こんにちは、AI チームの長澤(@sp_1999N)です。
今回は Arize AI 社が開発・提供する LLM アプリケーション向けの監視ツール Phoenix の紹介および簡単なデモ構築を行いたいと思います。

デモとして Chainlit で構築した簡易的なチャットサービスを、自前ホストした Phoenix サーバーで監視してみたいと思います。
Phoenix について
Phoenix は LLM アプリケーション向けの監視ツールとして、オープンソースで開発・提供されています。Python および TypeScript 向けに SDK の提供もされています。
LLM アプリケーションは API の呼び出しに留まらず、プロンプトや対話履歴の管理、function calling などで用いるツールの提供などその複雑さを増しています。この状況に対して、Phoenix は総合的な管理基盤として必要となる要素を提供してくれています。
LangSmith も似た機能を提供していますが、大きな違いとしてオープンソースか否かという点があります。Phoenix は "プライバシーとカスタマイズ性を念頭に置いて設計されたオープンソースのプラットフォーム" となっており、セルフホスティングすることが可能です。LangSmith でもセルフホスティングは可能ですが、エンタープライズプランへの加入が必要になります。
また Phoenix は OpenTelemetry を基盤としている点も大きな魅力となっています。
この記事では、Docker で Phoenix サーバーをホスティングして使ってみることに重点に置き、トレースからエラー監視までを行ってみようと思います。
Chainlit で構築したチャットサービスを監視する
Chainlit は LLM のチャットサービスを簡単に作成できる Python パッケージです。気になる方は公式ドキュメントをご参照ください。
今回は Phoenix によるトレーシングの様子を体感するため、簡易的なユースケースを用意します。
シナリオとして「LLM Agent が DB へのアクセス管理を行い、認証されたユーザーに対してのみ DB での操作を許可する」という設定を考え、このやりとりをチャット形式で行います。
Spans, Traces, Projects
具体的な実装例の前に、トレース管理において重要なコンセプトを簡単に整理します。
- Spans
- Span は LLM アプリケーション内での特定の操作や処理を表す基本的な単位です。
各 Span は、開始時間、終了時間、メタデータなどの情報を持ち、アプリケーション内でのリクエストの流れを詳細に追跡できるようになります。
- Span は LLM アプリケーション内での特定の操作や処理を表す基本的な単位です。
- Traces
