はじめに
こんにちは。Game Platform DevのDong Hun Ryoo、Takenaka、Zhang Youlu(Michael)、Hyungjung Leeです。私たちの組織は、ゲームパブリッシングに必要なさまざまな機能を開発・運用する役割を担っています。
私たちは最近、組織内の業務効率を高めるためにさまざまなLLM(large language model)アプリケーションを開発し、それと連携してLLMOpsシステムの構築プロジェクトを行いました。プロジェクトの主な目標の一つは、参入障壁が高いLLMアプリケーション開発を、職種に関係なく誰でも簡単に作成できる環境を構築することでした。そのため、さまざまなことを考えながら試行錯誤を経た結果、誰でも簡単にアクセスできる開発・デプロイ環境を整えました。
今回の記事では、LLMアプリケーションの一般的な開発方法と開発プロセスで直面する困難について説明し、それらの問題を解決できる環境を構築するために、私たちがどのように取り組んできたのかを紹介したいと思います。この記事を通じて、LLMアプリケーション開発におけるボトルネックを改善・高度化し、アクセシビリティを向上させるための知見を得ていただければ幸いです。
LLMアプリケーションの開発プロセス
最近、OpenAIのGPTやAnthropicのClaudeのような高性能LLMが容易に利用できるようになり、LLMアプリケーション開発の焦点は、それらのモデルを効果的に活用してサービスを提供する方向にシフトしています。モデルを直接学習させたり、ファインチューニング(fine-tuning)することなく、コスト効率を考慮して商用モデルをそのまま使用しながら、モデルの入力となるプロンプトを構造化し、モデルがそれをよく理解できるようにすることにフォーカスしているのです。
プロンプトは、モデルが実行すべき作業のコンテキストと方向性を示すため、プロンプトをうまく構造化すれば、LLMの性能をさらに向上できます。また、プロンプトは修正が容易であるため、高いコストを払ってモデルを直接修正するよりもはるかに低コストで済むというメリットもあります。このメリットを活かして、開発者はより迅速かつ経済的にモデルの性能を最適化できます。
しかし、LLMアプリケーションが新しいデータに対して適切に回答できるようにする課題は、プロンプトの最適化だけでは解決できません。では、モデルの追加学習なしにその課題をどのように解決できるのでしょうか。
