




こんにちは。生産プラットフォーム開発部の中嶋です。生産プラットフォーム開発部はアパレル生産のDXを進めている部門です。具体的には服作りのIT化を含めたアパレル生産の効率化の促進と「生産支援」のシステムを主にGoで開発しています。今回はその運用の中でGoプログラムの実行時間をどのように短縮したのかを紹介します。
目次
学べること・解決できること
- Goのメモリエラーに対するアプローチ例
- Go視点からみるメモリの基本的な知識
- チャネルの基本について
- ゴルーチンの具体的な実装例
- 時間がかかる重い処理の分析とGoを用いた最適化
背景
生産プラットフォームのバックエンドシステムは、複数のクラウドや自社・他社システムと連携をしながら製品に関する生産データを収集・デジタル化しています。例えば生産工程の進捗や検品データを収集してシステムに定期的に取り込みを行うなどです。
主にデータ連携はdigdagを利用し定期的に行っています。タスク自体はGoで開発し、各連携タスクは30分以内で終了することをシステム要件としています。

エラー発生
その連携タスクの1つが30分で完了しなくなり、タイムアウト時間を60分、さらに120分まで延長して問題を先送りしていました。それがある日を境に以下のようなエラーが発生しはじめます。いわゆるOOM(out of memory)です。
docker: Error response from daemon: failed to create shim: OCI runtime create failed: container_linux.go:380: starting container process caused: process_linux.go:545: container init caused: Running hook #0:: error running hook: exit status 2, stdout: , stderr: fatal error: out of memory allocating heap arena map
調査・対応
まずはSREチームとインフラ面での調査・対応を試みました。
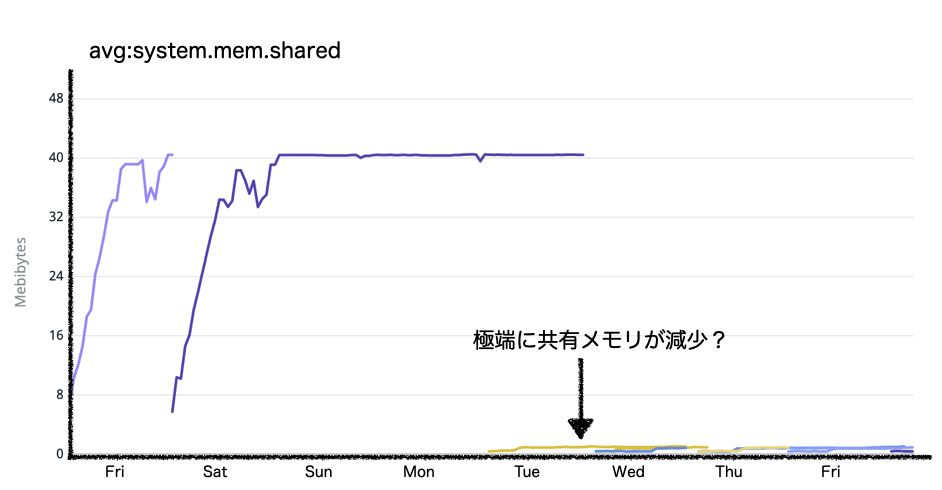
エラーの発生するタイミングのプロセス数が一気に上がっており、その影響で処理が追いつかなくなっているようでした。エラーが発生した当日に運用作業で新たにデータ登録作業がありました。そのデータは該当タスクの対象母数となるものです。

エラーの一因としてUbuntu18で起動時のメモリ消費量が増加している影響がありそうでした。Increase in memory consumption after updating Ubuntu to 18.04LTS
インスタンスの変更
リソース不足が原因であると仮説を立て、冗長化と世代を上げる対応でスケールアップを試みました。
処理自体が動くようdigdagエージェントのインスタンス数のスケールアップを行いました。問題発生前まではインスタンスが1だったのを最大4まで増加させました。一時的にエラーは止まりますが、複数タスクが起動する時間帯によっては同じエラーが発生していました。
今回問題が発生したインスタンスタイプはt2.mediumです。入れ替えたインスタンスはt3.medium、そしてm5.largeとスケールアップを試みました。下図にあるようにt2.mediumとt3.mediumはOSのメモリサイズは同値のため効果はありませんでした。
| タイプ | メモリ | ネットワーク帯域幅 | 考察 |
|---|---|---|---|
| t2.medium | 4GB | 低~中 | このインスタンスで問題発生 |
| t3.medium | 4GB | 最大5 | このスケールアップでは効果なし |
| m5.large | 8GB | 最大10 | ここで安定したが処理時間は1時間以上かかる |

