はじめに
BASE Dept. Product Devにてバックエンドエンジニアをしているオリバです。
2024年末、弊社のソフトウェアエンジニア(以下、SWE)でSREに興味を持つメンバーを募り、「SREをはじめよう」を題材にした輪読会を実施しました。本記事では、各部・各章の要点を整理し、実践に役立つ知見を共有します。

※引用元: O'Reilly Japan SREをはじめよう
第1部 SRE入門
この部では、SREの定義やSREの文化のような、SREの概論に触れています。
SREの定義
書籍では、SREを以下で定義しています。
サイトリライアビリティエンジニアリングは、組織がシステム、サービス、製品において 適切なレベルの信頼性を持続的に達成できるよう支援することを目的とした工学分野である。
工学の分野の1つと認識されていますが、情報系の学部出身の弊社社員の中で、工学分野としてのSREという言葉を耳にしたことがある方はいませんでした。もしかすると、将来的に大学の講義でもSREが取り上げられるかもしれません。
また、SREを理解するのに最適な1枚のスライドが紹介されています。

※引用元: Keys to SRE
このスライドはSREの始祖とも言われているBen Treynor Slossが、2014年5月31日のSREconの基調講演で紹介されたスライドです。
私が特に疑問に思ったのは、上から6つ目のExcess Ops work overflows to DEV teamです。和訳すると、「余計な運用作業は開発チームにオーバーフローさせる」という意味になり、なぜ運用作業を開発チームにオーバーフローさせるのか輪読会で話し合い、以下の内容で解釈しました。
- 余計な運用作業があることを意図的に開発チームに気づかせるようにする
- SREの運用作業は過剰になりがちで、より重要な業務に注力するために、開発チームに一部を委譲する
- インシデントが起きたときに、SREの中で閉じないようにする
DevOpsとSREの関係性
DevOps
コードを本番環境にリリースするために何が必要か考えます。
SRE
本番環境を起点に、信頼できる運用を実現するには何をすべきか考えます。

※引用元: SREの探求
SREの心構え
本書で特に重要とされるSREの心構えとして、以下の4点が挙げられます。
1. フィードバックループを重ねる
信頼性向上の中心となるのは、継続的な改善を可能にするフィードバックループの構築です。
2. 共同作業を重視する
SREは、さまざまな分野の同僚と協力しながらシステムの信頼性を向上させます。また、顧客とも信頼性に関する共同作業を行う姿勢が重要です。
3. オーナーシップを持つ
運用するサービスに対して責任を持ち、主体的に取り組みます。
4. 失敗から学ぶ
システムのエラーを学習機会と捉え、そこから改善のアイデアを得ます。
SREの文化を醸成する
本書で紹介されているSRE文化を醸成するための取り組みの中で、組織に取り入れやすいと思われるアイデアを以下にまとめました。
1. トイル削減を祝う文化を作る
トイル(以下の特徴を持つ繰り返し作業)を削減した取り組みを組織全体で祝う文化を作ります。
- 手作業である
- 繰り返される
- 自動化可能
- 長期的価値を持たない
- サービスの成長に比例して増える(O(n))
2. 「ポストモーテム会」や「デザインドキュメント会」の開催
ポストモーテムとは、インシデント発生後の事後検証プロセスです。インシデントレポートをチーム全体で共有する文化や、振り返りの場を定期的に設けることで、組織的な学びを深められる可能性があります。
3. チーム間のローテーション
SWEが一定期間SREチームに参加する「交換留学」を実施することで、SRE文化が組織全体に広がります。弊社でも2025年からこの取り組みを開始する予定です。
