




はじめに
SRE部 ECプラットフォームSREチームの小林 (@akitok_) です。
ZOZOTOWNでは、マイクロサービス間通信におけるトラフィック制御のために、Istioによるサービスメッシュを導入しています。本記事ではZOZOTOWNのマイクロサービスプラットフォーム基盤(以下、プラットフォーム基盤)において、Istioをいかにプロダクションレディな状態で本番に投入していったか、その取り組みを紹介します。
なお、Istioによるサービスメッシュを導入した背景については、以下の記事で紹介しています。
- はじめに
- What is Istio?
- Istioをプロダクションレディにするまでに直面した3つの課題
- どのようにリソース消費量を見積もるか
- 何を監視するか
- どのように可観測性を向上させるか
- まとめ
- 終わりに
What is Istio?
Istioは、マイクロサービスの複雑性を解決する一手段である「サービスメッシュ」を実現するためのフレームワークです。サービスメッシュは、マイクロサービスの実装においてビジネスロジックに集中できることを目指して生まれた手法です。
具体的にはサービス間の通信制御をサービスごとに実装させるのではなく、すべてプロキシ経由の通信とし、ルーティングや認証などのプロキシ設定を全体に伝搬させます。プロキシ経由でサービス間に網状の構成を取ることから、サービスメッシュと呼ばれています。
Istioは以下の特徴を持ちます。
- Google、IBM、Lyftの3社共同開発により、2017年5月にOSS化されたサービスメッシュフレームワーク
- KubernetesのPodにプロキシ(Envoy)をサイドカーコンテナとして注入させることで、サービスのコード変更を伴わずにサービスメッシュの実現が可能
アーキテクチャは以下の通りです。
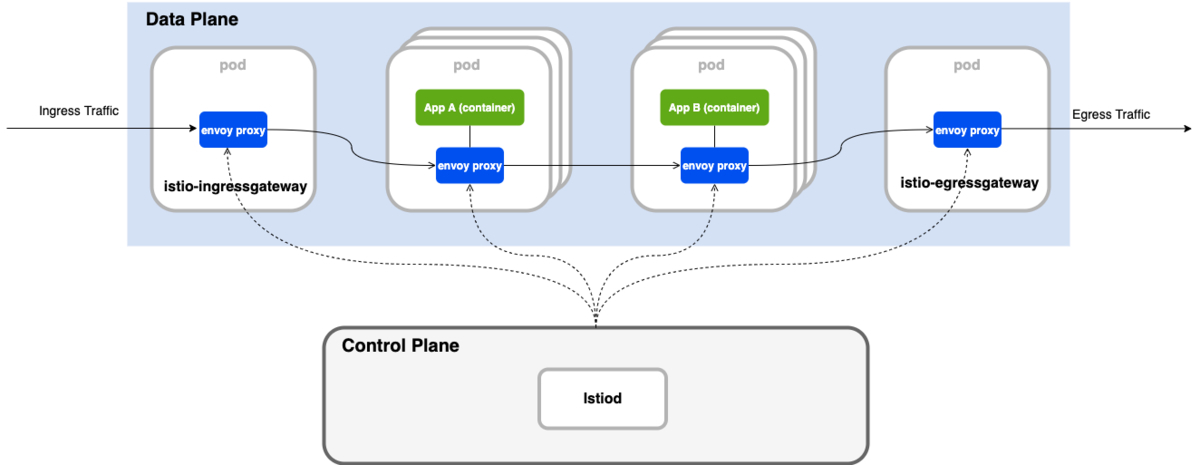
Istioのアーキテクチャは、Data PlaneとControl Planeに分割して考えることができ、それぞれ以下の特徴を持ちます。
- Data Plane
- サイドカーとして注入されるEnvoyプロキシ(正確にはEnvoyプロキシの拡張)のコンテナから構成される
- このプロキシがマイクロサービス間の通信を仲介・制御する
- Control Plane
- Envoyプロキシコンテナのサービスへの注入や設定伝搬を司る
Istioをプロダクションレディにするまでに直面した3つの課題
ZOZOTOWNでは、これからも持続的に成長を続けていくことを目的とし、現在レガシーシステムのリプレイスを進めています。ZOZOTOWNのリプレイス戦略については、以下のスライドをご覧ください。
その一環で、モノリシックアーキテクチャから、マイクロサービスアーキテクチャへの移行も行われています。そして、マイクロサービス化が進むにつれ、プラットフォーム基盤上で稼働する各サービス間通信に複雑性が生まれていました。
そこで、この課題を解決していくために、昨年度末にIstioの導入を推進しました。その際に、Istioをプロダクションレディな状態で導入していくために、以下3つの大きな課題に直面しました。
