
本シリーズのトップページはこちら!!
はじめに
さて、前回まででチャットボットのインフラ部分の構築が終了しました!いよいよ今回からアプリケーション編に突入していきます!こちらの記事で言及していますが、本アプリケーションは、ニュース定期通知機能、ユーザーリクエストによるニュース通知機能の2つがあります。本記事では、これらの機能をPythonやDockerで実装する方法について、解説していきます。
ニュース定期通知機能
では、ニュース定期通知機能から始めていきましょう。
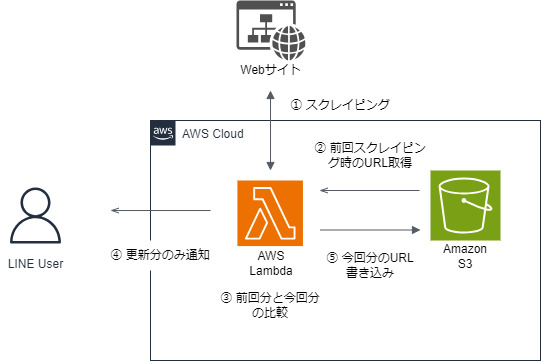
- Webサイトからニュース記事を取得する(スクレイピング)
- S3バケットから前回スクレイピング時に取得したURLを取得
- 2で取得したURLと今回スクレイピング時に取得したURLとの比較を行い、更新分だけ取り出す
- 更新分URLのみ、LINEに通知する。
- 今回のスクレイピングで取得したURLをS3に書き込む
Webサイトからニュース記事を取得
今回は、スクレイピングを活用してWebサイトからニュースURLを取得します。スクレイピングとは、Webサイトからデータを自動的に取得する技術です。この技術を使うことで、ニュースサイトから最新情報を一括して自動的に素早く収集することができます。(スクレイピングが禁止されているサイトもあるため、利用規約等をよく確認しましょう。)
Pythonにも、beautifulsoup4という便利なHTML解析ライブラリがあり、これを使って簡単にスクレイピングが可能です。では、該当のソースコードを見ていきましょう。
- url = 'https://www.soccer-king.jp/news/world' ## スクレイピング対象のサイト
- html = urllib.request.urlopen(url)
- soup = BeautifulSoup(html, "html.parser")
- ###################### 関数の定義 ###############################################################
- def news_scraping(soup=soup):
- # 記事のタイトルとurlを取得
- title_list = []
- titles = soup.select('article a[href*="https://www.soccer-king.jp/news/world/"] .tit')
- for title in titles:
- title_list.append(title.text)
- url_list = []
- urls = soup.select('article a[href*="https://www.soccer-king.jp/news/world/"]')
- for url in urls:
- url_list.append(url.get('href'))
- return title_list,url_list
- # ~~~~~~~~~~~~~~~~~~~~~~省略~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
- ##スクレイピング実行
- title,url = news_scraping()
- csv_list = url
- title_list = title
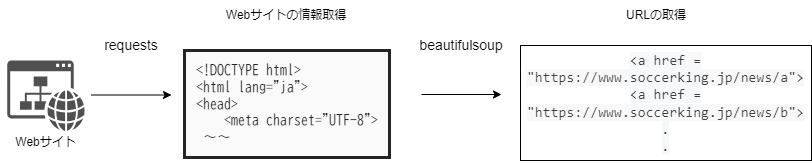
requestsライブラリでWebサイトのURLを指定し、情報を取得します。その次に、
beautifulsoup4ライブラリを用いて
articleタグ内にある<a href = "https://www.soccer-king.jp/news/world/任意の文字列">に一致するURLとタイトル一覧を抽出しています。
S3バケットから前回スクレイピング時に取得したURLを取得
該当のソースコードはこちらです。
- def get_s3file(bucket_name, key):
- # S3からcsvを読み取る
- s3 = boto3.resource('s3')
- s3obj = s3.Object(bucket_name, key).get()
- return io.TextIOWrapper(io.BytesIO(s3obj['Body'].read()))
- #前回スクレイピング分のurlをex_csvに入れる
- ex_csv =[]
- for rec in csv.reader(get_s3file("バケット名", "ファイル名")):
- ex_csv.append(rec)
- ex_csv = ex_csv[1:]
- ex_csv = list(itertools.chain.from_iterable(ex_csv))
まず、S3バケットにアクセスするためにAWSリソースを操作するライブラリであるboto3を使用します。
バケット内のファイルには前回スクレイピング時に取得したURL一覧が記載されているので、それを読み取り、
ex_csvリストに格納しています。
前回分と今回分のURL比較
今回のスクレイピングで取得したURL(csv_listに格納)をex_csv内のURLと比較します。該当のソースコードはこちらです。
- # 更新分のニュースurl、titleを格納するリストを作成
- new_url=[]
- new_title=[]
- #ex_csvと比較して更新分を取り出していく
- for i in range(10):
- if csv_list[i] in ex_csv[0]:
- num = i
- #ex_csvの先頭にある記事がcsv_listの何番目の記事に当たるか調べる
- break
- else:
- num = 'all'
- if num == 'all':
- new_title.append(title[0:10])
- new_url.append(url[0:10])
- else:
- new_title.append(title[:num])
- new_url.append(url[:num])
