SREチームマネージャーの藤原です。
LM Studio + Gemma 3 + Cline + VSCodeの環境を自由研究的に試用したので、その報告エントリです。
モチベーション
プライベートでコードを書く際も最近はClineなどを使ってLLMを使ってコーディングをすることが徐々に増えてきました。 VSCodeとClineを組み合わせて外部サービスをつかってコードの変更作業を実施する場合、 何かコードの変更を依頼するたびに、財布の中身から少しずつお金が溢(こぼ)れていく感覚があるでしょう。
1回1回の額は少額とはいえ、多数回繰り返すとなかなかの金額になってきます。 会社では予算の範囲内であれば、利用できますが、個人開発の場合はなかなか躊躇してしまうこともあるでしょう。
また、先日Googleが公開したオープンなローカルLLMのGemma 3も話題になったりしています。 そこでAPI課金に怯えることなくLLMを活用したコーディングができないか?ということでGemma3を使ったコーディングにチャレンジしてみました。
やったこと
Clineからローカルマシンで動かしているGemma 3のモデルを利用してコードを作成させてみる。
試行に用いた環境
昨年くらいにインフルエンザにかかって熱に浮かされた際に購入したマシンで試してみます。
- HP ZBook Fury 16 G9
あらかじめ、GEMMA 3を動かす上で必要となるNVIDIAのプロプライエタリドライバや、CUDAは導入済みです。 またファイアウォール等も設定済みです。
環境構築
LM Studioの導入
ローカルLLMを動かすためのツールとしてLM Studioを導入します。
LM Studioの公式ページ にアクセスして、LM Studioをダウンロードします。
Linux向けには、AppImage版が用意されており、libfuse2さえインストールされていればシングルバイナリで動作するようになっています。
ダウンロードしたAppImageファイルを実行できるようにファイルのプロパティを変更します。
ファイルに実行権限を付与しましょう。 ダウンロードしたファイルのアイコンを右クリックして、ファイルのプロパティを開きます。 アクセス権のタブを開いて、プログラムとして実行可能のチェックボックスにチェックを入れます。
