




はじめに
こんにちは。ブランドソリューション開発部プロダクト開発チームの木目沢とECプラットフォーム部カート決済チームの半澤です。
弊社では、ZOZOTOWNリプレイスプロジェクトや新サービスで、Amazon DynamoDBを活用することが増えてきました。そこで、AWS様から弊社向けに集中トレーニングという形でDynamoDB Immersion Daysというイベントを開催していただきました。
今回は、2021年7月6日、13日、14日の3日間に渡って開催された当イベントの様子をお伝えします。
7月6日のDay1及び、14日のDay3の様子をDay1のサブスピーカーとして参加した木目沢がお届けします。13日のDay2を同じくDay2にてサブスピーカーとして参加しました半澤がお届けします。
目次
- はじめに
- 目次
- Day1(2021年7月6日)
- Day2(2021年7月13日)
- NoSQL Design Patterns for DynamoDB
- SQL(リレーショナル)とNoSQL(非リレーショナル)の設計パターン
- Queryを使用した基礎的な探索方法
- 複合文字列ソートキーを使用して効率的に探索する
- GSIを追加して新しいアクセスパターンを実現する
- スパースなインデックスでコスト効率が高いスキャンを実現する
- カーディナリティの低いアイテムへの書き込みを分散する
- カーディナリティの高いパーティションキーを持つテーブル全体をGSIで効率的に探索する
- 読み込み時の負荷の偏りを軽減してスロットリングを回避する
- DynamoDBでOLAP処理を行う
- 大きなアイテムの扱い方
- ネストされたJSONをクエリする方法
- 特定のインデックスを選択的にクエリする
- DynamoDBのトランザクション
- 階層データをドリルダウンで絞り込む
- デザインパターンを学んで
- Advanced Design Patterns For Amazon DynamoDB
- NoSQL Design Patterns for DynamoDB
- Day3(2021年7月14日)
- さいごに
Day1(2021年7月6日)
1日目は2つのセッションが行われました。各セッションの模様を紹介します。
Amazon DynamoDB Architecture & History Amazon DynamoDBの進化を振り返る

最初のセッションでは、AWSソリューションアーキテクトの成田さんがメインスピーカーを、同じくソリューションアーキテクトの堤さんがサブスピーカーをご担当されました。
2004年にリレーショナルデータベース(以下RDB)の拡張性に関する課題が表面化し、その解決策として2007年にDynamoDBが誕生。2012年に一般への提供開始という歴史を説明いただきました。現在では、Amazon PrimeやAmazon Music、Amazon AlexaなどでもDynamoDBが使用されているということでした。
amazon.comを支えるために開発されたDBを、一般に提供してしまうそのポリシー、大変素晴らしいものと感じました。弊社でも最大限活用させていただきます。
その後は、DynamoDBの特徴を詳細に説明いただきました。個人的に特に印象深かったトピックスを紹介します。
データベースのスケーリング
SQLでは縦方向のスケーリング、つまり容量やメモリの増幅がスケーリングの対象であったのに対し、DynamoDBは水平にスケーリング、多数のシャードにスケールアウトされます。自動でスケーリングされるため、使う際にはあまり意識することがないのですが、仕組みを知っておく必要はあると感じました。一昔前はオンプレRDBのスケーリングに苦労した記憶があります。DynamoDBではマシンさえあればいくらでもスケールでき、しかもそれをユーザー側は意識する必要がないのは単純にすごいことだと思いました。
DynamoDB読み取りオペレーション
DynamoDBでは正確に0または1個の項目を返すGetItem、条件が指定できるQuery、テーブルのすべての項目を読み取るScanなどで項目を取得できます。NoSQLは検索しづらいイメージがありましたが、DynamoDBでは、一通り検索の仕組みが用意されています。
項目の分散(happy path)
DynamoDBではパーテーションキーをハッシュ化し、効率的なアクセスのために、近傍のデータをパーテーションとして保存します。よく、CloudFormationの定義でKeyType: HASHとしていますが、ここで使用されるものだったのですね。
レプリケーション
DynamoDBでは3つのアベイラビリティーゾーンにレプリケートされます。DynamoDBの高い稼働率の秘密がここにありました。DynamoDBは99.999%のSLAを保証しています。
オンデマンドモード
事前にキャパシティの予約をしなくても、読み取り、書き込みした分のみ課金されるモードです。弊社がDynamoDBを使用し始めたころにはなかったモードでした。当時DynamoDBへのアクセスを予測できない中、余裕を持ってキャパシティを確保していたためその分の料金がかかっていました。そんな中でオンデマンドモードを使用できるようになり劇的に料金を下げることができました。
他、グローバルセカンダリインデックス(GSI)やpoint-in-time recovery、On-demand backup、Global Tableなど多彩な機能が用意されています。これらを自前で用意するのは困難ですので、DynamoDBを活用しましょう。弊社では大いに活用させていただいております。
Amazon DynamoDB for Operations 今すぐ使えるAmazon DynamoDBのベストプラクティス集

