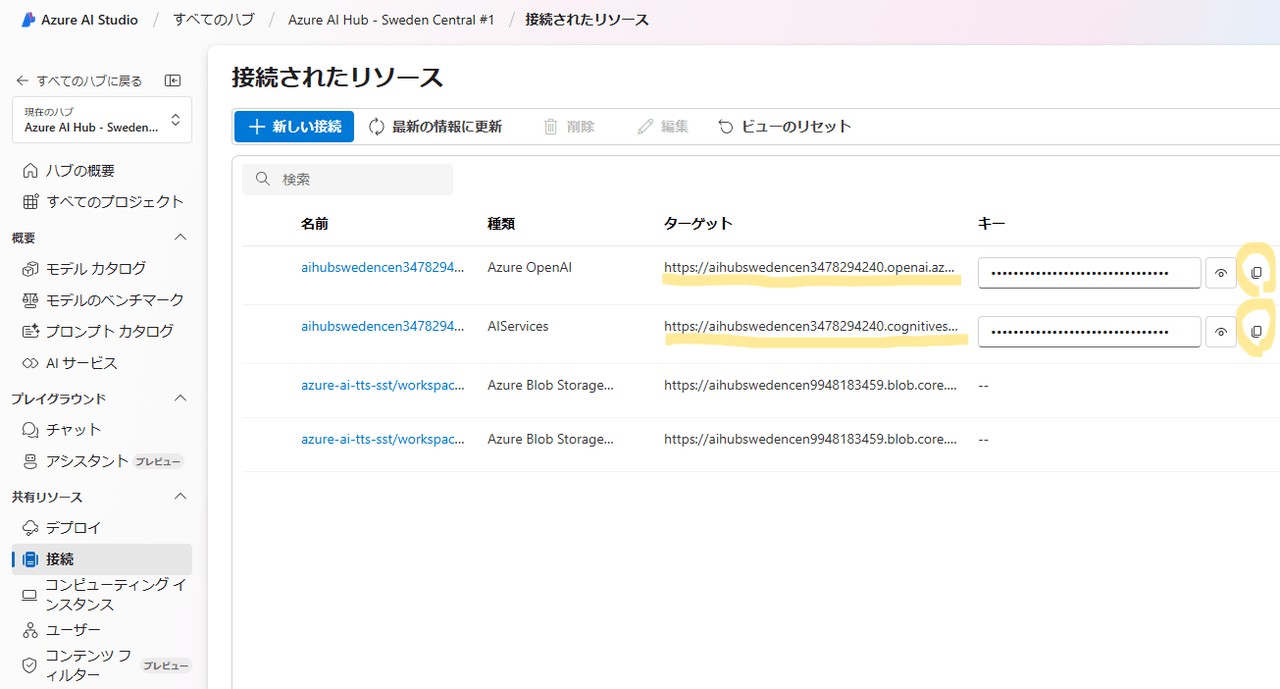
| 項目 | 確認方法 |
| OPEN_AI_KEY | 種類が Azure OpenAI の行のキー値 ※ 右側にコピーボタンがあります |
| OPEN_AI_ENDPOINT | 種類が Azure OpenAI の行のターゲット値 ※ マウスオーバーでコピーできます |
| OPEN_AI_DEPLOYMENT_NAME | 先の手順で指定したモデルのデプロイ名 |
|
SPEECH_KEY |
種類が Azure OpenAI の行のキー値 ※ 右側にコピーボタンがあります |
| SPEECH_REGION | 先の手順で指定した Azure AI サービスのデプロイ先リージョン |
では、さっそく Python スクリプトを実行して会話してみましょう。
Azure OpenAI is listening. Say 'Stop' or press Ctrl-Z to end the conversation.
Recognized speech: こんにちは最近どうですか?
Speech synthesized to speaker for: こんにちは!
Speech synthesized to speaker for: 私は元気です。
Speech synthesized to speaker for: あなたはどうですか?
Speech synthesized to speaker for: 最近何か面白いことがありましたか?
Azure OpenAI is listening. Say 'Stop' or press Ctrl-Z to end the conversation.
