

この記事は約3分で読めます。

はじめに
こんにちは。マネージドサービス部の福田です。
本ブログは以前執筆した以下ブログに関連する内容になります。
以前記載したブログはAWS Security Hubの検出結果をAmazon Bedrockで解析し、New Relicへ転送した内容でした。
今回は、New Relicへ転送時に設定したLambda関数を改善し、より効率的に実装した内容をご紹介します。
構成図
以前のブログの内容と変更はなく以下構成(Lambdaを使用した内容)になります。
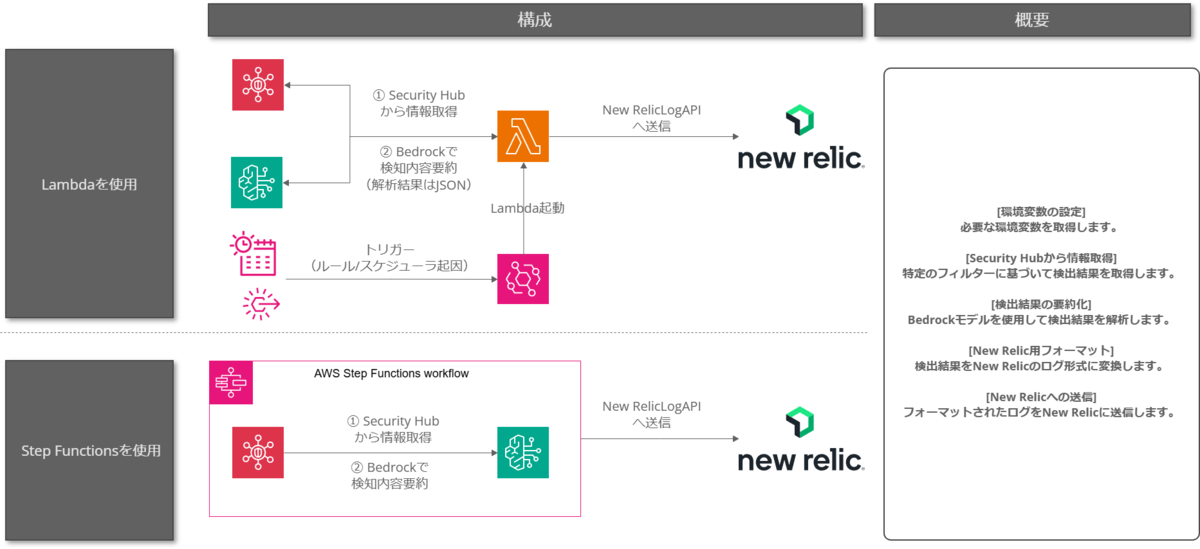
改善したLambda関数の概要
前回紹介したLambda関数ではいくつかの課題がありました。
今回は以下の点を改善しています
- (これがいちばんやりたかった)「claude-3-5-sonnet」から「claude-3-7-sonnet」に変更
- コード構造の整理と関数内容の明確化
- エラーハンドリングの実装
- バッチ処理と並列処理の導入によるパフォーマンス向上
- 環境変数によるカスタマイズ性の向上
Lambda関数の内容
あくまでも個人検証用としているので簡単な動作確認しかしておりません。from botocore.exceptions import ClientErrorimport boto3import jsonimport osimport gzipimport loggingfrom datetime import datetimeimport http.clientfrom typing import Dict, List, Any, Optional, Tuplefrom concurrent.futures import ThreadPoolExecutor# ロガーの設定logger = logging.getLogger()logger.setLevel(logging.INFO)# 環境変数の取得LICENSE_KEY = os.environ.get('NEW_RELIC_LICENSE_KEY')TARGET_REGION = os.environ.get('TARGET_REGION', 'ap-northeast-1')BEDROCK_MODEL_ID = os.environ.get('BEDROCK_MODEL_ID')BEDROCK_REGION = os.environ.get('BEDROCK_REGION')SEVERITY_FILTERS = os.environ.get('SEVERITY_FILTERS', 'CRITICAL,HIGH').split(',')BATCH_SIZE = int(os.environ.get('BATCH_SIZE', '10'))BEDROCK_TIMEOUT = int(os.environ.get('BEDROCK_TIMEOUT', '10'))# 定数LOGGING_ENDPOINTS = {'eu': 'log-api.eu.newrelic.com','default': 'log-api.newrelic.com'}PLUGIN_INFO = {"version": "1.0.0"}def validate_environment_variables() -> None:"""環境変数のバリデーション"""if not LICENSE_KEY:raise ValueError("NEW_RELIC_LICENSE_KEY 環境変数が設定されていません")if not BEDROCK_MODEL_ID or not BEDROCK_REGION:raise ValueError("BEDROCK_MODEL_ID または BEDROCK_REGION 環境変数が設定されていません")def _get_logging_endpoint() -> str:"""New Relic APIのエンドポイントを決定"""return LOGGING_ENDPOINTS['eu'] if LICENSE_KEY.startswith('eu') else LOGGING_ENDPOINTS['default']def get_security_hub_findings(client) -> List[Dict[str, Any]]:"""AWS Security Hubから情報を取得"""filters = {'ComplianceStatus': [{'Comparison': 'EQUALS', 'Value': 'FAILED'}],'RecordState': [{'Comparison': 'EQUALS', 'Value': 'ACTIVE'}],'SeverityLabel': [{'Comparison': 'EQUALS', 'Value': severity} for severity in SEVERITY_FILTERS],'ProductName': [{'Comparison': 'EQUALS', 'Value': 'Security Hub'}]}try:response = client.get_findings(Filters=filters)return response.get('Findings', [])except ClientError as e:logger.error(f"Security Hub API呼び出しエラー: {e}")raisedef create_bedrock_client() -> Any:"""Bedrock クライアントを作成"""try:return boto3.client('bedrock-runtime', region_name=BEDROCK_REGION)except Exception as e:logger.error(f"Bedrock クライアント作成エラー: {e}")raisedef interpret_finding(finding: Dict[str, Any], bedrock_client: Any) -> Dict[str, Any]:"""Bedrockを使用してSecurity Hub Findingを解釈"""system_message = "あなたはセキュリティ専門家です。