一般的に、このような課題はLLMのいくつかの機能を活用して解決します。LLMは、事前学習されたデータ以外にも、プロンプトに提示された追加情報から即座に情報を生成できます。このような機能をインコンテキスト(in-context)学習と呼びます。インコンテキスト学習の中でも特に、いくつかの回答例を通じてモデルがパターンを学習し、より良い回答ができるようにすることをフューショット(few-shot)学習と呼びます。これを利用してプロンプトに情報を入れると、LLMが新しいデータに対して適切に回答できるようになります。
これでLLMが新しいデータに対して回答できるようになりましたが、インコンテキスト学習とフューショット学習の2つの手法だけでは、新しいデータに対して完璧に対応するのは難しいです。それを補完するために、外部データベースからの適切な追加情報や例などをリアルタイムでモデルに注入して結果を生成する手法であるRAG(Retrieval Augmented Generation)を使用します。
RAGの基本的な仕組みは2つの段階に分けられます。最初は、モデルが理解できる形でデータを埋め込み(embedding)、ベクトル化してデータベースに保存する段階です。次は、LLMにリクエストする際にデータベースにクエリを実行し、質問に似たデータを検索(retrieval)して、その結果をプロンプトに入れる段階です。その結果、インコンテキスト学習を通じて、新しいデータに対してもパターンを認識し、LLMが回答できるようになります。
このようにさまざまな手法を利用してLLMの結果を最適化することを総称してプロンプトエンジニアリングと言います。サービス結果を最適化することなので、LLMアプリケーション開発の要と言えます。プロンプトエンジニアリングは主にLangChainというオープンソースを利用して作業しますが、前述のように良い結果を出すためにさまざまな手法や多くのコンポーネントを使用するため、複雑な作業になります。以下は前述の手法をLangChainを利用して作成した例で、LangChainやRAG、プロンプトエンジニアリングに関する情報を埋め込み、LLMで回答するものです。
LLMアプリケーション開発時に直面する課題
上記のような方法でさまざまなLLMアプリケーションを作成できましたが、開発を進めていく中で多くの課題に直面しました。
その中で一番大きな課題は、前述のLLMアプリケーションコードのように、自然言語プロンプトと静的なPythonコードが同時に存在するということでした。プロンプトは通常、サービスのドメイン専門家が修正しますが、もしプログラミングの知識がない人であれば、コードに直接アクセスしてプロンプトを修正するのは難しいかもしれません。また、プロンプトには通常「{}」のような形式で変数が含まれており、さまざまなケースを考慮してその変数の値を変更しながらテストする必要があります。