更新されたURLとタイトルをnew_url、new_titleというリストに格納しています。
更新分URLとタイトルをLINEに通知する。
- ## LINEへの通知
- access_token = "**************" # LINE Develpersで発行したチャネルアクセストークン
- line_bot_api = LineBotApi(access_token)
- # カルーセルテンプレートの作成
- if num == 0:
- columns_list = "新しいニュースはありません"
- line_bot_api.broadcast(TextSendMessage(text=columns_list))
- else:
- columns_list = []
- for i in range(len(new_title[0])):
- columns_list.append(
- CarouselColumn(title=new_title[0][i][0:10], text=new_title[0][i][0:60],
- actions=[{"type": "uri", "label": "サイトURL", "uri": new_url[0][i]},]
- )
- )
- carousel_template_message = TemplateSendMessage(
- alt_text = "最新ニュースを通知しました",
- template = CarouselTemplate(columns = columns_list))
- line_bot_api.broadcast(messages = carousel_template_message)
LINEへのメッセージ送信には、linebotライブラリを使用します。LINE Developersで発行されたアクセストークンをaccess_tokenに設定し、broadcastメソッドを使って条件に応じたメッセージをLINEに送信します。また、カルーセル形式のメッセージを作成するために、CarouselColumnコンストラクタを利用してカルーセルメッセージのリストを作成しています。

上手く実装できていれば、定期的にニュースが通知されるはずです。
ユーザーリクエストによるニュース通知機能
次に、ユーザーリクエストによるニュース通知機能をPythonのFlaskフレームワークで実装し、Dockerを用いてコンテナ化していきます。
Flaskとは?
Pythonで簡単なWebアプリを開発することができるフレームワークのことです。
- app=Flask(__name__)
- @app.route("/")
- def hello():
- return "hello ryota"
- # endpoint from linebot
- @app.route("/callback", methods=['POST'])
- ################################
- ### LINEへのメッセージ送信処理を記述 ###
- ################################
- if __name__=="__main__":
- app.run(host='0.0.0.0',port=3000,debug=True)
Flaskはリクエストパスごとに処理を記述していきます。上記では、https://{ALBに紐づけたドメイン名}/のリクエストはhello ryota、https://{ALBに紐づけたドメイン名}/callbackのリクエストが来ると、LINEへの返信処理が実行されます。
ここで、インフラ編の話を思い出してください。LINE通信で使用されるWebhockでは、通信先のURLを指定する必要がありました。この通知先URLこそが、https://{ALBに紐づけたドメイン名}/callbackなのです!
このURLをLINE DevelopersのWebhockURLに指定してあげることで、ようやくLINEとアプリケーション間の通信が可能となります。
実装
では、さっそく実装していきましょう!!と言いたいところですが、紙面の都合上、すべてのソースコードを説明するのは難しいため、詳細のソースコードは以下のGitHubリポジトリに格納しています。興味のある方はご覧ください。
なお、ファイル構成は以下の通りです。
- # ファイル構成
- │- app.py #コンテナで実行するアプリケーション
- │- buildspec.yml #ビルドの計画書
- │- Dockerfile # コンテナ定義ファイル
- │- requirements.txt # ライブラリインポートファイル
- └─src
- └─dict
- └─mydict.json
- └─service
- └─ handle_message_service.py # LINEメッセージ生成モジュール
- └─ scraping.py # スクレイピング、S3の読み取り、書き込み
複数のファイルがありますが、処理の流れやソースコードの内容は定期通知ニュース機能とほぼ同じです。異なるのは、ユーザーの送信メッセージによってスクレイピングするサイトURL、読み取り/書き込みするファイルが異なる点で、こちらはmydict.jsonとhandle_message_service.py で実現しています。
- ## mydict.json (一部抜粋)
- {
- "日本代表": {
- "url":"https://www.soccer-king.jp/league/national-japan",
- "href":"https://www.soccer-king.jp/news/japan/national/",
- "s3-filename":"japan.csv"
- },
- "イングランド": {
- "url":"https://www.soccer-king.jp/league/premier",
- "href":"https://www.soccer-king.jp/news/world/eng/",
- "s3-filename":"premiar.csv"
- },........
