


G-gen の杉村です。BigQuery の外部テーブル(external tables)機能で Google スプレッドシートのデータを BigQuery からクエリする方法について紹介します。

外部テーブルとは
当記事では、BigQuery の外部テーブル(external tables)機能で Google スプレッドシートのデータを BigQuery からクエリする方法について紹介します。
BigQuery の外部テーブル(external tables)とは、BigQuery の外部にあるデータを BigQuery からクエリするために定義する、仮想的なテーブルです。データを BigQuery に複製することなく、外部にあるデータをクエリすることができます。外部テーブルは以下のデータソースに対応しています。
- Cloud Storage
- Bigtable
- Google ドライブ(Google スプレッドシート、CSV、Newline delimited JSON、Avro)
外部テーブルを定義することにより、BigQuery にデータを転送することなく、外部のデータを直接クエリすることができます。外部テーブルにクエリした結果を BigQuery 内部のデータと JOIN することもできます。ただし、外部ストレージからデータを読み取るオーバーヘッドがあるため、パフォーマンスの面では BigQuery 内部のデータをクエリするよりも劣る可能性があります。
- 参考 : 外部テーブルの概要
また、外部テーブルの拡張として BigLake テーブルがあります。BigLake テーブルでは、Cloud Storage、Amazon S3、Azure Blob Storage のデータをクエリすることができます。
- 参考 : BigLake テーブルの概要
外部テーブルや BigLake については、以下の記事も参考にしてください。
- 参考 : BigQueryを徹底解説!(応用編) - G-gen Tech Blog - 外部テーブル
- 参考 : BigQueryを徹底解説!(応用編) - G-gen Tech Blog - BigLake
スプレッドシート
サンプルシートの準備
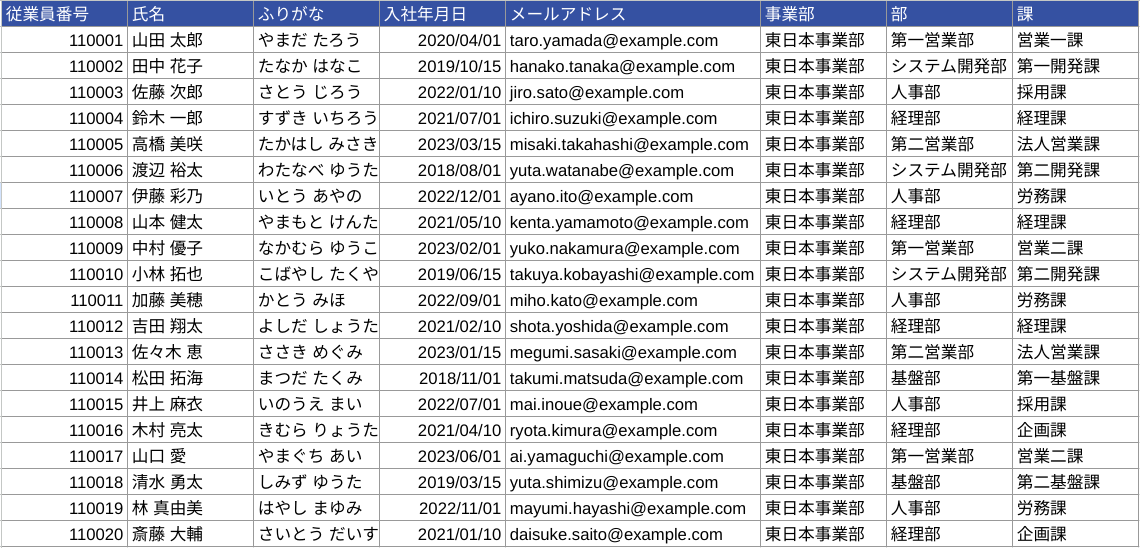
当記事では、Google スプレッドシートにある従業員名簿を BigQuery からクエリして、BigQuery 内に保存してある他のデータと JOIN するようなユースケースを想定して、手順を紹介します。
以下は、Google スプレッドシートに作成した従業員名簿です。値は生成 AI で生成した架空のものです。
共有リンクの取得
のちに外部テーブルを定義するときに必要なため、このスプレッドシートの共有リンクを取得してください。リンクは、以下のような形式になります。
https://docs.google.com/spreadsheets/d/1M-DdfRdZKLwWKxxxxx/edit?usp=sharing
なお、末尾の /edit?usp=sharing は削除しても構いません。また、スプレッドシートを開いた状態でブラウザの URL 欄から URL を取得しても構いません。このときも、末尾の /edit 以降は削除して構いません。
外部テーブルの定義
SQL(DDL)
当記事では、SQL(DDL)を用いてテーブルを定義してみます。コンソール画面からでもテーブルの定義は可能ですが、SQL を作っておけば列名の試行錯誤などを楽に行うことができます。
- 参考 : 外部テーブルを作成する
BigQuery Studio で以下の SQL を実行すると、スプレッドシートをデータソースとした外部テーブルが作成されます。プロジェクト名やデータセット名は、ご自身の環境のものに置き換えてください。
CREATE OR REPLACE EXTERNAL TABLE `my-project.my_dataset.employees`(id INT64,name STRING,name_kana STRING,join_date DATE,email_address STRING,business_unit STRING,department STRING,division STRING,)OPTIONS(uris=["https://docs.google.com/spreadsheets/d/1M-DdfRdZKLwWKxxxxx"],format="GOOGLE_SHEETS",sheet_range="従業員名簿!A:H",skip_leading_rows=1);
解説
列名は、BigQuery のスキーマ命名ルールに則ったうえで、任意の文字列とすることができます。BigQuery には「柔軟な列名」機能があり、通常のテーブルであれば列名に記号やマルチバイト文字を使うことができますが、外部テーブルではサポートされていません。外部テーブルの列名には英字(a~z、A~Z)、数字(0~9)、アンダースコア(_)だけを使用できます。
- 参考 : スキーマの指定
次に、OPTIONS の中身を解説します。
uris は、先ほど作成したスプレッドシートの URL(URI) です。末尾の /edit?usp=sharing は削除しても構いません。
format には GOOGLE_SHEETS を指定します。
sheet_range には、シート名と列範囲を指定できます。(シート名)!(開始列):(終了列) の形式で指定します。これにより、スプレッドシートファイルに複数のシート(タブ)が含まれていても、任意のシートを取り込むことができます。
skip_leading_rows には、ヘッダなどをスキップする行数を記載します。通常は、スプレッドシートの表の最初の数行まではヘッダなどが記載されており、実データは途中から格納されているはずです。実データ以外はスキップします。
シート指定の注意点
OPTIONS の sheet_range を省略すると、スプレッドシートのファイルの一番左に配置されているシートが読み取られます。日常業務でよく編集されるシートの場合、順番が入れ替わってしまう誤操作があり得ますので、シート名を明示することが望ましいといえます。
ただし、シート名が変更されてしまうと、データが読み取れなくなります。