続いて、DynamoDBのベストプラクティス集を一気にご説明いただきました。このセッションでは、AWSの堤さんに変わり、木目沢がサブスピーカーとして登壇しました。メインスピーカー成田さんの説明に沿って、質問や感想を行いました。
以下、個人的に特に印象深かったトピックスを紹介します。
適切なキャパシティを選択する
DynamoDBでは予め必要なキャパシティを予約するプロビジョンドモードとオンデマンドモードがあります。予めアクセス数が予測される場合はプロビジョンドモード、できない場合はオンデマンドモードが推奨されます。また、状況によってモードを切り替えるような運用の仕方もあるそうです。私の担当プロジェクトでは、セールなどでアクセス数が大きく変動し予測しずらい状況であったためオンデマンドモードを活用しています。このモードの選択により使用料金が大きく変わるのでよく検討する必要があるでしょう。
大きなアイテムを保存する方法
項目の最大サイズは400KBでそれ以上の項目は追加できません。また、大きなサイズを書き込むにもキャパシティユニットをその分消費するため、その対策を説明いただきました。項目名を短縮したり、S3に保存しパスだけ持つなど工夫のしどころがあると感じました。
グローバルセカンダリインデックス(GSI)のスロットリングに注意
グローバルセカンダリインデックスには非同期にデータが書き込まれます。グローバルセカンダリインデックスにも十分なキャパシティがないとスロットリングされるので注意が必要です。グローバルセカンダリインデックスについては、キャパシティの消費による料金の問題がよく課題に上がっていましたが、スロットリングにまでは注意していなかった気がします。ここは要注意です。
Time to Live(TTL)
期限切れのItemを自動的に削除する機能です。ゼロコストでパフォーマンスへの影響もなく、アーカイブも取ってくれるので便利な機能です。ただし期限切れしてすぐ削除するものではないので注意は必要です。期限切れItemが削除されるまでの時間要件がない場合、かなり使える機能ではないでしょうか。
DynamoDB Streams
DynamoDBのデータが更新されたイベントをStreamに流すことができます。弊社ではDynamoDB Streamsを活用し、Amazon Elasticsearch Serviceにデータを投入するなどで活用しています。また、最近ではAmazon Kinesis Data Streams for DynamoDBも使用できるようになりました。私の最近の担当プロジェクトではCQRSの構成でイベントをクエリ側にStreamとして流すためにこの機能を活用しています。
on demand backup
DynamoDBでは、簡単にバックアップが取れるようになっています。point in time recoveryを活用し継続的にバックアップを取ることも可能です。弊社でDynamoDBを使用し始めた頃にはなかった機能でした。そのため、DynamoDB Streamsからデータを投入していたAmazon Elasticsearch Serviceが実質バックアップになっていました。現在ではDynamoDB本体でバックアップが取れるようになり、非常に便利になったと感じた機能です。
Global Tables
世界的に活用されるサービスであればGlobal Tablesを利用することをおすすめします。簡単にマルチリージョンのデータベース構成を取ることができます。この機能は初めて知った機能でした。私の担当プロジェクトは国内向けなので使用することはありませんが、世界的に展開していれば、アクセス元から近いリージョンのDynamoDBを利用できるようになります。
Day2(2021年7月13日)

