こんにちは。okodoooonです🌵
ラスベガスに来てから、同行しているメンバーと手分けをしてセッションを聞いて、知見をまとめる作業に追われており、なかなかハードな日々を過ごしておりました。
今回は初日に聞いた5つのセッションがどれも知見に溢れるものだったので、そちら紹介していきたいと思います💪
スライドが公開されたり他メンバー担当分の記事が上がり次第リンクなど追って貼っていきます。(2日目以降のやつも頑張って書いております)
目次
- Data alone is not enough(訳:データだけでは不十分である)
- Breaking the mold: A smarter approach to data testing(型破り:データテストに対するより賢明なアプローチ)
- How dbt transformed FinOps cost analysis at Workday(訳:dbtがWorkday社のFinOpsコスト分析をどのように変革したか)
- Surfing the LLM wave: We can't opt out and neither can you(訳:LLMの波に乗る:私たちも、あなたも避けることはできない)
- Semantic layers: The next data revolution or just overrated hype? (訳:セマンティックレイヤー:次のデータ革命か、それとも過大評価された流行か?)
Data alone is not enough(訳:データだけでは不十分である)
発表者:Preston Wong (Analytics Engineer @ Settle)
概要
データを提供できる組織や環境を作るのではなく、洞察を提供できる組織や環境を作るべきで、 理想の組織に改善されるために、Settleが取り組んでいるJTBDというフレームワークの紹介をしていました
セッション内容の紹介
以下のような画像とこちらブログの引用ともに
レポーティング業務はデータ組織にとってゲートウェイドラッグのようなものだ。これらのレポートは本当に意味のあるものなのか?変化を促しているのか?実際に使用されているのか?誰かがそれを見て、2秒で終わるために7時間も費やすのはなぜだろう?最近のデータイニシアチブは、情報へのアクセスを民主化することに重点を置きすぎており、ビジネスへの影響を促進することに十分に注力されていない。どんなに多くの情報があっても、それだけでは組織の変革を促すことはできない。
という強烈なメッセージを発信していました。


とても耳が痛いですね。
「ビジネスインパクトをいかに生み出すか」という観点なしに、ただデータを出力し続けるチームになってしまうことへの懸念を紹介してくれました。
それらの懸念を紹介した後に「データチームがどのようにしてビジネスのデータが持つ潜在能力を最大限に引き出せるのかを考える必要がある」と続き、
レポーティング業務から抜け出せない理由はコンテキストを持っていないことが多いからと説明していました。
良い例として、Q3の新規アクティブ顧客数が安定して増加しており、最近の月では20%増加したことが挙げられます。データ担当者がこれに気づいたとしても、直接的な文脈を持っているとは限りません。このデータには、最近の企業買収があったことや、その顧客基盤を取得したことが含まれておらず、それが20%増加の理由です。この説明はデータ自体では行えず、他の誰かが説明する必要があります。つまり、なぜそうなったのかを答えるのは難しいのです。
Settleではデータチームを適切にステップアップさせていくためにデータ組織のJTBD(JobToBeDone)を設定しており、その運用によってレポーティング組織から適切に脱却しつつあると紹介しています。