ダウンロードした
これでLM Studioの導入は完了です。 それでは、アイコンをダブルクリックしてLM Studioを立ち上げてみましょう。
Gemma 3の取得と設定
LM Studioの画面下部でDeveloperに設定します。

ウィンドウ左側の虫眼鏡アイコンを選択します。 モデルの検索画面が表示されるので、Gemma 3を検索します。
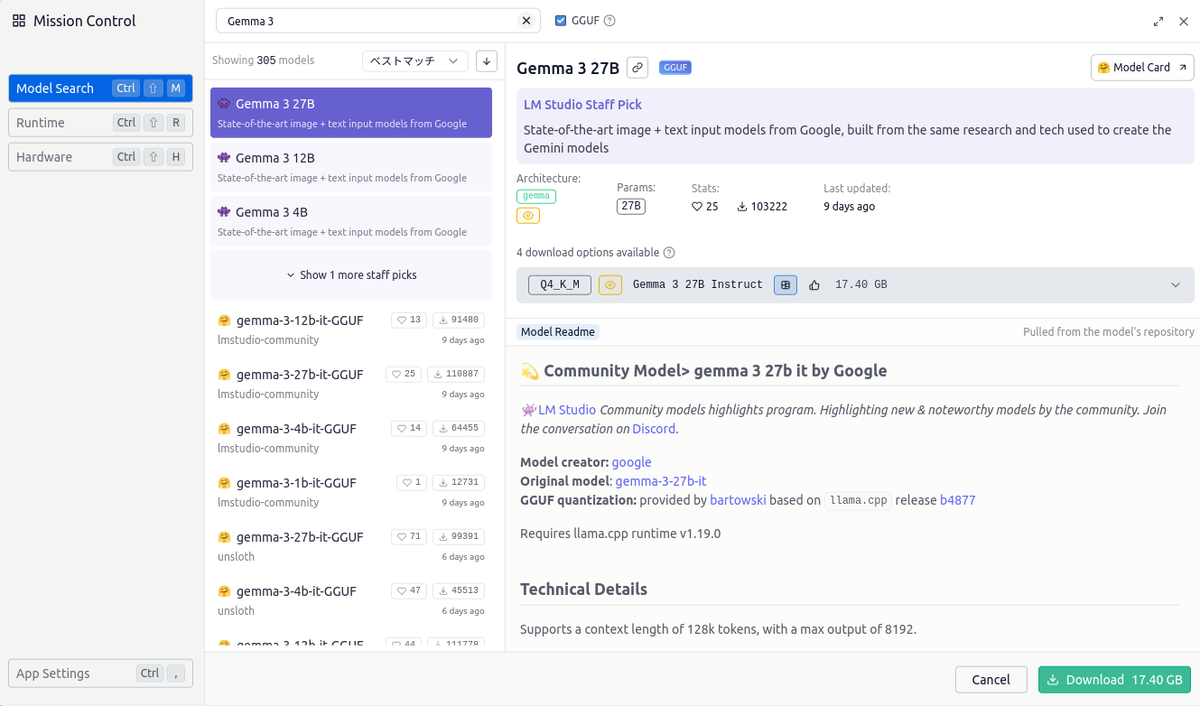
検索結果から Gemma3 4Bを選択してダウンロードします。
元の画面に戻りターミナル風のアイコンをクリックします。
Status: Stoppedとなっているトグルスイッチを切り替えるとCline等からアクセスするためのサーバーが起動します。
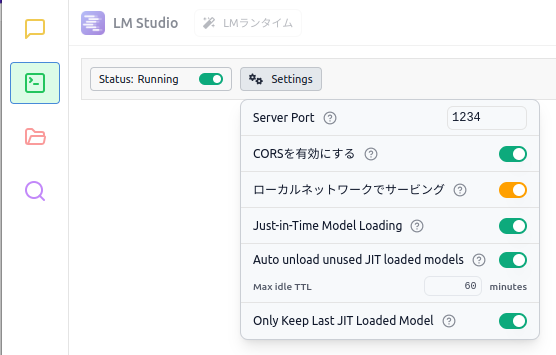
Settingsドロップダウンメニューから追加の設定ができます。
他のマシンからアクセスする際はローカルネットワークでサービングを有効にします。
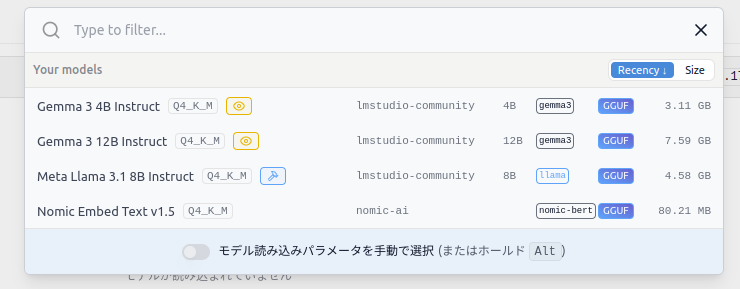
次にサーバー経由で提供するモデルを読み込んでおきます。画面上部の読み込むモデルを選択ドロップダウンメニューを選択します。
ダウンロード済みのモデル一覧が表示されるので、Gemma 3 4B Instructを選択します。
モデルの読み込みが完了しましたが、このままではコンテキスト長が不足しているため、Cline経由で利用できません。
右側のモデルの設定画面からLoadタブを開いて、コンテキスト長を設定します。
ここでは、50000を設定しました。
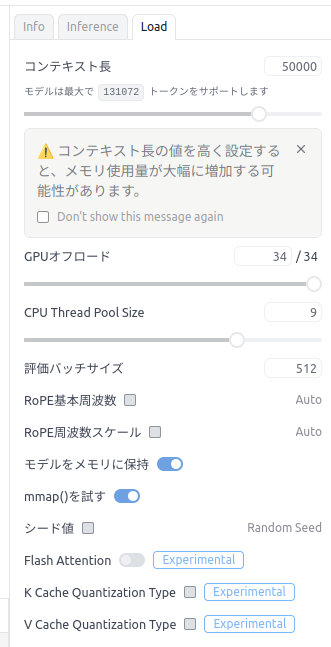
設定を変更したので変更の適用ボタンをクリックして設定変更を反映します。
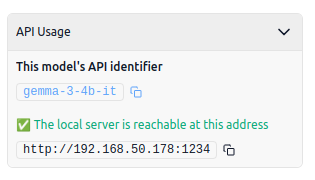
Infoタブを開くと接続に必要な情報が表示されます。
VSCode (Cline)の設定
VSCodeを起動し、拡張機能でClineを検索してインストールします。
VSCodeの左側のClineのアイコンをクリックします。

Clineの画面が開くので画面右上の歯車アイコンをクリックして設定画面を開きます。
