こんにちは、AI在庫管理の開発チームでバックエンドエンジニアをしているもっち(@mottyzzz)です。
AI在庫管理では、プロダクトのインフラとしてAWSを使用しています。その中でも特に重要なサービスのひとつがCloudWatchです。システムの監視やログ管理に不可欠なツールとして日々活用していますが、実はAWS利用料の約15%をCloudWatchが占めているという状況でした。
先日コストを確認したところ、ただでさえコストの割合が多かったCloudWatchの利用料が前月比で20%以上増加していることが判明しました。
この傾向が続けば年間で予想以上のコスト増になることが懸念されました。
そこで、以下の流れでCloudWatchの使用状況を分析し、効果的なコスト削減策を検討することにしました。
- コストが発生しているオペレーションや用途の確認
- 影響の大きいロググループの特定
- ロググループ内の何のログが多いのかの確認
本記事では、私たちが実際に行ったコスト削減についての分析から改善までの取り組みを紹介します。同じようなことで悩んでいる方々の参考になれば幸いです。
この記事はカケハシ Advent Calendar 2024 の 18 日目の記事になります。
コストが発生しているオペレーションや用途の確認
CloudWatchのどこにコストがかかっているかを確認するために、コストが発生しているオペレーションや用途を確認します。
AWS Management Consoleにログインし、まずはCost Explorerで全体像を把握します。
Cost Explorerは請求情報を視覚的に分析できる強力なツールです。
確認したい日付け範囲を指定し、サービスにはCloudWatchを指定します。
ディメンションを使用タイプに設定することで、CloudWatchの用途ごとのコストを確認できます。
日毎などの粒度に変更して確認することもできるので、日によって使用状況が変わるような場合は、そちらも確認すると良いでしょう。
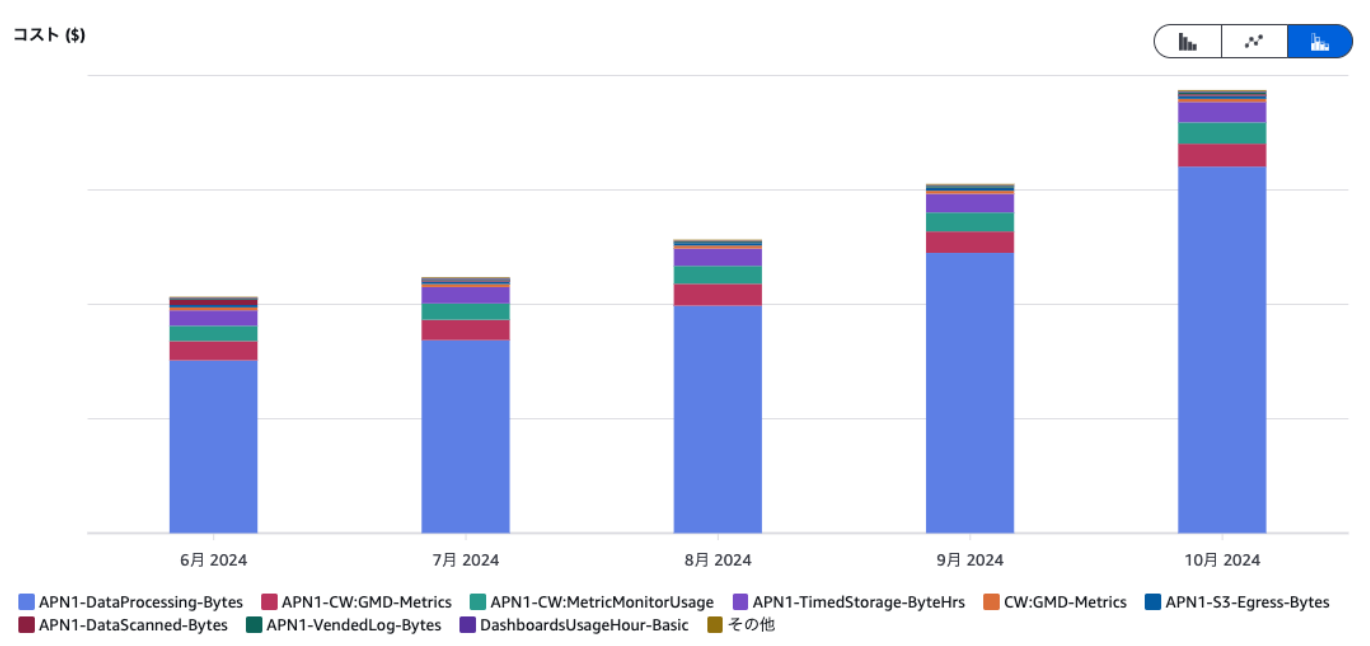
また、同様にディメンションをAPIオペレーションに設定することで、オペレーションごとのコストを確認できます。
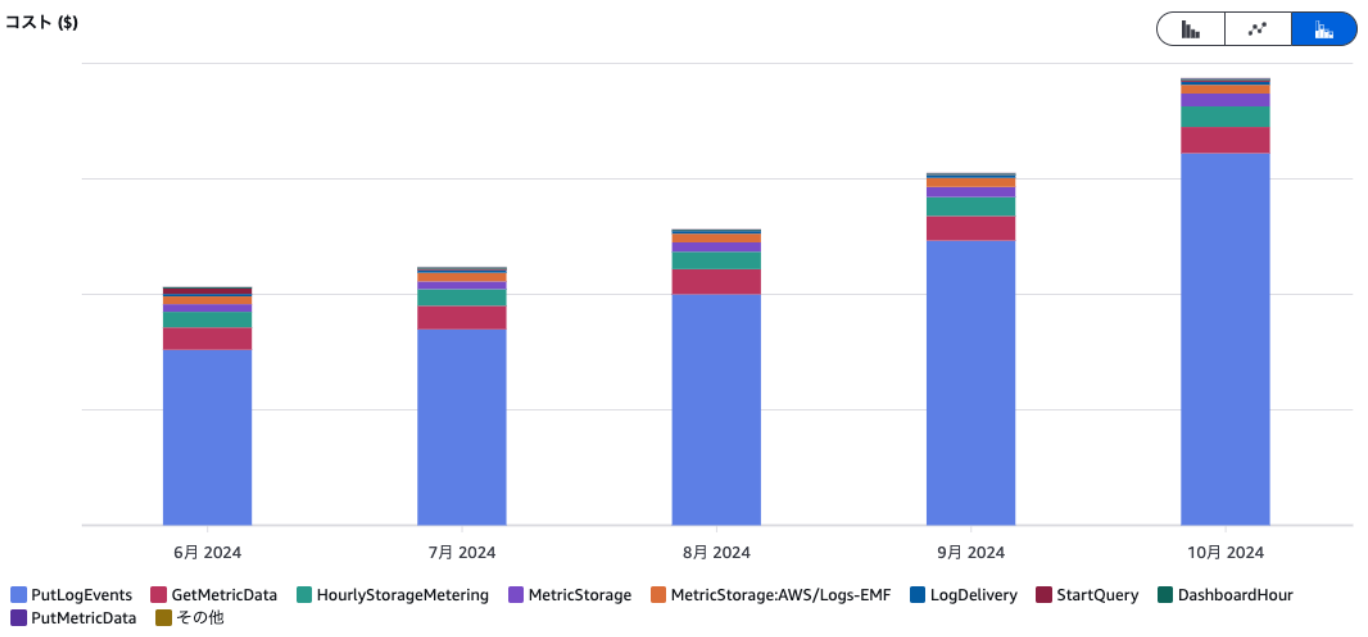
同様に請求書のページでもコストの内訳の確認ができます。
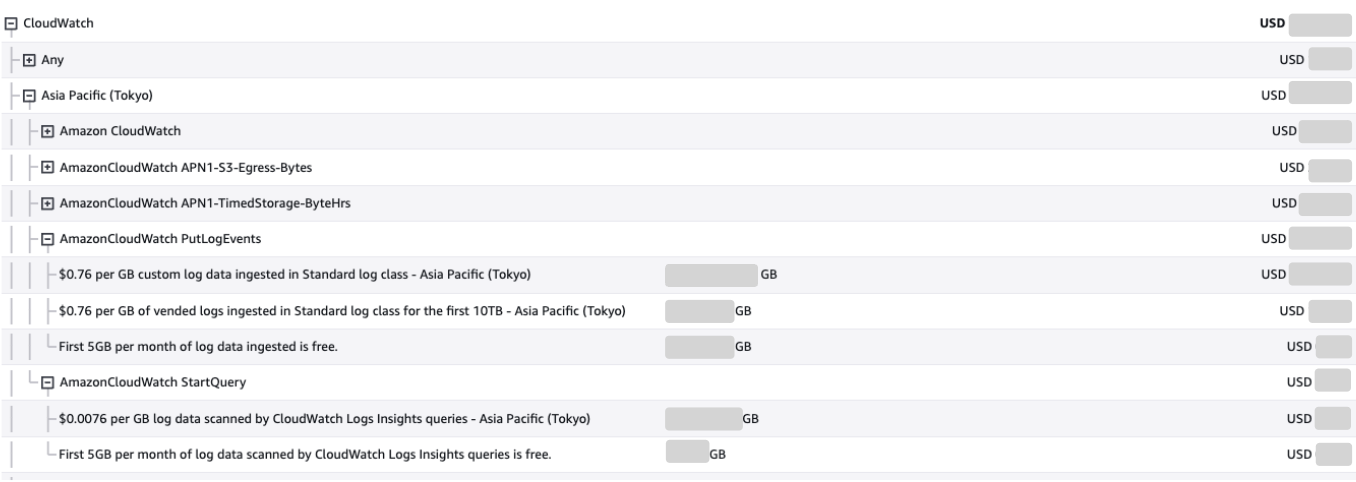
この分析から、AI在庫管理のCloudWatchのコスト増加は主にログの書き込み操作(PutLogEvents)の増加によるものだと判明しました。
これは、ログの保存料金ではなく、ログの書き込み回数や量の増加が直接の原因となっています。
影響の大きいロググループの特定
CloudWatchのコスト増加がPutLogEventsによるものと特定できたので、次は具体的にどのロググループが主要因となっているのかを分析していきます。
CloudWatchのメトリクスからもロググループごとの書き込み量(IncomingBytes)や書き込み回数(IncomingLogEvents)を確認できますが、ユーザー数などの他の指標とのクロス分析やさまざまな観点で確認したかったため、AWS CLIを使用してロググループごとの書き込み量を抽出することにしました。
