




帰納的な推論と発見的な推論(アブダクション)は、
私たちがソフトウェア開発の現場/実務で(知らず知らずにでも)駆使している思考の形です(それどころか日々の暮らしでも使っています)。
それほど“自然な”思考の形ですが、どんな考え方で、どんなところに注意すると質の高い思考ができるのか、基本知識を押さえておくと実務のレベルアップにつながります。
<実務三年目からの発見力と仮説力 記事一覧>※クリックで開きます
今回のトピックは2つ、前編では「帰納的推論で気をつけたい落とし穴」、そして後編では「帰納的推論の仲間」(第2回の続き)です。
帰納的推論で気をつけたい落とし穴
帰納的な推論にも落とし穴(誤謬)はあります。
見つける共通項が因果関係である場合には、因果関係の推定に関わる落とし穴もあります。
第2回, 第3回で説明したことも併せ、改めて今回見ていきましょう。
なお、[実践編]と同様、以下の点に注意してください。
- 本記事で紹介しているものがすべてではありません。
- これらの分類は排他的なものではありません。複数の分類に該当する誤りもあります(視点によって分類が変わる)。
- 複数の誤謬が重複したり関連したりして間違った推論を形づくることもあります。
- 誤謬の名称は、人により文献によって名称が異なることもあります。
帰納的推論の性質に関わる落とし穴
一般化:標本(サンプル)にまつわる落とし穴
- 軽率な一般化、または不十分な標本の誤謬。
母集団の規模に対して少な過ぎる事例を基に一般化をしてしまう誤りです。 - 偏った標本の誤謬。
数は問題ないとしても、母集団の傾向(属性/特徴の在りよう)を適切に反映できていない事例を基に一般化をしてしまう誤りです。
事例の数が少ない場合は軽率な一般化だけでなく偏った標本になっていないか気をつける必要があります。
こうしたことは、統計的な推論でなく枚挙的な帰納をする場合でも気をつけたい事柄と言えます。
(参考:第2回の図2-1(B))

帰納的な推論ができそうな場合は、まず、
「事例の数と傾向を把握した上で推測を立てる」ことを意識して、これらの点を確かめましょう。
- 事例の数は、一般化するには十分そうか?
(推測に合致しそうな事例だけ無意識に集めているということはないか)
(数が少ない場合、推論の蓋然性が低い可能性を意識できているか) - 事例は偏っていないか?
(推測に合致しそうな事例だけ無意識に注目しているということはないか)
(偏りがありそうなら、事例を増やして多様性を増すことはできないか)
なお、「事例の数が少ないならば、帰納的推論の蓋然性は低い」、というわけではありません。
母集団の均質性、類似性が高いなら(どれも同じ属性を持っている、どれもみな似通っている、etc.)、事例の数が少なくても結論の蓋然性は見込める場合があります。
一般化:結論の導き方にまつわる落とし穴
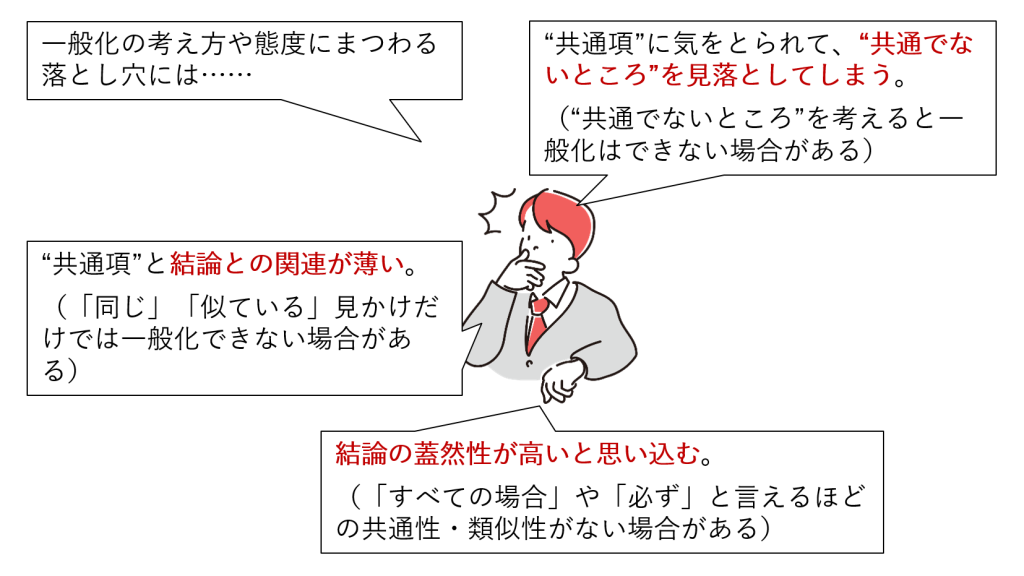
事例の数や偏りの点で問題がなくても、共通項から結論を引き出す際の考え方や態度にも落とし穴はあります。
いずれも、共通点/類似点に対して相違点への注目が相対的に弱まってしまうところからはまる落とし穴と言えます。
キャリアX社のAndroidスマートフォンA, B, C, D, Eがあるとして、
- (1)共通点や類似点にばかり注意が向いて、相違点を見落とす。
「A, B, C, D, EはAndroidスマートフォンだから同じだ」と考える類です。
(ハードウェアスペックもUI回りも違っている、etc.) - (2)共通点や類似点と結論する性質との関連が薄い。
A, B, C, Dで同じ故障が起こっていることから「Eでも同じ故障が起こるだろう」と考える類です。
(見かけの共通点/類似点に引っ張られて結論に飛びついてしまう、etc.) - (3)結論の蓋然性を過度に見積もる。
A, B, C, D, Eすべてで試したことから「この故障はすべてのAndroidスマートフォンで起こる」と考える類です。
(事例の多さや傾向の偏りのなさなどから、結論が必ず正しいと考える、etc.)
(実は権限設定に問題があり、使用したスマホで同じ権限設定のミスをしていたためだった……などの可能性もあります)
統計的帰納で気をつけたいこととしては、
的外れな一般化といったものがあります。
よく起こりがちなものは、事例の数を割合と同一視してしまう(または置き換えてしまう)、というものです。
続きを読むにはログインが必要です。
ご利用は無料ですので、ぜひご登録ください。