- JTBD of Modern Data Team
- データの活用
- メトリクス管理
- プロアクティブなインサイト
- 実験のドライブ
- データとのインターフェース
紹介されていた各要素ごとの課題例のproblemとimpactがこちらです(ちょっと文量が多いので畳んでいます)。
データの活用(クリックすると展開)
- データの活用
- オペレーショナルデータを必要とするチームに提供すること
- ex.
- マーケティング部門からのリクエストで「ハブスポットで解約した顧客に自動メールを送信し、タッチポイントとアウトリーチを行いたい」
- 解決したHow
- 多様なソースからのデータを、主に内部データを含めて、dbtモデルに統合。このデータマーケットは、ビジネスの包括的な表現として機能し、意思決定に不可欠な業務属性、将来のフラグ、メトリクスおよびSSoTを提供。
- リバースETLと組み合わせることで、各チームの好みや主要なSaaSツール(SalesforceやHubSpot、Intercomなど)にシームレスに同期されたSSoTを持つことが可能となり、効率的なデータ活用とリアルタイムのインサイトが実現可能。
- インパクト
- このワークフローを合理化し、データを取得して作業を行うのに何時間も費やす代わりに、数分で済むようになった。
- このアプローチにより、彼らはツールセットを簡素化し、結果として効率的なセルフサービスモデルを実現。
- マーケティングチームは最新の関連データに直接アクセスでき、タイムリーかつ正確に実行できるようになった。
メトリクス管理(クリックすると展開)
- メトリクス管理
- 共有された定義と重要な事実の基準を作成すること
- ex.
- もしファイナンスのステークホルダーに尋ねれば「アクティブカスタマー」とは、自分の銀行口座を接続した人だと言うでしょう。マーケティングに聞けば「アクティブカスタマー」は、完全なオンボーディングフローを完了した顧客だと言います。しかし、プロダクトに尋ねると「アクティブカスタマー」は、最近プラットフォーム上で活動があった顧客だと言います。では、どれが本当に正しいのでしょうか?
- 解決したHow
- セマンティックレイヤーを活用することで、これらのメトリクスを明確に定義し、文書化。
- インパクト
- Hexのようなツールや、ExcelやGoogle Sheetsを好むステークホルダーがアドホックレポートを作成する際にも使用可能に。
- 指標に関する煩わしい問い合わせ対応が大幅に減少。
プロアクティブなインサイト(クリックすると展開)
プロアクティブなインサイト

- プロアクティブ(=先手を取れる)ようなデータの提供 (= 先行指標を提供)
- ex.
- 顧客の解約が若干増えているが、どのデータが私たちが顧客を維持するためによりプロアクティブになる手助けをしてくれるか?
- 解決したHow
- 戦略的リーダーを特定、ビジネスユニットと密接に連携
- 「アシュアランススコア」を開発
- 顧客がサービスを解約する可能性を定量化し、チームが迅速に行動を起こすためのアラートを受け取れるようにする
- インパクト
- 。このデータ駆動型のアプローチにより、リスクのある顧客を早期に検出し、ターゲットを絞った介入措置を講じることが可能に。
- 顧客のライフタイムバリューを向上させ、会社の長期的な成功と持続可能な成長において重要な役割を果たすことに成功。
実験のドライブ(クリックすると展開)
実験のドライブ