ここからは、半澤が2日目の様子や学んだ内容をご紹介します。
2日目も前半と後半の2部構成となっており、前半はソリューションアーキテクトの成田さんによる講義、後半はハンズオンを行いました。
NoSQL Design Patterns for DynamoDB
2日目のセッションでは、テーブルを設計する際にDynamoDBの機能を有効に使うためのデザインパターンを学びました。
DynamoDBの操作は、基本的にkey-valueのシンプルなkeyを使ったアイテム操作になります。しかし、デザインパターンを活用することでRDBやRDBライクな他のサービス・プロダクトで出来るような探索等をDynamoDBでも実現できます。また、DynamoDBの特性を生かした設計をする事により、スロットリングなどの問題を引き起こしにくくなります。
学んだ内容を順にご紹介します。
SQL(リレーショナル)とNoSQL(非リレーショナル)の設計パターン
DynamoDBには、JOINという概念がありません。DynamoDBのテーブルを設計する際は、RDBのように正規化するのではなく、非正規化して1つのテーブルにまとめます。これにより複数テーブルに対してクエリやJOINを実行せず、必要なデータの取得が可能です。
規模に関係なく数ミリ秒台のパフォーマンスを実現するDynamoDBの利点を最大限活かすためには、アプリケーションのアクセスパターンをしっかり整理・理解して、データを適切に書き込む必要があります。
設計では以下を行います。
- ユースケースの定義
- アクセスパターンの特定
- データモデリング
- アプリケーションタイプはOLTPなのか、OLAPなのか判断
- データのライフサイクル(TTL、バックアップ/アーカイブなど)を決める
- プライマリキーの設計
- インデックスの設計
Immersion Daysに前後して、初めてDynamoDBのテーブル設計をしましたが、AWSのドキュメントが充実しており大変参考になりました。なお、一度で設計を完了せず、コードを動かしたり机上の設計を元にボトルネックや非効率な探索などの問題を洗い出して、何度でも設計とレビューを繰り返しブラッシュアップできる体制を作ることが大事だそうです。
実際に自チームでモデリングを行なった際も、モデリングとレビューを何度も繰り返しました。ソリューションアーキテクトの方にも都度レビュー頂き安心して進めることができました。
Queryを使用した基礎的な探索方法
ソートキーやフィルター式、複合キーを使ったDynamoDBの探索機能であるQueryの効果をより引き出す基礎的なテクニックを学びました。
QueryとはSQLでいうSELECTのような探索機能です。DynamoDBのプライマリキーは、パーティションキー単体、もしくはパーティションキーとソートキーを組み合わせた複合プライマリキーがあります。パーティションキーは完全一致な指定のみ可能ですが、ソートキーは柔軟な条件指定が可能です。
Queryに使用できる主な機能は以下となります。
- KeyConditionExpression
- パーティションキーとソートキーに対する検索条件を記述します。 パーティションキーは完全一致
=のみですが、ソートキーは完全一致=以外にも>>=<<=やbetweenbegins_withなどの関数も使用可能です。
- パーティションキーとソートキーに対する検索条件を記述します。 パーティションキーは完全一致
- FilterExpression
- パーティションキー、ソートキー以外の要素で絞り込みを行う場合に使用します。
条件式はKeyConditionExpressionで使用可能なものに加え、
<>が使用可能です。 フィルター式はKeyConditionExpressionでの絞り込み後に適用され、消費されるリソースの削減には寄与しないのでご注意ください。
- パーティションキー、ソートキー以外の要素で絞り込みを行う場合に使用します。
条件式はKeyConditionExpressionで使用可能なものに加え、
- ScanIndexForward
- SQLでいうORDER BYです。デフォルトはASCとなります。
この他にもページネーションなど様々な機能をサポートしています。
以下のテーブルは、デバイスのログを保存するdevice_logsです。パーティションキーはdevice_id、ソートキーはcreated_at、プライマリキー以外の属性としてログレベルlevelを保持しています。
このテーブルから、特定デバイスのWARNINGレベルのログを降順に取得するQueryを構築してみます。

- 一般的なSQL
SELECT * FROM device_logs WHERE device_id = 12345 AND level = 'WARNING' ORDER BY created_at DESC;
- DynamoDBのQuery
aws dynamodb query \ --table-name device_logs \ --key-condition-expression "#device_id = :device_id" \ --filter-expression "#level = :level" \ --expression-attribute-names '{"#device_id": "device_id", "#level": "level"}' \ --expression-attribute-values '{":device_id": {"N":"12345"}, ":level": {"S": "WARNING"} }' \ --no-scan-index-forward
ExpressionAttributeNamesは要素名、ExpressionAttributeValuesは条件値をパラメータ化するオプションです。パラメータ化により、DynamoDBの予約語1とのバッティングを回避できます。例えばフィルターに使用しているlevelは予約語なので、--filter-expressionの中でlevel = :levelと記述はできません。また、パラメータ化により何度も同じ条件を書かず1つのパラメータで賄える場合もあり、記述を簡略化できるという利点もあります。
上記の例で、データ量が少ない場合は問題なくデータが取得できます。しかし、例えばパーティションキーとソートキーで絞り込んだ結果が100万件で、更にフィルターで除外するアイテム数が99万件の場合は上記のQueryで問題が発生します。Queryのコストは、パーティションキーとソートキーで絞り込んだ結果で決定するため、多くのアイテムをフィルターで除外するのは非常に非効率でスロットリングを誘発する可能性が高くなります。
このQueryを効率化するためのテクニックを次に学びました。
複合文字列ソートキーを使用して効率的に探索する
device_logsの構造を変更し、ソートキーにlevelとcreated_atを#で結合した文字列を保存します。

Queryの条件を一部修正します。
- Before
--key-condition-expression "#device_id = :device_id" \ --expression-attribute-names '{"#device_id": "device_id", "#level": "level"}' \ --expression-attribute-values '{":device_id": {"N":"12345"}, ":level": {"S": "WARNING"} }' \
- After
--key-condition-expression "#device_id = :device_id and begins_with(#level_with_created_at, :level)" \ --expression-attribute-names '{"#device_id": "device_id", "#level_with_created_at": "level_with_created_at"}' \ --expression-attribute-values '{":device_id": {"N":"12345"}, ":level": {"S": "WARNING"} }' \
ソートキーの前方一致での検索により、パーティションキーとソートキーで絞り込みが完結し、効率的な検索が可能となりました。
GSIを追加して新しいアクセスパターンを実現する
新しいアクセスパターンとして、あるオペレーターが対応した特定期間のログを検索したくなった場合の対応方法を学びました。パーティションキーにプライマリキー以外の属性であるoperatorを指定したグローバルセカンダリーインデックス(GSI)2を追加します。これによりN:Nの関係を表現し、新しいアクセスパターンでの検索が可能となります。

