Amazon Web Services ブログ
大規模マルチモーダル AI による鉄道車両の異常画像検知システムの実証実験
この投稿は東日本旅客鉄道株式会社(以下、JR東日本)、 Deutsche Bahn AG(以下、ドイツ鉄道)、DB Systel GmbH、株式会社JR東日本情報システム(以下、 JEIS )が、車両外観検査で撮影された画像の AI 活用に取り組む事例について寄稿いただいたものです。
JR東日本とドイツ鉄道は、 1992 年から技術分野における交流を続けている。本稿では、両社の技術交流における生成 AI の利活用事例について紹介する。両社は、労働力不足の軽減、検査時間の短縮、検査支援を目的にコンピュータビジョンを活用したプロジェクトを進めているが、従来の教師あり学習手法では、異常画像検知システムの開発に必要な学習データの準備が難しいという共通の課題があった。
上記課題を解決するため、 JEIS は JR東日本の協力のもと、大規模マルチモーダル AI を用いた異常画像検知システムの可能性に着目し、実現性の検証を実施した。なお、実際の異常画像の準備が難しいことから、本検証の性能評価用のテストデータとしては、画像生成 AI で生成した異常画像を使用することとした。
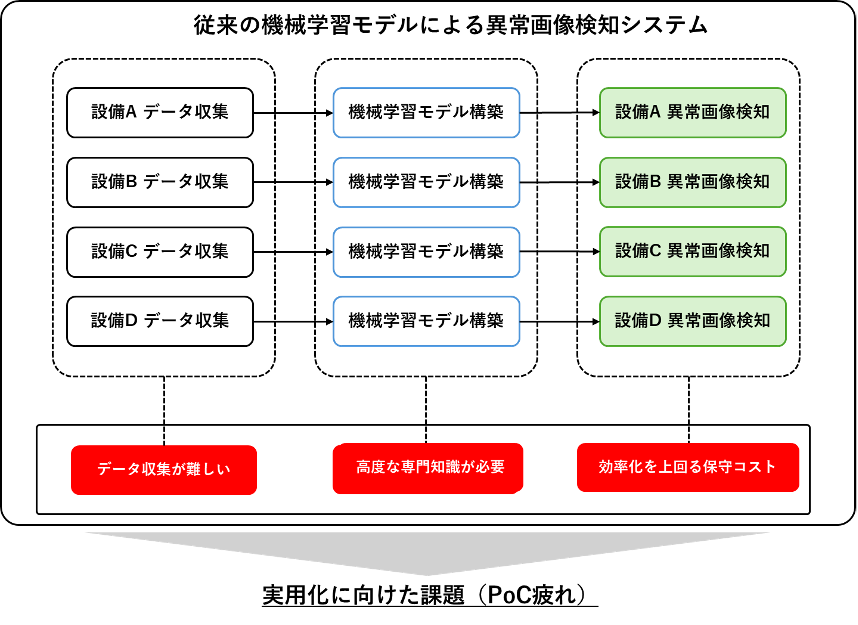
従来の機械学習モデルによる異常画像検知システムの開発には、ドメイン知識を持つユーザーが設備ごとにデータを収集し、専門知識を持つ技術者が適切なアーキテクチャの設計・開発を行う必要がある。しかし、高度な人的資源の確保は難しく、実用化が進まないのが現状である。
一方で大規模マルチモーダル AI を活用することで、これらの課題を克服できる可能性がある。大規模マルチモーダル AI とは、テキスト、画像、音声など複数の異なるデータ形式を統合的に処理することを目的に、大規模かつ多様なデータセットで学習された AI モデルである。この特性により、高い汎用性を持ち、画像だけでなくテキストやセンサーデータなどを統合的に解析することが可能で、ドメイン知識が限られている状況でも高精度な推論が期待される。
本稿で提案する大規模マルチモーダル AI による異常画像検知システムが実用化されれば、高度な人的資源に依存せずに AI の導入が可能になると期待される。検証結果は、同様の課題を抱える事業者への知見共有を目的として、 JR東日本およびドイツ鉄道の許可を得たうえで公開することとした。
本稿が、異常画像検知システムの実用化に向けた一助となることを期待する。
異常の定義
ドイツ鉄道では日々の検査のため、車両外観検査装置を用いて車両屋根を撮影している。この画像には、稀に落下物が写ることがあるが、この落下物は列車の運行に影響を与える可能性があるため、 AI を使用して、落下物を素早く発見して取り除く必要がある。以下に、過去に実際に発見された落下物の例を示す。車両屋根には落下物以外にも、部品の欠損やケーブルの緩みといった異常が発生する可能性があるが、本検証では対象外とした。
| 異常種別 | 説明 | |
|---|---|---|
| 1. | Branch | 運行途中で車両屋根に落ちた枝 |
| 2. | Roll | メンテナンス作業員が置き忘れたテープ |
| 3. | Rag | メンテナンス作業員が置き忘れた掃除用の布巾 |
| 4. | Plastic Bottle | 誰かによって投げ捨てられたペットボトル |
| 5. | Handbag | 誰かによって投げ捨てられたハンドバッグ |
| 6. | Banana | 誰かによって投げ捨てられたバナナの皮 |
| 7. | Jacket | 誰かによって投げ捨てられたジャケット |
| 8. | Paint | 誰かによって投げ込まれたペイントによる汚れ |
| 9. | Bird | 鳥の死骸 |
ジャケットやハンドバッグといった落下物は、一見すると非現実的に感じるが、これらの異常は全て実際に発生した事象であり、深刻なリスクを引き起こす可能性がある。しかし、こうした異常の多くは年に数回しか発生しないため、十分な異常画像を収集することが難しく、従来の手法による異常画像検知システムの開発が困難となる。そのため、大規模マルチモーダル AI によりこれらの異常画像検知が可能であるかを検証することとした。あわせて、大規模マルチモーダル AI の検証に十分な量の評価データを準備するにあたり、画像生成AIにより異常画像を生成する方法を提案する。
異常画像生成
画像生成には、生成の方向性をガイドするための「プロンプト」と、特定の要素を含めないようにするための「ネガティブプロンプト」が存在する。汎用的に高品質な画像生成に有効なプロンプトはあるものの、鉄道車両の異常画像を作成する前例は少なく、試行錯誤が必要である。以下は、 Amazon Titan Image Generator v1 を用いて、車両屋根上にバナナの皮を生成するためのプロンプトの例を示す。本検証では、このプロンプトを活用し、正常画像の一部領域に異常を生成することで、実際の異常に近い画像の生成に成功した。