- プロアクティブなインサイトの発見と連携しながら、ビジネスに対して測定可能な影響を与えるための実験を推進すること
- ex.
- 現在使用している機能に問題が発生しました。リスクを高めたり、ビジネスへの影響を評価したりするために利用できるデータポイントはあるか?
- 解決したHow
- 組織内のステークホルダーと協力して、実験を展開
- インパクト
- 全体のスコアを向上させることができ、非常に洞察に富んだ重要な結果を得ることに成功
データのインターフェース(クリックすると展開)
- データのインターフェース
- ビジネス全体にわたるチームメンバーに必要な情報や結論を提供し、彼らがそれを活用できるようにすること
- ex.
- この収益はどこから来ているのか?モデルでどのように定義されているのか?この数字を週次レポートに使用しても良いのか?
解決したHow
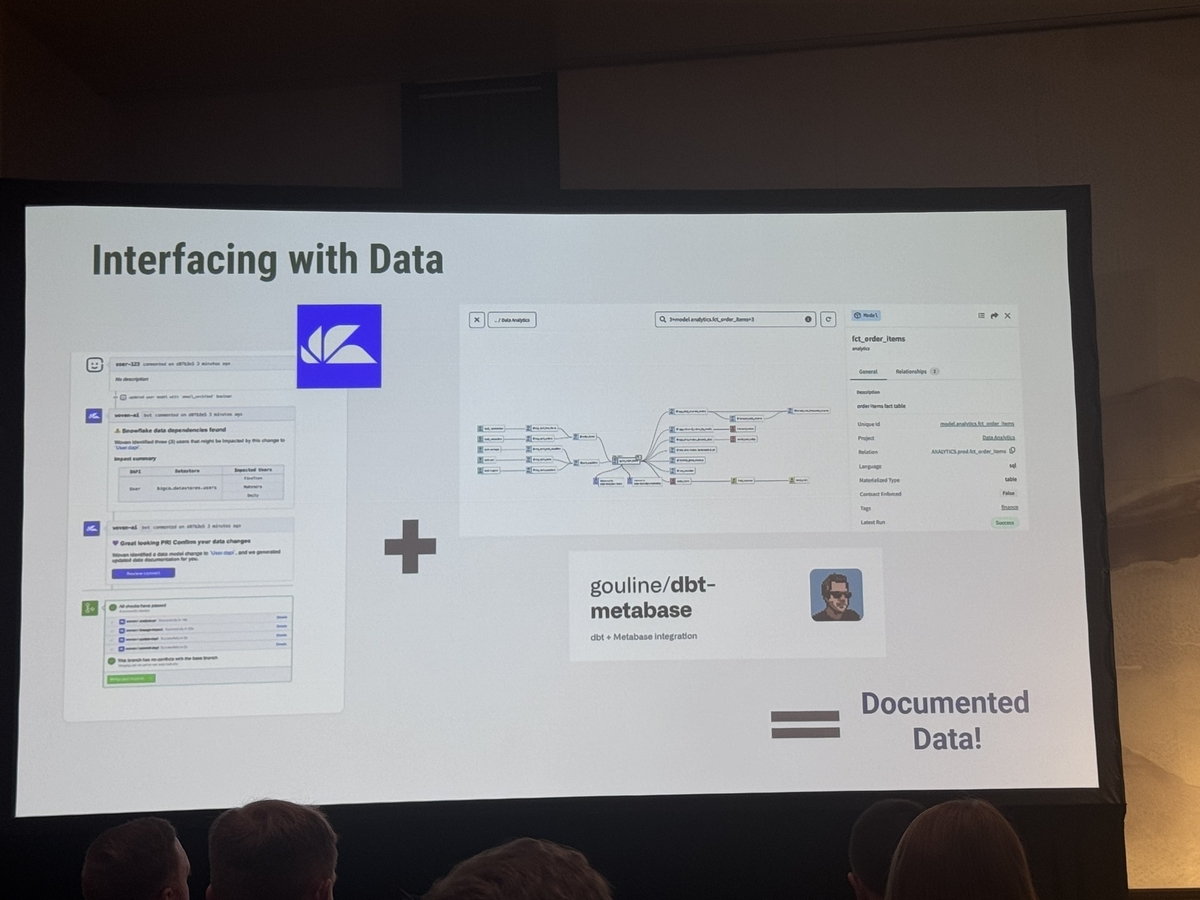
- 彼らが自分自身で質問を探求し、答えを見つけるために必要なツールを提供できるようにする
- description生成をAIに実行してもらいその内容をチェックするプロセスを実行する
- dbtとmetabaseを接合して、metabase上でdbt exploreと同様のメタデータを閲覧可能とする
- インパクト
- 最終的にデータチームのレポーティング作業負担を軽減
JTBDのマトリクスは最終的にこのような形になります。
 Settle社による所見
Settle社による所見
- 生のデータ出力だけでは不十分であり、JTBDフレームワークは、ステークホルダーのコンテキスト、動機、および具体的なニーズを理解することが、データを実行可能なインサイトに変換し、ビジネスを推進するために重要である。
- 私たちのステークホルダーを支援するために、データの活用を推進し、より効率的なセルフサービスモデルを実現するべきである。これにより、ステークホルダーは自身の専門分野で最も得意なことに集中でき、データの整理に関する煩わしさから解放される。


