Amazon Web Services ブログ
AWS Entity Resolution を使用した統合患者インデックスの構築
この記事は Build a Unified Patient Index Using AWS Entity Resolution (記事公開日: 2025 年 2 月 14 日) を翻訳したものです。
医療機関や公衆衛生機関は、膨大な量の患者データを扱っています。複数の、場合によっては接続されていないデータソースにわたって機密性の高い患者情報を正確に管理し、リンクすることは、医療の連携、研究、そして公衆衛生活動にとって極めて重要です。正確な統合患者インデックスを構築することで、医療提供者は包括的な患者履歴にアクセスでき、研究者は堅牢なデータセットを構築でき、公衆衛生当局は疾病の傾向や結果について洞察を得ることができます。
しかし、データ入力の不整合は、正確な患者識別に重大な課題をもたらす可能性があります。これらの問題は、名前の綴りやフォーマットの違いだけでなく、ニックネームや敬称の使用、複数の接点における連絡先情報の不一致、住所の項目や略語の標準化の不一致にまで及びます。様々なデータ入力の不整合は、患者レコードの断片化につながり、潜在的に医療の質や患者の安全性を損なう可能性があります。これらの課題は以下のような結果をもたらす可能性があります:
- 不完全な患者レコード
- 患者ケアにおける、データに基づかない意思決定
- 公衆衛生の課題への対応の困難さ
- 効果的な研究の障壁
- 非効率な医療連携
- 医療費の増加
- 患者満足度の低下
マスター患者インデックス (MPI) の構築は、これらの課題の解決にも役立ちます。なぜなら、MPI は個人に関連するレコードに割り当てられた個人ベースの永続的な識別子を持つ、一元化されたレジストリとして機能するためです。インデックス化された患者レコードに部分的なレコードをマッチングすることで、統合され、継続的に進化する患者のビューを作成することができ、これによってダウンストリームの消費者アプリケーション間での効果的な医療連携と研究が可能になります。
HIPAA に適格な AWS サービスを使用することで、医療機関は AWS Entity Resolution で患者レコードを処理し、Amazon Connect Customer Profiles でメンバー情報を統合し、Amazon Q in Connect の機能を活用して、パーソナライズされたタイムリーな患者ケアを提供することができます。
AWS Entity Resolution を使用することで、企業や組織は、複数のアプリケーション、チャネル、データストアに存在する関連する顧客または医療記録を照合、リンク、および強化することができます。このサービスは、ルールベース、機械学習 (ML) 駆動、およびデータサービスプロバイダーによる柔軟で設定可能なマッチング技術を提供し、データの正確性を向上させ、顧客のビジネスニーズに基づいて関連レコードを強化するのに役立ちます。AWS Entity Resolution を使用すると、顧客はエンティティマッチング技術を設定でき、手動データ入力や低品質データに関連する課題を組織が克服するのに役立ちます。このサービスは、データの移動を最小限に抑えることで、医療データアーキテクチャのセキュリティ体制を改善します。Amazon Simple Storage Service (Amazon S3) や AWS Glue など、広く普及している AWS サービスを活用することで、既存の医療データアーキテクチャパターンとシームレスに統合されます。
AWS Entity Resolution を使用して患者レコードを処理した後、ヘルスケア企業は Amazon Connect の機能を活用して、プロアクティブなサービスを提供し、患者ケアのニーズを予測することができます。Amazon Connect Customer Profiles を使用することで、医療機関は必要な患者の同意を得た上で、複数のソースからメンバーや患者の情報を統合することができます。Amazon Q in Connect を Amazon Connect Customer Profiles と統合することで、ヘルスケア企業はリアルタイムで患者のニーズを検出し、タイムリーでパーソナライズされた患者ケアを提供することができます。

このブログでは、独立系ソフトウェアベンダー (ISV) 、医療提供者、および保険支払機関が、一般に公開されている人工的に生成されたデータセットを使用して、AWS Entity Resolution を活用して関連する患者レコードを特定、およびマッチングする方法をデモンストレーションします。

図 1 – ハイレベルアーキテクチャ図
患者データセット
このソリューション例では、小児肥満データイニシアチブ (CODI) プロジェクト用に作成された合成データセットを使用しています。合成患者の医療履歴をモデル化するオープンソースの合成患者生成ツールである Synthea を使用して、一部の個人について複数の分割レコードを生成しました。これらの分割レコードでは、実際のシステムで想定されるように、人口統計情報が様々な形で変化する可能性があります。例えば、あるレコードでは名前が「John」であり、別のレコードでは「Johnny」というように表記が異なる場合があります。
患者データセットの構造
この例で使用している患者データは、分析のために FHIR フォーマットから CSV に変換されています。このデータセットには約 6,300 件のレコードが含まれており、データセット全体で患者のマッチングに必要な個人識別情報 (PII) を含む列があります。
以下の表は、患者データの構造を説明しています。データには、州名 (statename) 、郵便番号 (postalcode) 、住所 (address) 、国名 (countryname) 、市区町村名 (cityname) 、生年月日 (birthdate) 、固有 ID (uniqueid) 、名 (firstname) 、ミドルネーム (middlename) 、姓 (surname) 、リソースタイプ (resourcetype) 、電話番号 (phonenumber) などのフィールドが含まれています。これらのフィールドは、同一人物を参照するレコードをリンクするエンティティ解決プロセスで一般的に使用されます。データに含まれるフィールドの規模と多様性は、潜在的なエンティティマッチング技術を実証するのに適しています。