AWS CLIを使用してロググループごとの書き込み量を抽出する
下記のようなスクリプトを作成し、AWS CLIを使用してロググループごとの書き込み量を抽出しました。
こちらの記事のスクリプトを参考にしています。
get-incoming-bytes-by-loggroups.sh
#!/bin/bash START_DATETIME_UTC="2024-08-01T00:00:00Z" # 抽出開始日時 END_DATETIME_UTC="2024-11-01T00:00:00Z" # 抽出終了日時 METRICS="IncomingBytes" ### LogGroupの一覧を取得 LOG_GROUPS=$(aws cloudwatch list-metrics \ --namespace "AWS/Logs" \ --metric-name "IncomingLogEvents" \ --query "Metrics[].Dimensions[?Name==\`LogGroupName\`].Value" \ --output text) ### LogGroupごとに1日分のIncomingBytesの合計を出力 for LOG_GROUP in ${LOG_GROUPS}; do echo "### LogGroup: ${LOG_GROUP} ###" aws cloudwatch get-metric-statistics \ --namespace "AWS/Logs" \ --start-time "${START_DATETIME_UTC}" \ --end-time "${END_DATETIME_UTC}" \ --dimensions Name=LogGroupName,Value="${LOG_GROUP}" \ --metric-name "${METRICS}" \ --statistics "Sum" \ --period 86400 \ --query "reverse(sort_by(Datapoints,&Timestamp)[?Sum>\`0\`].{Sum:Sum,Timestamp:Timestamp})" \ --output text done
ポイントは次の通りです。
aws cloudwatch get-metric-statisticsコマンドを使用してCloudWatchのメトリクスを取得--dimensionsでロググループごとの情報出力--metric-nameにIncomingBytesを指定して書き込み量を取得。他にIncomingLogEventsを指定することで書き込み数も取得可能--periodに86400(24時間)、--statisticsにSumを指定をすることで、1日単位の合計量を計算
スクリプトの出力結果
上記で作成したスクリプトを、出力結果をファイルに出力するように実行します。
./get-incoming-bytes-by-loggroups.sh > result_incoming_bytes.txt
出力されたresult_incoming_bytes.txtには、このような内容でロググループごとに出力されます。
この出力結果は次のセクションで説明するPythonスクリプトで処理します。
このスクリプトにより、各ロググループの日次書き込み量データを収集でき、コスト増加の原因となっているロググループを特定するための基礎データを取得できます。