上記のインデックスから特定のオペレーターの対応した特定期間のログを検索する場合は次のようになります。
aws dynamodb query \ --table-name device_logs \ --index-name GSI_operator_created_at \ --key-condition-expression "#operator = :operator and #created_at between :from and :to" \ --expression-attribute-names '{"#operator": "operator", "#created_at": "created_at"}' \ --expression-attribute-values '{":operator": {"S":"MAX"}, ":from": {"S": "2020-02-02T00:00:00.000Z"}, ":to": {"S": "2020-02-02T00:00:10.000Z"} }' \ --no-scan-index-forward
--index-nameでインデックス名、--key-condition-expressionでオペレーターを指定し、その中でbetweenを使用し日時を範囲指定しています。
スパースなインデックスでコスト効率が高いスキャンを実現する
次に、大量のログの中から特別にエスカレーションされた数件を検索するようなパターンに有効なテクニックを学びました。
エスカレーションされたログに対して、ベーステーブルのプライマリキー以外の属性にescalated_toという要素を追加します。加えてescalated_toをパーティションキーに指定したGSIも作成します。なお、エスカレーションされていないアイテムには、escalated_toはnullではなく要素自体が存在しません。下図は、上がベーステーブル、下がGSIです。


作成したGSIに存在するアイテムは、escalated_toが存在するアイテムのみとなります。Scanを行なったとしても件数が少ないため、非常に効率的な探索が可能となります。このようなインデックスのことを、スパースなインデックス3と呼びます。
また、時間まで指定する用途がなく日付のみの指定に限られる場合は、2021-01-01のように時間情報を削除して格納することが推奨されます。検索の処理効率やレイテンシは変わりません。しかし、将来のテーブルサイズがTBレベルになるような場合では、話が変わってきます。予め不要な情報を削っておくことが、最終的なテーブルサイズに大きな影響を与える可能性があります。消費するキャパシティユニットの節約にもなるため、削れるバイト数は削っておくのがベストプラクティスです。
カーディナリティの低いアイテムへの書き込みを分散する
パーティションキーのカーディナリティが低いアイテムに対する書き込みを、キー空間のセグメント化により分散する方法を学びました。
次のテーブルは大統領選挙の投票数のようなデータを管理するテーブルです。プライマリキーはパーティションキーの候補者candidateで、プライマリキー以外の属性として投票数countを持っています。候補者はAとBのみで、アイテム数が限られています。そして、想定される書き込み負荷に備えてテーブルには10万書き込みキャパシティーユニット(WCU)を設定し、投票数に応じてcountをカウントアップします。
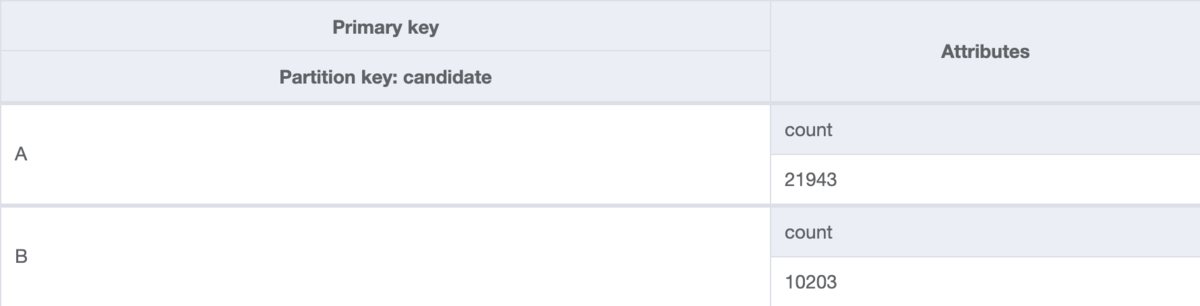
内部的には分散するためのリソースを用意し、10万WCUが出るテーブルになっています。しかし、この場合は特定のパーティションキーにのみ書き込みが集中するため、負荷分散されません。DynamoDBの単一アイテムへの書き込み上限は1,000WCUなのでスロットリングが発生してしまいます。
これを解決するには、まずパーティションキーに0-Nの文字列を結合したアイテムをN個作成しておきます。カウントアップする際は0-Nのアイテムへランダムに書き込むようアプリケーション側で制御します。結果を取得する際には0-Nのアイテムを直列、または並列にアプリケーションで取得して集計して結果を書き込みます。