- どのようにリソース消費量を見積もるか
- 何を監視するか
- どのように可観測性を向上させるか
本記事では、それぞれどのように検討・対処を進めていったかをご紹介します。
どのようにリソース消費量を見積もるか
Istioのリソース消費量を見積もり、適切なキャパシティプランニングを行う必要があります。そのためには、アーキテクチャに基づき、Data PlaneとControl Planeをそれぞれ分けて考慮する必要があります。
Data Planeサイジング
Istioの公式ドキュメントによれば、Data Plane(Envoy)のパフォーマンスについて、以下のようにレポートされています。
- Envoyプロキシは、プロキシを通過するリクエストにおいて、1000リクエスト/秒あたり0.35vCPUと40MBメモリを使用する
- Envoyプロキシは、90パーセンタイルで、レイテンシに2.65ミリ秒を追加する
上記の数値は以下の前提で行われた負荷テストによる結果です。
- Istio 1.10を使用する
- サービスメッシュが1000個のサービスと2000個のEnvoyプロキシ(サイドカーコンテナ)で構成される
- サービスメッシュ全体で1秒あたり70000回のリクエストがある
実際にはData Planeのパフォーマンスは、以下にあるような要素にも依存し、変動します。
- クライアント接続数
- 目標リクエストレート
- リクエストサイズとレスポンスサイズ
- プロキシワーカースレッド数
- プロトコル
- CPUコア数
これらの要因により、レイテンシやスループット、EnvoyプロキシのCPUやメモリのリソース消費量は変化します。そのため、Istioの公式ドキュメントを参考にしながらも、実際に負荷試験を行い、実環境で計測することが非常に重要です。
Envoyプロキシのチューニング
負荷試験の説明を進める前に、まずData Planeのチューニングポイントである、Envoyプロキシのチューニングについて説明します。
Envoyプロキシのresource設定は、Envoyプロキシを注入するリソースに対しspec.template.metadata.annotationsの指定を追加することで、チューニング可能です。
resource設定に関するannotationは以下の通りです。
| annotation | 説明 |
|---|---|
| sidecar.istio.io/proxyCPU | EnvoyプロキシのCPU Requestを指定する |
| sidecar.istio.io/proxyCPULimit | EnvoyプロキシのCPU Limitを指定する |
| sidecar.istio.io/proxyMemory | EnvoyプロキシのMemory Requestを指定する |
| sidecar.istio.io/proxyMemoryLimit | EnvoyプロキシのMemory Limitを指定する |
以下の例は、Deploymentリソースに注入するEnvoyプロキシのCPU Limitを500m、Memory Limitを512Miに指定する例です。