- Traceは、アプリケーションまたはエンドユーザーによって行われたリクエストが、複数ステップで処理される様子を記録します。 Trace は1つ以上の Span で構成され、最初の Span は Root Span となります。各 Root Span は、開始から終了までのリクエスト全体を表し、親 Span の下にある Span は、リクエスト中に発生する詳細なコンテキストを提供します。
- Traceは、アプリケーションまたはエンドユーザーによって行われたリクエストが、複数ステップで処理される様子を記録します。 Trace は1つ以上の Span で構成され、最初の Span は Root Span となります。各 Root Span は、開始から終了までのリクエスト全体を表し、親 Span の下にある Span は、リクエスト中に発生する詳細なコンテキストを提供します。
- Projects
- Project は複数の Trace をまとめたものになります。基本的に、1つのアプリケーションやサービスに紐づくものとして扱います。
Docker compose
Phoenix とアプリケーションのコンテナをそれぞれ建てるため、以下のような compose file を作成します。イメージは docker pull arizephoenix/phoenix で pull してきます。こちらのページでサンプルが紹介されているので、今回はこれを踏襲します。
services:
phoenix:
image: arizephoenix/phoenix:latest
ports:
- "6006:6006" # UI and OTLP HTTP collector
- "4317:4317" # OTLP gRPC collector
llm-server:
build:
context: .
dockerfile: Docker/Dockerfile
ports:
- "8000:8000"
env_file:
- .env
depends_on:
- phoenix6006 番 port で Phoenix の管理画面に、8000 番 port で Chainlit で作成したチャット UI にアクセスすることができます。ちなみに、環境変数としては以下のものを使用しています。
OPENAI_API_KEY="YOUR_OPENAI_API_KEY"
COLLECTOR_ENDPOINT="http://phoenix:6006/v1/traces"
PROD_CORS_ORIGIN="http://phoenix:3000"無事に立ち上がると、図1のような Phoenix の管理画面を開くことができます。今回は検証用に phoenix-run-on-docker という名前のプロジェクトを作成し、そこで Chainlit サービスの挙動を監視します。
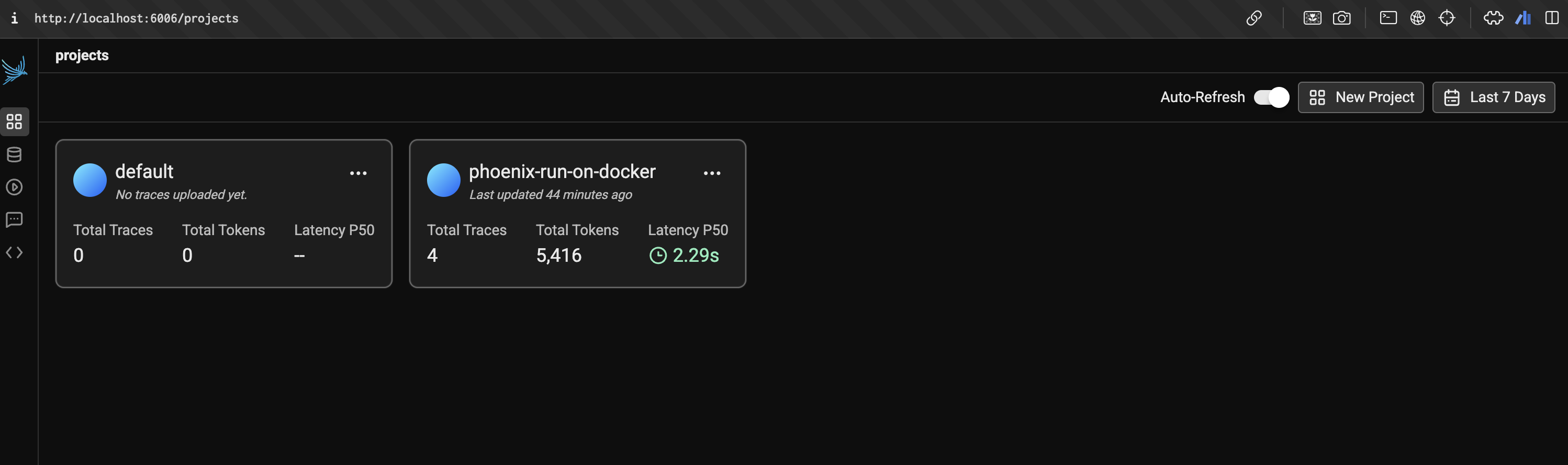
(添付の画像は Chainlit サービスを動かした後のものになっており、Token がどれくらい消費されたのかなどがプロジェクト単位で確認できることが分かります)
Phoenix のセットアップ