書き込み時に必要なパーティション数を算出するには次の計算式を利用します。
- 1秒あたり100K WCUの書き込みを実現したい場合
100K * CEILING(ItemSize/1KB) / 1000 = 100
- 平均アイテムサイズ4を1KB(1WCUごとに書き込める上限値)で割る
- ここでは、平均アイテムサイズを仮に1KBとします
- 実現したい10万WCUの100Kをかける
- 1パーティションあたりの書き込みWCU上限の1000で割る
- 最低100アイテムあれば理論上分散され10万WCU出るという結果が出る
アイテムサイズを計算をした上で、--return-consumed-capacityオプションを付与してDynamoDBへ書き込みを行い、実際に消費したキャパシティユニットを確認すると確実です。また、書き込むパーティションが偏る可能性もあります。計算結果は最低値と考えてテストを実施し、偏りが出ないか検証が必要です。偏りが出てしまう場合は150、200と余裕を持った数を設定しておくと安全です。
カーディナリティの高いパーティションキーを持つテーブル全体をGSIで効率的に探索する
先ほどは書き込みの例でしたが、次はテーブル全体をクエリするためにキースペースを人工的にセグメント化する手法を学びました。
UUIDのように推測しづらくカーディナリティの高いパーティションキーを持つテーブルがあるとします。このテーブルの10年分のアイテムから直近4時間以内の登録アイテムを検索するパターンを考えます。パーティションキーは完全一致の指定が必要なため、最近登録されたUUIDリストを元にGetItemを数万回発行するか、10年分をScanしてフィルター条件で除外するという非効率な探索となります。
これを解決するためには、ベーステーブルのプライマリキー以外の属性にランダムな数値を持たせ、パーティションキーに指定したGSIを作成します。下図は、上がベーステーブル、下がGSIです。


GSI上では単純化された0-Nがパーティションキーとなるため、パーティションキーとソートキーの範囲指定で効率的な探索が可能になります。また、パーティションを分けることで、1つのパーティションに集中した際のスロットリング防止にもなります。
読み込み時の負荷の偏りを軽減してスロットリングを回避する
次は読み込み時の負荷を軽減する方法について学びました。例として商品情報の読み込みについて考えます。通常商品と人気商品やトップページに表示される商品のように、アイテム間で負荷が極端に偏る場合があります。DynamoDBは1アイテムの読み込みにつき、3,000読み込みキャパシティーユニット(RCU)を超えるとスロットリングが発生してしまいます。
この場合はAmazon DynamoDB Accelerator(DAX)5やElastiCache Redis6などのキャッシュを有効に使うことでスロットリングを回避します。
DAXはフルマネージド型の高可用性インメモリキャッシュです。DynamoDBに特化したサービスで、ライトスルー方式のキャッシュを使えるのが最大の利点です。DAXクライアントはDynamoDBと同じ書き込みオペレーションをサポートしており、クライアントを差し替えるだけでキャッシュとDynamoDBへの同時書き込みが可能となります。
DAXのキャッシュはGetItem時に使用される項目キャッシュと、Query、Scan時に使用されるクエリキャッシュで独立しています。どちらもDAX上にキャッシュが存在しない場合はDynamoDBへ問い合わせて結果をキャッシュ上に保存します。DAXクライアントを通したライトスルー方式の書き込みは、すべて項目キャッシュへ保存されます。クエリキャッシュは検索条件毎に保存され、項目キャッシュの変更が反映されないため、TTLを短く設定しておくのがベストプラクティスです。
DAXよりもRedisなど他のキャッシュが推奨されるのは以下のような場合です。
- RedisのSorted SetsやPubSub、ストリーム等の他のキャッシュ特有の機能が必要な場合
- QueryやScanのキャッシュインバリデーションが必要な場合
- 既にアプリケーションでキャッシュを使用しており、同居した方がコストを抑えられる場合
以上のように、要件によって適したサービスを使い分ける形となります。
DynamoDBでOLAP処理を行う
Day1で、データ処理タイプには以下の2つがあり、DynamoDBはOLTPに向いていることを学びました。
- OLAP(Online Analytical Processing)
- 複雑なクエリで大量のデータを元に分析する
- OLTP(Online Transaction Processing)
- 単純なクエリを高速に処理する
DynamoDBはOLAP処理に適していませんが、必要となった場合の手段としてDynamoDB StreamsとExports to S3が用意されています。
DynamoDB StreamsはDynamoDBへ更新が入ったイベントデータをStreamから取得できるサービスです。Streamレコードには、書き込み・変更・削除の変更前と変更後のアイテム情報が格納されています。DynamoDB StreamsとLambdaを連携し、OLAP向けのクエリエンジンへ連携することでOLAP処理が可能となります。
また、2020年に新機能としてExports to S3がリリースされました。この機能を使用することにより、DynamoDBのデータをS3にエクスポート可能です。これにより、比較的簡単にAthenaなどへ連携しOLAP処理が可能となりました7。
DynamoDB Streamsは変更があった際に、ニアリアルタイムに処理してデータを連携できるので、直近のデータが必要な場合や多数の分析処理が常にあるようなケースにマッチします。しかし、1度限りのスポットな分析用途で特定の時点までのデータを必要とするケースでは、必要な時にS3へエクスポートして分析する事で、より低コストかつ簡単に連携できます。
要件に合わせて連携方法を使い分けましょう。
大きなアイテムの扱い方
サイズの大きなアイテムを扱う場合のテクニックを学びました。
下記はユーザがアップロードしたデータの処理状況を管理するためのテーブルです。パーティションキーはuser_id、ソートキーはstatusとcreated_onの複合キーです。プライマリキー以外の属性documentにサイズの大きなデータを格納しています。