apiVersion: apps/v1 kind: Deployment metadata: name: test-api spec: template: metadata: annotations: sidecar.istio.io/proxyCPULimit: 500m sidecar.istio.io/proxyMemoryLimit: 512Mi
その他のannotationでの設定は、公式リファレンスをご参照ください。
本記事で説明する負荷試験では、試験結果を見ながら、このannotationによるチューニングを繰り返し行いました。
負荷試験
プラットフォーム基盤では、以下の3つの負荷試験フェーズに分け、パフォーマンス測定を行い、チューニング精度を上げていくようにしました。
- Istioベンチマーク試験
- サービス単体負荷試験
- サービス結合負荷試験
また、プラットフォーム基盤でのIstioの導入は、BFF(Backends For Frontends)を実現するZOZO Aggregation APIがファーストターゲットとなりました。以下に示す負荷試験イメージは、このAPIの負荷試験を対象として記しています。
ZOZOTOWNのBFFへの取り組みについては、以下の記事をご参照ください。
Istioベンチマーク試験
Istioベンチマーク負荷試験は、以下の構成で実施しました。
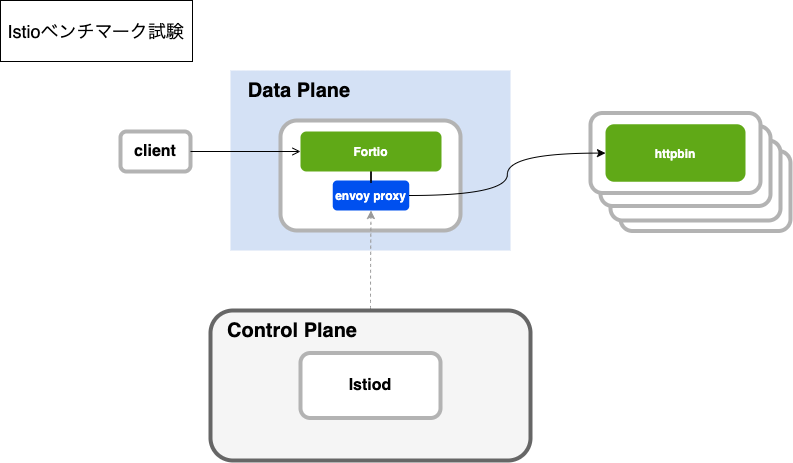
この構成では、実際のマイクロサービスをData Planeに置くのではなく、Fortioという負荷試験クライアントのPodにEnvoyプロキシを注入し、Data Planeに組み込んでいます。FortioがEnvoyプロキシ経由でコールするバックエンドサービスは、httpbinというモックを水平スケールさせた状態で稼働させています。この状態でクライアントからcurlコマンドでHTTPリクエストを実行し、Fortio経由でEnvoyプロキシに負荷をかけ、検証しました。
この試験は、各マイクロサービスに注入するEnvoyプロキシの初期リソース(CPU、Memory)サイジングに役立ちました。また、マイクロサービスのリソースサイジングだけでなく、Istioのバージョンアップにおけるパフォーマンスの変化を確認できる環境としても役立っています。
サービス単体負荷試験
サービス単体負荷試験は、以下の構成で実施しました。
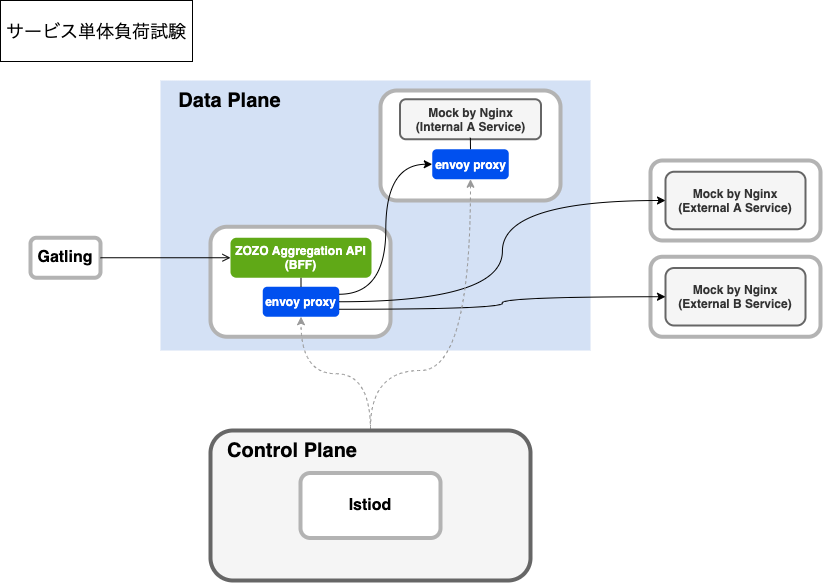
この構成では、試験対象であるマイクロサービスのPodにEnvoyプロキシコンテナを注入し、連携先である他サービスは、Nginxを用いて静的コンテンツを返すWebサービスモックを用意しました。さらに、負荷試験はIstioベンチマーク試験とは異なり、本番環境へのリクエストを想定したテストシナリオを作成し、Gatlingを負荷試験クライアントとして活用しています。
