はじめに
こんにちは! タイミーでPlatform Engineerをしている @MoneyForest です。
今回は、弊社のDatadogにおけるAWSメトリクス収集を、従来のCloudWatch GetMetric APIからCloudWatch Metric Streams方式に移行することで高速化した取り組みについて紹介します。
背景
タイミーのワーカー様向けアプリケーションは、ピーク時に1分あたり十数万リクエストを処理するような規模で運用されています。そのため、システムの異常を素早く検知し、対応することが求められます。
主にシステムの異常検知は、メトリクス、ログ、APMをソースとしてエラーレートやレイテンシーの異常を判断し、DatadogのモニタリングアラートでSlackに通知することにより行われます。
DatadogによるAWSメトリクス収集の仕組み
Datadogでは、AWSのメトリクスを収集する方式として2つの方法があります。
- CloudWatch GetMetric API方式
- CloudWatchのAPIを定期的にポーリングしてメトリクスを収集
- メトリクスの遅延が15-20分程度発生する可能性がある
- CloudWatch側の遅延(5-10分)
- Datadogのポーリング間隔(10分)
- APIレート制限による追加遅延(最大5分)
- CloudWatch Metric Streams方式
- ストリーミングしたメトリクスをAmazon Data Firehoseを介してDatadogに送信
aws.s3.bucket_size_bytesやaws.billing.estimated_chargesのような2時間以上遅れてレポートされるメトリクスは取れないので、GetMetric APIも設定する必要がある- 2-3分程度の遅延
それぞれの方式をポンチ絵で書くと以下のようになります。
GetMetric APIはまとめて取ってくるPull型、Metric Streamsは継続的に送信するPush型というイメージです。
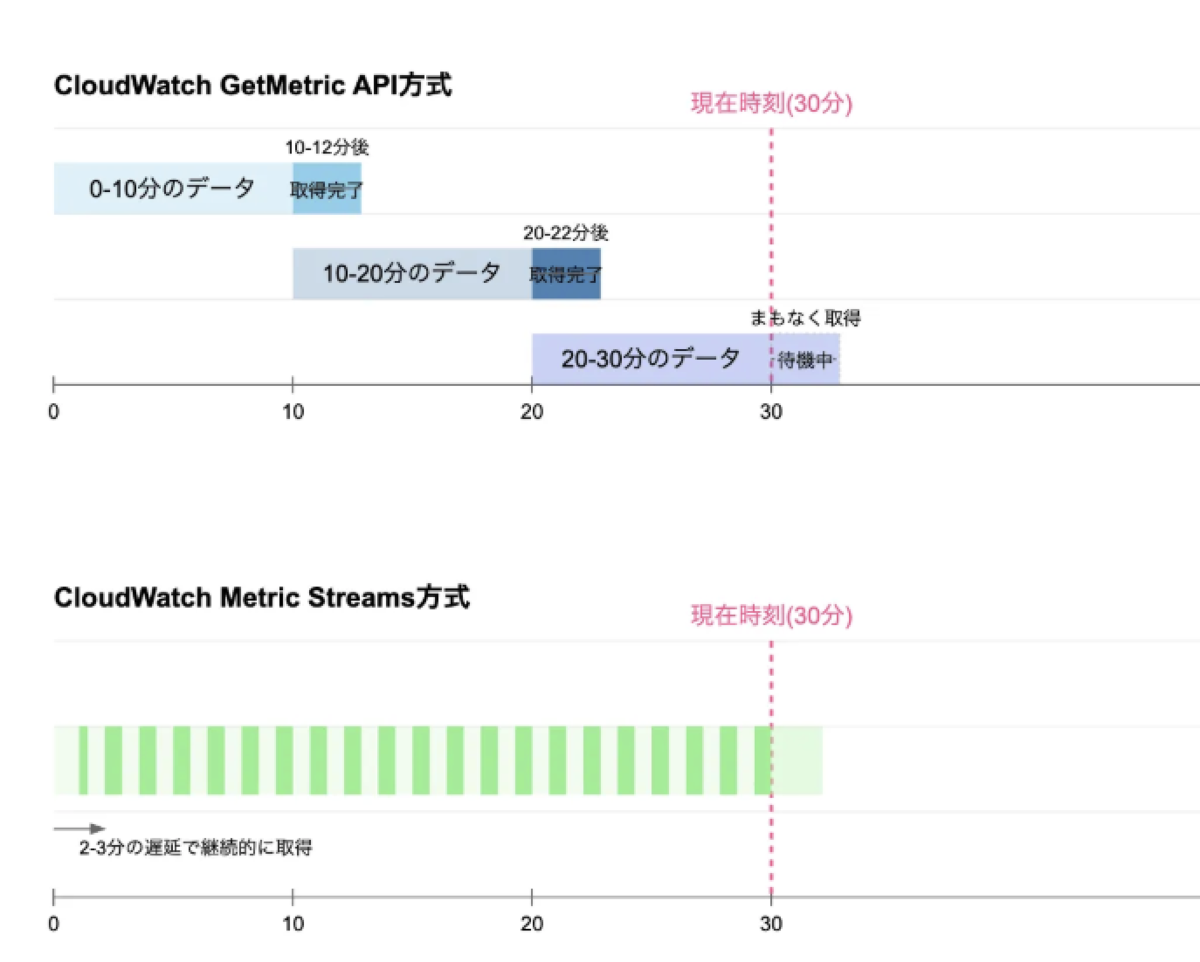
タイミーではGetMetric API方式のみでAWSメトリクスの連携を行っていましたが、最悪のケースでは20分近い遅延が発生する可能性があり、問題の検知が大幅に遅れる可能性がありました(実績ベースではALBのメトリクスなどが10-12分程度遅延している状態でした)。
タイミーのトラフィック規模では、メトリクス送信の遅延が大きすぎるとして、CloudWatch Metric Streams方式の検討を始めました。
CloudWatch Metric Streams方式への移行
検証環境を活用しながら実装、コスト、切り替えの流れを検討し、移行を進めました。
実装面の考慮
タイミーではIaCとしてTerraformを採用しています。
一方で、CloudWatch Metric Streams方式を実装する手段として、AWSのIntegration画面からCloudFormationテンプレートが提供されています。
CloudFormationテンプレートの内容を全てTerraformに書き換えるのはコストが高いため、aws_cloudformation_stack リソースでCloudFormationスタックのApplyを行うことにしました。
# Datadog CloudWatch Metics Streams の設定 # CloudFormationのテンプレートがDatadog側で提供されているため、そのまま利用する resource "aws_cloudformation_stack" "datadog" { name = "datadog" template_url = "https://datadog-cloudformation-stream-template.s3.amazonaws.com/aws/streams_main.yaml" # テンプレート内部で名前指定をしたIAM Roleを作成するのでオプション指定が必要 capabilities = ["CAPABILITY_NAMED_IAM"] parameters = { ApiKey = data.aws_ssm_parameter.datadog_api_key.value Regions = join(",", [ "us-east-1", data.aws_region.current.name ]) } lifecycle { ignore_changes = [ parameters["ApiKey"], # ApiKeyの変更を無視 ] } }
コスト面の考慮