Security Hub の検出結果を解釈し、重要な情報のみに要約を行い、AWSアカウント保有者が必要なアクションがあれば、記述してください。"human_message = f"""以下のSecurity Hub Findingを解釈し、重要な情報のみに要約を行い、AWSアカウント保有者が必要なアクションがあれば、記述してください。: {json.dumps(finding, indent=2)}回答は以下の形式で提供してください(必ずJSON形式で記述してください):{{"summary": "検出内容の要約","severity": "重要度(CRITICAL/HIGHなど)","impact": "影響","recommendation": "推奨される対応(AWS公式ドキュメントのリンクの記載があると望ましい)","productName": "製品名","RecommendationURL": "GuardDutyの情報の場合GuardDutyのRecommendationURLを記載してください",}}"""default_response = {"summary": "","severity": "","impact": "","recommendation": "","productName": "","RecommendationURL": ""}try:response = bedrock_client.invoke_model(modelId=BEDROCK_MODEL_ID,body=json.dumps({"anthropic_version": "bedrock-2023-05-31","max_tokens": 500,"messages": [{"role": "user", "content": f"{system_message}\n\n{human_message}"}]}))response_body = json.loads(response['body'].read())raw_text = response_body.get('content', [{}])[0].get('text', '')# JSON解析を試みるtry:json_start = raw_text.find("{")json_end = raw_text.rfind("}") + 1if json_start == -1 or json_end == -1:logger.warning("JSON部分が見つかりません")return default_responseclean_json_text = raw_text[json_start:json_end]parsed_response = json.loads(clean_json_text)# 必須フィールドの存在確認と設定for field in default_response.keys():if field not in parsed_response:parsed_response[field] = default_response[field]return parsed_responseexcept (json.JSONDecodeError, ValueError) as e:logger.warning(f"Bedrock応答のJSON解析失敗: {e}")return default_responseexcept ClientError as e:logger.error(f"Bedrock API呼び出しエラー: {e}")return {"error": f"Bedrock API呼び出しに失敗しました: {str(e)}"}except Exception as e:logger.error(f"予期せぬエラー: {e}")return {"error": f"予期せぬエラーが発生しました: {str(e)}"}def get_product_name(interpreted_finding: Dict[str, Any], finding: Dict[str, Any]) -> str:"""productName を Security Hub 関連サービスで統一する"""product_name = interpreted_finding.get('productName', finding.get('ProductName', 'N/A'))if product_name in ("Security Hub", "AWS Security Hub"):return "AWS Security Hub"elif product_name in ("GuardDuty", "Amazon GuardDuty", "AWS GuardDuty"):return "Amazon GuardDuty"return product_namedef extract_resource_info(resources: List[Dict[str, Any]]) -> Tuple[List[str], List[str], List[str]]:"""リソース情報を抽出"""resource_types = [resource.get("Type", "N/A") for resource in resources]resource_ids = [resource.get("Id", "N/A") for resource in resources]resource_arns = [resource.get("Arn", "N/A") for resource in resources]return resource_types, resource_ids, resource_arnsdef extract_standards_info(compliance_details: Dict[str, Any]) -> List[str]:"""コンプライアンス標準情報を抽出"""associated_standards = compliance_details.get('AssociatedStandards', [])return [standard.get('StandardsId', 'N/A') for standard in associated_standards]def process_finding(finding: Dict[str, Any], account_id: str, bedrock_client: Any) -> Dict[str, Any]:"""単一の検出結果を処理"""# 各項目を取得title = finding.get('Title', 'N/A')description = finding.get('Description', 'N/A')compliance_status = finding.get('Compliance', {}).get('Status', 'N/A')severity_label = finding.get('Severity', {}).get('Label', 'N/A')# リソース情報の取得resources = finding.get('Resources', [])resource_types, resource_ids, resource_arns = extract_resource_info(resources)# 最終更新日last_updated_at = finding.get('UpdatedAt', 'N/A')# コンプライアンスの関連付けられた標準compliance_details = finding.get('Compliance', {})standards_ids = extract_standards_info(compliance_details)# Bedrockによる解析結果interpreted_finding = interpret_finding(finding, bedrock_client)# 製品名を統一product_name = get_product_name(interpreted_finding, finding)# 現在のタイムスタンプcurrent_time = int(datetime.utcnow().timestamp() * 1000)# ログデータを構築return {"timestamp": current_time,"attributes": {"aws": {"accountId": account_id,"region": TARGET_REGION,"service": "SecurityHub",# 検出結果IDとリソース情報"findingId": finding.get('Id', 'N/A'),"title": title,"description": description,# コンプライアンス情報"complianceStatus": compliance_status,"associatedStandards": standards_ids,# リソース情報"resourceType": resource_types,"resourceId": resource_ids,"resourceArn": resource_arns,# 最終更新日"lastUpdatedAt": last_updated_at,# Bedrock解析結果を追加"summary": interpreted_finding.get('summary', 'N/A'),"severity": interpreted_finding.get('severity', severity_label),"impact": interpreted_finding.get('impact', 'N/A'),"recommendation": interpreted_finding.get('recommendation', 'N/A'),"productName": product_name,"RecommendationURL": interpreted_finding.get('RecommendationURL', ''),"message": finding.get('Message', 'N/A')},"bedrock": {"summary": interpreted_finding.get('summary', 'N/A'),"severity": interpreted_finding.get('severity', 'N/A'),"impact": interpreted_finding.get('impact', 'N/A'),"recommendation": interpreted_finding.get('recommendation', 