LLMアプリケーションを通じてのみプロンプトを実行しなければならない場合、変数値の変更のようなプロンプトの変更による結果の変化を個別に確認することは困難です。これと似たような観点で、モデルの種類によってプロンプトの結果が大きく変わることがありますが、モデルを変更しながら結果を確認することが難しい場合、開発が遅れる可能性があります。そして、さまざまなプロンプト作成手法がコード内に分散されていると、ノウハウを共有しにくいという問題も発生します。これらの問題はすべて、プロンプト作成とコードとの依存関係の問題だと言えます。
さらに、開発の観点から見ると、RAGのためのベクトルデータベースとプロンプトチェーン方法は、多くのボイラープレートコードを生成し、開発者がコードを理解するのが難しくなります。また、これらのコードはお互い複雑に絡み合っているため、デバッグにおいても多くの問題を引き起こします。実際、私たちの組織でLLMアプリケーションのPoC(proof of concept)を実施したとき、プロジェクトが膨大になり、管理コストも増加しました。プロジェクトを継続するためには、これらの問題を必ず解決する必要がありました。
課題を解決し、開発プロセスをスピードアップするための3つのアプローチ
私たちは、これらの課題を解決するために3つのアプローチを選択しました。
1つ目は、プロンプトを即座に実行でき、共有できる環境を作ることです。プロンプトはLLMの最も基本的な要素として、最初に管理すべき対象でした。私たちは、ドメイン専門家が問題をすぐに確認できるよう、1つのプロンプトを即座に実行できる環境を作ることにしました。そのため、変数を簡単に指定できるようにし、モデルも即座に選択して実行できるようにしました。また、プロンプトを1つの保存スペースに集め、その共有または再利用が簡単にできるようにすることで、プロンプト作成ノウハウが保存されるように改善しました。
2つ目は、開発にビジュアルスクリプティングを導入することです。プロンプトエンジニアリングに使用するコンポーネントは、ほとんどが再利用可能な要素です。ただし、その関係が複雑で繰り返し呼び出されるため、コードを見ながらどのコンポーネントがどのような関係でいつ呼び出されるのか直感的に把握することは困難です。 私たちはこの問題を解決するために、開発環境にビジュアルスクリプティングを導入して再利用可能なコンポーネントを可視化し、各コンポーネントがどのような結果で呼び出されるのかを視覚化したいと考えました。幸いなことに、私たちと同じような悩みの末にリリースされたさまざまなオープンソースがあり、その中でLangflowをベースにしたビジュアルスクリプティング方式の開発を導入しました(これについては後で詳しく説明します)。