図 2 – 合成データセットのサンプルデータ
AWS Entity Resolution ワークフローを実行するために、与えられた患者データを Amazon S3 バケットにアップロードしました。その後、AWS Glue クローラーがファイルを処理して、自動的にスキーマを判断し、AWS Glue Data Catalog のテーブルとしてメタデータを更新します。次に、AWS Entity Resolution コンソール画面に移動します。
AWS Entity Resolution コンソールで、メニューから「スキーママッピング」オプションを選択し、「スキーママッピングの作成」をクリックします。スキーママッピングは、解決に使用される元データとそれに含まれる属性について、サービスに情報を提供します。

図 3 – AWS Entity Resolution のスキーママッピング作成画面
「スキーママッピングの作成」画面で、ソースデータを表す AWS Glue データベースとテーブルを選択します。この記事では、患者データを含む「patientdata」テーブルを持つ、「demodb」という名前のデータベースを使用しました。このデータベースは、患者データを格納した Amazon S3 バケットで AWS Glue クローラーを実行した際に作成されました。

図 4 – AWS Entity Resolution のスキーママッピング設定画面
次に、ドロップダウンからユニーク ID (Unique ID) を選択します。ユニーク ID カラムは、データの各行を一意に参照するものでなければなりません – これはデータベースの主キーカラムのようなものと考えてください。この場合、CSV ファイルの「uniqueid」がそれに該当します。
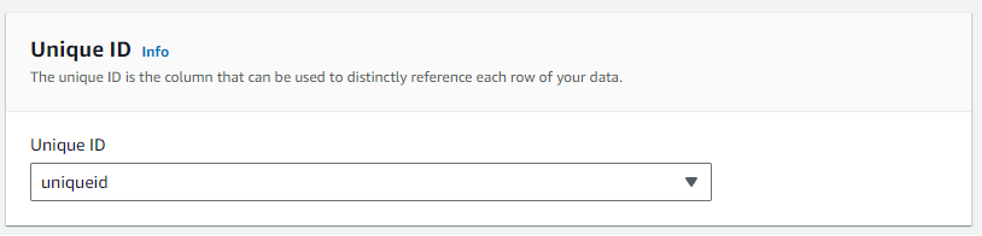
図 5 – AWS Entity Resolution スキーママッピングの作成、ユニークID選択
次に、下にスクロールして解決 (マッチング、リンク) に必要な入力フィールドを選択します (図 6 参照) 。この場合、firstname (名) 、middlename (ミドルネーム) 、surname (姓) 、statename (州名) 、countryname (国名) 、homeaddress (自宅住所) など、患者の人口統計情報を示す列が選択されています。

図 6 – AWS Entity Resolution スキーママッピング、マッチング列の選択
さらに、解決には必要ないものの、最終的な出力ファイルに必要な列は、パススルーフィールドセクションで選択できます。この例では、birthdate (生年月日) 、cityname (市区町村名) 、contactemailaddress (連絡先メールアドレス) 、contactfamilyname (連絡先姓) 、contactname (連絡先名) 、gender (性別) 、linkid (リンク ID) 、maritalstatus (婚姻状態) 、phonenumber (電話番号) 、postalcode (郵便番号) 、resourceid (リソース ID) を選択しました。これらの列はマッチングプロセスには参加しませんが、出力の一部として表示されます。