1アイテムの平均サイズは256KBで、ユーザーは1度に最大50件のアイテムを一覧で取得したい場合を考えます。
この場合消費されるRCUの計算式は以下となります。
50 * 256KB * (1RCU / 4KB) * (1/2) = 1600RCU
- 4KBは1RCUで読み込めるデータサイズ上限
- 「結果整合性のある読み込み」を利用するため1/2をかける
計算結果から、1回の一覧取得に1,600RCU消費することがわかりました。もしも10人、100人が同時にアクセスするならば膨大なRCUが必要です。
この問題を解決するために、ベーステーブルの設計を少し変更します。新たにreport_idをパーティションキーとして追加し、user_idをプライマリキー以外の属性に変更します。そして一覧表示に使用するデータのサマリsummaryを追加しました。

次に、ユーザーを指定して一覧を取得するためのGSIを作成します。パーティションキーはuser_id、ソートキーはステータスと追加日の複合キーstatus_with_created_onを指定します。そして、GSIのProjectionTypeにINCLUDEを指定し、GSIのプライマリキー以外の属性にreport_idとsummaryを含めるよう設定しました。

GSIにはdocumentを持たないため、1アイテムあたりのサイズが削減されます。その結果、一覧表示に必要なRCUはたったの1RCUとなり、効率的な探索が可能となりました。また、一覧から詳細情報を取得する際はGSIから導き出したreport_idを元にGetItemが可能です。
Queryは--selectオプションで要素名を指定でき、SQLでカラム名を指定するのと同じように取得する要素の絞り込みが可能です。しかし、RCUは絞り込む前のアイテム全要素分を消費します。そのため、不要な要素はなるべく削除しアイテム自体を小さくしておくことが重要です。
また、Queryにかかるコストは前述の計算式のように、取得した全件のデータサイズを4KBで割ったものとなります。対象データ全てをGetItemで取得すると1回あたり1RCU(結果整合性のある読み込みの場合は0.5RCU)かかるため、Queryで一度に取得する方が効率的でコストも小さくなります。
ネストされたJSONをクエリする方法
次に、ネストされたJSONデータの特定の値を取得するためのテクニックを学びました。
例として、パーティションキーuser_idに対して、以下のようなカート情報のJSONが格納されているケースを見ていきます。カート内の靴下のpriceを取得したい場合、アプリケーションにJSONデータを一度ロードし解析する必要があります。
{ "cart_items": [ { "item_name": "靴下", "item_id": "靴下ID", "sku": "靴下SKU", "quantity": "2", "price": "3,300", "category": "レッグウェア", "sub_category": "ソックス/靴下", "added_at": "2021-08-01T00:00:00.000Z" },{ "item_name": "お茶碗", "item_id": "お茶碗ID", "sku": "お茶碗SKU", "quantity": "1", "price": "5,500", "category": "食器/キッチン", "sub_category": "食器", "added_at": "2021-08-01T00:10:00.000Z" } ], "ship_to": { "name": "ZOZO MAX", "address": "稲毛区緑町1-15-16", "city": "千葉市", "state": "千葉県", "postal_code": "263-0023", "phone": "04-1234-5678" } }
必要な箇所がドキュメントの一部であっても、ドキュメント全体を毎回操作すると、消費コストが大きくなります。アイテムを要素ごとに垂直分割することで、容量とコストの削減になりパフォーマンスが向上します。
上記のJSONデータを分割するため、ソートキーで階層を表現するとこのようになります。これにより、ネストされた複雑な値に対する探索や書き込みが可能となりました。

# マックスさんのカートに入っている靴下の`price`を取得するQuery aws dynamodb query \ --table-name carts \ --key-condition-expression "#user_id = :user_id and #sort_key = :sort_value" \ --expression-attribute-names '{"#user_id": "user_id", "#sort_key": "sort_key"}' \ --expression-attribute-values '{":user_id": {"S":"MAX"}, ":sort_value": {"S": "cart_items#price#靴下ID"} }'
# マックスさんのカートのアイテム一覧情報を取得するQuery aws dynamodb query \ --table-name carts \ --key-condition-expression "#user_id = :user_id and begins_with(#sort_key, :sort_value)" \ --expression-attribute-names '{"#user_id": "user_id", "#sort_key": "sort_key"}' \ --expression-attribute-values '{":user_id": {"S":"MAX"}, ":sort_value": {"S": "cart_items"} }'
更に、sort_keyをパーティションキー、gsi_skをソートキーに指定したGSIを作成します。