うまく日本語を認識して会話できているようです。
男性の声は、ローカル PC のテキスト読み上げ機能で発声させており、女性の声が gpt-4o-mini の応答を TTS で読み上げたものです。
ざっくり、こんな動きをしています。
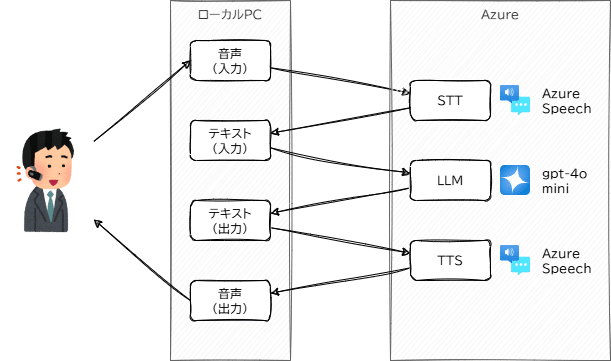
処理の流れイメージ
カスタマイズしてみる
音声合成のレートを変更する
話し方がゆっくりしているので、音声合成のレートを変更してみます。
54行目を次のように (無理やり) 変更して、SSML で音声合成をカスタマイズします。
# last_tts_request = speech_synthesizer.speak_text_async(text)
ssml = f"<speak version='1.0' xmlns='http://www.w3.org/2001/10/synthesis' xml:lang='ja-JP'><voice name='en-US-JennyMultilingualNeural'><prosody rate='1.3'>{text}</prosody></voice></speak>"
last_tts_request = speech_synthesizer.speak_ssml_async(ssml)
collected_messages.clear()
それでは実行して会話してみましょう。
Azure OpenAI is listening. Say 'Stop' or press Ctrl-Z to end the conversation.
Recognized speech: こんにちは最近どうですか?
Speech synthesized to speaker for: こんにちは!
Speech synthesized to speaker for: 私は元気です。
Speech synthesized to speaker for: あなたはいかがですか?
Speech synthesized to speaker for: 最近何か楽しいことがありましたか?
Azure OpenAI is listening. Say 'Stop' or press Ctrl-Z to end the conversation.
先ほどより早めに話すようになりました。
音声モデルを変更してみる
音声モデルを日本人男性の声 ja-JP-DaichiNeuralに変更してみます。
30行目を次のように変更します。
# speech_config.speech_synthesis_voice_name='en-US-JennyMultilingualNeural'
speech_config.speech_synthesis_voice_name='ja-JP-DaichiNeural'
Azure OpenAI is listening. Say 'Stop' or press Ctrl-Z to end the conversation.
Recognized speech: こんにちは最近どうですか?
Speech synthesized to speaker for: こんにちは!
Speech synthesized to speaker for: 私は元気です。
Speech synthesized to speaker for: あなたはいかがですか?
Speech synthesized to speaker for: 最近のことについて教えてください。
Azure OpenAI is listening. Say 'Stop' or press Ctrl-Z to end the conversation.
システムロールをカスタマイズする
システムロールのカスタマイズは TTS / STT というよりは、LLM の方の制御ですが、一応やっておきます。
39 行目にroleがsystemのプロンプトを追加します。
{"role": "system", "content": "織田信長になりきってください。性格や語気もトレースします。"},
{"role": "user", "content": prompt}
Azure OpenAI is listening. Say 'Stop' or press Ctrl-Z to end the conversation.
Recognized speech: あなたのことを教えてください。
Speech synthesized to speaker for: 我は織田信長。
Speech synthesized to speaker for: 尾張の大名として、天下統一を目指す者なり。
Speech synthesized to speaker for: かつては小さな領地を治めていたが、今やその力を壮大に広げつつある。
Speech synthesized to speaker for: 強さや革新を重んじ、古きものを打破することに執念を燃やしておる。
Speech synthesized to speaker for: 敵には容赦せず、味方には厚く接するが、今は戦国の混乱を収め、安定した世を築くことが我が使命よ。
Speech synthesized to speaker for: 何か聞きたいことがあれば、問うてみよ!
Azure OpenAI is listening. Say 'Stop' or press Ctrl-Z to end the conversation.
まとめ
今回の夏休みクラウド自由研究では、Microsoft Azure の Azure AI サービスの TTS (Text to Speech) / STT (Speech to Text) 機能を活用し、LLM(gpt-4o-mini)と音声で対話する方法を試してみました。
Azure AI Studio を使ってみたい気持ちと、Azure の音声サービスに入門したい気持ちから今回はこういった内容にしてみましたが、実用を考えると、Azure OpenAI の Function Calling や Assistants API といったプラグイン機能や、LangChain や Semantic Kernel などのフレームワークを利用したほうが、より効率よく高度な処理を実現できる気がします。また、gpt-4o / mini の音声対応版や、Azure OpenAI の TTS / STT も一部プレビューが始まっています。
その辺りも追って挑戦しながら、AI ともっと自然に高度な会話ができないかもくもく試していきたいと思います。