m5.largeへインスタンスタイプを変えて以降は確かにタスク終了までの所要時間は120分以内で収まるようになりましたが、システム要件の30分以内で処理が終了することは達成できていません。大幅に増加したOSメモリをタスク処理が効率良く使いこなしているようには思えませんでした。
原因
最初のきっかけはdigdagのOSイメージが古くなったことと、タスク負荷が増加した影響でDockerが起動しなくなりました。それを解消するためにOSをアップデートしました。その直後にDockerの以下のエラーが頻発します。いずれにしてもメモリ不足が原因であることは間違いなさそうでした。
docker: Error response from daemon: failed to create shim: OCI runtime create failed
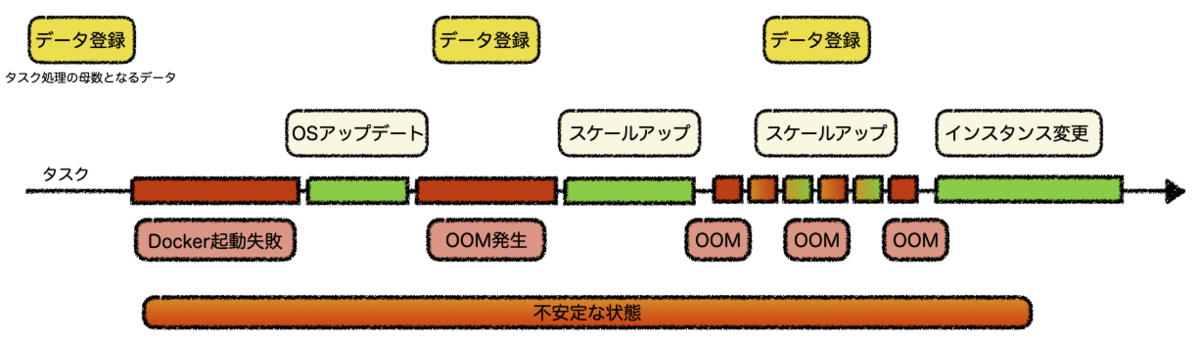
タスク処理の母数が増える度にスケールアップするというのは非現実的です。インフラ面ではこれ以上できることがないように思えました。ということでソフト面(実装・プログラム)の見直しが必要になりました。
実装アプローチの見直し
問題が発生したdigdagタスクはGoのゴルーチン(goroutine)で実装しています。
ゴルーチンとはGoのランタイムによって管理される軽量な並行処理スレッドです。通常のコルーチン(co-routine)とは、異なり開発者が処理の操作・制御はできません。その代わりスレッドやメモリアクセスの管理など複雑な作業はGoランタイムが管理します。 *ゴルーチンについては書籍など多く出版されているのでこちらの書籍などを参考にしてください。
ゴルーチンを使ったタイムアウト処理
実装ではゴルーチンとチャネル(channel)を使用しています。その目的としては並行処理というよりタイムアウトを実現するためです。下図に概要を示しました。チャネルは一度アクティブにすると受信が来るまで待ち続けるものです。その特性を利用してタイムアウトを実現しています。