感想
- 事業会社のデータ部署に勤めている僕としては、めちゃくちゃ刺さりました。
- JTBDを弊社なりに構築しつつ、もっとアナリストやDSと協働して、意思決定に刺さる指標がビジネスに素早く届けられるような状態を構築しなきゃなあ。
- なぜ早くデータを出せるようにするのか、なぜメタデータを拡充するのか、なぜこのようなインターフェースを構築するのか、などをしっかりとビジネスインパクトと紐づけた上で、今後意思決定をしていけるようになれる気がしています!
Breaking the mold: A smarter approach to data testing(型破り:データテストに対するより賢明なアプローチ)
発表者:Anton Heikinheimo (Senior Data Engineer @ Aiven) , Emiel Verkade (Senior Analytics Engineer @ Aiven)
概要
僕たちはdbt testを書きまくっているけれど、デリバリーが遅くなることの方がデータ品質において深刻なケースが多いよね。 warningの利用やWHERE句による代替で不要なテストを消してデータ品質を向上させていこう
セッション内容の紹介
朝にSlackを開いて、dbtパイプラインのfailedの通知を確認して、トリアージを決めて、ステークホルダーと合意形成して、解決策を実装・テストしてデプロイする。そんな朝がたくさんあるのはおかしい。dbtのデータテストのベストプラクティスに従っているはずなのに
そんな言葉から始まった本セッションでは、以下のようなMEMEでテストを書くこととデリバリー品質の向上が一致しないことに対する課題感を説明していました。


現状のdbtテストを単純に実装していくと、以下のような課題点があると説明しています。
- テストが落ちるとその下流のビルドがすべて落ちるので、データの品質が落ちる。
- 特定のモデルが更新される一方で、他のモデルが更新されないことがありロジックによっては致命的である。
- buildコマンドではテストは落ちるが、run → testの順番なのでrunによって不正なテーブルが出力される。
データテストが何であるか、そして典型的なデータセットアップがどのようなものか を以下の図を用いて説明していました。

この図における右と左のアサーションテスト(正常な場合に予測されるものと一致していることを確認するテスト)の役割を整理すると、以下のように記述できます。
- 左側のアサーションテスト
- ソースデータに関する仮定をテストするのに役立ちます。
- このデータは、外部および内部のソースから来る可能性があり、データコントラクトやQAフレームワークが組み込まれていないこともあります。
- 右側のアサーションテスト
- 私たちが適用したロジックに関する仮定をテストするためのもの。
- すでにソースデータをテストし、それが期待に合致していることを確認していると仮定しているもの。
- 入力データが検証された後、出力データをテストすることで、私たちはロジックの整合性を確認できる。つまり、dbtプロジェクトで行ったすべての変換が、期待した結果をもたらすことを確実にするためのテスト。
例えば左側のアサーションテストで落ちた場合は図中の Data と記載されたテーブルに悪いデータが留まり、左のアサーションテストが解決されるまで更新されない ショートサーキット が発生します。
ただし、テストの重要性が不明瞭で、モデルのテストに対して厳しい要件を持つことでプロセスを標準化しようとしたり、テスターなどのメトリクスを持つことで対処しようとしたりする場合、テストが品質に与える影響を無視しているとも言えます。
上流のプロダクトやSaasの変化や変更は加速しており、テストは「そのテスト作成時点のアサーションでしかない」という主張です。なのでよく落ちるテストに対しては削除することが合理的な場合があり、落ちるケースに対しては以下のような対応をしてしまうとのことでした!
<= before | after =>


このようにフィルターとして扱ってしまうことで、テストによるデータ鮮度の品質を落とさず、そもそも間違ったデータが渡らないようにしてしまおうという発想のものです。
テストはデータ基盤のしなやかさを構築するためのものでもあり、そのためにSettleのチームではテストのデフォルトの重要度を「警告」に変更したとのことでした。確かにこのようにすれば、上流の変化に“しなやかに”対応しつつデータ鮮度の品質は落とさずにいられますね。
また、このテストではなくフィルターを記載する取り組みをスケールさせるために、マクロを使用していると話していました。
<= before | after =>


↑こんな感じでマクロを呼び出せるようにして、外部キー制約やaccepted_valueなどをフィルターとして表現可能にしているとのことです!
最終的に以下のようにテストを減らしつつ、しなやかな構成に変更できたと締めくくられています!