この出力例では、記事記載の関係上、メトリクスの数値と日時の間は半角スペースで区切っていますが、実際にはタブ区切りで出力されます。
### LogGroup: /aws/lambda/loggroupA ### 228186.0 2024-10-07T00:00:00+00:00 204496.0 2024-09-19T00:00:00+00:00 613309.0 2024-09-13T00:00:00+00:00 617325.0 2024-09-12T00:00:00+00:00 252569.0 2024-09-03T00:00:00+00:00 333045.0 2024-09-02T00:00:00+00:00 50238.0 2024-08-30T00:00:00+00:00 50286.0 2024-08-26T00:00:00+00:00 25114.0 2024-08-23T00:00:00+00:00 ### LogGroup: /aws/lambda/loggroupB ### 3112.0 2024-10-07T00:00:00+00:00 3112.0 2024-09-19T00:00:00+00:00 9240.0 2024-09-13T00:00:00+00:00 9240.0 2024-09-12T00:00:00+00:00 3116.0 2024-09-03T00:00:00+00:00 6232.0 2024-09-02T00:00:00+00:00
結果を整形してCSVに出力する
このままの出力結果では分析しづらいため、CSV形式に整形して出力するようにしました。
CSV形式への整形にはJupyter NotebookとPython、そして、Pandasを使用しました。
必要なライブラリのインポート
import pandas as pd import datetime as dt import csv
ログデータの読み込みと整形
出力されたログデータのファイルを読み取り、この後の処理で扱いやすいように整形します。
# AWS CLIの出力結果を読み込み with open('result_incoming_bytes.txt') as f: lines = f.readlines() results = [] loggroupname = "" # ログデータをパースして構造化データに変換 for line in lines: line_ = line.strip() if line == "": continue if line_.startswith('### LogGroup:'): # ロググループ名の行の処理 loggroupname = line_.replace("### LogGroup: ", "").replace("###", "").strip() else: # メトリクスデータの行の処理 splited_line = line_.split('\t') incoming_bytes_str = splited_line[0].strip() datetime_str = splited_line[1].strip() results.append({ "loggroupname": loggroupname, "incoming_bytes": incoming_bytes_str, "date": dt.datetime.strptime(datetime_str, "%Y-%m-%dT%H:%M:%S%z").date() }) # DataFrameの作成 incoming_bytes_df = pd.DataFrame(results) incoming_bytes_df['incoming_bytes'] = incoming_bytes_df['incoming_bytes'].astype(float) incoming_bytes_df = incoming_bytes_df.sort_values(by=['loggroupname', 'date']) incoming_bytes_df = incoming_bytes_df.reset_index(drop=True)
この結果、次のような日付・ロググループごとのCloudWatchへの書き込み量のDataFrameが作成されます。
| loggroupname | incoming_bytes | date | |
|---|---|---|---|
| 0 | /aws/lambda/loggroupA | 25114 | 2024-08-23 |
| 1 | /aws/lambda/loggroupA | 50286 | 2024-08-26 |
| 2 | /aws/lambda/loggroupA | 50238 | 2024-08-30 |
| 3 | /aws/lambda/loggroupB | 333045 | 2024-09-02 |
| 4 | /aws/lambda/loggroupB | 252569 | 2024-09-10 |
日付を補完するためのベースのDataFrameを作成
上記で整形したDataFrameには、AWS CLIで取得した値が存在する日付のみが含まれています。
値が存在しない、つまり、書き込み量が0である日付の行が値0で存在する方が分析しやすいため、すべての日付を持つDataFrameにします。
そのために、まずはベースとなる対象範囲のすべての日付けを持つDataFrameを作成します。
# 対象範囲(メトリクスの抽出範囲と揃える) START_DATE="2024-08-01" END_DATE="2024-11-01" # 分析対象のロググループ一覧を取得 loggroupnames = list(incoming_bytes_df['loggroupname'].unique()) + list(incoming_bytes_df['loggroupname'].unique()) loggroupnames = list(set(loggroupnames)) # 分析対象期間の日付レンジを生成 date_range = pd.date_range(start=START_DATE, end=END_DATE, freq='D').to_list() # すべての日付とロググループの組み合わせを作成 base_data = [] for loggroupname in loggroupnames: for d in date_range: base_data.append({ "loggroupname": loggroupname, "date": d.date() }) base_df = pd.DataFrame(base_data)
このようなロググループごとに対象範囲のすべての日付を持つDataFrameが作成されます。