'N/A'),"productName": interpreted_finding.get('productName', 'N/A'),"RecommendationURL": interpreted_finding.get('RecommendationURL', '')},# プラグイン情報"plugin": PLUGIN_INFO}}def format_findings_for_newrelic(findings: List[Dict[str, Any]], account_id: str, bedrock_client: Any) -> List[Dict[str, Any]]:"""Security Hubの情報をNew Relic用にフォーマット(バッチ処理と並列処理を導入)"""logs = []# バッチ処理for i in range(0, len(findings), BATCH_SIZE):batch = findings[i:i+BATCH_SIZE]# 並列処理with ThreadPoolExecutor() as executor:batch_results = list(executor.map(lambda finding: process_finding(finding, account_id, bedrock_client),batch))logs.extend(batch_results)return logsdef send_to_newrelic(logs: List[Dict[str, Any]]) -> bool:"""New Relic Log APIにデータを送信"""if not logs:logger.info("送信するログがありません")return Truepackaged_payload = [{"common": {"attributes": {"logtype": "security-findings","plugin": PLUGIN_INFO}},"logs": logs}]try:compressed_data = gzip.compress(json.dumps(packaged_payload).encode('utf-8'))except TypeError as e:logger.error(f"JSONシリアライズエラー: {str(e)}")raiseheaders = {'Content-Type': 'application/json','Content-Encoding': 'gzip','X-License-Key': LICENSE_KEY,'X-Event-Source': 'aws-security-hub'}try:endpoint = _get_logging_endpoint()logger.info(f"New Relicに接続中: {endpoint}")conn = http.client.HTTPSConnection(endpoint)try:conn.request('POST', '/log/v1', compressed_data, headers)response = conn.getresponse()if response.status != 202:logger.error(f"ログ送信失敗。ステータス: {response.status}")logger.error(f"レスポンス内容: {response.read().decode()}")return Falselogger.info(f"{len(logs)}件のログが正常に送信されました")return Truefinally:conn.close()except Exception as e:logger.error(f"New Relicへの送信エラー: {str(e)}")return Falsedef lambda_handler(event: Dict[str, Any], context: Any,securityhub_client: Optional[Any] = None,bedrock_client: Optional[Any] = None) -> Dict[str, Any]:"""Lambda関数のメインハンドラー"""try:# 環境変数のバリデーションvalidate_environment_variables()logger.info(f"Lambdaハンドラー開始。リージョン: {TARGET_REGION}")# クライアントの初期化(依存性注入パターン)securityhub_client = securityhub_client or boto3.client('securityhub', region_name=TARGET_REGION)bedrock_client = bedrock_client or create_bedrock_client()# アカウントIDの取得account_id = context.invoked_function_arn.split(":")[4]# Security Hubからの検出結果取得findings = get_security_hub_findings(securityhub_client)if not findings:logger.info("Security Hubのアクティブな情報はありません")return {'statusCode': 200, 'body': json.dumps({'message': 'No active findings'})}# 検出結果のフォーマットlogs = format_findings_for_newrelic(findings, account_id, bedrock_client)# New Relicへの送信if not send_to_newrelic(logs):raise Exception("New Relicへのログ送信に失敗しました")return {'statusCode': 200,'body': json.dumps({'message': f'{len(logs)}件のログ送信完了','processedFindings': len(findings)})}except Exception as e:logger.error(f"エラー発生: {e}", exc_info=True)return {'statusCode': 500, 'body': json.dumps({'message': str(e)})}