感想
- 弊社もdbt + Lookerで構築されたセマンティックレイヤーがかなりのオペレーションに活用されており、こちらのパイプラインの停止がビジネスの停滞に繋がりうるため、とても参考になる発表でした!
- 外部に公開する数字とか請求金額とか絶対に間違えちゃいけないもの以外は、実は多少ずれていても意思決定に大きく影響しないものもありますもんね!
- 主キー制約とかまでフィルターでやっちゃうのは執念が感じられて笑っちゃったのと、弊社だとSalesforceみたいなデータソースの自由入力や意図しないデータ入力にパイプライン全体が影響を受けていたりするので、すぐにでも実践を検討したいです!
How dbt transformed FinOps cost analysis at Workday(訳:dbtがWorkday社のFinOpsコスト分析をどのように変革したか)
発表者:Eric PuSpeaker (Senior Software Engineer @ Workday), Pattabhi Nanduri ( FinOps Data Engineer @ Workday )
概要
DBTとJinjaマクロを活用してAWSやGCPを中心としたプラットフォーム上でのコスト要因を把握 DBTマクロやテンプレートを用いることで、ユーザーの負担を軽減し、データモデルの構築から実装までを自動化 モデル定義を通じて、ドキュメンテーションの自動生成やテストの自動実行

- Workday社でのビジネス上の課題
- コストとコストドライバーの理解: AWSやGCPから発生するコストやその要因を把握。
- コスト最適化の機会の特定: コスト削減のための最適化ポイントを特定。
- コストの割り当て:アプリケーションサービス、顧客、テナントごとにコストを適切に割り当て。
- コストの予測:未来のコストを見積もり、予測する。
- レポートとセルフサービス機能: 自己サービス型のレポート作成、チーム開発、行レベルアクセスやオブジェクトレベルアクセスなど、SOXコンプライアンスに対応したアクセス制御。
- 作成したダッシュボード(写真撮り忘れました)
- 今日の作業全体が表示され、コンピューティング、ストレージ、データベースなど、さまざまな支出の詳細が表示されているもの。同様に、月ごとのコンピューティングトレンドも表示されているもの。
- コンピュータに関連する支出の詳細が表示されているもの。現在の四半期での使用状況を見ることができ、プロセッサやインターネット利用料などがわかるもの。
- ダッシュボードのDimension
- 階層型の製品Dimension
- 最初のレベルでAWS製品とGCP製品といった大分類で区切り、7つのレベルにブレークダウンする形で分割しているもの。
- 階層型のプロジェクトDimension
- マーケットや人、組織に関する情報が含まれる。人と組織の情報は、プラットフォームの所有者や責任者に関連している。
- 階層型の製品Dimension
全体のデータ構造はこんな感じです。

ユーザーが早い段階で次元カラムとファクトカラムを明確に定義するようにして、カラムのタイプを一度だけ定義すれば、その情報がデータマートの最終段階まで引き継がれるようにしているとのことです。 モデルの概要を宣言するだけで、残りのコードが自動的に生成され、モデルが正しく効率的に動作するように設計されています。
こちら紹介されていたサンプルクエリ。