サンプルコード
下記の実装は問題が発生したプログラムとほぼ同じサンプルです。時間内に結果が返ってこなかったらタイムアウト処理に入りプログラムが終了します。並行実行はせず、1つのスレッドで処理を完結させる実装です。
package main import ( "fmt" "time" ) func main() { // タイムアウトを5秒に設定 ctx := context.Background() // WithTimeoutメソッドを使ってタイムアウトコンテクストを作ります。 ctx, cancel := context.WithTimeout(ctx, 5 * time.Second) defer cancel() // string型のデータを受信するチャネル作成 c := make(chan string) go func() { // 時間がかかる処理をここに記述(サンプルなので3秒処理のダミー) // timeoutの再現は5秒以上にするとタイムアウトにはいります。サンプルは3秒で終わる処理なのでタイムアウトにはなりません。 longTask(3) // 処理終了後にチャネルに文字列を送信 c <- "タスク正常終了!" }() select { case res := <-c: fmt.Println(res) case <-ctx.Done(): fmt.Println("タイムアウトしました") os.Exit(1) } } func longTask(costTimeSecond int) { time.Sleep(time.Duration(costTimeSecond) * time.Second) }
チャネルのクローズについて
ログのout of memory allocating heap arena mapを見て「メモリリークではないか、リークするとしたらチャネルのクローズ漏れがあるかも」と思いました。実際に上の実装ではチャネルのクローズ処理は記述されていません。
それについて調べてみると以下のようなドキュメントを見つけました。
- Goチャネルを使用する一般的な原則の1つは、 受信側からチャネルを閉じないこと、およびチャネルに複数の同時送信者がある場合はチャネルを閉じないことです。
- チャネルはファイルとは異なります。通常、それらを閉じる必要はありません。ループを終了するなど、受信者にこれ以上値が来ないことを通知する必要がある場合にのみ、閉じる必要があります。
参考:A Tour Of Go - Range and Close
クローズを必要とするケースは複数のゴルーチン(goroutine)を利用しているケースなどです。チャネルの送受信が終了したことを別のゴルーチンに示すため、チャネルのクローズを呼び出します。 実装ではゴルーチン1つなのでクローズ処理は不要です。念の為チャネルのクローズ処理を追加しましたが改善は見られませんでした。
ではどこに問題があるのでしょうか。ログのallocating heap arena mapというメッセージは明らかにメモリ割り当てができていないと示しています。そこでGoのメモリについて少し深堀りしてみました。
Goのメモリマネジメントについて
Goの実装でメモリ管理をコーディングでは通常意識する必要はありません。なぜならGoのランタイムにそれを任せて実装者はコーディングだけに集中できるからです。しかしメモリについて基本的なポイントは押さえておくことが今回は原因の特定に役立つと考えました。
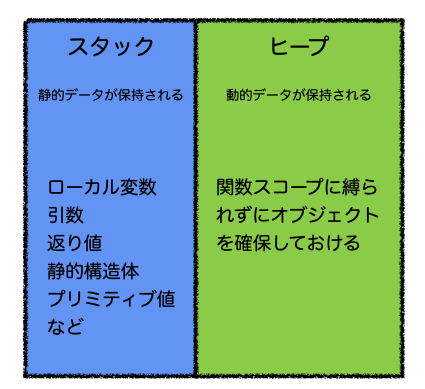
スタックとヒープ
Goはスクリプト実行時にメモリを確保する領域としてスタックとヒープの2つがあります。
参考:How do I know whether a variable is allocated on the heap or the stack?
- スタック:ローカル変数、引数、返り値を含む全ての静的変数は、型に限らず直接スタックへ保持される。
- ヒープ:全ての動的型データはヒープ上に作成される。プロセスが完了すると、ヒープ上にあるオブジェクトはスタックから参照されるポインタがなくなり、参照されないオブジェクトになる。
ゴルーチンとメモリについて
ゴルーチンにはメモリ領域として1つのスタックが存在します。2KBの最小スタックサイズから始まり、不足するリスクなしに、必要に応じて拡大・縮小します。スタックはOSによって自動的に管理されています。 一方、ヒープはOSによって管理されていません。ヒープは動的なデータを保持しているため大きなメモリ空間です。そのためメモリ領域は指数関数的に成長する可能性がありメモリ不足に陥る可能性が高い箇所です。また、時間の経過とともに断片化され、アプリケーションの動作が遅くなることもあります。 ヒープはガベージコレクションによって管理されます。参照されていないオブジェクトが使用していたメモリアドレスを解放して、新しいオブジェクトを作成するためのメモリスペースを確保します。

ヒープについて
ログに出力されている アリーナ(arena)とは、メモリ領域とメモリ領域の管理をひとつのまとまりとした単位です(下図)。
ユーザからのメモリ確保要求に対してどこが使用可能なのかを管理しています。動的なデータの要求が大きくなるプログラムは、当然必要な領域を確保するためにこのアリーナへの確保要求ボリュームは大きくなることがわかります。