CloudWatch Metric Streamsの料金体系は、AWSのPricingページのExample 21に以下のように書かれています。
アプリケーションが 30 日間休まず毎日 24 時間稼働し、毎分 10,000 メトリクスを更新し、CloudWatch メトリクスストリームが、米国東部の Kinesis Data Firehose 配信ストリームを経由してパートナーの HTTP エンドポイントにデータを送信する場合、月額料金は次のようになります。 CloudWatch Metric Streams メトリクス更新の合計数 = 10,000 メトリクス更新/分 x 43,200 分/月 = 432,000,000 メトリクス更新/月 432,000,000 メトリクス更新 (1,000 メトリクス更新あたり 0.003 USD) = 1,296 USD/月 CloudWatch の月額料金 =1,296 USD/月
許容できないほど高くなることはなさそうなため、検証環境に数日反映して実績ベースで確認することにしました。
結果として、日次で$20ほどかかっていたCW:GMD-Metrics がなくなり、代わりに$50ほどCW:MetricStreamUsage にかかるようになりました。
タイミーでは本番環境より検証環境の方がAWSリソースが多いため、このコスト増を最大値と見込み、許容範囲と判断しました。

切り替え時の考慮
切り替えに関しては、CloudWatch Metric Streamsを有効化することによるメトリクスの変化を検証環境で確認しました。
結果として以下2点の問題が明らかになり、それぞれ対応を行いました。
- CloudFormationスタックの適応中(8分程度)はダッシュボードで一部のメトリクスが重複して計上されてしまっている
- Datadogのドキュメントには以下の記載があり、特別なケアは必要ないものの、キレイに切り替わるわけではなさそうなことがわかりました。
- API ポーリングメソッドを通じて特定の CloudWatch ネームスペースのメトリクスを既に受け取っている場合、Datadog は自動的にこれを検出し、ストリーミングを開始するとそのネームスペースのメトリクスポーリングを停止します。
- こちらは反映が完了すると元通りになるため、許容範囲と判断し、念のため開発者へリリースタイミングを周知するにとどまりました。
- Datadogのドキュメントには以下の記載があり、特別なケアは必要ないものの、キレイに切り替わるわけではなさそうなことがわかりました。
aws.applicationelb.httpcode_elb_5xxなど一部のメトリクスにおいて、CloudWatch Metricsのデータポイントがなかった場合はNO DATAになる- GetMetric APIの場合は、CloudWatch Metricsにデータポイントがなかった場合、Datadog側には0のデータポイントが入りましたが、CloudWatch Metric Streamsの場合は、0のデータポイントが入らないという仕様差異がありました。
- こちらはモニタリングアラートがRecoverしなくなるなど明確な問題があったため、事前に該当するモニタリングアラートに
default_zeroをつけて回る修正を行いました。
まとめ
CloudWatch Metric Streams方式への移行により、メトリクスの収集が高速化され、MTTDを約10分ほど短縮できました(まだリリースしたばかりなので、本当のところはMTTDが短縮される見込み、です)。
これからも高トラフィックなアプリケーションで信頼性を担保するための地道な改善を続けていきたいと思います!またね〜