まず初めに、アプリケーションの監視を行う上で必要になる Tracer を定義します
import os
from phoenix.otel import register
from openinference.instrumentation.openai import OpenAIInstrumentor
# Initialize tracer provider and tracer
TRACER_PROVIDER = register(
project_name="phoenix-run-on-docker",
endpoint=os.getenv("COLLECTOR_ENDPOINT"),
set_global_tracer_provider=False
)
# Setup OpenAI instrumentation
OpenAIInstrumentor().instrument(tracer_provider=TRACER_PROVIDER)
# Get tracer instance
TRACER = TRACER_PROVIDER.get_tracer(__name__)プロジェクト名を phoenix-run-on-docker として TRACER_PROVIDER を定義します。COLLECTOR_ENDPOINT としては http://phoenix:6006/v1/traces など Phoenix のエンドポイントとなるものを指定します。
また OpenAIInstrumentor を使用することで、コード内で呼び出される OpenAI LLM へのリクエストを自動収集することができます。
そして TRACER_PROVIDER から TRACER を取得していますが、これがコード内で Span などのトレース単位を管理するオブジェクトになります。コードへの組み込みで使用することになります。
トレースの組み込み
上記で用意した TRACER を使って、Chainlit での挙動を監視します。
import uuid
import json
import chainlit as cl
from dotenv import load_dotenv
from openinference.instrumentation import using_session
from openinference.semconv.trace import SpanAttributes
from phoenix_config import TRACER
from llm_service import get_response
from tools import (
fetch_db_info,
auth_user
)
load_dotenv()
MESSAGE_HISTORY = []
session_id = str(uuid.uuid4())
@cl.on_chat_start
async def on_chat_start():
cl.Message(content="Ask me anything!").send()