主要な改善点
1. 環境変数の活用
Lambda関数自体の修正が極力生じることがないように環境変数を設定しました。
| 環境変数名 | 必須 | デフォルト値 | 説明 |
|---|---|---|---|
| NEW_RELIC_LICENSE_KEY | ✓ | - | New Relic APIキー |
| BEDROCK_MODEL_ID | ✓ | - | 使用するBedrockモデルID |
| BEDROCK_REGION | ✓ | - | Bedrockサービスのリージョン |
| TARGET_REGION | - | ap-northeast-1 | Security Hubデータ取得リージョン |
| SEVERITY_FILTERS | - | CRITICAL,HIGH | 取得する検出結果の重要度(カンマ区切り) |
| BATCH_SIZE | - | 10 | バッチ処理サイズ |
| BEDROCK_TIMEOUT | - | 10 | Bedrock API呼び出しタイムアウト秒数 |
特にSEVERITY_FILTERSでは、取得するSecurity Hub検出結果の重要度をカンマ区切りで指定できるようになり、必要な情報のみを処理することが可能になりました。
2. バッチ処理と並列処理の導入
検出結果を効率的に処理するため、バッチ処理と並列処理を導入しました。
def format_findings_for_newrelic(findings, account_id, bedrock_client):logs = []# バッチ処理for i in range(0, len(findings), BATCH_SIZE):batch = findings[i:i+BATCH_SIZE]# 並列処理with ThreadPoolExecutor() as executor:batch_results = list(executor.map(lambda finding: process_finding(finding, account_id, bedrock_client),batch))logs.extend(batch_results)return logs
これにより、多数の検出結果がある場合でも効率的に処理できるようになりました。
3. エラーハンドリングの実装
Bedrock APIの呼び出しエラーや応答解析の失敗に対するエラーハンドリングを実装しました
def interpret_finding(finding, bedrock_client):# ...default_response = {"summary": "","severity": "","impact": "","recommendation": "","productName": "","RecommendationURL": ""}try:# Bedrock API呼び出し# ...except ClientError as e:logger.error(f"Bedrock API呼び出しエラー: {e}")return default_responseexcept Exception as e:logger.error(f"予期せぬエラー: {e}")return default_response
これにより、一部の検出結果の処理に失敗しても、全体の処理が継続されるようになりました。
4. 関数説明を追記
各処理を細かく分割し、それぞれの内容を記載しました。
def extract_resource_info(resources):"""リソース情報を抽出"""resource_types = [resource.get("Type", "N/A") for resource in resources]resource_ids = [resource.get("Id", "N/A") for resource in resources]resource_arns = [resource.get("Arn", "N/A") for resource in resources]return resource_types, resource_ids, resource_arnsdef extract_standards_info(compliance_details):"""コンプライアンス標準情報を抽出"""associated_standards = compliance_details.get('AssociatedStandards', [])return [standard.get('StandardsId', 'N/A') for standard in associated_standards]
これにより、コードの可読性と保守性が向上しました。
Amazon Bedrockのモデルを変更
