

AIモデル開発の多様化、システム実装が本格化する昨今、AIモデル開発のプロセスを効率化する仕組みとして、MLOpsは欠かすことができません。
MLOpsとは何なのか、MLOpsがあると何が良いのかについて説明します。
MLOpsとは
Machine Learning Operationsの略語で、Machine LearningとOperationsが組み合わされている通り、AIモデル開発とAIモデル運用を迅速に行うための手法です。
学習データの準備、AIモデル学習の実行や管理を行う仕組みを整備すると、効率よくAIモデル開発を進められるようになります。
また、AIモデルは推論対象となるデータの性質が時間経過と共に変化することで、精度劣化が生じることが多々あります。
データ変化にも対応できるAIモデルをシステムで提供していくためには、AIモデルを進化し続ける必要があり、新しいモデルを迅速にシステムへ適用(デプロイ)するための仕組みが、MLOpsにより実現できるのです。
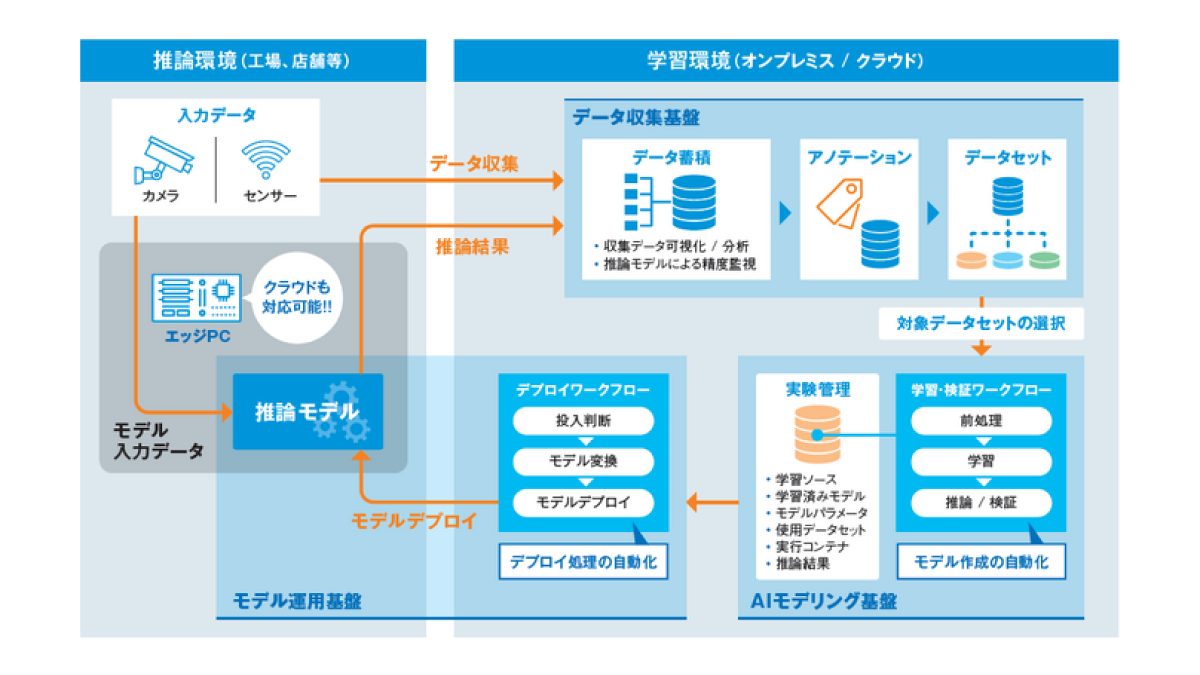
段階的なMLOpsの導入
AIモデル開発の効率化を目的としたMLOps環境を構築することを考えてみます。
MLOpsに求められる要素は様々なのですが、MLOpsを構築するときは、導入する目的を明確にして用途に合わせた要件を定義します。
最初からフルスペックな状態を目指すのではなく、スモールスタートで始めてみて、運用で課題が見えてきた部分を拡張して、現場の声もくみ取りながら徐々に育てていくことで、AI技術者にとって使い勝手のよいシステムが構築できます。
AIモデル開発の効率化を目的とした場合の、段階的な構築例を紹介します。

① モデル管理の導入
AIモデルを開発されている方であれば、過去の学習済みモデルの管理に苦労された経験はあるのではないでしょうか。
実験管理を行うことは、MLOpsの第一歩とも言えると思います。
MLflowは、その実験管理を行うためのツールの一つです。
MLflowを使うと、過去に実施したモデル学習の結果(Metrics)と、学習済みモデルや付随するデータ(Artifacts)を紐づけて管理することができ、過去の学習と条件を揃えて再学習したり、結果を比較するということがしやすくなります。
MLflowを使うメリット
- 多くのディープラーニング/MLフレームワークが対応しており、メトリクスやモデルの管理が容易にできる。
- 学習環境と分けてMLflowサーバを構築することで、モデル管理に必要なストレージ管理を、GPUマシンと分離できる。
モデル管理を導入するだけでも、AIモデル開発の加速に効果があります。
詳しくは、以下ブログもご参照ください。
② MLパイプライン自動化
モデル開発を行う段階では、Jupyter Notebook等を使って開発を行う方が多いかと思います。
Notebookは便利なのですが、このままでは自動的に学習を実行させる処理をさせるのが難しいです。
ソースコードと実行環境のコンテナを整理して、再現性のある学習と検証が可能なパイプラインを構築します。
MLパイプラインを実現するツールとして、Kubeflowなどのツールキットがよく使われます。