複雑なサービスメッシュ構成において一気にすべてのサービスを接続し、想定したパフォーマンスが出ない、あるいはエラーが頻発するというような事象が発生した場合、問題切り分けが非常に困難になります。被疑箇所は、以下のように分割して考える必要があります。
- 接続元サービス
- 接続元サービスのEnvoyプロキシ
- 接続先サービスのEnvoyプロキシ
- 接続先サービス
そこでサービス単体試験環境を用意し、接続元サービスと接続元サービスのEnvoyプロキシのチューニングを完了させた上で、実際のマイクロサービスを連携させた負荷試験のフェーズに進むことが重要と考えました。
サービス結合負荷試験
サービス結合負荷試験は、以下の構成で実施しました。
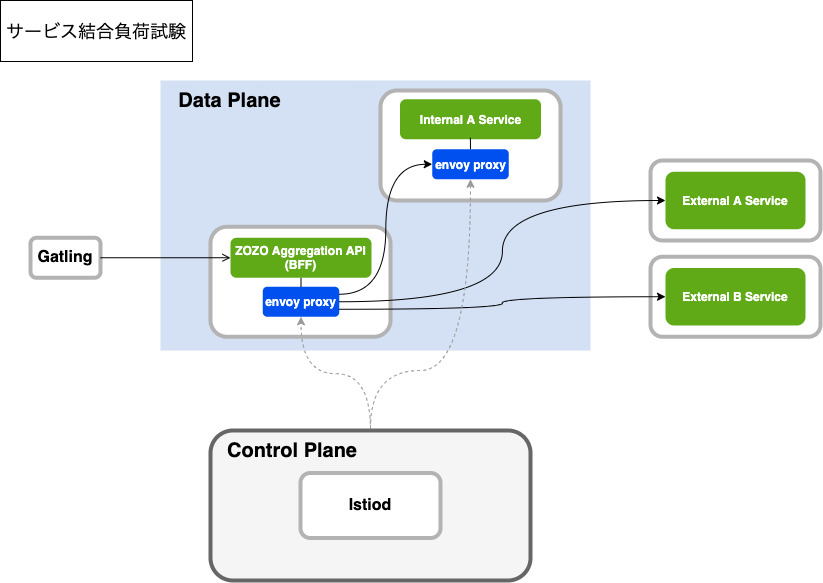
この構成では、連携する他サービスも含め、本番環境と同等の環境を用意しています。
この試験結果が期待通りでない場合は、単体負荷試験と比較しながら切り分けを行うことで、マイクロサービス間での課題整理をスムーズに進めることができました。
Control Planeサイジング
Control Planeを構成するIstiodコンポーネントのパフォーマンスは、以下の要素に依存し、変動します。
- Deploymentの変更頻度
- Configurationの変更頻度
- Istiodに接続するEnvoyプロキシ数
またIstiodは水平にスケール可能なので、CPU使用率などをトリガーとしてKubernetesのHPA(Horizontal Pod Autoscaler)設定で、オートスケールさせると良いです。
なお、本記事ではIstioの構築には深く触れていませんが、プラットフォーム基盤ではIstio Operatorを活用した構築をしています。Istio OperatorによりHPAの設定は自動生成され、IstiodのCPU使用率が80%に到達したら、オートスケールするようにしています。
何を監視するか
プラットフォーム基盤における運用監視には、Amazon CloudWatchとDatadogを採用しています。特に今回、既にDatadogで取得している各サービスの監視対象メトリクスなども合わせてダッシュボード化していくことも考慮し、Istioに関するメトリクスもDatadogで取得する方針としました。
DatadogにおけるIstioインテグレーションについては、公式ドキュメントをご参照ください。
メトリクス監視
監視対象のメトリクスについても、Data PlaneとControl Planeに分けて考慮しました。
Data Planeメトリクス
プラットフォーム基盤上に稼働している各マイクロサービスは、Datadog APMを活用し、マイクロサービス単位でのメトリクス収集・監視は十分に実施できている状況でした。そのため、Data Planeの監視は、個々のマイクロサービスに着目するのではなく、Data Plane全体のエラーレートを監視するのが良いと考えました。
そこで、以下の2つのメトリクスを用いて、エラー数 / リクエスト数 = エラーレートで算出した値を監視することにしました。
| メトリクス | 説明 |
|---|---|