また、スプレッドシートをブラウザで開いているときにブラウザの URL 欄に表示されるリンクは、開いているシートに応じたアンカー(#)が付与されています。ブラウザでこのアンカー付き URL を開くと任意のシートを開くことができますが、外部テーブル定義の DDL でこの URL を指定しても、任意のシートを読み取り対象とすることはできません。sheet_range オプションでシート名で明示的に指定する必要があります。
アンカー付き URL の例
https://docs.google.com/spreadsheets/d/1M-DdfRdZKLwWKxxxxx/edit?gid=925071692#gid=925071692
クエリ
作成された外部テーブルは、通常のテーブルと同じようにクエリすることができます。BigQuery の通常のテーブルとの JOIN も可能です。
なお、スプレッドシートをデータソースとする外部テーブルに対するクエリは、常にフルスキャンとなります。パーティショニングやクラスタリングは利用できません。
SELECT * FROM `sugimura.my_dataset.employees`

アクセス権限
Google アカウントによるアクセス
スプレッドシートをデータソースとする外部テーブルに対してクエリを行うには、外部テーブルとスプレッドシートの両方にアクセス権限が必要です。
クエリを行うアカウントは、Google Cloud 側で以下のロールが必要です。
- プロジェクトに対する BigQuery ユーザー(
roles/bigquery.user)または BigQuery ジョブユーザー(roles/bigquery.jobUser) - テーブルに対する BigQuery データ閲覧者(
roles/bigquery.dataViewer)
加えて、対象のスプレッドシートに対して、閲覧者権限以上が必要です。
クエリ実行アカウントが、Google Cloud 側には権限を持っているものの、スプレッドシート側(Google ドライブ側)に権限を持っていない場合は、以下のようなエラーとなります。
Access Denied: BigQuery BigQuery: Permission denied while getting Drive credentials.

プログラムからのアクセス
Cloud Run functions などで実行するプログラムからクライアントライブラリを用いて BigQuery の外部テーブルへクエリする際にも、前述のとおり、Google Cloud プロジェクト側とスプレッドシート側の両方に権限が必要です。
Cloud Run functions の関数等にアタッチしたサービスアカウントにこれらの権限を付与すれば、外部テーブルにアクセスすることができます。しかし、ソースコード内で BigQuery クライアントを生成する際に注意が必要です。
Python のクライアントライブラリから BigQuery の外部テーブルにクエリを投入する場合を例に取ります。通常、ソースコード内で BigQuery クライアントを生成する際は、以下のように記述します。
import google.cloud.bigqueryclient = google.cloud.bigquery.Client()
しかし、この記述だと、Google Cloud プロジェクト側とスプレッドシート側の両方に正しく権限を付与しているのにもかかわらず、403 Access Denied: BigQuery BigQuery: Permission denied while getting Drive credentials. というエラーメッセージが出力されます。
これは、クライアント生成時に認証情報のスコープが正しく設定されていないことに起因します。以下のように記述することで、認証情報のスコープに Google ドライブが含まれるようになり、エラーが解消します。
import google.cloud.bigquerycredentials, project = google.auth.default(scopes=["https://www.googleapis.com/auth/drive","https://www.googleapis.com/auth/cloud-platform",])client = google.cloud.bigquery.Client(credentials=credentials, project=project)
杉村 勇馬 (記事一覧)
執行役員 CTO / クラウドソリューション部 部長
元警察官という経歴を持つ現 IT エンジニア。クラウド管理・運用やネットワークに知見。AWS 12資格、Google Cloud認定資格11資格。X (旧 Twitter) では Google Cloud や AWS のアップデート情報をつぶやいています。
Follow @y_sugi_it