3つ目は、結果を素早く確認できるようにデプロイを簡単にすることです。単一プロンプトについて結果を素早く確認できるだけでなく、LLMアプリケーション内で実際に動作することを素早く確認することも必要ですが、開発者でなければアプリケーションのデプロイが難しいかもしれません。そのため、デプロイ作業をできるだけカプセル化して、ドメイン専門家でも簡単な操作でLLMアプリケーションをデプロイできるようにしました。
では、各アプローチを実際にどのように適用したかを一つずつ紹介します。
1. プロンプトを即座に実行・共有できるPrompt Storeを開発する
私たちは、プロンプトを即座に実行・共有できる環境を作るために「Prompt Store」を開発しました。プロンプトをテストして共有できるPrompt Storeの機能を簡単に紹介します。
プロンプトの作成と編集機能
Prompt Storeの基本的な機能として、ユーザーはプロンプトに名前を付けて保存でき、管理のためにタグを追加することもできます。また、プロンプト内に変数キーを挿入することができ、{}を使って変数が挿入された場合、その値を指定する機能を提供します。
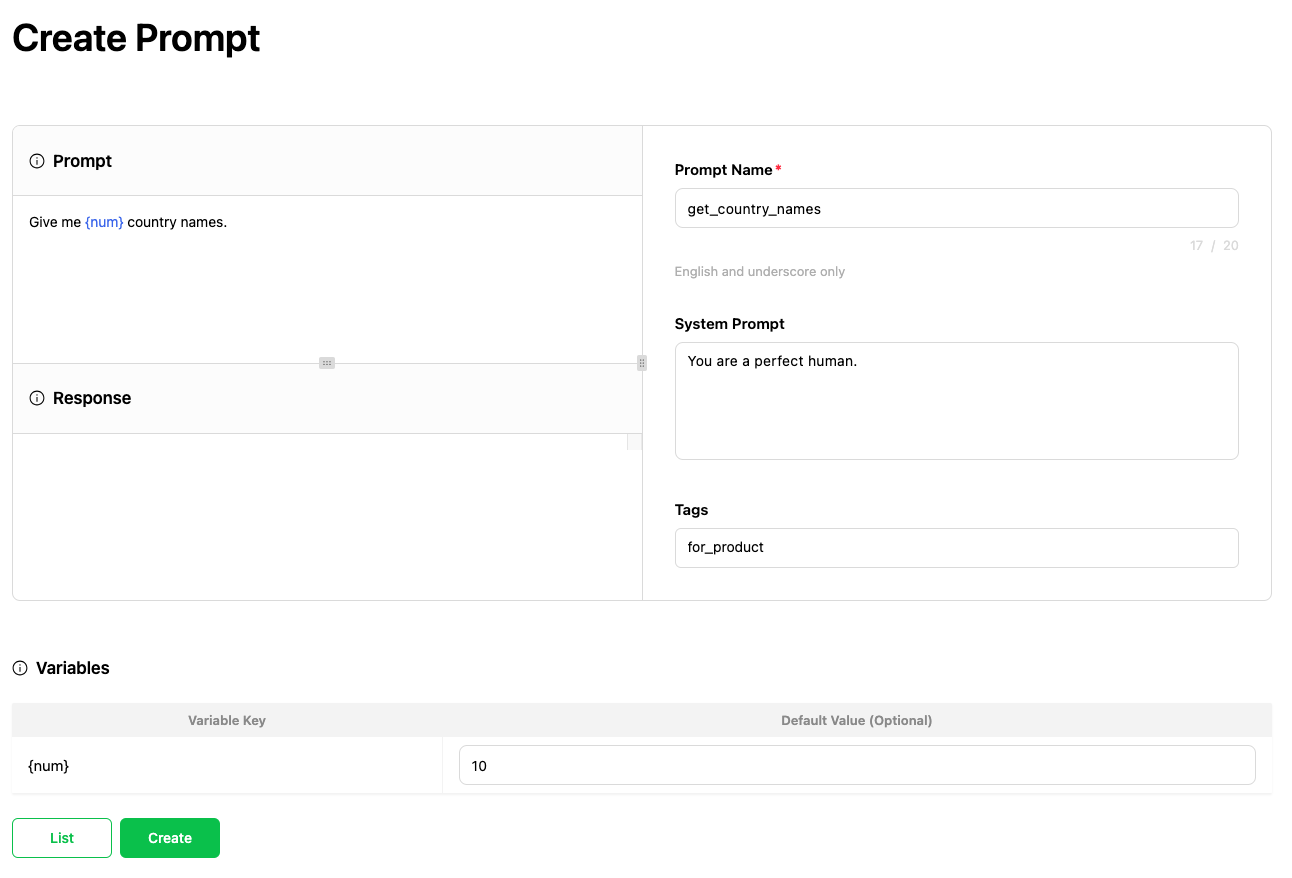
作成したプロンプトは他の人と共有して一緒に管理できます。これにより、プロンプト作成のノウハウを共有したり、すでに作成されたプロンプトを再利用したりできます。
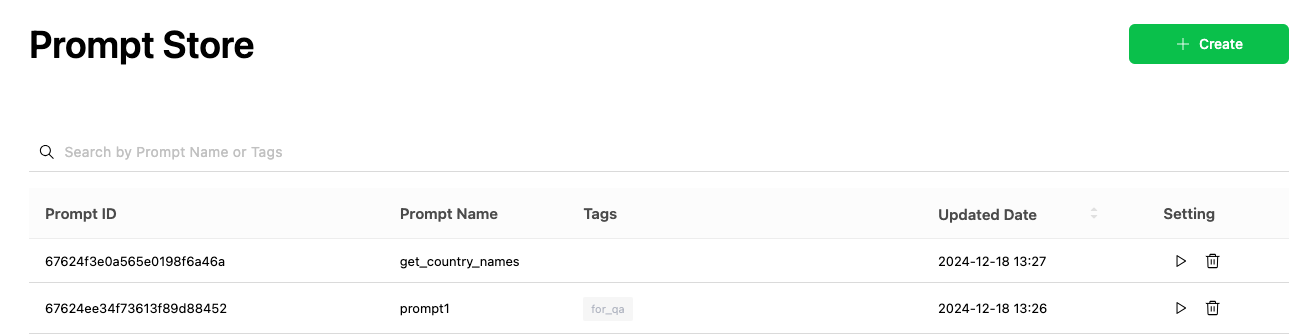
プロンプトをテストできるPlayground機能
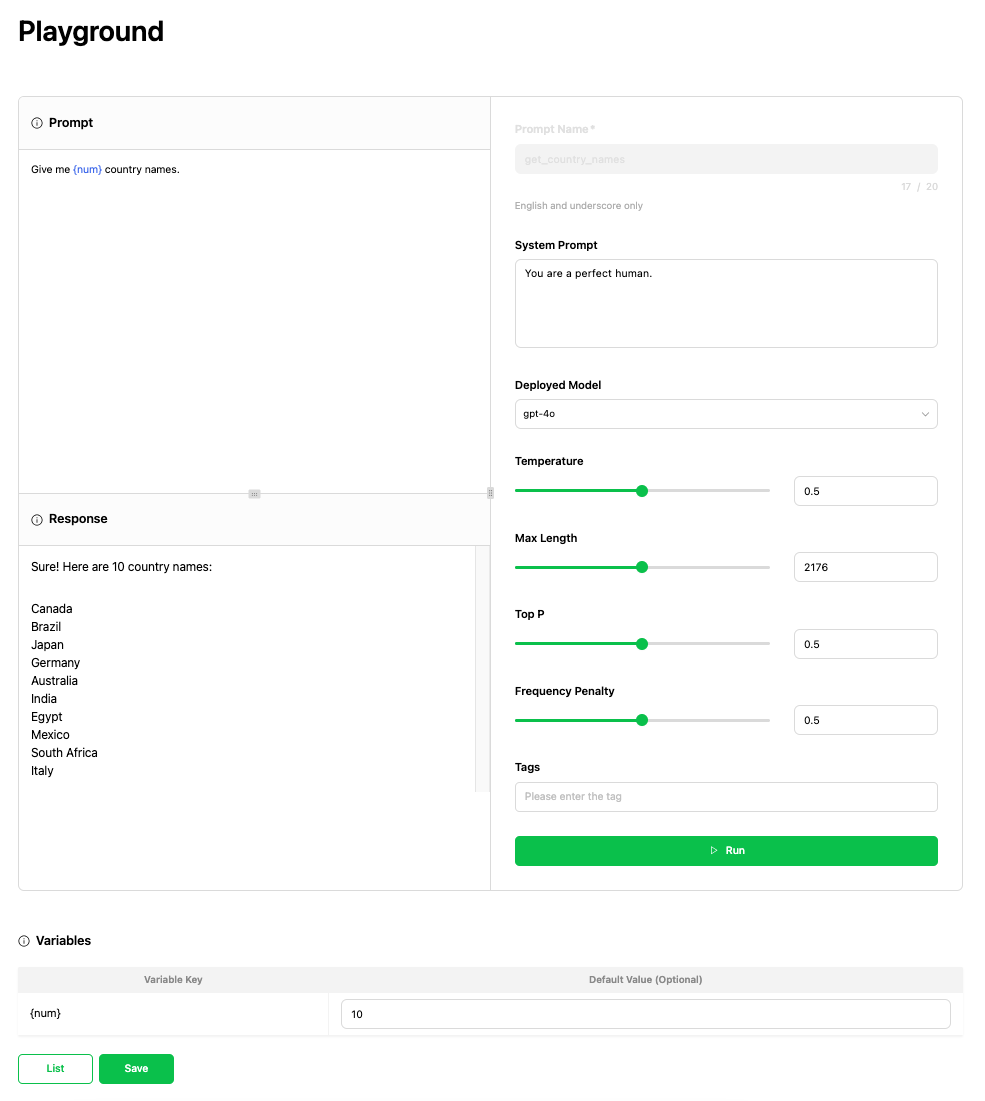
Prompt Storeでは作成したプロンプトをテストできる「Playground」機能を提供します。Playgroundで実行すると、OpenAIのモデルから組織内で作成したカスタムモデルまで選択でき、さまざまな環境で作成したプロンプトの結果をさまざまなパラメータに基づいて確認できます。
プロンプトの再利用機能
Prompt Storeでは、作成したプロンプトをさまざまなコンポーネントで使用できる機能を提供します。これにより、Langflowを利用してアプリケーションを視覚的に開発することや、Harnessを利用してテストする際に最適化されたプロンプトを一貫して使うことができます。
2. Langflowを利用してLLMアプリケーション開発にビジュアルスクリプティング方式を導入する