今回の改善では、Amazon Bedrockのclaude-3-5-sonneからclaude-3-7-sonnetに変更しております。
claude-3-5-sonnetに比べると処理速度や要約した内容がよりわかりやすくなっておりました。
ただ、現時点(2025/03/14)でus-east-1(バージニア北部)、us-east-2(オハイオ)、us-west-2(オレゴン)リージョンでのみ利用可能のようなので
その点だけ注意が必要です。
なおBedrockの処理は以下内容になります。
- 検出内容の簡潔な要約
- セキュリティ上の影響の評価
- 具体的な対応手順の提案
- 関連するAWS公式ドキュメントへの参照
実装結果と可視化
改善したLambda関数によりNew Relicへ転送、可視化された情報は以下になります
- Security Hubの検出結果の重要度別分布
- 検出結果の種類別分布
- Bedrockによる解析結果の要約
- 推奨される対応策
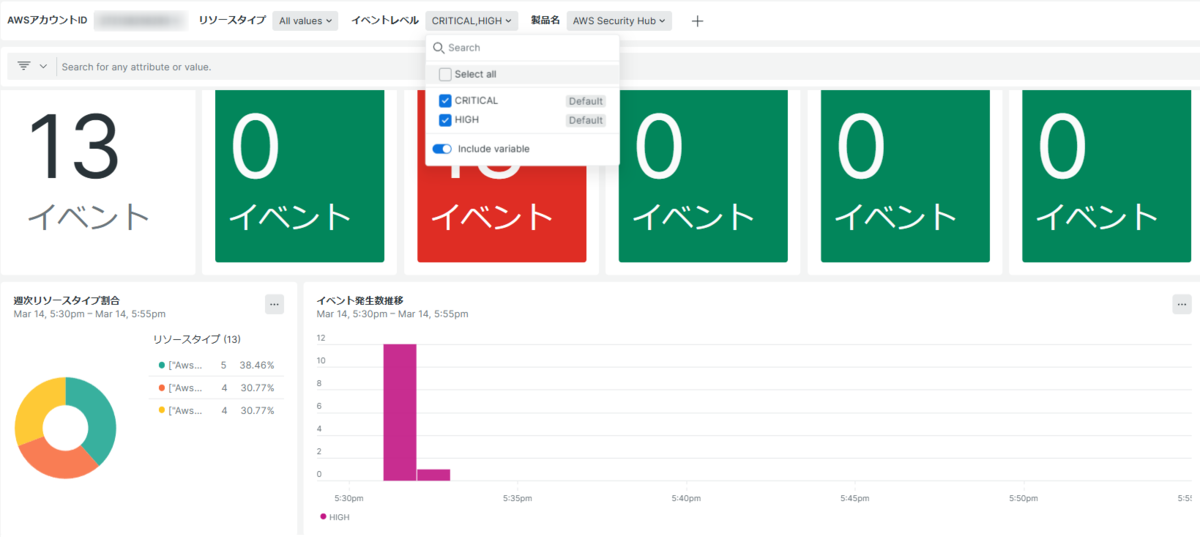
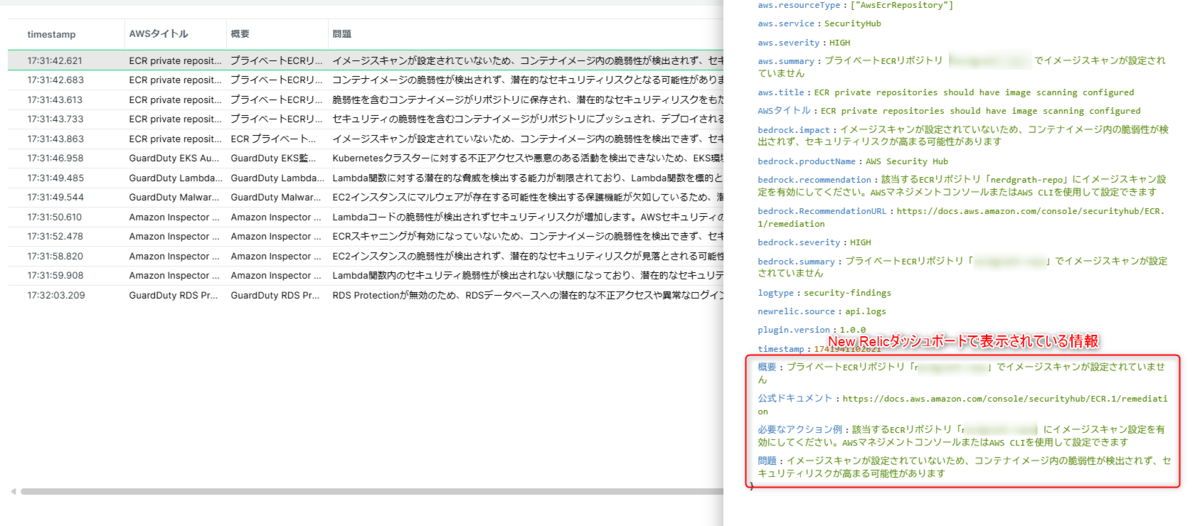
New Relicへ送られた情報
「bedrock,xxx」が「bedrock」で要約してもらった内容になります。{"aws.accountId": "xxxxxxx","aws.associatedStandards": "[\"standards/aws-foundational-security-best-practices/v/1.0.0\"]","aws.complianceStatus": "FAILED","aws.description": "This control checks whether a private ECR repository has image scanning configured. This control fails if a private ECR repository doesn’t have image scanning configured.","aws.findingId": "arn:aws:securityhub:ap-northeast-1:xxxxxxx:security-control/ECR.1/finding/xxx","aws.lastUpdatedAt": "2025-03-14T06:48:17.026Z","aws.message": "N/A","aws.productName": "AWS Security Hub","aws.RecommendationURL": "https://docs.aws.amazon.com/console/securityhub/ECR.1/remediation","aws.region": "ap-northeast-1","aws.resourceArn": "[\"N/A\"]","aws.resourceId": "[\"arn:aws:ecr:ap-northeast-1:xxxxxxx:repository/xxxxxxx-repo\"]","aws.resourceType": "[\"AwsEcrRepository\"]","aws.service": "SecurityHub","aws.severity": "HIGH","aws.title": "ECR private repositories should have image scanning configured","bedrock.impact": "イメージスキャンが設定されていないため、コンテナイメージ内の脆弱性が検出されず、セキュリティリスクが高まる可能性があります","bedrock.productName": "AWS Security Hub","bedrock.recommendation": "該当するECRリポジトリ「xxxxxxx-repo」にイメージスキャン設定を有効にしてください。AWSマネジメントコンソールまたはAWS CLIを使用して設定できます","bedrock.RecommendationURL": "https://docs.aws.amazon.com/console/securityhub/ECR.1/remediation","bedrock.severity": "HIGH","bedrock.summary": "プライベートECRリポジトリ「xxxxxxx-repo」でイメージスキャンが設定されていません","logtype": "security-findings","newrelic.source": "api.logs","plugin.version": "1.0.0","timestamp": 1741941102621}
まとめ
今回の改善により、AWS Security Hubの検出結果をAmazon Bedrockで解析し、New Relicに転送するLambda関数の効率性が増しました。
(個人的に試しているための自己満ではあります)
とはいえこのようなAIを活用した監視の効率化はシステム異常/障害に「気付く」だけでなく気付いた後に
「なぜ問題が起きているのか」「なにをすればいいのか」の判断材料として重要になってくるかと思います。
New RelicとAmazon Bedrockの連携により、セキュリティ監視問わず監視対応の効率化と迅速化をどんどん実現していきたいですね。
宣伝
弊社では、お客様環境のオブザーバビリティを加速するためのNew Relicアカウント開設を含めた伴走型のNew Relic導入支援サービスをご提供しております。 もしご興味をお持ちの方は、こちらのお問合せフォームよりお問合せ頂けましたら幸いでございます。