




はじめに
データシステム部検索技術ブロックの内田です。私たちはZOZOTOWNの検索精度改善や検索システムの運用効率化のためのメンテナンスなどに取り組んでいます。
これまでテックブログでご紹介してきた通り、ZOZOの検索改善チームではランキング学習(Learning to Rank)やクエリの意図解釈、ベクトル検索の導入など、比較的モダンなアプローチでZOZOTOWNの検索改善に努めてきました。先進的な技術を調査し、サービスの開発に応用することはサービスの品質改善において重要な取り組みです。
しかし、モダンなアプローチをとる一方で、検索エンジンのベーシックな設定についてはメンテナンスする機会が徐々に減少していきました。設定内容や経緯を把握している開発メンバーの割合も減っていき、このままだと誰も触れない謎の設定になってしまうリスクがあったため、一度見直しを実施することにしました。
この記事では、全文検索エンジンの基礎的な設定について見直しを始める際に意識した内容を紹介します。これから検索システムを構築する方、全文検索エンジンの設定について学ぶ方の参考になれば幸いです。
全文検索システムの設定の基礎
全文検索とは、与えられたクエリにマッチするテキスト情報を持つ文書を発見する技術です。Luceneを代表とする全文検索エンジンは、文書に含まれるテキスト情報を解析して索引(インデックス)を構築することでクエリにマッチする文書の発見の高速化を実現しています。
ここで重要となるのが、文書中のテキスト情報からインデックスに登録されるトークンをどのように抽出するかという問題です。トークン抽出の品質は、全文検索全体の精度に大きく影響を与えます。そのため、トークン抽出を担うアナライザー(解析器)の設定は非常に重要です。
Apache SolrやElasticsearchなどのLuceneベースの全文検索エンジンでは、アナライザーは以下のような三層構成をとります。入力が想定されるクエリや文書に含まれるテキスト情報に応じてそれぞれを設定します。クエリに対して適用するアナライザーと文書中のテキスト情報に適用するアナライザーは別々に設定できますが、出力されるトークンの一致が取れるよう設計する必要があります。
- Character filter:入力されたテキストに対する加工処理
- Tokenizer:トークンへの分割処理
- Token filter:トークンに対する加工処理

テキスト情報に応じたアナライザー設定
N-Gramと形態素解析
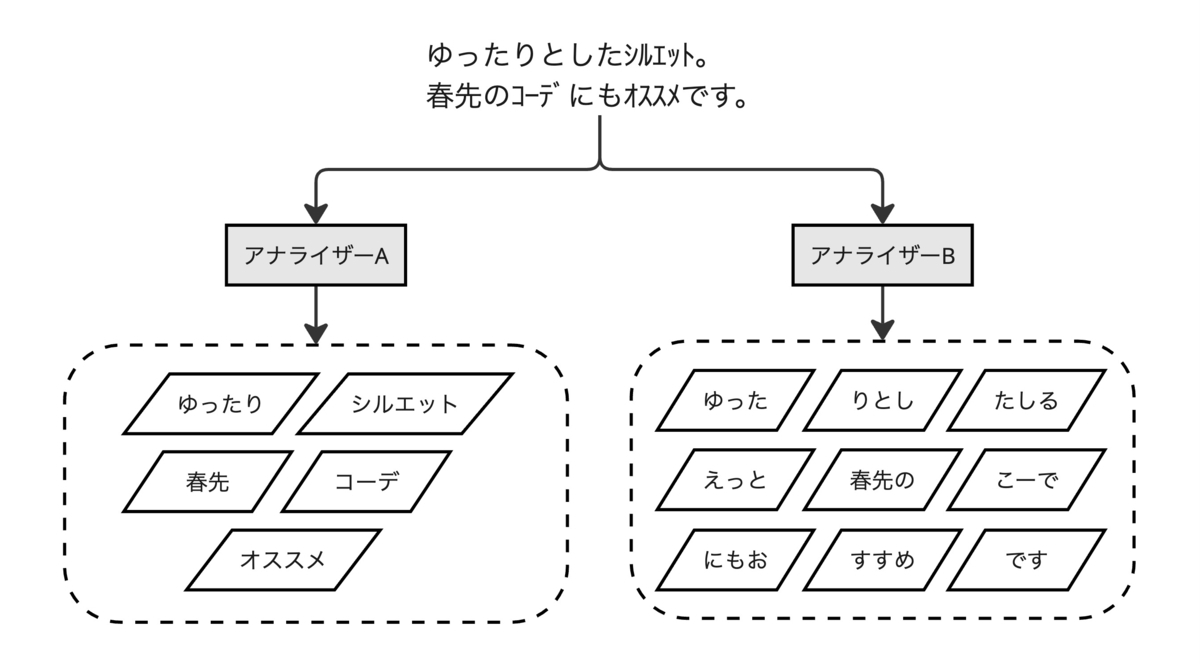
先述した通り、検索エンジンに文書を登録する際にはテキスト情報をトークンに分割する必要があります。英語など西洋の多くの言語では空白文字で単語が区切られますが、日本語の文章は明確な区切り文字を持ちません。そのため、日本語で構成される文書に対しては、N-Gramと形態素解析に基づいたトークン分割が採用されることが多いです。ZOZOTOWNの検索システムでも検索対象フィールドに対しては、この2種のトークン化手法に基づいたアナライザーが設定されています。
N-Gramは文章をN文字ごとに区切ります。一方で形態素解析は辞書に基づき意味のある単位で文字列を区切ります。