| trace.envoy.proxy.hits | Envoyプロキシが受け付けたリクエスト数 |
| trace.envoy.proxy.errors | Envoyプロキシが受け付けたリクエストのエラー数 |
Control Planeメトリクス
前述の通り、プラットフォーム基盤ではIstio Operatorを用いた構築をしています。これによりControl Planeは、Istio Operatorのマニフェストファイルに基づき、自動運用されます。
例えば、Control PlaneのPod障害などがあった場合には自動で再起動され、Podのリソース消費が大きい場合にはオートスケールされるなど、回復性および拡張性をもった構成になっています。そのため、Control Planeの単純なインフラメトリクスの変化ではなく、Control Planeが正しい挙動をしていない以下のような状態を捕捉すべきと考えました。
- 何らかの原因でEnvoyプロキシの注入に失敗している
- 何らかの原因でEnvoyプロキシへの設定伝搬に失敗している
それぞれ以下のメトリクスを監視することで、捕捉できます。
| メトリクス | 説明 |
|---|---|
| istio.sidecar_injection.failure_total | Envoyプロキシの注入に失敗した回数 |
| istio.galley.validation.failed | Envoyプロキシへの設定伝搬に失敗した回数 |
分散トレーシング
プラットフォーム基盤ではIstioサービスメッシュの導入により、マイクロサービス間の通信が透過的にルーティングされ、複雑性が増しています。あるサービスのレイテンシ遅延の原因を調査したい場合に、1つのリクエスト起点で発生する複数のマイクロサービス呼び出しをすべてトレースし、どこで何が起きているのか特定するのは至難の業です。分散トレーシングは、まさにこれらのリクエストを追跡するための技術です。Istio Data Planeの分散トレーシングについては、Istioの公式ドキュメントで、ZipkinやJaegar、Lightstepを活用した方法が紹介されています。
前述の通りプラットフォーム基盤では、Datadog APMを活用し、各マイクロサービスの分散トレーシング情報を既に収集していました。そこで、Envoyプロキシを通過した通信も同様にDatadog APMを活用し、各マイクロサービスの通信とIstio Data Planeの通信を一気通貫でトレースできるようにしました。
Datadogを活用したIstio Data Planeのトレーシング情報の収集については、公式リファレンスをご参照ください。
以下は、実際の各マイクロサービスとEnvoyプロキシを通過する通信を含むトレーシング情報の図です。
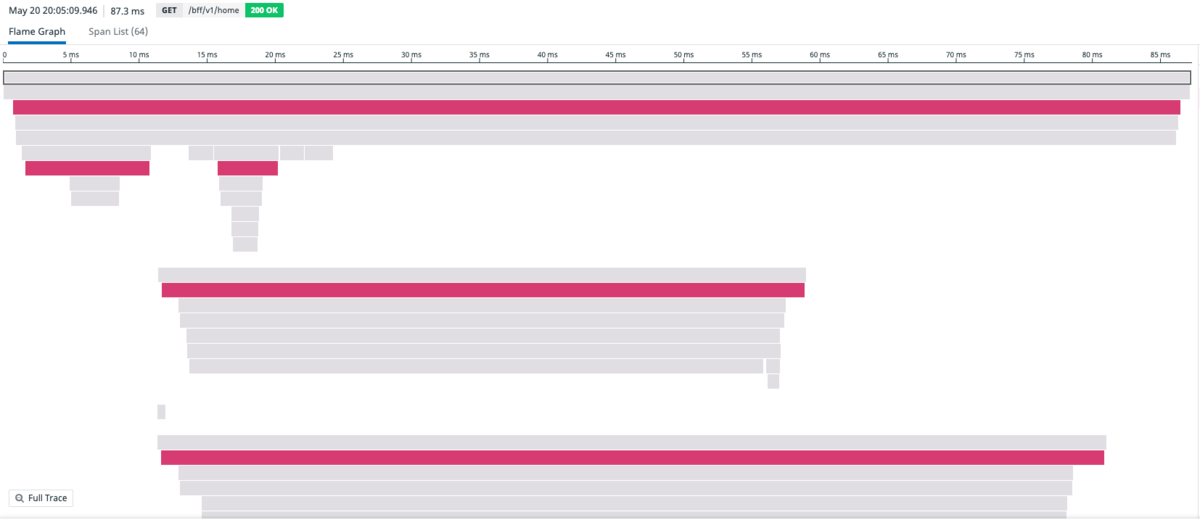
この図の「えんじ色」の部分が、Envoyプロキシのトレーシングを示しています。他のサービスからの呼び出し関係などを含め、一気通貫したトレースが容易になっています。
どのように可観測性を向上させるか