SREを提唱する
SREを提唱できる力は、組織内外でその存在意義を説明する場面で重要です。例えば、組織のステークホルダーにSREの存在意義を伝え、SREという組織を存在させる場面でも必要ですし、採用活動や転職時には、SREの役割や文化を候補者や採用側と共有し、ギャップを認識することが求められます。
また、他者の経験やストーリーを学ぶことも重要です。本書では、イベントや勉強会への参加が強く推奨されています。私もさっそく、2025年1月26日に開催されるSRE Kaigi 2025への参加申し込みを行いました。
第2部 個人がSREをはじめるには
この部では、個人がSREを始めるために必要なスキルや考え方について説明します。
SREになるための準備
SREになるために必要なスキルとして、本書では以下を挙げています。
1. コーディングスキル
コーディングスキルはSREにとって不可欠です。システムの構造を深く理解し、潜在的な故障を予測・防止する能力を備えるには、このスキルが求められます。
2. 計算機科学の学位
計算機科学の学位は必須ではありませんが、コーディング経験を通じて同等の知識を習得する必要があります。
3. モノリス、分散システムへの理解
OSやネットワークの仕組みを理解することは、大規模でスケーラブルなシステムの構築に不可欠です。また、近年ではマイクロサービスやマルチリージョン対応などの分散システムを扱うケースが増えています。
4. 統計とデータの可視化
SLI(Service Level Indicator)やSLO(Service Level Objective)で使用されるパーセンタイルの理解には統計学の知識が必要です。輪読会ではマンガでわかる統計学 (Ohmsha)という書籍が推薦されていました。
その他、ストーリーテリング、NALSD(非抽象的な大規模システム設計)、レジリエンス工学、性能工学、AI/MLの知識も重要とされています。
肩書きだけの変更はNG
本書では、学生やSWEがSREに転向する方法が述べられていますが、システム管理者やDevOpsメンバー全員の肩書きを単に「SRE」に変更することへの警告も含まれています。
文化的・戦略的・組織的な変革を伴わない肩書きの変更では、SREの本質的なメリットを享受できません
コラボレーションモード
SREは「あくなき共同作業」によって成り立つと本書では強調されています。
具体例として、SLI/SLOの策定や実施が挙げられます。また、監視業務を通じて顧客の声に耳を傾け、顧客との共同作業も実現しています。
弊社では隔週で「定点観測会」を開催し、BASEのコア機能を洗い出し、SLI/SLOの見直しを行っています。
トイルとの関係を築く
SREは、「SREの文化を醸成する」で触れたトイルに継続的に向き合う必要があります。本書では、その理由として以下の3つを挙げています。
1. 美学
トイルは非効率で美しさを欠き、最適化の障害となります。
2. お金
高度なエンジニアをトイルに費やすのではなく、価値を生む仕事に集中させることで、組織のコスト削減に繋がります。
3. 時間の使い方/仕事の満足度
エンジニアはトイルではなく開発業務に時間を使いたいと考えます。過剰なトイルは生産性と満足度を低下させます。
弊社では毎週、有志メンバーによるトリアージ会を開催しています。この会では、SentryやNewRelicのアラートを確認し、解決すべきIssueをタスクとして起票しています。
また、OKRを活用し、目標を達成するためのトイル解消に取り組んでいます。
※ 参考: OKRを設定する(https://rework.withgoogle.com/jp/guides/set-goals-with-okrs)
失敗から学ぶ
本書では、失敗から学ぶ方法として、インシデント後のレビューが重要であるとされています。