| loggroupname | date | |
|---|---|---|
| 0 | /aws/lambda/loggroupA | 2024-08-01 |
| 1 | /aws/lambda/loggroupA | 2024-08-02 |
| 2 | /aws/lambda/loggroupA | 2024-08-03 |
| 3 | /aws/lambda/loggroupA | 2024-08-04 |
| 4 | /aws/lambda/loggroupA | 2024-08-05 |
データの結合と付加情報の追加、CSV出力
上記で作成した2つのDataFrameを結合し、ロググループごとに日付の欠損がないDataFrameを作ります。
さらに、分析しやすいようにKB, MBに変換した情報や年月日の個別カラムを追加します。
# すべての日付けを持つDataFrameとログデータの結合 merged_df = pd.merge(base_df, incoming_bytes_df, on=['loggroupname', 'date'], how='left') merged_df = merged_df.fillna(0) # 欠損値を0で補完 # あとで見やすいようにKB, MBに変換した情報を追加 merged_df['incoming_KB'] = (merged_df['incoming_bytes'] / 1024).round(2) merged_df['incoming_MB'] = (merged_df['incoming_bytes'] / 1024 / 1024).round(2) # あとで分類しやすいように年月日を分割した情報を追加 merged_df["year"] = merged_df["date"].apply(lambda x: x.year) merged_df["month"] = merged_df["date"].apply(lambda x: str(x.month).zfill(2)) merged_df["day"] = merged_df["date"].apply(lambda x: str(x.day).zfill(2)) # CSVに出力 merged_df.to_csv("incoming_bytes_daily.csv", index=False, quoting=csv.QUOTE_NONNUMERIC)
出力結果
CSV形式で出力されたデータは次のようになります。
生成されたCSVファイルには以下のような情報が含まれます。
- ロググループ名
- 日付
- データ量(バイト、KB、MB単位)
- 年月日の個別カラム
"loggroupname","date","incoming_bytes","incoming_KB","incoming_MB","year","month","day" …(中略)… "/aws/lambda/loggroupA","2024-08-20",0.0,0.0,0.0,2024,"08","20" "/aws/lambda/loggroupA","2024-08-21",0.0,0.0,0.0,2024,"08","