これにより、ユーザー全体から靴下をカートに入れているユーザーの特定や、特定地域へ発送するユーザーの特定が可能となりました。これはGSI Overloadingと呼ばれる手法で、あえてソートキーを曖昧にすることで、拡張性を担保した上で1つのGSIで複数のコンテキストによる探索が可能となります。
特定のインデックスを選択的にクエリする
次は前のテクニックとは逆に、GSIを検索条件毎に作成して特定のパーティションキーを静的逆引きするテクニックを学びました。
例として、クリスマスプレゼントに箱猫マックスの千葉県ご当地ステッカーを作り、以下の条件に当てはまるユーザーへプレゼントするという場合を考えます。
- 発送先住所を千葉県で登録している
- 12月が誕生月
- 12月に注文している
ベーステーブルはuser_idがパーティションキー、プライマリキー以外の属性には検索に必要な要素を持っています。そして、user_idを逆引きするため、検索に必要な条件分のGSIを作成します。下図は上から順にベーステーブル、発送住所の都道府県GSI、誕生月GSIと最後の注文月GSIです。


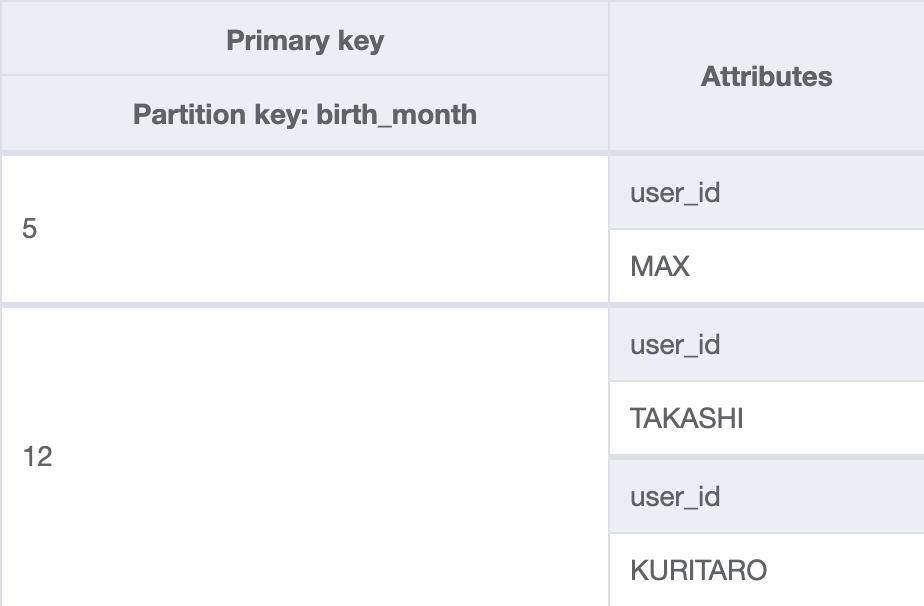

これにより、GSIを探索してベーステーブルのパーティションキー特定が可能となります。設計を最適化していく上で、このようなテクニックが有効になる場合もあることを覚えておくと便利です。
DynamoDBのトランザクション
DynamoDBはトランザクションをサポートしています。トランザクションは書き込みと読み込みの2種類あり、どちらも最大25のアクションが実行可能です。しかし、非正規化した形でモデリングを行いDynamoDBに最適化した方が効率的になることも多く、局所的に必要な場面での使用が推奨されています。
階層データをドリルダウンで絞り込む
例えば全国の店頭・ロッカー受取りサービスの受け取り場所を住所からドリルダウンで絞り込む場合、以下のように複合キーを用いた前方一致の検索にて実現可能です。