# エラー分析のため、一部挙動パターンに対応していない不完全な関数となっています
@cl.on_message
async def on_message(message: cl.Message):
if not message.content:
await cl.Message(content="Feel free to ask me anything!").send()
with TRACER.start_as_current_span(name="agent", attributes={SpanAttributes.OPENINFERENCE_SPAN_KIND: "agent"}) as span:
with using_session(session_id):
span.add_event("チャットストリームを開始")
span.set_attribute(SpanAttributes.INPUT_VALUE, message.content)
MESSAGE_HISTORY.append({"role": "user", "content": message.content})
response = get_response(MESSAGE_HISTORY)
if response.choices[0].message.tool_calls:
span.add_event("function calling の実施")
tool_call = response.choices[0].message.tool_calls[0]
args = json.loads(tool_call.function.arguments)
tool_name = tool_call.function.name
try:
if tool_name == "fetch_db_info":
result = fetch_db_info()
elif tool_name == "auth_user":
result = auth_user(args["username"], args["password"])
else:
raise ValueError(f"Unknown tool name: {tool_name}")
except Exception as e:
raise e
MESSAGE_HISTORY.append(response.choices[0].message)
MESSAGE_HISTORY.append({
"role": "tool",
"tool_call_id": tool_call.id,
"content": str(result)
})
response = get_response(MESSAGE_HISTORY)
MESSAGE_HISTORY.append(response.choices[0].message)
response_content = response.choices[0].message.content