- Gitリポジトリ上で、ソースコードや学習環境のDockerfileをバージョン管理。
- コンテナレジストリで、Dockerイメージを管理。
- 学習/推論用のソースコードを元に、Kubeflowのパイプラインを実行するためのComponentを作成。
- コンテナレジストリで管理されたDockerイメージを使って、Kubeflowのパイプラインが実行されるようにする。
この形にすることにより、学習/推論処理を実行する環境の再現性を確保したり、処理を再利用しやすい運用が可能になります。
③ CI/CTパイプライン自動化
再現性が確保できれば、次は学習用コードやデータの変更を契機に学習を実行し、ソースコードの正常性、学習済みモデルの精度のモニタリングを自動で行う環境を構築します。
Gitと連動したパイプライン実行を、CI/CTそれぞれ実行できるようにします。
CI(継続的インテグレーション)
開発したソースコードが正常に動作するかを検証するためのパイプライン。
CT(継続的トレーニング)
モデル学習から推論/評価を自動で行うパイプライン。
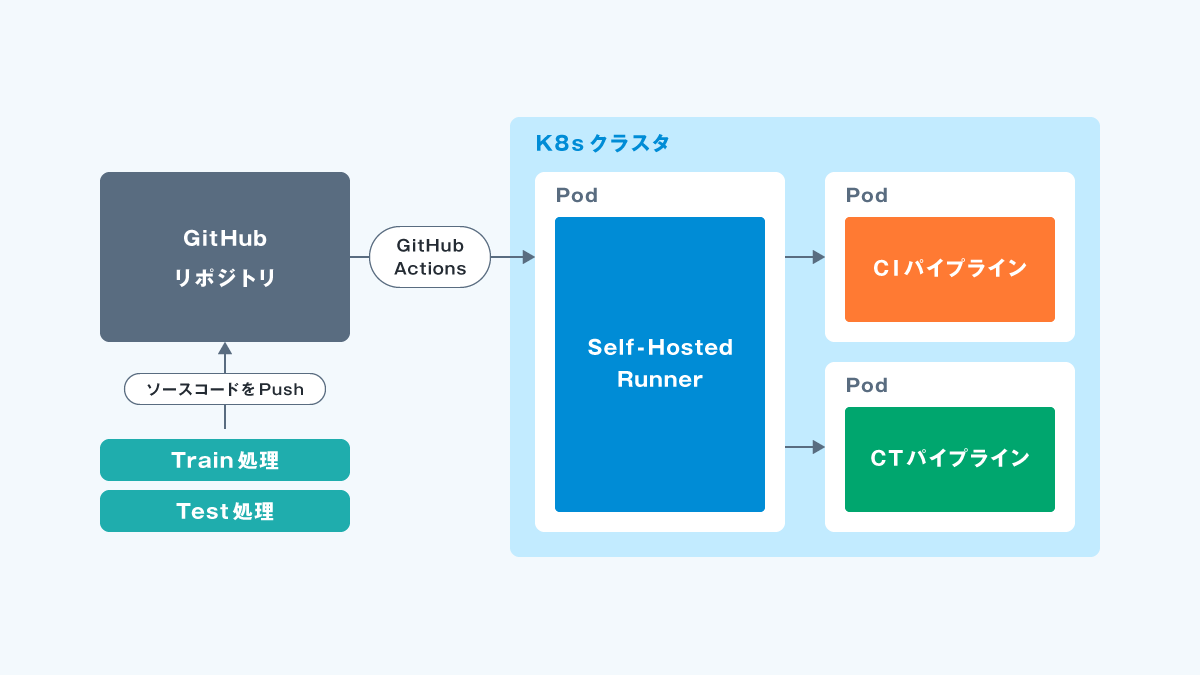
GitHub Actions や GitLab CI/CD を使用すると、ソースコードの改変を契機にした自動学習が可能になります。
MLパイプラインを動作させるためには、GPUリソースが必要になるケースが大半ですが、GitHub Actions の Self-hosted runnerや、GitLab Runnerを使用すれば、Gitリポジトリとは別のGPUマシンリソース上でMLパイプラインの自動実行が可能となります。
しかし、CIに比べてCTは学習に要するリソースが多く必要であると同時に、所要時間も長くなります。
自動実行するランナー数を多くする場合は、対応できるだけのマシンリソースを確保することと、マシンリソースに見合ったアクションの起動タイミングの設計が重要になります。
マシンリソースを拡張しやすくする仕組みとして、Kubernetes (k8s) でクラスタを構築することにより、複数のGPUマシンリソース上でMLパイプラインを並列処理することが可能になります。
これらの仕組みは、記事で紹介したOSSを中心に構築するのですが、OSSの標準のUIではかゆい所に手が届かないということも多々あります。
私たちのチームでは、そのような部分をサポートするためのコンソールアプリケーションを開発するという業務も行っております。
お困りのことがございましたら、弊社までお問い合わせください。
最後に
私たちのTech Blogを最後までお読みいただき、ありがとうございます。
私たちのチームでは、AI技術を駆使してお客様のニーズに応えるため、常に新しい挑戦を続けています。
最近では、受託開発プロジェクトにおいて、MLOps構築のニーズが高くなってきていますが、弊社ではAI開発経験者の目線で使いやすい環境を構築するように努めています。
また、このようなシステム開発にチャレンジしたいという技術者も募集しております。
AI開発経験のある方やMLOps、LLM開発に興味のある方は、ぜひご応募ください。
あなたのスキルと情熱をお待ちしています。