図 7 – AWS Entity Resolution スキーママッピング、パススルー列の選択
スキーママッピング作成の次のステップでは、選択した入力フィールドを適切なデータタイプとマッチキーにマッピングします。入力タイプ (名前、メール、住所など) を指定することで、AWS Entity Resolution は各列のデータをどのように解釈するか、そして必要に応じて特定の列にどの正規化ルールを適用できるかを理解します。マッチキーは、どのフィールドが類似しており、マッチングプロセス中に単一のユニットとして考慮する必要があるかを決定します。
注:個人識別情報 (PII) ではないフィールドを解決に使用する必要がある場合、それらのフィールドを「入力フィールド」として選択することができます。入力タイプとして「Custom String」を選択し、適切なマッチキー名を設定してください。Custom String のサポートは、ルールベースのマッチング技術でのみ利用可能で、機械学習ベースのマッチングでは無視されます。
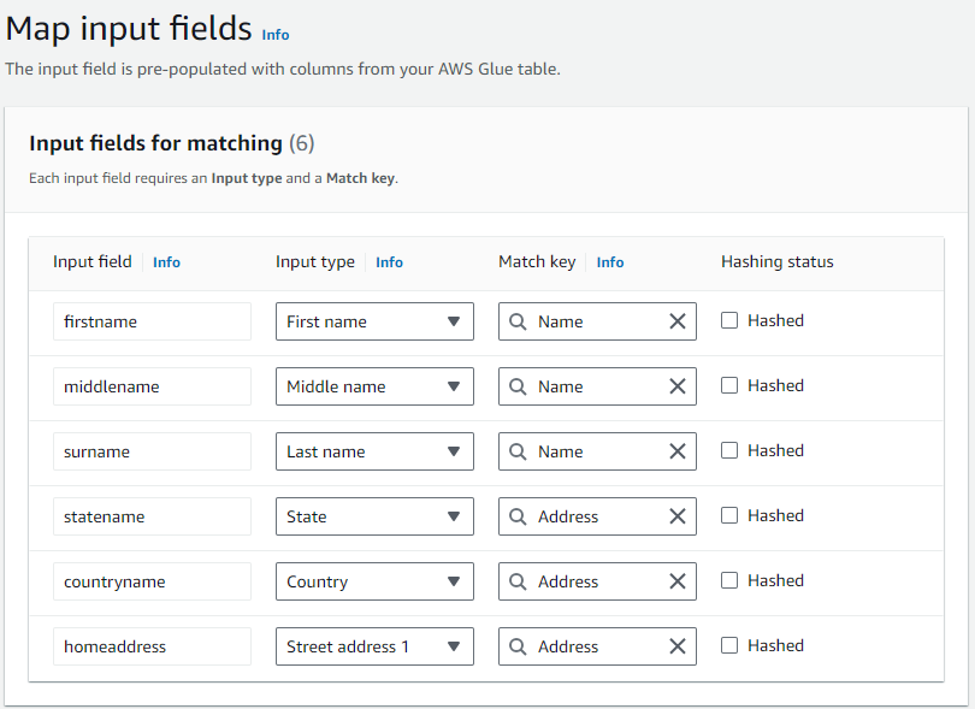
図 8 – AWS Entity Resolution スキーママッピング、入力フィールドを入力タイプへマッピング
「次へ」をクリックしてグループを作成します。グループとは、First Name (名) 、Middle Name (ミドルネーム) 、Last Name (姓) のような関連する入力フィールドを単一の「Name (氏名) 」列にまとめたセットです。これにより、AWS Entity Resolution は、マッチングと類似性の計算の際に、個々のフィールドを個別に比較するのではなく、まとめて比較することができ、より正確なマッチングが可能になります。

図 9 – AWS Entity Resolution スキーママッピング、名前のグループ定義
名前フィールドのグループ化と同様に、「住所」フィールドのグループも作成し、入力フィールドとして statename (州名) 、countryname (国名) 、homeaddress (自宅住所) を選択します (図 10 参照) 。

図 10 – AWS Entity Resolution スキーママッピング、住所のグループ定義
グループ設定が完了したら、「次へ」をクリックして、確認と作成画面に進みます。すべての設定を確認し、「スキーママッピングの作成」をクリックします。これによりスキーママッピングが作成されます。
スキーママッピングが作成されたら、次のステップはマッチングワークフローの作成です。マッチングワークフローは、ソース間でレコードをマッチングおよびリンクするために必要な、関連するマッチング技術、ルール、または機械学習の入力を定義するのに役立ちます。マッチングワークフローを作成するには、左側のメニューのワークフローのドロップダウンから「マッチング」を選択し、「マッチングワークフローの作成」ボタンをクリックします (図 11 参照) 。

図 11 – AWS Entity Resolution マッチングワークフローの作成
マッチングワークフロー画面で、名前と説明を入力してワークフローの作成を開始します。この例では、「patient-data-matching-workflow」という名前を付けました。

図 12 – AWS Entity Resolution マッチングワークフロー作成:名前と説明の定義
次に、適切な AWS Glue データベース、AWS Glue テーブル、および先ほど作成した対応するスキーママッピングを選択します。このステップにより、AWS Entity Resolution サービスにソースデータの場所を知らせ、スキーママッピング定義を使用してデータを解析し理解する方法を指示します。