問題の仮説
今回問題が2つありました。
- 処理時間が非常に長くなる
- OOMの発生で処理が進まない、落ちる
発生したOOM(out of memory)は、プログラムで必要となる動的データを格納するヒープ部分で割り当てできないことが原因であることはログからわかります。具体的にはプログラム中で使用しているSDK仕様と実装方法(使用方法)がマッチしていなかったことが原因だと思いました。なぜならループする母数が少ない場合はなんの問題も出ないのですが、ループする母数が増えることでメモリ確保量が指数関数的に増加します。 では指数関数的に増加するメモリ要求に対してどのように対応すればよいのかが次の課題になりました。
メモリを調査してみて1つの仮説にたどり着きました。
- 1つのタスクが必要とするメモリ量はその中で行われる処理の必要メモリ量の総量
- 各処理が必要とするメモリ領域は親であるタスク中でヒープにとどまり続けてしまっている
- 1ゴルーチンに対するスタックは1つであるため、ヒープとのやり取り増加でGC効率が低下する
- 結果GC効率が悪くメモリ解放されにくくなりメモリ空間を逼迫させる
- メモリ確保の要求量が増加することで同時に処理時間が長くなっている
どのように解決したか
改修量を極力少なくしたかったので、既存コード部分を生かしながら実装し直しました。 時間のかかるタスク(多くのメモリが必要な重い処理)を複数サブタスクに分けました。それらを並行実行させることにより処理単位で必要となる確保メモリ量を小さくかつ時間短縮を同時に実現できると考えました。

それを実現するのに改めてGoのゴルーチン(goroutine)が利用できると考えました。軽量な並行処理スレッドであることと、メモリアクセスの管理など複雑な作業はGoランタイムが管理してくれるからです。必要とする総メモリ量は変わらないですが、ヒープ領域のGC効率は格段に向上すると考えました。1処理を分割することで、全体の処理回転率が上がるイメージです。
実装イメージ
下図のようにゴルーチンから更に枝分かれしたゴルーチンが重い処理を手分けするイメージです。