- }
- # handle_message_service.py (一部抜粋)
- class handle_message_service :
- def generate_reply_message(receivedMessage) :
- json_file = open('/app/src/dict/mydict.json', 'r') #mydict.jsonを開く
- mydict = json.load(json_file)
- send_line_flag = "No"
- for key in mydict :
- if (receivedMessage == key) : #受け取ったメッセージがjsonファイル内のキーと等しいか
- # ファイル名、url、hrefを取得する
- filename = mydict[key]["s3-filename"]
- url = mydict[key]["url"]
- href = mydict[key]["href"]
- #
- ex_csv =[]
- for rec in csv.reader(scraping.get_s3file("バケット名", filename)):
- ex_csv.append(rec)
- ex_csv = ex_csv[1:]
- ex_csv = list(itertools.chain.from_iterable(ex_csv))
- #読み込んだcsvが二次元配列になっていたため一次元に変換
- # スクレイピングを実行
- title,urlname = scraping.news_scraping(url,href)
- csv_list = urlname
- title_list = title
- ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~以下省略~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
例えば、ユーザーから「日本代表」というメッセージを受け取った場合、mydict.jsonファイル内の「日本代表」に対応するurl、href、s3-filenameを取得し、それらの情報を用いてスクレイピングやS3バケット内ファイルの読み取り・書き込みを行います。
アプリケーションのコンテナ化
ソースコードを実装した後は、OSSであるDockerを使用して、Dockerイメージを作成していきます。
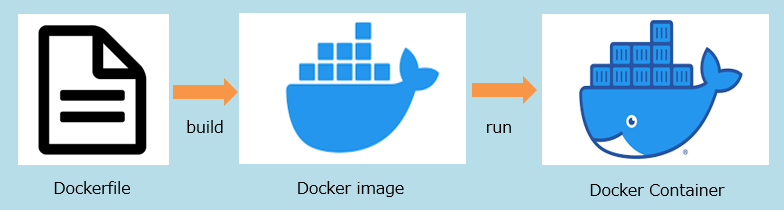
Dockerイメージとは、Dockerコンテナの動作環境となるテンプレートファイルのことです。つまり、コンテナはDockerイメージを基に起動します。
また、Dockerイメージを作成するには、Dockerfileという設計図のようなファイルを作成する必要があります。Dockerfileには、Dockerイメージの設定内容をコマンド形式で記述します。このDockerfileをビルドすることで、Dockerイメージが生成されます。(ややこしい、、、、)