図 13 – AWS Entity Resolution マッチングワークフロー作成:入力ソースの定義
AWS Entity Resolution に必要なアクセス権限を提供します。このサービスを初めて実行する場合は、「新しいサービスロールの作成と使用」を選択します。このオプションにより、サービスは自動的に IAM ロールを作成し、入出力用に指定された Amazon S3 バケットと、生データの入力ソースである AWS Glue データベース / テーブルへのアクセス権限を付与します。サービスロール名は自動生成されますが、必要に応じて編集することができます。IAM ロールの作成に関する詳細は、ユーザーガイドで確認できます。

図 14 – AWS Entity Resolution マッチングワークフロー作成:IAMロールの選択
最適な IAM ロールオプションを選択した後、「次へ」をクリックして次のページに進みます。このページでは、ソースデータの解決を実行するために、ルールベースと機械学習ベースのマッチングの間から適切なマッチング技術を選択します。この場合、同一患者に属するレコードを確定的に識別するために、ルールベースのマッチング技術を選択します。

図 15 – AWS Entity Resolution マッチングワークフロー作成:ルールベースマッチング技術の選択
マッチングルールでは、ルール名を入力し、そのルールのマッチキーを選択します。最大 15 個のルールを作成でき、ルール全体で最大 15 個の異なるマッチキーを適用してマッチング基準を定義できます。比較タイプについては、「複数入力フィールド」オプションを選択します。これにより、データが同じ入力フィールドにあるか異なる入力フィールドにあるかに関係なく、複数の入力フィールドに保存されているデータをマッチングすることができます。

「次へ」をクリックして次のページに進みます。このページでは、サービスが結果を書き込む出力用 Amazon S3 バケットの場所を設定します。出力データ形式として「正規化データ」を選択します。このオプションでは、ダウンストリームでの迅速な利用のために、特殊文字や余分なスペースを削除し、すべての値を小文字に整形することでレコードを正規化します。必要に応じて、「AWS Entity Resolution 向け正規化ライブラリのカスタマイズガイダンス」に従って、正規化ライブラリをカスタマイズすることができます。

図 16 – AWS Entity Resolution マッチングワークフロー作成:出力設定
ワークフローを作成する前の最終ステップとして、すべての設定内容を確認し、マッチング要件を正確に反映していることを確認してから、「作成して実行」をクリックします。これによりマッチングワークフローが作成され、最初のジョブが実行されます。
ジョブの完了を待つと (図 17 参照) 、ジョブメトリクスに入力レコード数と生成された一意のマッチング ID 数が表示されます。出力は設定された Amazon S3 バケットに書き込まれます。指定された出力用 Amazon S3 バケットへ移動し、出力ファイルをダウンロードして結果を分析することができます。

図 17 – AWS Entity Resolution マッチングワークフロー実行統計
出力データ (図 18 参照) では、各レコードに元の一意の ID (uniqueid カラム) と新しく割り当てられた matchid が含まれています。同じ患者に関連するマッチングレコードには、同じ matchid が付与されています。matchrule フィールドは、マッチしたレコードセットを生成した際に適用されたルールを説明しています。

図 18 – AWS Entity Resolution マッチング済みデータ出力
このマッチング済みデータは、医療機関や公衆衛生機関にとって貴重な資産となり得ます。予防接種情報システム (IIS) 、疾病監視プラットフォーム、人口動態記録システムなどの医療システムに、AWS Entity Resolution の出力から特定されたマッチを取り込むことができます。これらのシステムは、マッチング済みデータを活用して潜在的なマッチを特定し、ユーザーに提示することができます。これにより、医療スタッフは潜在的なマッチを確認、統合、解決することができ、患者データの正確性と完全性を向上させることができます。
マッチング済みデータを活用することで、組織はより良い介入を促進し、健康状態の改善につながる分析を強化することができます。例えば、異なるデータセット間でデータをリンクすることで、予防接種データ、病院の退院データ、疾病監視データを連携させ、重症 COVID-19 のリスク要因をより良く特定することができます。
まとめ
AWS Entity Resolution は、断片化されたレコード、データに基づかない意思決定、研究の障壁、不正確なデータによるケア連携の不一致、コスト増加といった課題の解決に役立ちます。この例で示されたように、医療機関や研究者は、AWS Entity Resolution を使用して、複数の多様なデータソースから患者レコードを効果的にリンクおよびマッチングすることができます。これにより、個人の健康履歴と結果について包括的で長期的なビューを作成することが可能になり、結果としてより良い全体的なケアにつながる可能性があります。
貴社のビジネスの加速にどのように貢献できるか、AWS の担当者にお問い合わせください。
参考文献
- AWS Entity Resolution Resources
- ヘルスデータのための AWS Entity Resolution
- AWS Entity Resolution: 複数のアプリケーションとデータストアからの関連レコードを照合してリンクする
- AWS Entity Resolution Workshops
著者について
本稿の翻訳は、ソリューションアーキテクトの髙橋が担当しました。原文はこちら。