21" "/aws/lambda/loggroupA","2024-08-22",0.0,0.0,0.0,2024,"08","22" "/aws/lambda/loggroupA","2024-08-23",25114.0,24.53,0.02,2024,"08","23" "/aws/lambda/loggroupA","2024-08-24",0.0,0.0,0.0,2024,"08","24" "/aws/lambda/loggroupA","2024-08-25",0.0,0.0,0.0,2024,"08","25" "/aws/lambda/loggroupA","2024-08-26",50286.0,49.11,0.05,2024,"08","26" "/aws/lambda/loggroupA","2024-08-27",0.0,0.0,0.0,2024,"08","27" "/aws/lambda/loggroupA","2024-08-28",0.0,0.0,0.0,2024,"08","28" "/aws/lambda/loggroupA","2024-08-29",0.0,0.0,0.0,2024,"08","29" "/aws/lambda/loggroupA","2024-08-30",50238.0,49.06,0.05,2024,"08","30" "/aws/lambda/loggroupA","2024-08-31",0.0,0.0,0.0,2024,"08","31" "/aws/lambda/loggroupA","2024-09-01",0.0,0.0,0.0,2024,"09","01" "/aws/lambda/loggroupA","2024-09-02",333045.0,325.24,0.32,2024,"09","02" "/aws/lambda/loggroupA","2024-09-03",252569.0,246.65,0.24,2024,"09","03" "/aws/lambda/loggroupA","2024-09-04",0.0,0.0,0.0,2024,"09","04" "/aws/lambda/loggroupA","2024-09-05",0.0,0.0,0.0,2024,"09","05" …(中略)… "/aws/lambda/loggroupB","2024-08-20",0.0,0.0,0.0,2024,"08","20" "/aws/lambda/loggroupB","2024-08-21",0.0,0.0,0.0,2024,"08","21" "/aws/lambda/loggroupB","2024-08-22",0.0,0.0,0.0,2024,"08","22" "/aws/lambda/loggroupB","2024-08-23",0.0,0.0,0.0,2024,"08","23" "/aws/lambda/loggroupB","2024-08-24",0.0,0.0,0.0,2024,"08","24" "/aws/lambda/loggroupB","2024-08-25",0.0,0.0,0.0,2024,"08","25" "/aws/lambda/loggroupB","2024-08-26",0.0,0.0,0.0,2024,"08","26" "/aws