ここまでは、Istioの監視メトリクスについて、いくつか紹介してきました。
一方で、他にも常に監視対象とする必要はないものの、運用状態として可観測性を高く保っておきたいメトリクスもありました。それらはDatadog Dashboardを使い、一箇所に情報を収集・可視化し、Istioサービスメッシュの健康状態の把握を分かりやすくしています。
以下が実際のダッシュボードです。
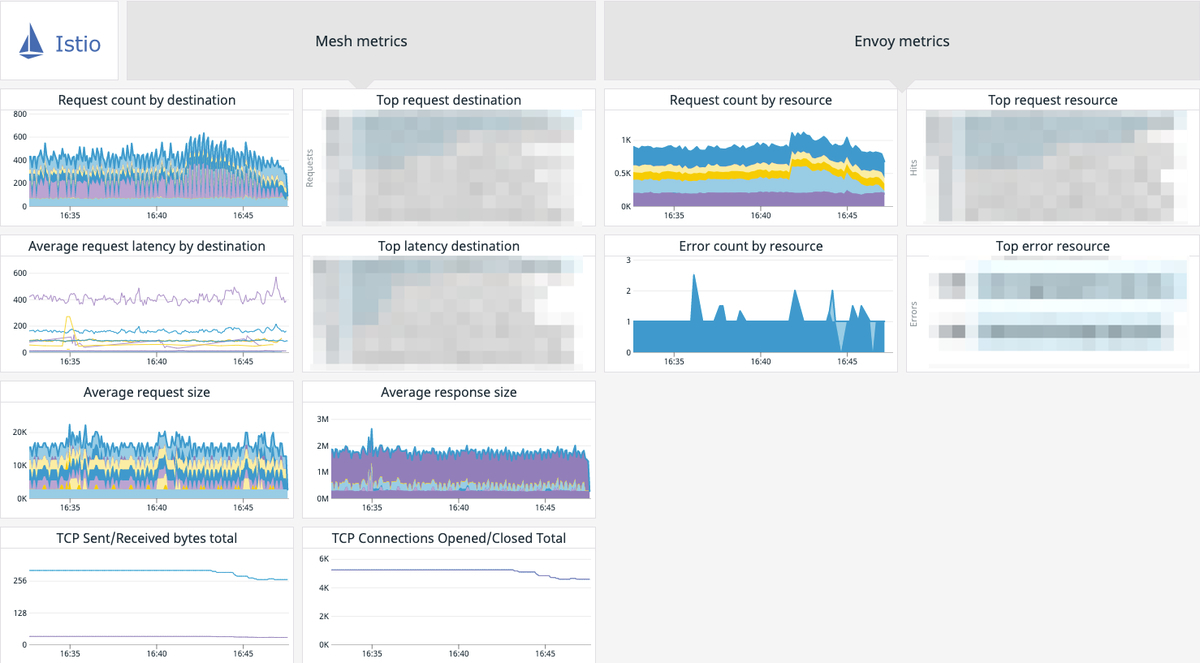
IstioのDatadog Dashboardの作成にあたっては、公式ドキュメントとブログが非常に参考になりました。
プラットフォーム基盤上のマイクロサービスで、パフォーマンス劣化やエラーなどが観測された際に、特にウォッチしているグラフは以下のものです。
| グラフ | 説明 |
|---|---|
| Request count by destination | 宛先ごとのリクエスト数 |
| Top request destination | リクエスト数上位の宛先 |
| Average request latency by destination | 宛先ごとの平均レイテンシ |
| Top latency destination | レイテンシ上位の宛先 |
| Request count by resource | マイクロサービスごとのリクエスト数 |
| Top request resource | リクエスト数上位のマイクロサービス |
| Error count by resource | マイクロサービスごとのエラー数 |
| Top error resource | エラー数上位のマイクロサービス |
例えば、サービスメッシュ全体のエラーレートが高騰した際に、特定のマイクロサービスに集中して発生している問題なのか、サービスメッシュ全体での問題なのか切り分ける必要があります。その際には、Top request resouceとTop error resourceのグラフを参考にしています。
具体的には、プラットフォーム基盤全体で発生している問題であれば、Top request resourceとTop error resourceのランキングは相関した動きになるはずです。一方で、特定のサービスに起因する場合は必ずしも相関せず、特定のサービスのみ大量にエラー発生している状態が読み取れるでしょう。
このように特定メトリクスを監視するだけでなく、Dashboardなどを活用した可観測性の向上も継続的に実施することが、サービスメッシュを拡大していく上では非常に重要です。
まとめ
本記事では、Istioサービスメッシュをプロダクションレディな状態で、ZOZOTOWNプラットフォーム基盤に導入してきた取り組みを紹介しました。Istioは今後ますますマイクロサービス全体に利用を拡大し、さらなる可観測性の向上や、サーキットブレーカーなどの高度な機能も取り入れていく予定です。また新たな知見が得られたら、紹介したいと思います。
終わりに
ZOZOテクノロジーズでは、一緒にサービスを作り上げてくれる方を募集中です。ご興味のある方は、以下のリンクからぜひご応募ください。