else:
response_content = response.choices[0].message.content
MESSAGE_HISTORY.append({"role": "assistant", "content": response_content})
span.set_attribute(SpanAttributes.OUTPUT_VALUE, response_content)
await cl.Message(content=response_content).send()
少し長いですが、重要なところだけをピックアップしてご紹介します。
注目頂きたいのは on_message 関数になります(後述のエラー分析のため、一部挙動パターンに対応していないコードになります🙇)
on_message の関数が主軸となっており、with TRACER.start_as_current_span() の with 句が宣言されています。これにより、1ターン分の対話を1つの Span として管理することができます。
また with using_session() が続きますが、これによりOpenTelemetry Context にセッションIDを追加します。今回の場合、Chainlit のアプリケーションを再起動するたびに新しい uuid が付与されるので、1セッションごとの管理が可能になります。
続いて span.add_event() を使って、イベント記録を行っています。これは Phoenix 上のログメッセージのようなものとして管理するものになります(ドキュメントはこちら)
そして span.set_attirbute() を使って key/value ペアとしてより詳細な挙動の記録を行います。今回は SpanAttributes で事前定義されている INPUT_VALUE および OUTPUT_VALUE に値を詰めることで、管理画面上で Session として一連の対話を管理できるようにします。
ここで、一度監視の様子を確認するために Chainlit 上でしりとりをしてみようと思います。
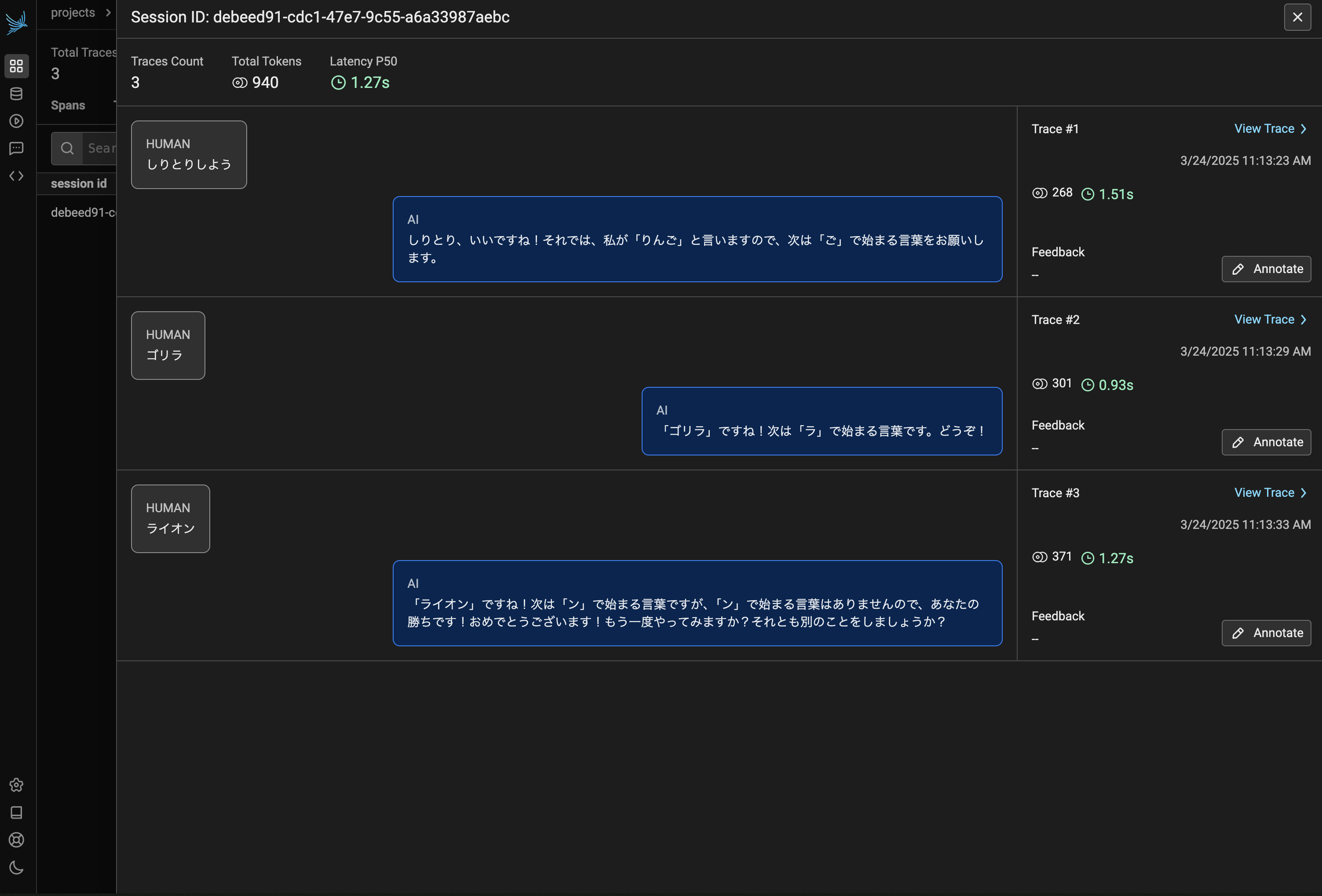
Chainlit でサービスを立ち上げ、数ターン分会話をした後に Phoenix 管理画面の Session タブを見てみると、図2のように対話のラリーが記録できていることが分かります。
なぜか「ん」で終わって勝ってしまいましたが、対話順に Trace が記録されていることが分かります。また上部のバーを見ると、この会話全体におけるトークンの総消費量やレイテンシーなどが確認できます。
この会話は3つの Trace から構成されていることがわかるので、次に Trace を見てみます。
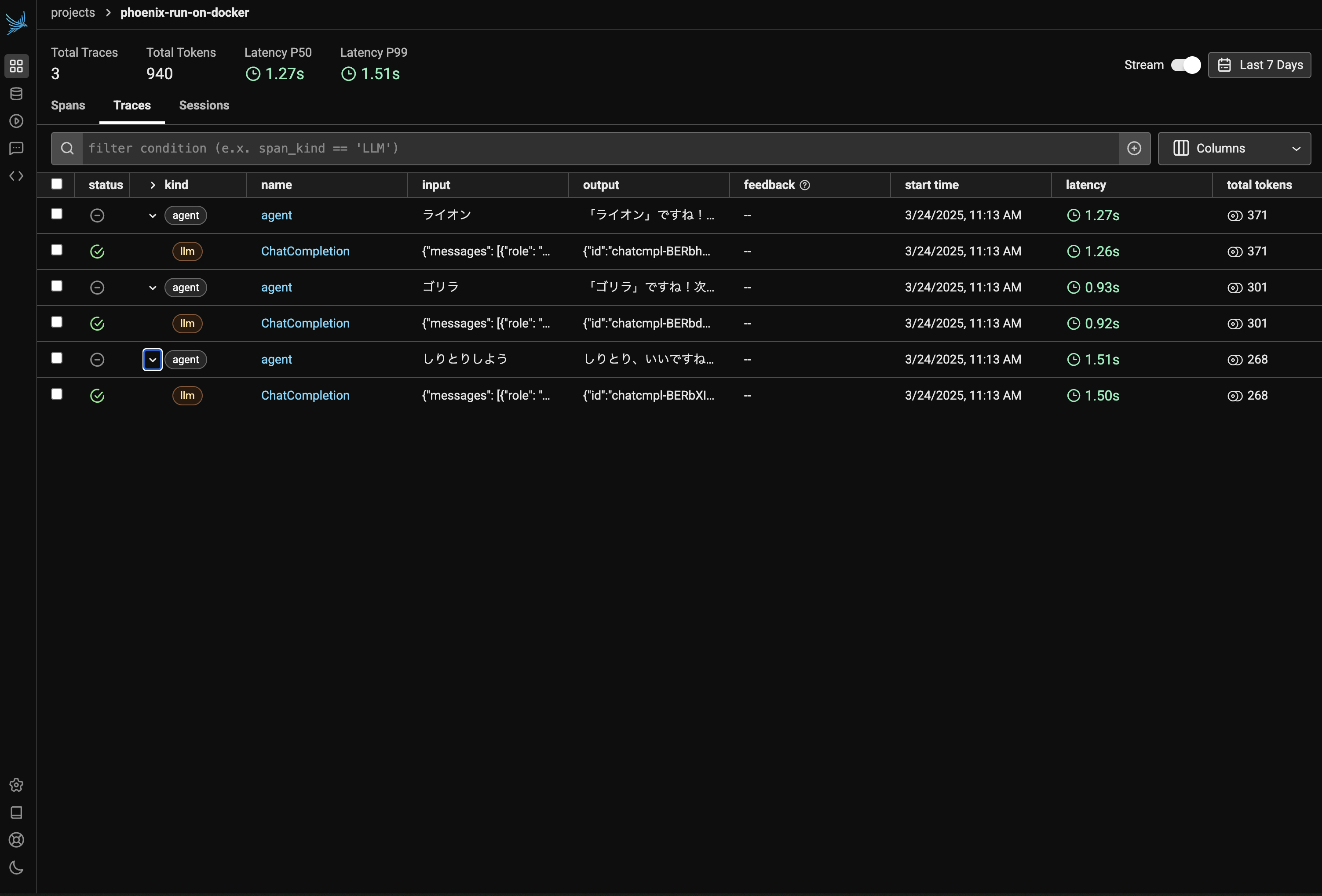
Traces タブを開くと図3のような画面が確認できます。それぞれ agent が親 Span となり、そこに llm Span がそれぞれ紐づいていることが分かります。