利用したパッケージ
パッケージは golang.org/x/sync/errgroup と golang.org/x/sync/semaphore を使いました。
errgroupはGoメソッドでサブタスク(ゴルーチン)を簡易に実行できます。またサブタスクの1つでエラー発生する場合、1つのタスク処理としてキャンセルできます。今回は1タスクを複数に分割したので、サブタスクでのエラーはタスク全体のエラーとして処理したいため都合がよかったです。
semaphoreはゴルーチンの同時実行数を制御するために利用しました。並行処理を制限なしに実行してパフォーマンスが下がることを防ぐためです。
サンプルコード
実際の処理は以下のようなコードで実現しています。 今まで時間のかかっていた処理を1つのメソッドとしてまとめて、サブタスク毎にゴルーチンとして並行実行するように修正しました。 *サンプルはエラーハンドリング等、一部内容を省略しています。
package main import ( "context" "fmt" "golang.org/x/sync/errgroup" "golang.org/x/sync/semaphore" ) type person struct { name string order, age int } var persons = []person{ {name: "A", order: 1, age: 24}, {name: "B", order: 2, age: 29}, {name: "C", order: 3, age: 20}, {name: "D", order: 4, age: 21}, {name: "E", order: 5, age: 29}, {name: "F", order: 6, age: 25}, {name: "G", order: 7, age: 45}, {name: "H", order: 8, age: 19}, {name: "I", order: 9, age: 36}, {name: "J", order: 10, age: 29}, } // goroutine safe func execute() error { ctx := context.Background() // 並列処理を開始 eg, ctx := errgroup.WithContext(context.Background()) // 同時実行できるゴルーチンを設定する。この場合は3個まで同時に並行処理走らせます // 4個目からは実行待ちにはいる。 sem := semaphore.NewWeighted(3) for _, aPerson := range persons { // 無名関数にする意図は受け取るデータが変わらないようにするための実装です。 // そうしないと通常処理前にaPersonが入れ替わってしまいます。 func(p person) { // Goメソッドでgoroutine化します eg.Go(func() error { if err := sem.Acquire(ctx, 1); err != nil { // semaphore取得エラー return err } defer sem.Release(1) select { case <-ctx.Done(): // エラーが発生した場合は後続処理をキャンセルして終了する println("cancel") return nil default: // 通常時の処理 return longProcess(p) } }) }(aPerson) } // errgroupは全ての処理が終わるまたはエラーが返るまで 待ち合わせします if err := eg.Wait(); err != nil { fmt.Println(err) } return nil } // 今まで時間のかかっていた重い処理は変更せずメソッド化した func longProcess(p person) error { // 簡易的に出力しているのみですが、実際は重い処理です fmt.Printf("名前:%s 番号:%d 年齢:%d\n", p.name, p.order, p.age) return nil } // サンプルタスク func main() { fmt.Println("Start") execute() fmt.Println("End") }
上のサンプルを動かすとその都度出力される順番が変わります。非同期で処理されていることが体感できると思います。
Start 名前:J 番号:10 年齢:29 名前:A 番号:1 年齢:24 名前:B 番号:2 年齢:29 名前:F 番号:6 年齢:25 名前:D 番号:4 年齢:21 名前:C 番号:3 年齢:20 名前:E 番号:5 年齢:29 名前:I 番号:9 年齢:36 名前:G 番号:7 年齢:45 名前:H 番号:8 年齢:19 End
結果
タスクをサブタスクに分割し、再実装してタスクを実行した結果を下図に示します。
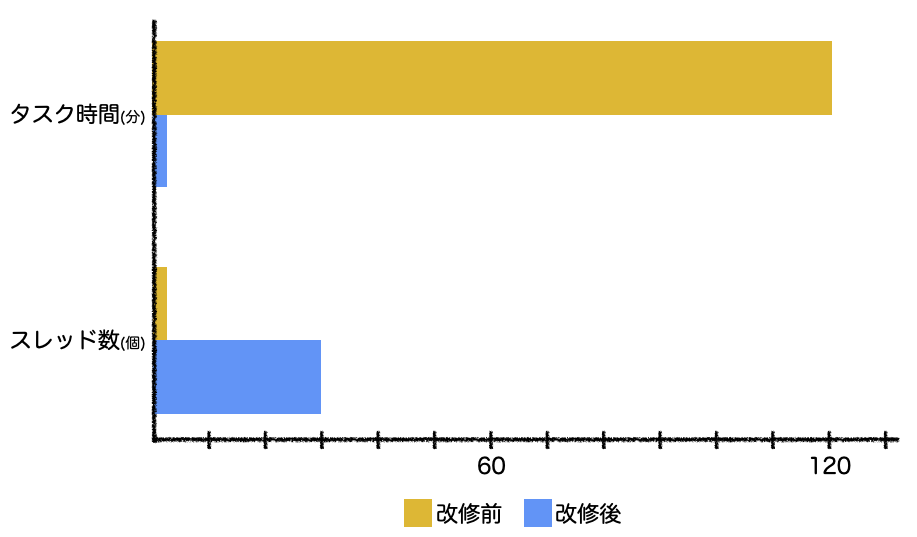
同時スレッド数を30に設定しました。2時間かかっても終わらなかった処理が2分程度まで短縮できました! Goのゴルーチンの実力を改めて実感できました。
まとめ
処理時間のかかるタスクを改修・再実装し、大幅に時間短縮できたポイントと発見を振り返ります。
- スタックには静的データ、ヒープには動的データが格納される。スタックはGoが管理するが、ヒープはOSが管理している。
- ゴルーチン毎に1つのスタックが用意されている。
- ゴルーチンの使い所の1つは重い処理を複数のサブタスク化できるような場合、ゴルーチンによってパフォーマンス改善の可能性がある。
- semaphoreは並列タスクで動作するゴルーチンの数を制限できる。
- errgroupは1つの共通タスクのサブタスク間で動作するゴルーチンの同期、エラーの伝播、コンテキスト単位のキャンセルができる。
- 処理の実行順が結果に影響を与える場合は、WaitGroupなどを利用して処理順序を管理する考慮・実装が必要。
- Goのチャネルのクローズの基本はデータ送信側が行う場合を除きクローズしなくても良い。GCが自動的にマークして破棄してくれる。
Goの実装はメモリを意識してプログラミングする必要はないが、メモリ管理の概要を理解していれば問題解決に最適な選択ができることを学びました。例えば今回のようにゴルーチンを実装することによって劇的にパフォーマンスが向上します。
最後に
今回は私達が運用しているシステムの改善の1つを紹介しました。 生産プラットフォーム開発部の今までの活動について興味のある方はこちらの記事もぜひご覧ください。
チームにはまだ様々な課題があります。その課題解決を一緒に行い、生産支援のプラットフォームを作り上げてくれる方を募集しています。 ご興味のある方は、こちらから是非ご応募ください。