| 利点 | 欠点 | |
|---|---|---|
| N-Gram | ・検索漏れが少ない(再現率が高い) ・辞書が不要 |
・検索ノイズが多い ・無差別に分割するため、インデックスのサイズが肥大化しがち ・N文字以下の文字列入力に対してトークンを出力できない |
| 形態素解析 | ・検索ノイズが少ない(適合率が高い) ・インデックスのサイズが小さめ ・品詞に基づくフィルタリングや変形が可能 |
・辞書が必要 ・辞書に過不足があり単語を正しい位置で区切れなかった場合に検索精度が低下する (主に未知語による検索漏れが起こりやすい) |
この通り、N-Gramと形態素解析はそれぞれ得意とする領域が異なります。どちらを適用するかは取り扱うテキスト情報の特徴に合わせて検討する必要があります。例えば、ZOZOTOWNで取り扱う商品のテキスト情報には以下のような特徴があります。
- 商品名:主に名詞で構成されるため、品詞に基づく処理を必要としない。ファッション系の商品名はカタカナの連語で構成される固有名詞(未知語)であることが多く、形態素解析器では正しい位置で区切ることが難しい。
- 商品説明文:入力テキストが大きく、比較的多量のトークンが抽出される。日本語の文章で記述されていて、検索上意味を持ちにくい助詞などの形態素を数多く含むため品詞によるフィルタリングを行いたい。
これら2つの手法を適用したフィールドを横断的に検索するクエリを用いることで検索の精度を向上させることが出来ます。代償として検索処理の計算コストやインデックスのサイズおよび構築時間が膨らむため、それに見合った精度向上が期待できるかは検証するとよいでしょう。また、それぞれのフィールドに対するスコア重み付けの調整も重要です。
辞書
現在、ZOZOTOWNの検索システムに設定されている各種辞書の見直しに取り組んでいます。見直しを進める中で、逆に検索精度面に問題を発生させてしまっている設定が見受けられました。その一例を紹介します。
形態素解析器のユーザ辞書
ZOZOTOWNの検索システムは形態素解析器としてKuromojiを採用しています。Sudachiなど他の形態素解析器では挙動が異なる可能性があるためご注意ください。
形態素解析器の辞書は形態素解析処理の根幹となるため、検索の精度に大きく影響を及ぼします。文書中に出現する語句を多くカバーするためにユーザ辞書に単語を片っ端から追加してしまいがちです。ZOZOTOWNの検索システムの形態素解析ユーザ辞書にも過去に様々な語句が登録されていました。
ここで注意が必要なのが、ユーザ辞書に登録された語は優先的に区切られやすくなるというKuromoji tokenizerの挙動です。例えば、ZOZOTOWNではアクセサリーの略語である「アクセ」がユーザ辞書に登録されていました。これにより、「アクセ」を部分文字列に含む文章は概ね「アクセ」トークンを含むように分割されるようになります。結果として「アクセサリー」を意図して「アクセ」というクエリで検索したユーザに対して、全く関連のない商品を返してしまうことがありました。
GET _analyze { "tokenizer": { "user_dictionary_rules": [ "アクセ,アクセ,アクセ,カスタム名詞" ], "type": "kuromoji_tokenizer" }, "text": [ "アクセント" ] } // Output: { "tokens": [ { "token": "アクセ", "start_offset": 0, "end_offset": 3, "type": "word", "position": 0 }, { "token": "ント", "start_offset": 3, "end_offset": 5, "type": "word", "position": 1 } ] }
このような挙動は辞書に登録された短い語句で頻繁に発生していました。そのため、文書に登場する未知語を片っ端からユーザ辞書に登録するのではなく、以下のケースに絞って登録する方針で整理を進めています。
- 語句が意図せず区切られてしまっている場合、区切らせないためにその語句を登録する
- 途中で区切られてほしい語句(フレーズ)が区切られない場合、その語句の区切り方を登録する
シノニムの辞書
検索の再現率を向上させるためにSynonym (graph) token filterを利用することがあります。辞書に語句の同義関係を記述することで、検索時にトークンの拡張を行えます。
Synonym token filterは、元のトークンとシノニム拡張で得られたトークンを同等の重みで扱う点に注意が必要です。スコア計算式によっては、拡張後のトークンにマッチした文書が元のトークンにマッチした文書よりも高いスコアを持つことがあります。ヒット件数を増やしたいという動機で軽率に同義関係を増やしてしまうと、検索の精度に悪影響を及ぼす危険性があります。
例えばZOZOTOWNでは、シノニム辞書に「リング」と「指輪」が同義語として登録されていました。「指輪」で検索した際に、ピンキーリングなどの指輪商品をヒットさせたかったものと思われます。これら2つの語は似た意味を持ちますが、厳密には同義ではなく「リング」は指輪に限らず輪形のもの全般を指す語です。結果として、指輪を探すユーザに対して、イヤリングやスマホリングなどを返してしまう不具合を発生させてしまっていました。
シノニム拡張は再現率を向上させるのに有用ですが、スコアの制御ができないため、同義ではなく類義の語まで適用範囲を拡張してしまうと思わぬ結果を招くリスクがあります。類義語でクエリを拡張したい場合は、アナライザー内で処理するのではなくクエリの構築時に重み付きのOR条件で記述する方が制御が容易になると思われます。ZOZOTOWNでもシノニム辞書で扱っている語句を整理して、一部はクエリ構築時に展開処理を施す方針を検討しています。
まとめ
本記事では、Elasticsearchのアナライザー設定について解説しました。また、ユーザ辞書の登録方針やシノニム拡張のリスクについて具体例を交えて説明しました。
ZOZOでは今後も引き続き、有益な検索結果を提供できるよう検索機能の改善に努めていきます。
おわりに
ZOZOでは、一緒にサービスを作り上げてくれる方を募集中です。ご興味のある方は、以下のリンクからぜひご応募ください。