自動化プログラムの作成と検証
画像生成 AI は必ずしもプロンプトの記述通りの画像を生成するとは限らない。そのため、本物に近い異常画像を大量に生成するための自動化プログラムを実装した。このプログラムは、異常画像を繰り返し生成し、実際の異常画像に近い画像のみを選択することで、効率的に大量の異常画像データセットを作成することを可能にする。

自動化プログラムのフローは以下の通りである。異常画像の生成は、基となる正常画像と、異常種別ごとに用意したプロンプトリストを用いて実行する。
-
マスク画像の生成
- 正常画像に対して、異常を配置する座標(x, y)とマスク画像の大きさ(width, height)をプロンプトリストの条件に従って決定し、ランダムにマスク画像を生成する。
-
画像生成
- 正常画像とマスク画像を Amazon Titan Image Generator v1 (API)に入力して異常画像を生成する。
-
生成された異常画像の自動判定
- 生成された画像と異常種別の類似度が 20% 以上であることを確認する。
- 生成された画像と正常画像の類似度が 75% 以下であることを確認する。
- 上記の判定条件を 両方満たした場合、異常画像として保存する。
- 判定条件を満たさない場合、①に戻り再生成 する。
-
人手による画像の選別
- 保存された異常画像の中から、目視により異常画像を選別する。