インシデント後のレビューでは、単なる文書や報告書、アクションリストの作成に留まらず、以下の点を重視することが求められます。
時系列での詳細な記録
インシデントの前後で何が起きたのかを明確に記載します。
プロセスの記述
どのような資料を参照したのか、解決までのプロセスを詳細に説明し、単なる事象の振り返りにとどまらず、将来の予防策や信頼性向上のための具体的な知見を得られます。
また、インシデント後のレビューを行う際には、以下の行動を避けることが重要です。
犯人探し
問題の原因を特定の人物に帰結させることは、生産的な学びや改善にはつながりません。
ヒューマンエラーへの責任転嫁
人間のミスに焦点を当てるだけでは、システム全体の信頼性向上を妨げます。
成功点の無視
問題解決においてうまく機能した点も学びの一部であり、見落とさないことが重要です。
インシデント後のレビューは、失敗からの学びをシステムの改善やプロセスの洗練に結びつけるための重要な手段です。これを適切に活用することで、組織全体の信頼性を向上させることができます。
なぜなぜ分析はアンチパターン
「なぜなぜ分析」は、トヨタグループの創始者である豊田佐吉が考案した手法です。この手法では、事象に対して「なぜ」を繰り返し問い続けることで、根本原因を突き詰めていきます。一般的に、5回「なぜ」を繰り返すと根本的な原因に到達できるとされています。
本書では、「なぜなぜ分析」は特定の事象を深掘りして原因を発見するのには適しているものの、インシデントを理解し、そこから学びを得るためには不十分であると指摘されています。その理由は以下の通りです。
- 重要な情報を見逃す可能性が高い
- システム全体の理解を阻害し、部分的な要因に偏りがちになる
そのため、「なぜなぜ分析」はインシデント分析においてはアンチパターンとされています。
「なぜ」を繰り返す前に、まずは「何が起こったのか」を詳細に確認し、全体像を把握することが重要です。インシデントのプロセスや影響を全て洗い出すことで、包括的な学びと改善につながります。
第3部 組織がSREをはじめるには
この部では、組織がSREの導入に成功するための要因を探っています。
Dickersonの信頼性の階層構造
既存の組織がSREを開始するためのわかりやすいロードマップとして、Dickersonの信頼性の階層構造があります。
これは、元Google社員のMikey Dickersonが、マズローの欲求階段説を引用したものです。
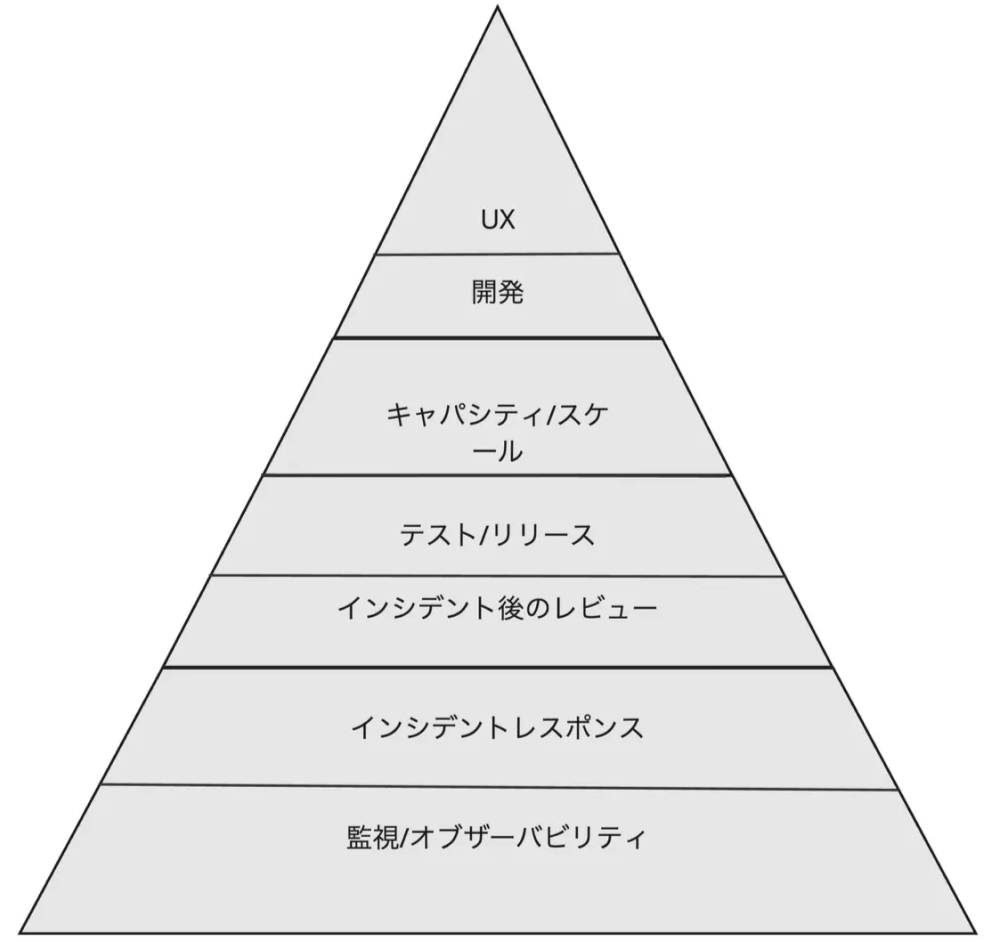
※引用元: O'Reilly Japan SREをはじめよう p.198
マズローの階層構造と同様に、階層の一番下からはじめて、下の階層が強固になった時点で初めて上の階層に進みます。
1段目の監視/オブザーバビリティに関して、監視ツールやオブザーバビリティプラットフォームを導入している組織がほとんどだとは思いますが、意外とSLI/SLOまでしっかり実践している組織は少ないかもしれません。
SREを組織に組み込む
本書では、SREを0からスケールアップする(本書ではSRE0と呼ぶ)ために必要なものは、建築工学や土木工学など資格を持った人がいないとはじめられないものではなく、サービスやシステムに対する好奇心と、SLI/SLOを始めるための機会であると述べています。
また、SREが既に組織に統合されているモデルとして、以下の3種類を定義しています。
1. 中央集権型/パートナー型モデル
Googleが最初に導入し普及させたもので、独立した組織として、採用プロセスや、人員、ジョブラダーを持ちます。例えばGoogleでは、GoogleマップのSREチーム、GmailのSREチーム、広告のSREチームが存在します。
2. 分散型/埋め込み型モデル
Metaで導入されているモデルで、SREが開発チームに参加します。詳細は、SREの探求の第13章に記載されています。