Docker環境構築~RPMビルド【ハンズオン】 - RAKUS Developers Blog | ラクス エンジニアブログ
Dockerfileの作成
今回作成したDockerfileは以下の通りです。
- # ベースイメージの選択
- FROM python
- #コンテナ上でディレクトリを作成する
- RUN mkdir /app
- # コンテナ上の作業ディレクトリを設定する
- WORKDIR /app
- # 必要なパッケージをインストールする
- COPY requirements.txt ./ #コンテナにコピー
- RUN pip install --no-cache-dir -r requirements.txt # インストール
- # ローカルのソースコードをコンテナにコピーする
- COPY app.py ./
- COPY ./src /app/src
- # 実行するコマンドを指定
- CMD ["python", "./app.py"]
まず、FROM句では、ベースイメージを選択します。ベースイメージとはいわばアプリケーションの実行に必要な基本的な環境をパッケージしたものです。このベースイメージを基に自分専用のDockerイメージを作成していきます。
今回はPythonアプリケーションを実行したいので、ベースイメージとしてpythonを選択します。
COPY句でローカル上のapp.pyとrequirements.txtをコンテナにコピーし、最後のCMD ["python", "./app.py"]でコンテナ上でのアプリケーションの実行を指定しています。なお、requirements.txtには、アプリケーションで使用するパッケージのリストを記載します。
- # requirements.txt
- requests
- beautifulsoup4
- line-bot-sdk
- pandas
- flask
ビルド・プッシュ
Dockerfileをビルドしてイメージを作成し、そのイメージをAmazon ECRにプッシュしていきます。これらの手順をbuildspec.ymlに記述し、AWS CodePipelineと連携させることで、ビルド、ECRへのプッシュ、ECSへのデプロイを自動化することができます。
以下に示すのは、今回のbuildspec.ymlの内容です。本節では、docker関連のコマンドについて説明します。(自動化の設定や各フェーズの詳細についてはインフラ編Part3をご覧ください)
- # buildspec.yml
- version: 0.2
- # ビルドの前準備
- env: ## AWS SSMのパラメータストアから環境変数呼び出し
- parameter-store:
- REPOSITORY_URI: REPOSITORY_URI
- ACCOUNT_ID: ACCOUNT_ID
- phases:
- pre_build:
- commands:
- - echo Logging in to Amazon ECR... # ECRへのログイン