/lambda/loggroupB","2024-08-27",0.0,0.0,0.0,2024,"08","27" "/aws/lambda/loggroupB","2024-08-28",0.0,0.0,0.0,2024,"08","28" "/aws/lambda/loggroupB","2024-08-29",0.0,0.0,0.0,2024,"08","29" "/aws/lambda/loggroupB","2024-08-30",0.0,0.0,0.0,2024,"08","30" "/aws/lambda/loggroupB","2024-08-31",0.0,0.0,0.0,2024,"08","31" "/aws/lambda/loggroupB","2024-09-01",0.0,0.0,0.0,2024,"09","01" "/aws/lambda/loggroupB","2024-09-02",6232.0,6.09,0.01,2024,"09","02" "/aws/lambda/loggroupB","2024-09-03",3116.0,3.04,0.0,2024,"09","03" "/aws/lambda/loggroupB","2024-09-04",0.0,0.0,0.0,2024,"09","04" "/aws/lambda/loggroupB","2024-09-05",0.0,0.0,0.0,2024,"09","05" …(後略)…
これらの情報を分析することで、ロググループごとの使用量比較、時系列での変化分析などができるようになります。
IncomingLogEventsの情報も合わせて出力すれば、書き込み回数と書き込み量との関係も見ながら分析することもできるようになります。
ロググループ内の何のログが多いのかの確認
ここまでで特定した高コストのロググループについて、具体的にどのような種類のログが書き込まれているのかを分析していきます。
この分析にはCloudWatch Logs Insightsを使用します。CloudWatch Logs Insightsは、ログデータをクエリして分析するためのサービスです。
CloudWatch Logs Insightsを使用してログのパターンを確認する
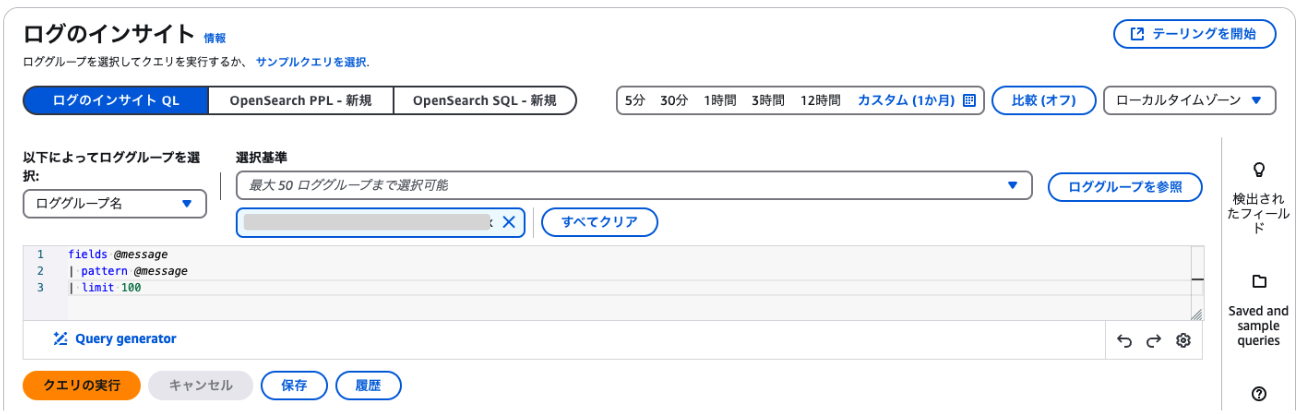
CloudWatch Logs Insightsを使って、特定したロググループの中身を詳しく見ていきましょう。
AWSのマネージメントコンソールからCloudWatchのサービスを開き、Logs Insightsを開きます。
特定したロググループを指定し、パターンを抽出するクエリを実行します。
fields @message | pattern @message | limit 100
パターンを抽出するためには、pattern句を使用します。
抽出期間はいくつか状況に合わせて確認してみましょう。
- まずは直近1週間程度のログを見て、全体的な傾向を把握する
- コスト増加が始まった時期のログと比較してみる
実行した結果は次のように出力されます。
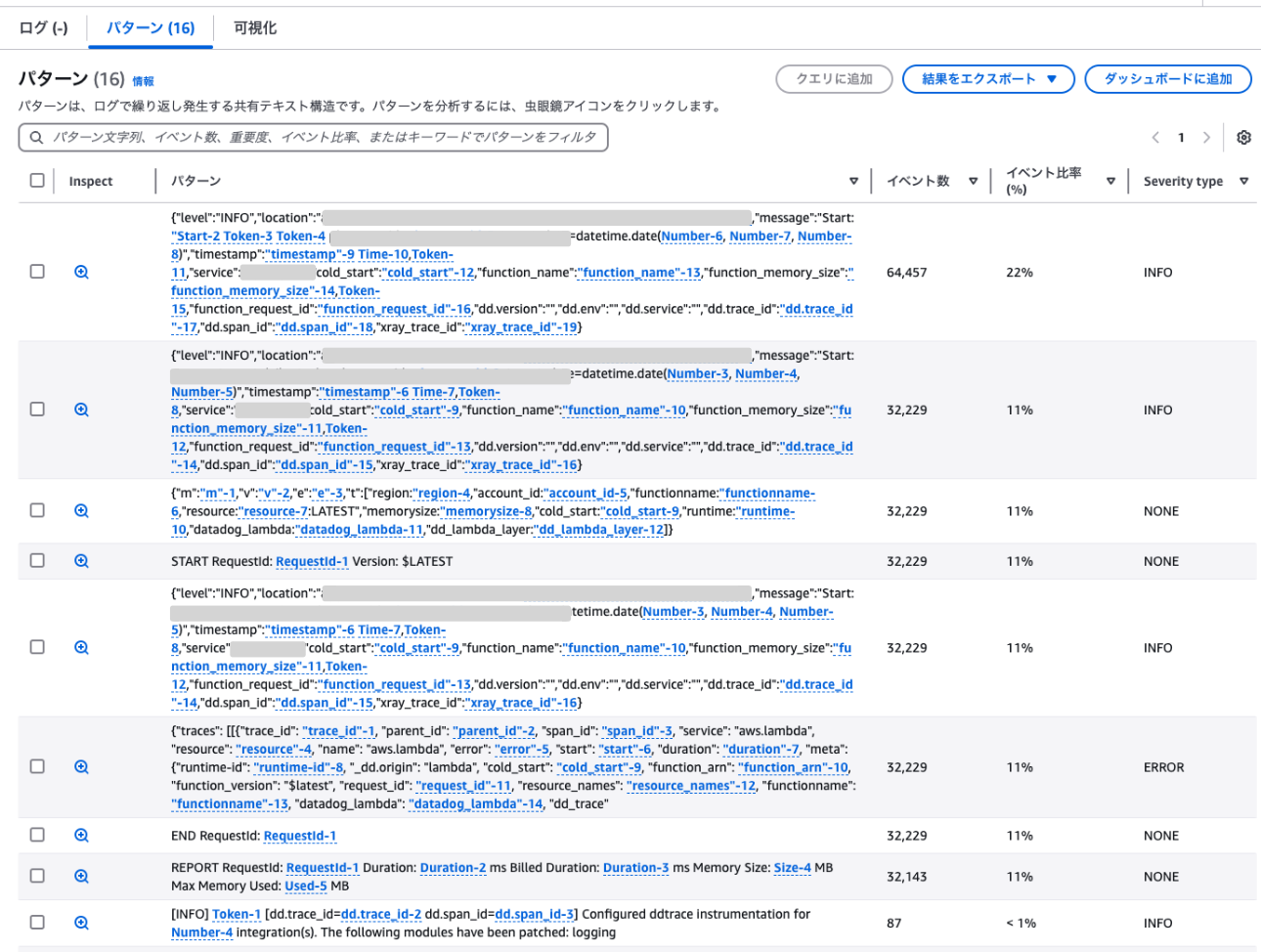
この機能を使うと自動で似たようなログの出力パターンごとにまとめてくれ、パターンごとに出力回数や全体の比率を確認できます。