ここで llm Span をクリックしてみてみます。
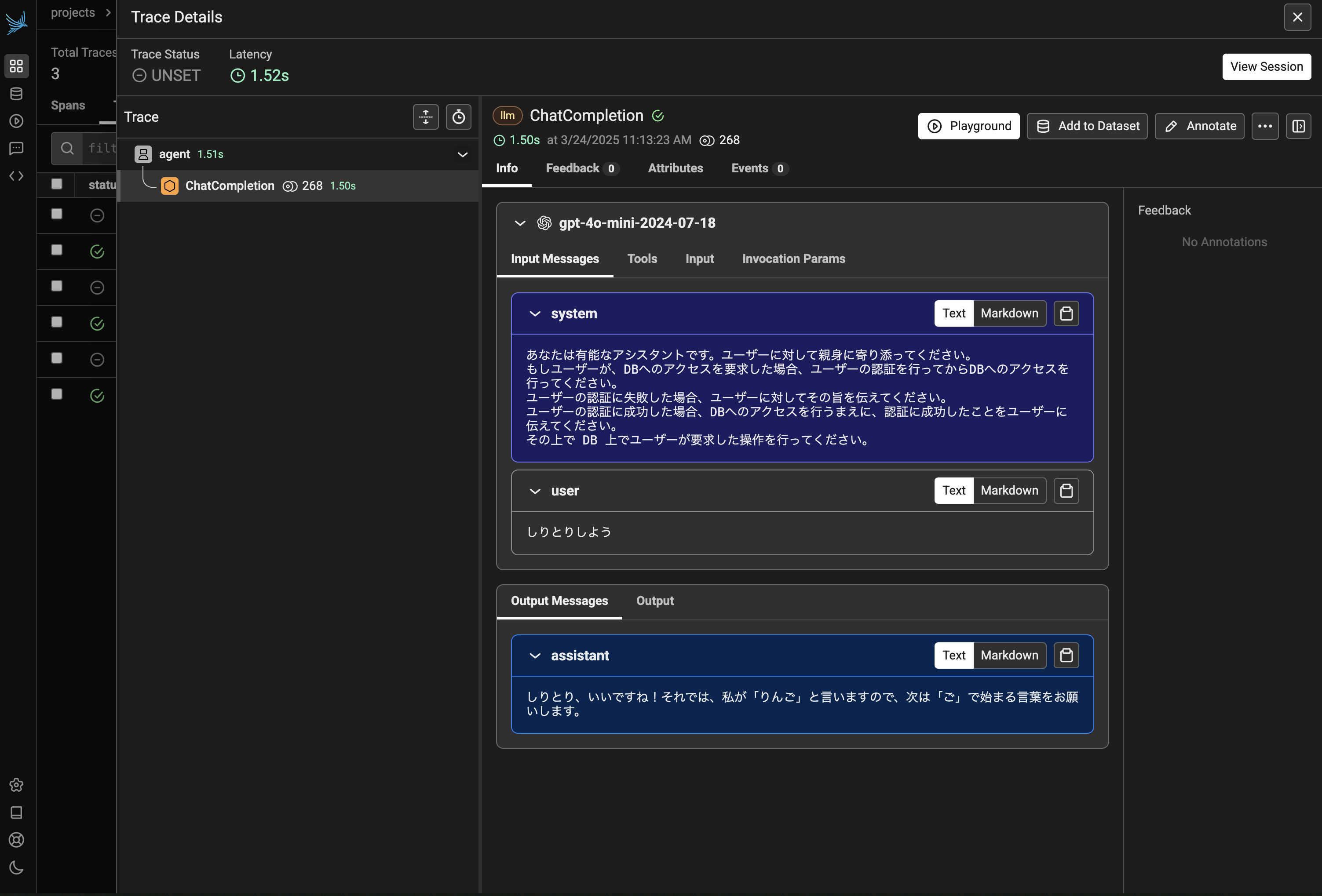
すると図4のように、system prompt などをその時のリクエスト内容の詳細を確認することができます。Tools などを開くと、LLM に設定されている json 形式の tool description なども確認できます。
また Trace ではアノテーションを付与することも可能です。今回はしりとりのルールを無視した不正な返答があったとして correctness というアノテーションを用意し、カテゴリカルラベルとして bad 、数値スコアとして 0 を設定してみます(図5)。
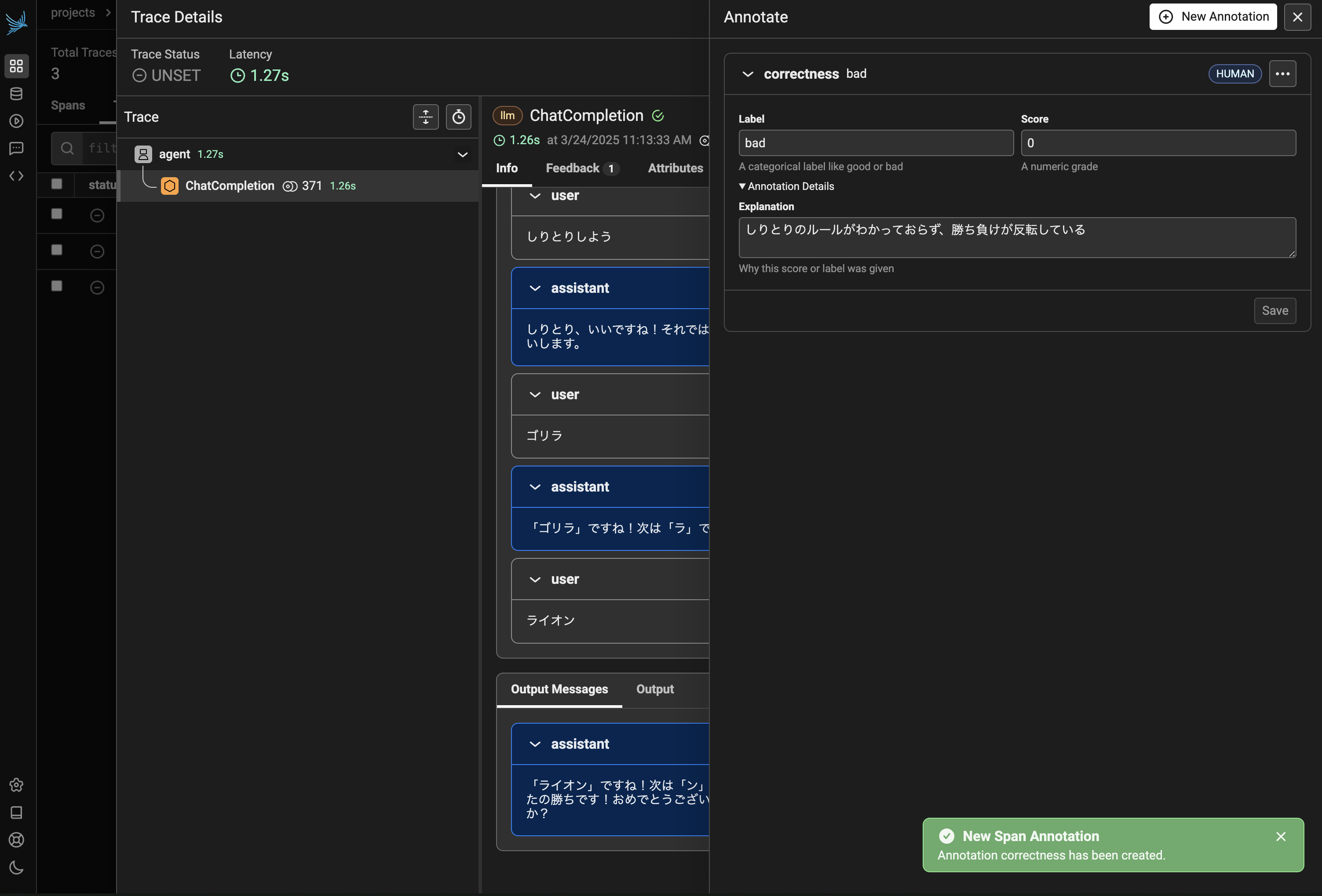
そのほか、しりとりの勝率などをアノテーションすると、下記図6のように Span にどのようなラベルが付与されているのかであったり、アノテーションラベルの統計情報を確認できるようになります。
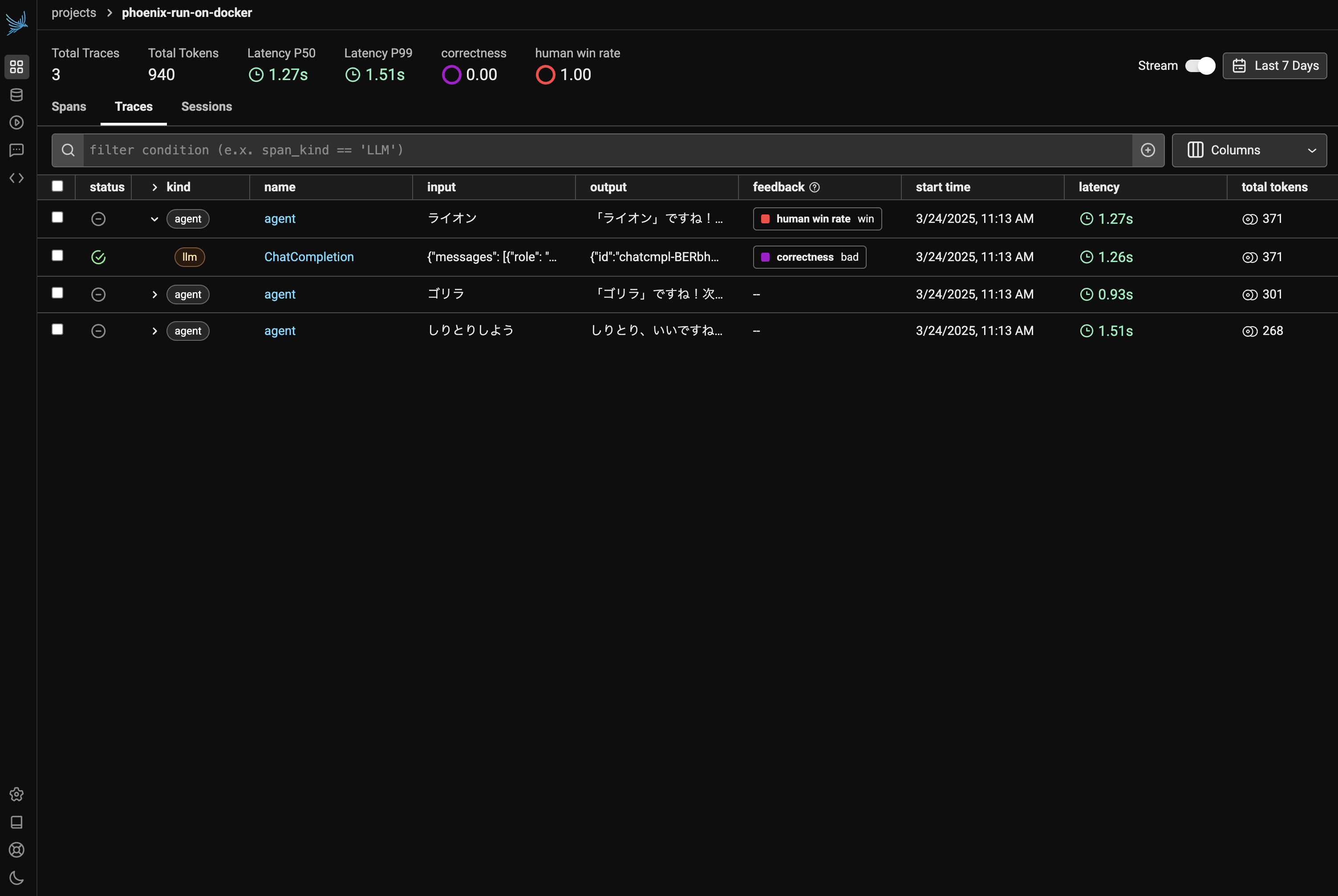
今回は試していませんが、コード内でアノテーションを付与することも可能です。例えば、ツールの呼び出し結果などを集計しておくことで、どの関数が LLM にとって使いにくそうか、などの分析も可能になります。また Datasets や Evaluation の機能と組み合わせることで、LLM as a judge による評価などにも拡張できます。
Tool Call
それでは最後に、function calling のトレースを行って今回の検証を終わろうと思います。
import random
import time
from phoenix_config import TRACER
TOOL_DESCRIPTIONS = [
{
"type": "function",
"function": {
"name": "fetch_db_info",
"description": "Fetch a list of users from a database. This tool can only be used by users who are authorized. Make sure to use the auth_user tool before using this tool.",
"parameters": {
"type": "object",
"properties": {}
},
"required": []
}
},
{
"type": "function",
"function": {
"name": "auth_user",
"description": "Authenticate a user with a password. Need username and password.",
"parameters": {
"type": "object",