- 紀尾井町の受け取り場所一覧を検索する場合
aws dynamodb query \ --table-name pick_up_locations \ --key-condition-expression "#state = :state and begins_with(#location, :location)" \ --expression-attribute-names '{"#state": "state", "#location": "location"}' \ --expression-attribute-values '{":state": {"S":"東京都"}, ":location": {"S": "千代田区#紀尾井町"}}'
デザインパターンを学んで
講義を通して、以下を学ぶことができました。
- リレーショナルデータベースとの違い
- DynamoDBのテーブルを設計する時は、まずアクセスパターンを洗い出し逆算してモデリングを行うこと
- スロットリングなどの問題を回避し、DynamoDBの利点を最大限享受するために様々なデザインパターンが存在すること
- OLAP処理は他のOLAPに向いているサービスに連携することで、全体のアーキテクチャをスケールするということ
- トランザクションやExports to S3などの便利な新機能が用意されており、年々機能がアップデートされていること
GSI Overloadingなどの高度なテクニックはNoSQLに慣れていないとなかなか出てこない発想だと思いますが、覚えておくことで今後役に立ちそうです。
成田さんからは最後に「複雑になればなるほど、オプティマイザやストレージエンジンの気持ちを考えてモデリングを行う必要があります。迷ったら是非SAをレビューに呼んでいただき、一緒にブラッシュアップしていきましょう!」とメッセージをいただきました。オプティマイザの気持ちを全て理解するのはまだ難しいですが、今回の講義を通して少しは理解できるようになった気がします。成田さん、ありがとうございました!
Advanced Design Patterns For Amazon DynamoDB
講義後、1時間半のハンズオンワークショップが開催されました。解説は引き続き成田さんで、流れに沿ったデモをソリューションアーキテクトの馬(Ma)さんに画面共有しながら実演いただきました。参加者はイベント用アカウントでAWSのWebコンソールへログインし、馬さんのお手本を見ながら動作を確認しました。また、他にもソリューションアーキテクトの方が数名サポートとして参加されており、詰まった場合はすぐにサポートしてもらえる体制でした。
このワークショップの具体的な内容は、「Hands-on Labs for Amazon DynamoDB :: Amazon DynamoDB Workshop & Labs」にて公開されています。
以下は見出しの日本語訳です。興味を引くものがあれば、ぜひ挑戦ください。
- Setup
- ラボ環境をセットアップ
- EC2のラボインスタンスに接続
- DynamoDB Capacity Units and Partitioning
- DynamoDBテーブルを作成
- サンプルデータを投入
- 実行時間を比較するため、スクリプトから大量データを登録する
- CloudWatchでメトリクスを見る
- テーブルのキャパシティを増やす
- 再度大量データを登録して前回の実行時間と比較する
- キャパシティの少ないGSIを作成し、大量データを投入してスロットリングを確認する
- Sequential and Parallel Table Scans
- 直列スキャンを実行して実行時間を確認する
- 並列スキャンを実行して直列スキャンと実行時間を比較する
- Global Secondary Index Write Sharding
- GSIを作成する
- シャーディングされたGSIからのステータスコードと日付で並べ替えられたデータを効率的に読み取る
- Global Secondary Index Key Overloading
- GSI Overloading用のemployeesテーブルを作成する
- 作成したテーブルにデータを投入する
- オーバーロードされた属性を持つGSIを使用して複数のアクセスパターンの探索を実現する
- Sparse Global Secondary Indexes
- employeesテーブルにis_managerをパーティションキーとしたGSIを追加する
- ベーステーブルをスキャンとフィルター条件でマネージャーを探索し、スキャンされたアイテム数、実行時間を確認する
- 作成したGSIをスキャンして、スキャンされたアイテム数と実行時間を比較する
- Composite Keys
- employeesテーブルのパーティションキーに「state#州」、ソートキーに「都市#部門」の複合キーを使用したGSIを作成する
- 州を指定してクエリを実行する
- 都市を指定してクエリを実行する
- 都市と特定の部門を指定してクエリを実行する
- Adjacency Lists
- InvoiceAndBillingテーブルを作成し、GSIを作成し、データをロードする
- コンソールからGSIをScanし、1つのテーブルに複数のエンティティタイプが存在することを確認する
- Invoice詳細をクエリする
- GSIを使用してCustomer詳細とInvoice詳細をクエリする
- Amazon DynamoDB Streams and AWS Lambda
- logfileテーブルのレプリカ用にlogfile_replicaテーブルを作成する
- IAMロールのポリシーを確認する
- Lambda関数を作成する
- DynamoDB Streamsを有効にする
- DynamoDB StreamsをLambda関数にマッピングする
- logfileテーブルにデータを入力し、logfile_replicaへのレプリケーションを確認する
これまでの講義で学んだテクニックを、実際に手を動かして確認しました。手を動かしたことで理解が進み、業務で利用する自信が付きました。また、役に立つコマンドやGSI作成時にはどのくらい時間がかかるのかなど、ワークショップを通しての学びも多く、とても充実した時間でした。
成田さん、馬さん、サポートいただいたソリューションアーキテクトの皆様、ありがとうございました!
Day3(2021年7月14日)

改めまして木目沢です。最終日のセッションはAWS石川さんにご担当いただきました。1日目、2日目で教えていただいたテクニックをすべて駆使して具体的なシナリオを元に設計、実装していくハンズオンです。
オンライン小売店のカートシステムと、銀行で定期支払いを管理するシステムの2シナリオが用意されており、石川さんが直接設計、実装していく様子を見ながら一緒に手を動かしました。
こうして手を動かし、構築することで、漠然と理解していた2日間の内容もかなり整理できました。
これらのシナリオも「Design Challenges :: Amazon DynamoDB Workshop & Labs」にて公開されていますので、ぜひ皆さんも挑戦してみてください。
さいごに
コロナ渦ということもあり、オンラインでの開催となりましたが、DynamoDBの奥深いところまでご説明いただき、弊社の各サービスでの活用に大いに役に立つ内容でした。お忙しい中イベントを企画し、実現いただいたAWSの皆様、本当にありがとうございました。
ZOZOテクノロジーズでは、DynamoDBを始めとするAWSを活用し、サービスを成長させていく仲間を募集中です。ご興味ある方はこちらからぜひご応募ください!