(左上からBranch, Roll, Rag, Plastic Bottle, Handbag, Banana, Jacket, Paint, Bird)
本検証で用いた画像生成 AI による異常画像生成は、過去にドイツ鉄道が実施した画像処理ソフトを用いた異常画像生成と比較した結果、遠近法、オブジェクトのサイズ、影や反射の処理といった複雑な要素をより適切に処理できることが明らかになった。
大規模マルチモーダル AI による異常画像検知システムの検証
本検証では、大規模マルチモーダル AI として、 Amazon Bedrock から簡単に利用できる Anthropic Claude 3.5 Sonnet を活用することとした。 Anthropic Claude 3.5 Sonnet に対して、検査対象の画像とその画像に関する質問を入力し、画像解析の結果を出力させた。

大規模マルチモーダル AI のプロンプト設計
大規模マルチモーダル AI から望ましい出力を得るためには、適切な指示(プロンプト)を設計するスキルが重要である。この技術は プロンプトエンジニアリング と呼ばれ、 AI に対して適切な問いかけや指示を与えることで、より正確で有用な回答を引き出すことができる。
例えば、 AI に複雑な問題を解かせる際に、「Let’s think step by step」という一文をプロンプトに加える手法がある。これにより、 AI は問題を小さなステップに分けて考えるようになり、論理的かつ構造化された回答をしやすくなる。

大規模マルチモーダル AI による異常画像検知システムでは、プロンプトを以下のような構造で設定している。
- ロールの設定 1(You are Pro-mechanic)
- ロールの設定 2(If there are anomalies anywhere in the image, answer with True)
- 構造化された回答の要求(Let’s think step by step)
- 出力形式の指定(<think></think>, <answer></answer>)
異常画像検知システムの性能検証
本検証では、大規模マルチモーダル AI を用いた異常画像検知システムの性能を評価した。評価には、正常画像 50 枚および 9 種類の異常画像をそれぞれ 50 枚ずつ、合計 500 枚の画像データを使用した。検証結果を下記に示す。
| 異常種別 | True | False | 正解率 | |
|---|---|---|---|---|
| 1. | Branch | 50 | 0 | 100% |
| 2. | Roll | 31 | 19 | 62% |
| 3. | Rag | 49 | 1 | 98% |
| 4. | Plastic Bottle | 50 | 0 | 100% |
| 5. | Handbag | 50 | 0 | 100% |
| 6. | Banana | 50 | 0 | 100% |
| 7. | Jacket | 50 | 0 | 100% |
| 8. | Paint | 50 | 0 | 100% |
| 9. | Bird | 50 | 0 | 100% |
| 10. | Normal | 48 | 2 | 96% |
用語説明
- True: AI が “異常” を正しく判定した枚数。
- False: AI が “正常” と誤って判定した枚数。
- Normal: 正常画像、 AI が “正常” と正しく判定した場合を True 、誤って “異常” と判定した場合を False とする。
- 正解率: (True / (True + False)) × 100 で計算された割合。
全異常種別の平均正解率は 95.6% 。正常画像の正解率は96%、適合率は99.5% 、再現率は 95.5% 、 F 値は 97.4% を達成した。
適合率は AI が異常と判定した画像のうち、実際に異常であった割合を示している。つまり、誤って正常な画像を異常と判定することが少ないことを意味する。一方、再現率は実際に存在する異常画像のうち、 AI が正しく異常と認識した割合を示し、異常の見逃しが少ないことを表している。
これらのバランスを示す F 値が 97.4% と非常に高いことから、大規模マルチモーダル AI を用いた異常画像検知システムは、実用性があると判断できる。
ハルシネーション(幻覚)
大規模マルチモーダル AI が事実に基づかない情報を生成する現象をハルシネーション(幻覚)と呼ぶ。これは、文章生成の原理として、ある単語の次に来る可能性が最も高い言葉を順次出力する仕組みに起因する。本検証においても、稀に前後の文脈が不自然になるケースが確認された。以下の図は、大規模マルチモーダル AI による異常画像検知システムの出力結果の一例(異常種別:バナナ)である。このケースでは、大規模マルチモーダル AI が黄色の物体を検出しているにもかかわらず、「異常なし」と誤判定している。
本例では、異常判定の過程において、最初の 1 箇所目の検査で異常を検出したものの、その後の 7 箇所では異常が検出されなかった。このため、大規模マルチモーダル AI がテキスト生成の過程で最も確率の高い次の単語を予測する際に、「異常なし」と出力した可能性があると考えられる。
この問題を防ぐために、検査箇所ごとの出力結果を分析する別の言語モデルと併用し、「 1 箇所でも異常が検出された場合は異常と判定するアルゴリズム」を導入することで、誤判定を抑制できると考えられる。