これにより、ログの出力内容や頻度を確認し、削減効果を確認しながら、不要なログの出力を抑制を検討できます。
AI在庫管理での対策
ログパターンの分析結果から、いくつかの改善ポイントが見えてきました。
この結果から、AI在庫管理では以下のような観点で対策を進めていくことにしました。
ログの出力頻度の見直し
ログ出力の頻度を見直す際は、まずシステムの運用に本当に必要なログかどうかを見極めることから始めました。
日常的なトラブルシューティングでほとんど参照していないINFOレベルのログについては、DEBUGレベルに変更することで出力を抑制。
これにより、必要なときだけログを出力できるようになり、普段の書き込み量を大幅に削減することができました。
また、AWS Lambdaの運用において特に注目したのが、システムログの出力レベルです。
デフォルトではLambdaの実行開始時(START)、終了時(END)、そして実行結果(REPORT)のシステムログが自動的に出力されます。
これらのシステムログのログ出力をWARNレベルに設定することで通常の実行時のログ出力を抑制することが可能です。
ただし、REPORTログについてはとくに慎重な判断が必要です。
このログはLambdaの実行時間やメモリ使用量などの重要なメトリクスの取得にも使用されているため、出力を抑制する場合は各Lambdaの監視要件を個別に検討する必要があります。
特に、パフォーマンスの監視が重要な関数については、Lambdaのシステムログの出力を維持することをオススメします。
ログ出力先の見直し
ログの分析方法や用途に応じて、出力先を見直すことでもコストを削減できます。
とくに、CloudWatchでの分析が不要なログについては、他のサービスへ直接出力するように変更することで、コスト的にムダな二重管理を防ぐことができます。
具体的な例として、RDSの監査ログの扱いの変更が考えられます。
これまではRDSの監査ログもCloudWatchにログを出力していましたが、実際の利用シーンを検討した結果、S3への直接出力で十分ではないかと考えました。
S3ではコストを抑えながら長期保存が可能で、必要に応じて分析ツールと連携することもできます。
また、システム監視にDatadogなどの外部モニタリングツールを使用していて、CloudWatch経由で送信している場合は、そちらへ直接データを送信するように変更できます。
これにより、CloudWatchを経由する必要がなくなり、よりシンプルな構成でコストを削減することができました。
まとめ
CloudWatchのコスト削減について、分析から改善までの取り組みを紹介しました。
AI在庫管理では、分析の結果コスト増加の主な要因として、ログ書き込み(PutLogEvents)の増加と一部ロググループでの過剰なログ出力がありました。
これらの分析結果を踏まえ、ログレベルの見直しやログ出力先の変更などの対策を段階的に進めています。
ただしログ削減は、システムの監視や運用への影響も考慮しながら、バランスの取れた最適化を目指すことが重要です。
一気にいろんな対策を実施するのではなく、段階的に確認しながら慎重に進めています。
引き続き、システムの監視や運用の品質を維持しながら、ログの使用状況の見直しを続けていく予定です。
本記事で紹介した分析・改善の手順が、同じような課題をお持ちの方の参考になれば幸いです。