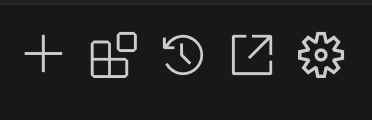
Clineの設定画面が表示されるので、LM Studioに接続するように設定します。
API ProviderにLM Studioを選択します。
Base URLにはLM StudioでGamma 3を設定した際に表示された接続情報を設定します。
ここまで設定すると、利用可能なモデルが表示されるので gemma-3-4b-itを選択します。
ここまで設定したらDoneボタンをクリックして設定完了です。
では試みに動かしてみましょう。
動かしてみる
Clineを使ってFizz Buzzのbashスクリプトを書かせてみました。
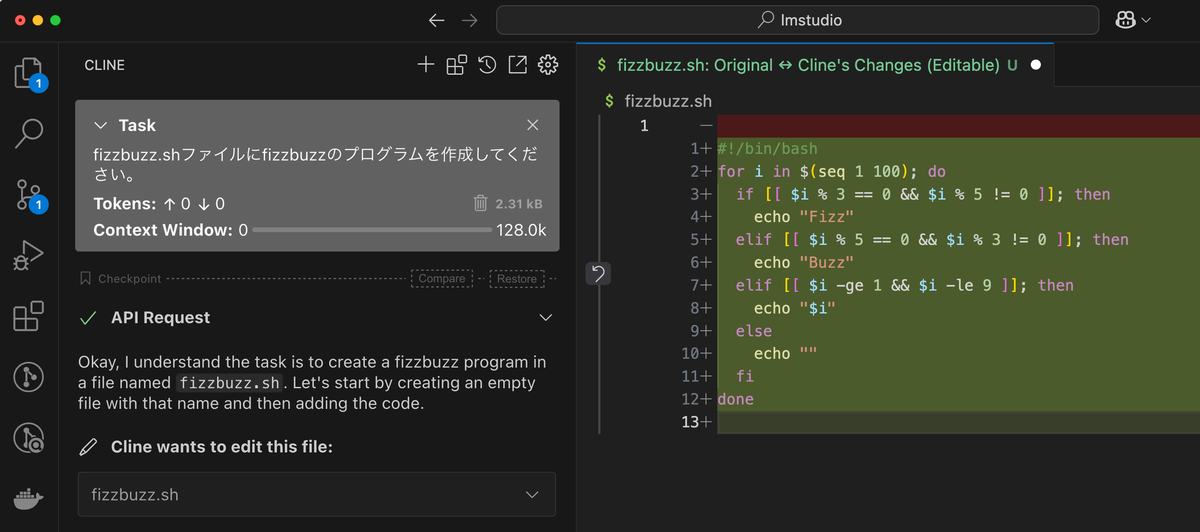
いくつかのプロンプトや何度かの指示出しを試してみましたが、残念ながらgemma-3-4b-itでは正しいFizz Buzzプログラムを出力するまでは、結構な手数が必要でした。
プロンプトの書き方についてはまだまだ改良の余地はありそうなのでこの辺りを磨いていくことで改善はできるかもしれません。
速度的には、外部のサービスを利用するよりもかなり高速に動作しました。試行錯誤する観点では、かなりストレス少なく利用できると思います。
また、(ハードがすでにあれば)電気代のみなので、その点ではコストを気にすることなく安心して利用できました。
モデルを変えた場合どうなるかを検証する目的でgemma-3-12b-itを使っての出力も試してみました。
デフォルトの設定のままでは十分なトークン数(Clineの要求するだけのもの)を設定することができませんでした。
一方で、gemma-3-12b-itが動作するよう設定を変更した場合は正しく動作し、Fizz Buzzプログラムを正しく生成することはできましたが、実用的とはいいがたい出力速度でした。
まとめ
今回は試みにGemma 3 + LM Studio + Cline + VS Codeで生成AIをつかったコーディングができないかを検証してみました。 最低限は動作するところまでは確認できました。
今後もモデルの改良は続くでしょうし、将来的にはより使いやすいものになることは間違いないので、時間を見つけて新しいモデル活用なども含めて試行錯誤を重ねる価値はありそうです。