lightdashを活用しているので、その辺りのアクセス制御もマクロを活用して行っているとのこと。
- 動的なユーザーフィルター
sql_filter: {account_project_id in [select account_project_id from cpus.flops.access_control_bridge where login_user=${lightdash.attributes.user_name}]}
- ユーザーアクセスコントロール
- name: effective_discount_column data_type: numeric meta: dimension: required_attributes: is_opus_super_user: "true"
- name: aws_cur_table meta: required_attributes: is_opus_super_user: "true"
- このような構成にしたメリット
- ユーザーに多くの教育を必要としない。
- パーティショニングが自動で切られてテストも自動で追加されるため気にしなくても良くなる。
- 統一された生成方法なのでドキュメンテーションが自動的に生成される仕組みを導入できた。
- 情報をリネージグラフと組み合わせて、実行計画を作成し、それをAirflowに送信、実行計画に基づいて、Airflowはクラスタの動的スケーリングを行い、各ステージのワークロードに応じた最適なリソースの割り当てが可能。
- ユーザーに多くの教育を必要としない。
感想
- クラウド料金を探索できるデータモデリングをする際のDimensionの切り方や、主要なコストはそれ単体をFactとして切り出して名前をつけてしまっているところなんかが地味に参考になりました!
- マクロ化には賛否色々ありそうですが、テストが自動で設定されるようになっていたり、DBTが生成するドキュメントに自動的に反映するような仕組みになっていたりして、ここまでやりきってしまえるならメリットが大きそうだなあと思いました!
Surfing the LLM wave: We can't opt out and neither can you(訳:LLMの波に乗る:私たちも、あなたも避けることはできない)
発表者:Amanda Fioritto(Senior Analytics Engineer @ Hex), Erika Pullum(Analytics Engineer @ Hex Technologies)
概要
データ分析&BI統合ツールのHexにできたmagicと呼ばれるLLMによるサポート機能をHex社自身が使い倒して LLMによるクエリ生成の精度をどうしたらどのくらい向上させることができるか試行錯誤したレポートです
セッション内容の紹介
Hex社にはドッグフーディングの文化があるので、リリースした magic というLLMによるクエリサポート機能を自社でどこまで活用できるか常に使用してきたそうで、社内のmagic機能に「パトリック」という名前をつけているそうです!
パトリックの精度は論文やLLMモデルの公式発表などによると90%であるとのこと。

パトリックをオンボーディングする時の仮説
⇒ 人間の同僚とそれほど違わないかもしれない。
⇒ 人間のステークホルダーにとってデータが役立つように工夫することが、パトリックが新しい役割で成功する手助けにもなるかもしれない。
⇒ データ組織の役割はステークホルダーにとって使いやすいデータ資産を作ることであり、現在ステークホルダーにはパトリックも含めている。
パトリックの評価の比較対象はspiderというtext-to-sqlのオープンソースとのことです。
パトリックの評価を比較可能にするために「前四半期に予約された会議の数はいくつですか?」という質問を投げることにしたが
dim_datesというテーブルがJOINできていなかった。- 会議の日を特定するカラムを指定できていない。
など人間のステークホルダーからもよく寄せられる質問のようなミスをした。
「MMセグメントにいる顧客数は何人ですか?」という質問にパトリックが答えられるためには「顧客」とは何か、「セグメント」とは何を意味するのか、「MM」が何を指すのかを理解する必要がある。
パトリックのチューニング方法
- 「エンフォースメント」というツールを使ってDWH内のアクセス範囲を拡げる、または狭める。
- ドキュメンテーションへのアクセスを許可してカンニングペーパーありの状態にする。
アクセス範囲のチューニングの実験結果
- アクセス範囲を全snowflakeテーブルに拡大 ⇒ 正答率10%
- アクセス範囲をHex社内のテーブルに限定 ⇒ 正答率38%
- アクセス範囲をHex社内のテーブルに限定して、よく使われるテーブルにフラグをつける ⇒ 正答率46%
ドキュメンテーションの実験をする際に、ドキュメントの品質にも差をつけた。
- 低品質:
segment_typeはEnterpriseやMid-Marketなどの値を含むことができる。 - 高品質: 低品質なものに加えて同義語も提供します。例えば、「Small Midsize(中小企業)」は「SMB」とも呼ばれるし、「Mid-Market」は別の呼び方もある。
ドキュメントの品質によるチューニングの実験結果
- 低品質のドキュメント ⇒ 正答率33%
- 高品質のドキュメント ⇒ 正答率51%