3. ハイブリット型モデル
上記2つのモデルを混ぜて導入したもので、中央集権的な組織で働くSREと、個々の事業部門で個別に雇用されているSREがいます。
弊社が提供するサービスには、ECストアフロントを提供する「BASE」のほか、ID決済機能とショッピングアプリ機能を提供する「PayID」、金融サービスを提供する「BASE BANK」などがあります。(その他のサービスについてはここでは割愛します)
これらを上記の3種類のモデルに当てはめると、「BASE」は中央集権型/パートナー型モデルに、「PayID」と「BASE BANK」は分散型/埋め込み型モデルに該当すると考えられます。
このことから、弊社全体としてはハイブリッド型モデルを採用していると言えるでしょう。
SRE組織の進化段階
SREチームの進化に関する概念的な枠組みとして、本書では、SREcon Asia 2018で元LinkedInのBenjamin Purgason氏が行った講演内容を引用しています。この進化段階は5つのステージに分かれていますが、必ずしも順序通りに進む必要はなく、ステージを飛ばして進化することも可能です。
段階1: 消防士
多くのSREチームがこのステージからスタートします。主な役割は障害対応などの「火消し」ですが、重要なのは火災と火災の間に何を行うかです。例えば、この時間を活用して、Dickersonの信頼性の階層構造でいう最初の2つの階層(監視/オブザーバビリティとインシデントレスポンス)の構築や、トイル(繰り返し作業)を撲滅するための自動化(本書では「自動消火装置」と表現)に取り組むことが推奨されています。
段階2: ゲートキーパー(門番)
この段階では、SREが「ゲートキーパー」の役割を果たし、システムに関するすべての決定がSREを通過しなければならない状態になります。しかし、ゲートキーパー的な振る舞いは、他の開発者や組織内のメンバーに不快感を与える可能性があります。本書では具体例として、空港の税関職員をイメージした説明がなされています。
段階3: 提唱者
この段階では、SREと他のメンバーの関係がより協力的になります。SREは、設計やアーキテクチャの議論など、ソフトウェアライフサイクルの初期段階から積極的に関与します。これにより、全員が協力して本番環境を構築し、信頼性を高めることを目指します。
段階4: パートナー
段階3の発展形であり、SREとSWEがパートナーとして対等に協力する状態です。具体的には、計画やロードマップの作成を共同で行い、チーム間の連携がより強化されます。
段階5: エンジニア
この最終段階では、SREとその他のエンジニアの役割の境界線が曖昧になります。全員がシステムのライフサイクル全体に関与し、信頼性向上を目的とした活動に取り組みます。SREの活動がチーム全体に自然に組み込まれ、信頼性が組織全体の文化として根付いた状態です。
今後の展望
本記事で取り上げた「SREをはじめよう」の内容や輪読会での議論を通じて、SRE文化の醸成や実践への理解が深まりました。今後、弊社では以下のような取り組みが可能ではないかと、輪読会で議論しました。
1.トイル削減を祝う文化の醸成
トリアージ会やOKRを活用したトイル削減活動を継続し、削減したトイルの成果を社内で共有し、モチベーションを高める文化を醸成します。
2. 知識共有の強化
外部イベントやカンファレンスへの参加、登壇を行い、自分なりのSREの定義を語れるようにします。
3. 失敗からの学びを最大化
ポストモーテム会を定期的に開催し、インシデント後の学びを組織全体に共有します
おわりに
弊社では、SREの方だけではなく、サイトリライアビリティエンジニアリングに興味を持たれているSWEの方も積極採用しています。興味を持っていただいたら、ぜひ下記からご応募ください!