"properties": {
"username": {"type": "string"},
"password": {"type": "string"}
},
"required": ["username", "password"]
},
"required": []
}
}
]
@TRACER.tool()
def fetch_db_info():
# 1-3秒のランダム遅延
delay = random.uniform(1.0, 3.0)
time.sleep(delay)
# 10%の確率で失敗
if random.random() < 0.1:
raise RuntimeError("Failed to fetch users data")
# ダミーのユーザーデータを生成して返す
dummy_users = [
{"id": 1, "name": "Taro Tanaka", "email": "tanaka@example.com", "age": 28},
{"id": 2, "name": "Hana Sato", "email": "sato@example.com", "age": 34},
{"id": 3, "name": "Suzuki Ichiro", "email": "suzuki@example.com", "age": 42},
{"id": 4, "name": "Yuko Ito", "email": "ito@example.com", "age": 25},
{"id": 5, "name": "Ken Yamada", "email": "yamada@example.com", "age": 31}
]
return dummy_users
@TRACER.chain()
def get_password(username):
passwords = {
"ais_user": ["aishift2025"],
"admin": ["admin_master_password"]
}
return passwords[username]
@TRACER.chain()
def get_auth_users():
users = ["ais_user", "admin"]
return users
@TRACER.tool()
def auth_user(username, password):
auth_users = get_auth_users()
auth_password = get_password(username)
if password in auth_password and username in auth_users:
return "Authorized"
else:
return "Not authorized"
LLM によって直接呼び出される関数は fetch_db_info とauth_user の2つのみです。