実用化に向けた課題
近年、実証実験(PoC)による異常画像検知システムの検証が進んでいるが、PoC の段階を超えられない「 PoC 疲れ」が生じていると指摘されている。その要因の一つとして、従来の機械学習モデルをベースとした異常画像検知システムの開発には、ドメイン知識と高度な技術力を持つ人的資源が必要であり、さらに、 AI 導入による効率化を上回る保守コストが発生することが挙げられる。
例えば、設備 A と設備 B の異常画像検知システムを開発する場合、それぞれの設備画像を収集する必要がある。しかし、通常業務と並行して AI 導入のために新規のデータを収集することは容易ではない。特に、異常画像の撮影を目的として列車運行に影響を与えることは現実的に不可能である。仮に十分なデータが収集できたとしても、機械学習モデルの構築にはデータの前処理技術、適切なアーキテクチャの選定、機械学習モデルの開発に必要なプログラミング能力など、高度な専門知識を持つ技術者が求められる。さらに、異常画像検知システムの構築後には、システム化のための導入費や保守費が発生する。
これらの要因を総合的に考慮した結果、多くの企業が実用化を見送り、その結果として「 PoC 疲れ」が発生している。この状況を打開するためには、データ収集やモデル構築のプロセスを効率化し、導入および保守コストを削減するための新たなアプローチが求められる。
大規模マルチモーダル AI による異常画像検知システム
大規模マルチモーダル AI を活用した異常画像生成と、それを評価データとする異常画像検知システムは、上記の実用化に向けた課題の一部を解決する可能性がある。従来の機械学習に必要だったデータ収集コストを削減できるうえ、特定のタスクに応じたカスタマイズが比較的容易になる。また、本検証で示したように、プロンプトを適切に設計・調整することで、それぞれの設備に応じた異常画像検知が可能となる。

おわりに
大規模マルチモーダル AI の利用にあたっては、法的リスクや倫理的リスクを十分に考慮し、システム導入前にこれらの課題をクリアにする必要がある。例えば、 EU の「 AI Act 」では、 AI システムのリスクレベルに応じた厳格な規制が求められており、高リスクに分類される AI には透明性、説明責任、データガバナンスの確保が義務付けられている。特に、異常画像検知システムのような分野では、誤検知や判断のバイアスが社会的影響を及ぼす可能性があるため、倫理的側面を考慮した設計・運用が不可欠である。
一方で、本検証結果が示すように、大規模マルチモーダル AI の活用は、異常画像検知システムの精度向上や運用負担の軽減にも寄与する可能性が高い。今回の検証結果を踏まえ、鉄道事業における大規模マルチモーダル AI 活用のグランドデザインを策定し、異常画像検知システムの開発・保守の最適化を図ることで、安全性と経済性の両立を実現し、新たな価値創造の機会を拡大することができる。
大規模マルチモーダル AI の導入と活用を通じて、より安全で効率的な鉄道運行を支え、持続可能な未来を共に築いていきたい。
著者略歴
Stanford University US-Asia Technology Management Center
東日本旅客鉄道株式会社 フロンティアサービス研究所
株式会社JR東日本情報システム テクノロジー応用研究センター
Deutsche Bahn AG
謝辞
東日本旅客鉄道株式会社 フロンティアサービス研究所
DB Systel GmbH