- - aws ecr get-login-password --region ap-northeast-1 | docker login --username AWS --password-stdin $ACCOUNT_ID.dkr.ecr.ap-northeast-1.amazonaws.com
- - COMMIT_HASH=$(echo $CODEBUILD_RESOLVED_SOURCE_VERSION | cut -c 1-7) #イメージに付与するタグを作成
- - IMAGE_TAG=${COMMIT_HASH:=latest}
- build:
- commands:
- - echo Building the Docker image... #コンテナイメージの構築
- - docker build -t $REPOSITORY_URI:latest .
- - docker tag $REPOSITORY_URI:latest $REPOSITORY_URI:$IMAGE_TAG # タグ付与
- post_build:
- commands:
- - echo Pushing the Docker images... # ECRへのプッシュ
- - docker push $REPOSITORY_URI:latest
- - docker push $REPOSITORY_URI:$IMAGE_TAG
- - echo Writing image definitions file...
- - printf '[{"name":"soccer-info","imageUri":"%s"}]' $REPOSITORY_URI:$IMAGE_TAG > imagedefinitions.json
- artifacts:
- files: imagedefinitions.json
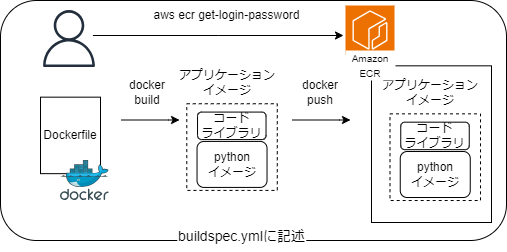
流れとしては、aws ecr get-login-password...を実行し、ECRへのログイン、
docker buildでビルド、docker pushでECRへのプッシュを実行しています。また、イメージ識別のために
docker tagでタグを付与しています。
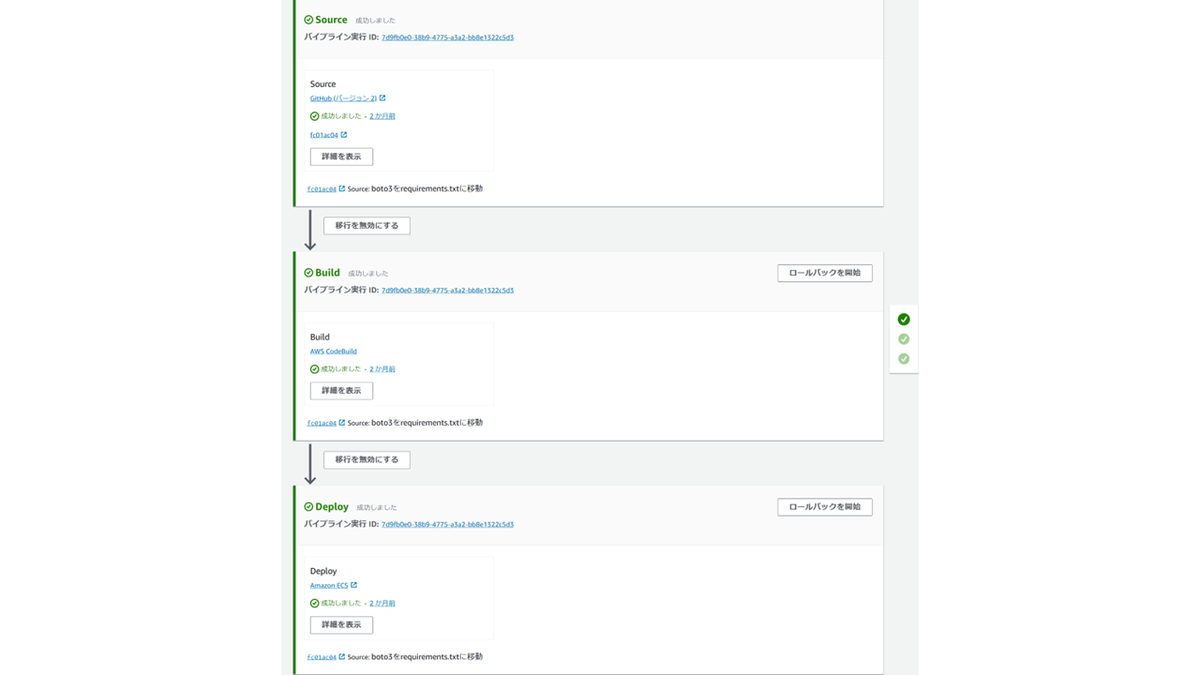
さて、これにてDockerコンテナの設定は終了です!ソースコード一式をインフラ編Part3で設定したGitリポジトリにプッシュしましょう。AWS CodePipelineで設定したパイプラインがトリガーされ、ECSへのデプロイが自動的に行われるはずです。
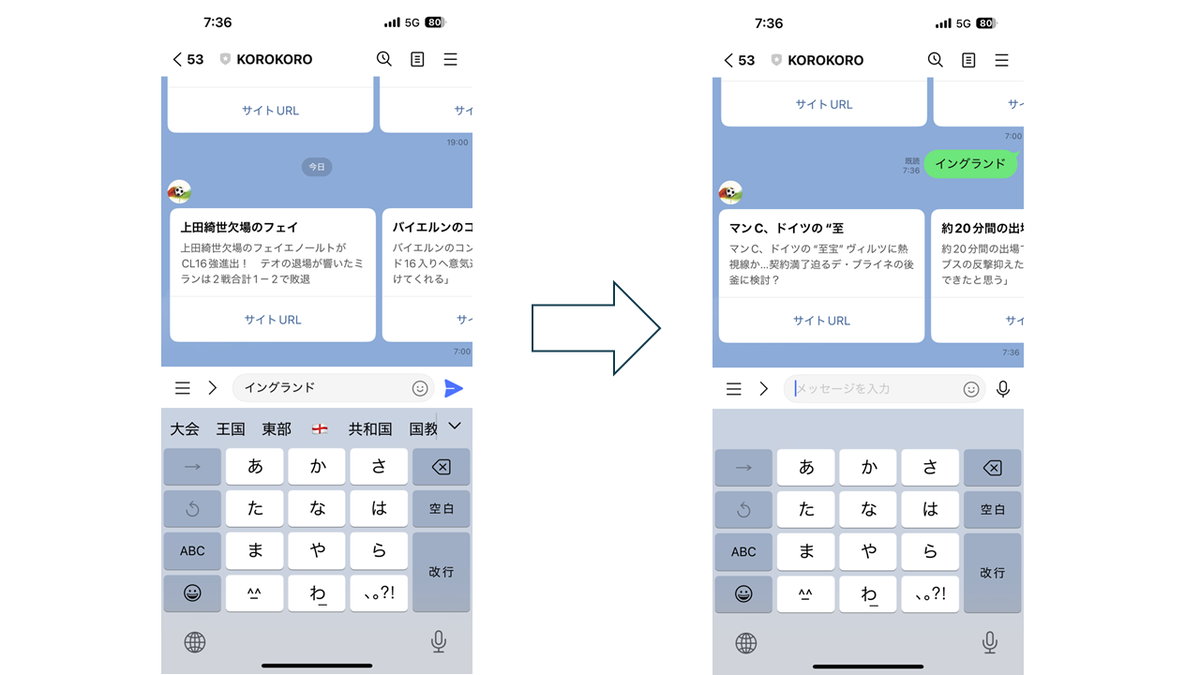
デプロイが完了したら、実際にメッセージを送ってみましょう。
以上でアプリケーションの実装は終了です!!
次回はIDEウィーク涙の最終回!!Postmanというツールを用いてLINEのリッチメニューを作成していきます!!

職種 : インフラエンジニア
推しのサッカー選手 : ケビン デブライネ