セマンティックレイヤーを使った場合の実験結果
- 正答率75~88%
実験結果を受けてHex社の見解
- MMをMidMarketと変換できるような人なら、パトリックのサポートをうまく活用し、自分たちの作業を進められるかもしれません。
- データチームにとって、これらのツールがどのように、そしてなぜ機能するのか、またそれが質問に答えようとする人たちにとって役立っているのかを理解することが重要です。
- データウェアハウスの整理やモデルのドキュメント化やコンテキストの整理は必要です。
- 重要なテーブルをマーキングする作業と高品質のドキュメント整備がそこまで差異がなかったのは驚異的でした。
- LLMをうまくクエリビルダーとしてワークさせたいならセマンティックレイヤーの導入が必要そう。

感想
- LLMをクエリビルダーとして使う想像は誰もがしたと思いますが、(僕も去年試行錯誤しましたhttps://speakerdeck.com/okodoon/slackkarazi-you-yan-yu-deshe-nei-zhi-biao-wowen-ihe-waserarerubotwozuo-ritaka-tuta)実際にこれをすると何%改善するのかというところまで定量的に示してくれている実例は滅多にないので素晴らしい発表だと思いました!
- セマンティックレイヤーを作っていくことで、社内のクエリコスト低下だけでなくLLM活用まで見据えられそうなことが明確に示唆されたので、セマンティックレイヤー整備を引き続き頑張ります!
- LLMをステークホルダーと捉えてマシンリーダブルなデータ基盤に寄せていくって発想は今後のデータ基盤にきっと求められていく要素なんだろうなあと思いました!
Semantic layers: The next data revolution or just overrated hype? (訳:セマンティックレイヤー:次のデータ革命か、それとも過大評価された流行か?)
発表者:Katie Hindson(Head of Product and Data @ Lightdash)
概要
dbtによってトランスフォーメーションが容易になったが課題が多く、数字の不整合の解消、指標の統一、LLMの活用といった課題を解決するためにセマンティックレイヤーが有用であると思われる。 ユニバーサルなセマンティックレイヤーを参照できるツール(Lightdash)がセマンティックレイヤーの活用方針としては望ましい
セッション内容の紹介
セマンティックレイヤー不在における課題点を以下のようなスライドで紹介しています。



- クエリごとに同じ指標を出しているはずなのにバラバラになってしまう。
- 指標の定義が社内で噛み合わない(アクティブユーザーのアクティブって何?「使用」の定義は?)
- LLMをデータ基盤で活用するためには同じ質問に対して同じ答えが得られることが重要。
そして、今日のセマンティックレイヤーは以下のようにスタンドアロン型かバンドル型かに分類されるとの主張をしていました。

- スタンドアロン型
- ex. ATSCALE, Minerva, cube, dbt Semantic Layer
- インテグレーションが不足しており、ビジネスユースケース足り得ない。
- バンドル型
- ex. Lightdash, MicroStrategy, Looker, SAP
- BIツールに統合されたセマンティックレイヤー。他のモダンデータスタックとのインテグレーションが不足している。
セマンティックレイヤーの使用体験として必要なもの
- メトリクスファーストの探索(テーブルを意識しないで指標名だけで思考が完結するような体験)。
- データカタログでメトリクスの意味が確認できること。
- データカタログから、簡単にメトリクスの探索ができること。
これらの体験を満たしているセマンティックレイヤーとして、Airbnb社が内製しているMinervaがとても優れていると述べていました。(Minervaに関するAirbnb社の記事はこちら)



セマンティックレイヤーのユニバーサル性として必要なもの
- スタック全体に適用できるほど汎用的
- 必要なすべてのツールと統合可能
今後セマンティックレイヤーがデータ基盤の中心となるため、あらゆるデータスタックと接続可能な状態を構築する必要があるとのことでした!

感想
- 結構ポジショントークみが強く「ユニバーサルって言葉をLightdashにだけ使うのは言葉として強すぎるのでは?」という指摘をQAで受けていて少し面白かったです。
- Looker上にセマンティックレイヤーを構築している弊社としては、データカタログからの滑らかな探索体験みたいなところは実現が難しそうで、Lightdashも全然候補になってくるなと思いました!
- Gemini on Lookerを超えるセマンティックレイヤー✖️LLMの体験を創出できるのか、これからもWatchし続けていきたいです。