これらの関数には @TRACER.tool() のデコレータを使用します。これにより、「LLM によって実行される関数」として監視が可能になります。
また auth_user 関数に注目すると、内部で get_password と get_auth_users が呼び出されていることが分かります。このように「直接 LLM からは呼び出されないが、内部で実行される関数」には @TRACER.chain() のデコレータを使用することで、内部連鎖の様子をトレースすることが可能になります。
再度 Chainlit を立ち上げ直し、会話をしてみます。すると先ほどのしりとりとは別に、新しくセッションが切り出されます。
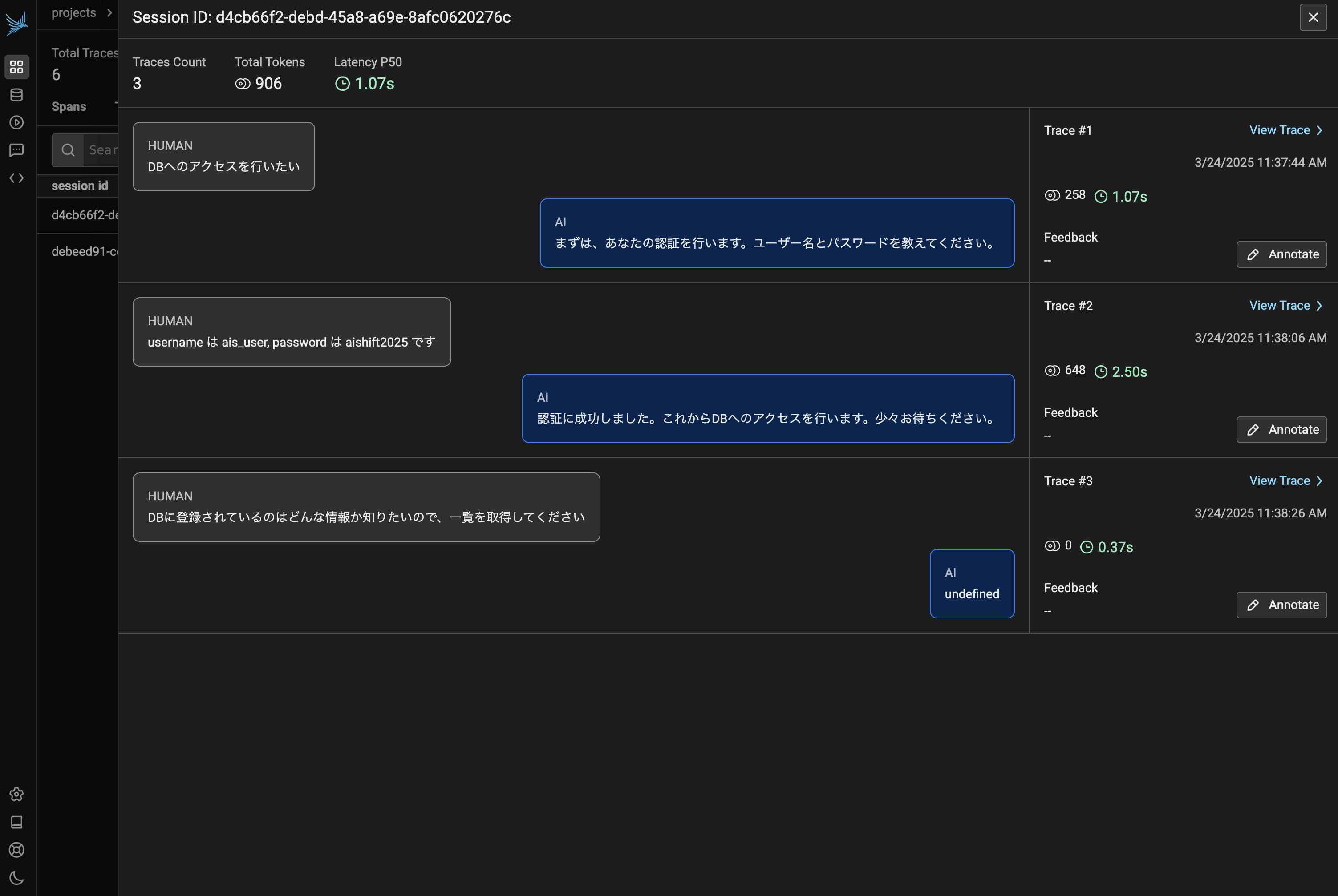
図7において、認証を行っている Trace #2 をみてみると、function calling が行われていることが分かります。下記図8は @TRACER.tool() でデコレートした auth_user 関数の挙動の様子です。関数への入出力までしっかりトレースされていることが分かります。また @TRACER.chain() でデコレートした2つの関数が紐づいている様子も確認でき、こちらについても同様に関数の入出力を確認することができます。
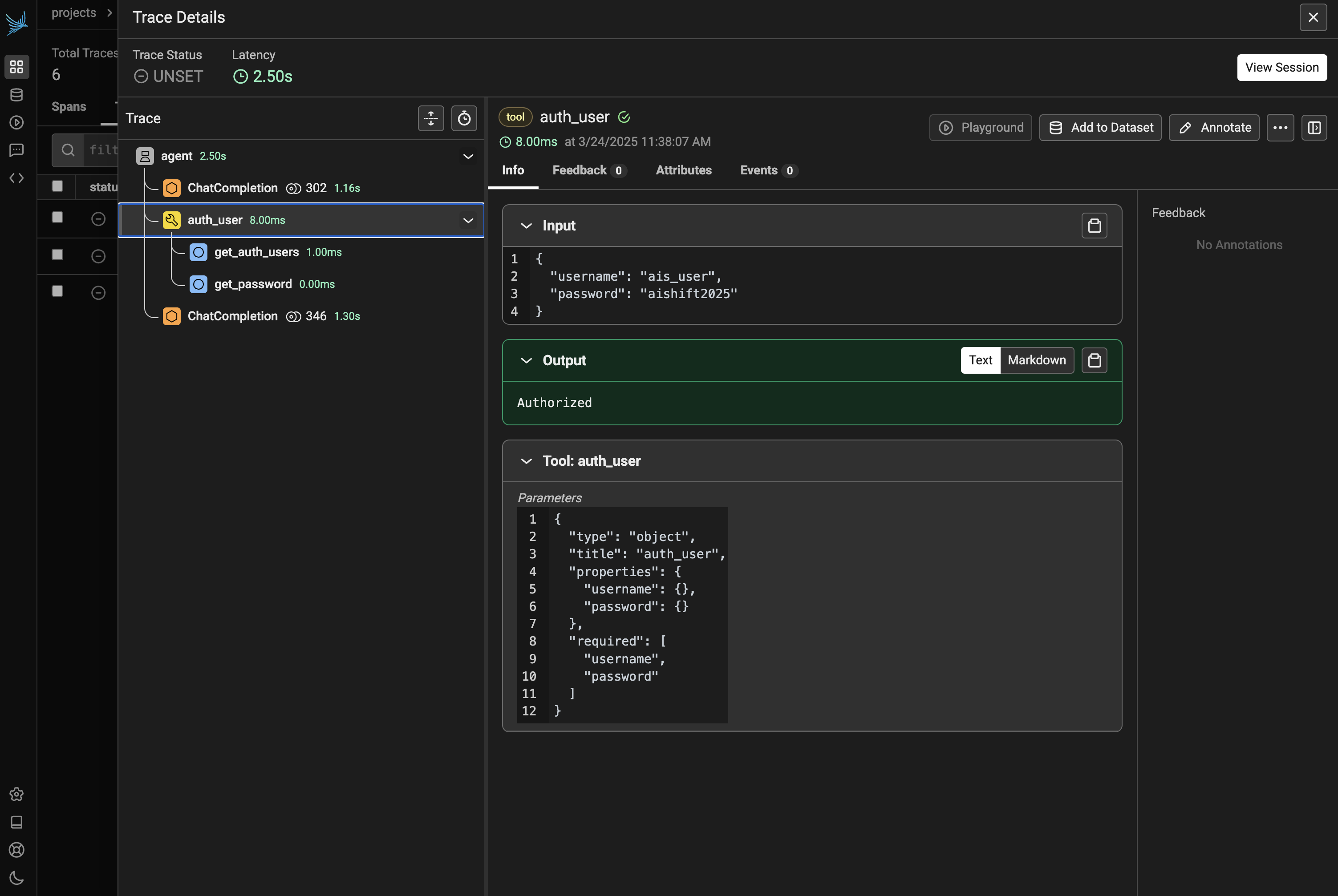
今回のやり取りでは認証挙動までは成功しましたが、fetch_db_info 関数の呼び出しに失敗してしまいました。
そこで Trace #3 の AI の返答が undefined となってしまっている点に注目し、この Trace の詳細をみてみます。すると、400 番エラーが返されていることが確認できます。
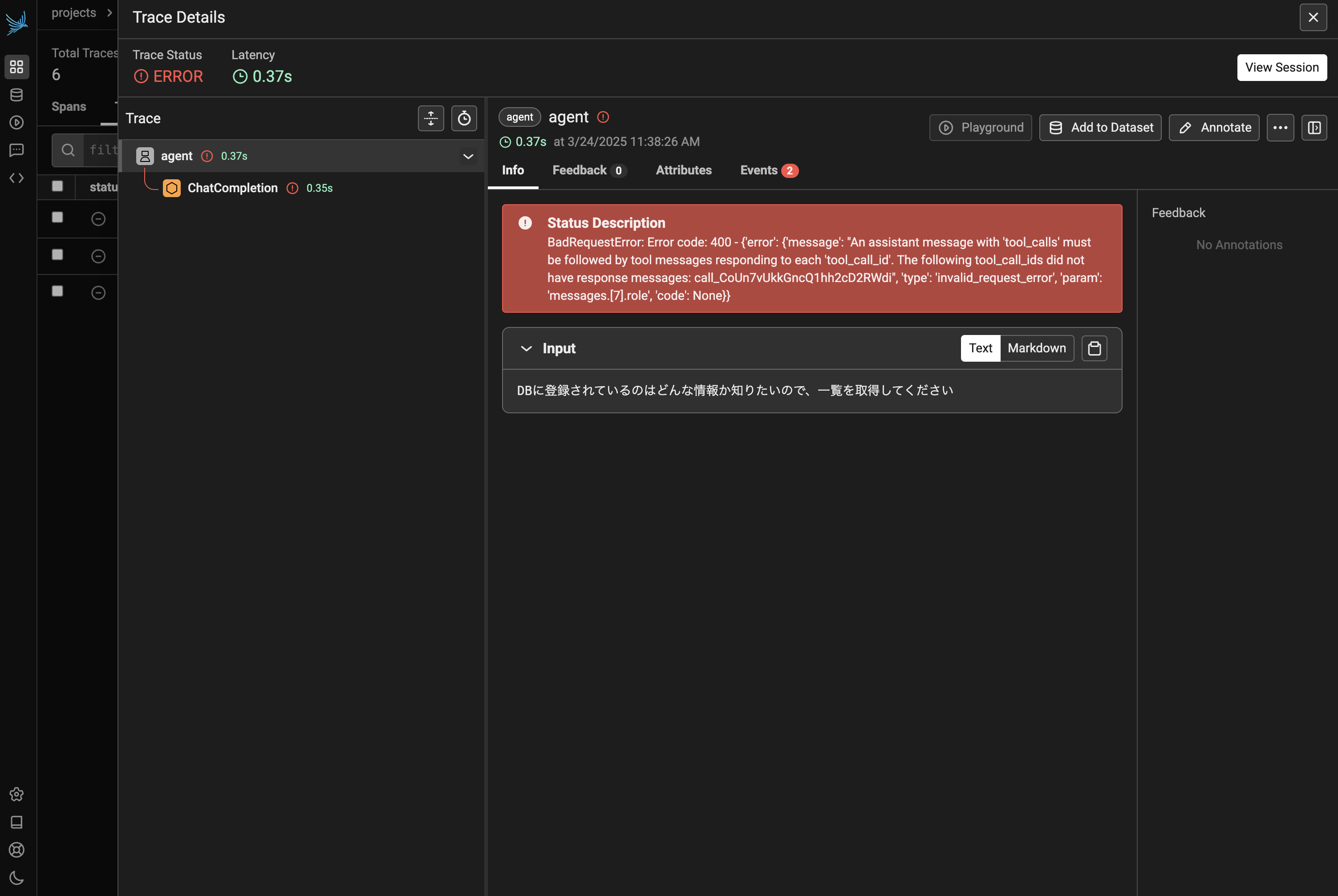
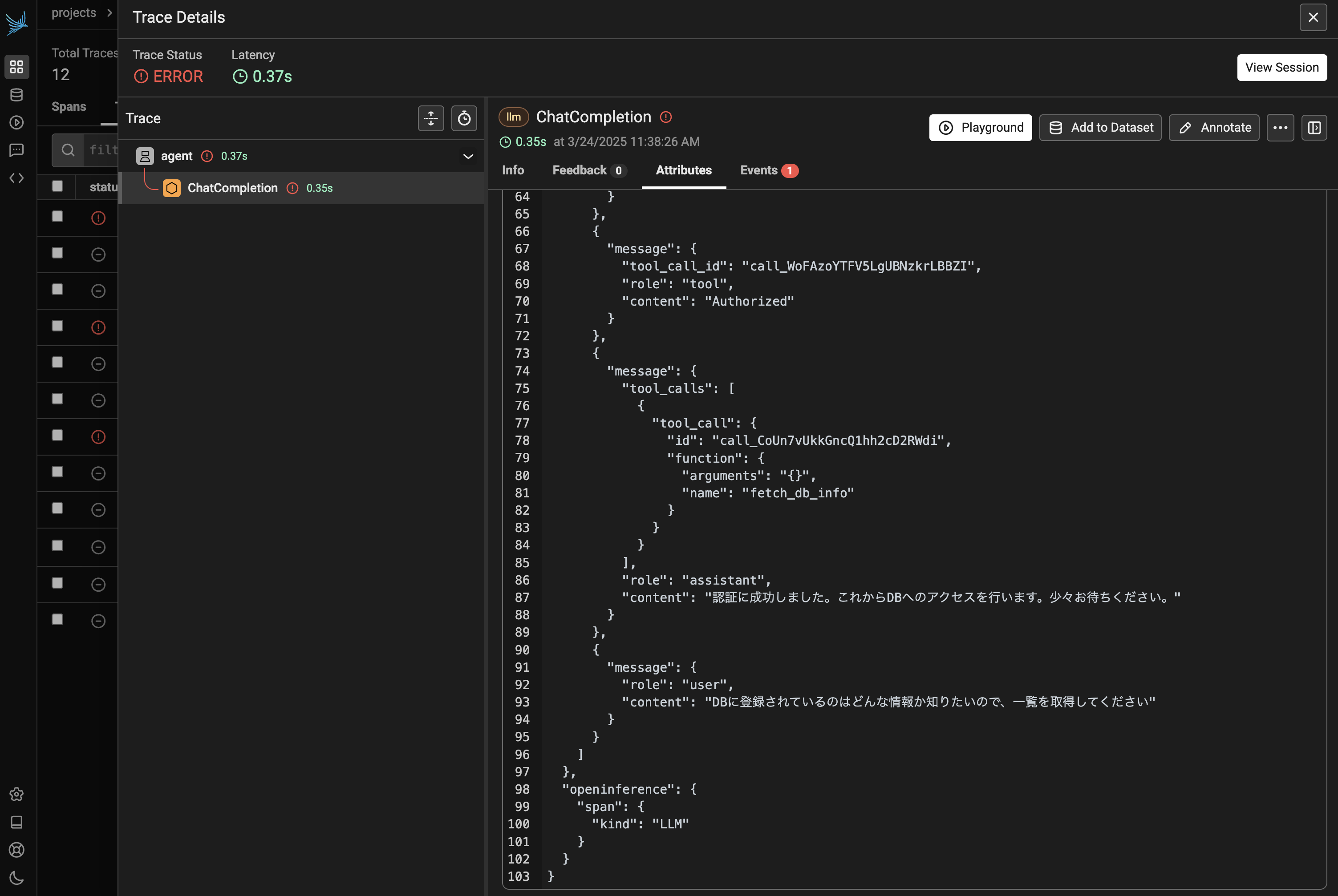
図9および図10を確認してみると、tool_call が LLM から要求された後に、関数が実行されずにユーザーメッセージが格納されてしまっていることが分かります。今回は Chainlit で on_response 単位で LLM を動かしていたため、「on_response の最終出力が tool_call の要求であるパターン」に対応できていなかったようです。
詳細なトレースがされているからこそ、どうしてアプリケーションが動かなくなってしまったのかの分析までとてもやりやすくなっています。
おわりに
今回は Arize AI が提供する Phoenix をセルフホスティングして、LLM サービスの監視を行ってみました。
デモとして構築したのはかなり簡易的なものでしたが、よりリッチな例を公式が紹介してくれています。今回は紹介できなかった Datasets & Experiments, Evaluation などの機能についても例が用意されています。
ご興味のある方は是非一度ご覧いただくと、実際のアプリケーションへの導入イメージがより明確になるかもしれません。