次に、Langflowを利用してビジュアルスクリプティング方式を開発に導入した方法を紹介します。
Langflowはビジュアルスクリプティング方式で開発できる機能を提供するオープンソースで、複雑なコンポーネント間の関係を簡単に把握できる環境を提供します。私たちはさまざまな方法を検討した結果、Langflowを選択しましたが、その理由は以下のとおりです。
- ドラッグアンドドロップでLLMアプリケーションを作成できる
- プロンプトエンジニアリングやRAGなど、LLMアプリケーション構築に必要な作業を簡単に適用できる
- コンポーネントを再利用できるため、 繰り返しの開発作業を回避できる
- 機能のカスタマイズや新しい機能の追加が簡単にできる
- Pythonベースで、内部プロジェクトと互換性がある
- 短期間で多くの貢献者が参加するため、しっかりとメンテナンスされ、急速に成長しているプロジェクトである
- デプロイ環境を構築しやすい
同じ機能を提供するFlowiseというプロジェクトもありましたが、比較テストした結果、Langflowを選択しました。その理由は以下のとおりです。
- TypeScriptベースのプロジェクトだったのでLangflowの方が互換性が良かった
- UI/UXの面でLangflowの方が良かった
次は、Langflowの使い方や機能、組織内への導入記について紹介します。
Langflowの紹介
Langflowの使い方や機能を簡単に見てみましょう。ちなみに、この記事は1.0.5バージョンをベースに作成しました。Langflowは現在急速にアップデートされているオープンソースプロジェクトなので、みなさんが記事を読むタイミングでは使い方や機能に多少の違いがあるかもしれません。
Langflowを実行してみる
以下の2つのコマンドを実行してLangflowを実行できます。
- インストールする:
pip install langflow - 実行する:
python -m langflow run
正常に実行されると以下のような画面が表示されます。
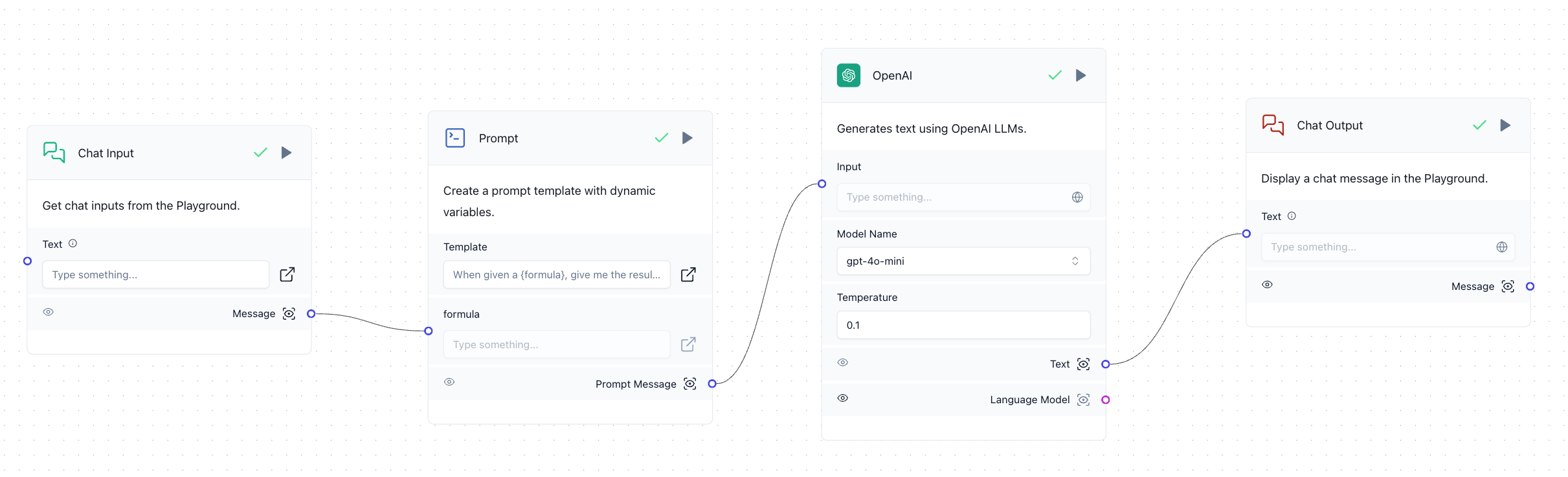
Langflowでは1つのアプリケーションをFlowと呼びます。簡単なFlowの例を見てみましょう。以下はチャットしながらOpenAIのGPTモデルを使って応答を受けるFlowです。「Chat Input」コンポーネントと「Chat Output」コンポーネントの間にOpenAIコンポーネントを配置し、チャットを通じてGPTと会話をやり取りできるように構成しました。
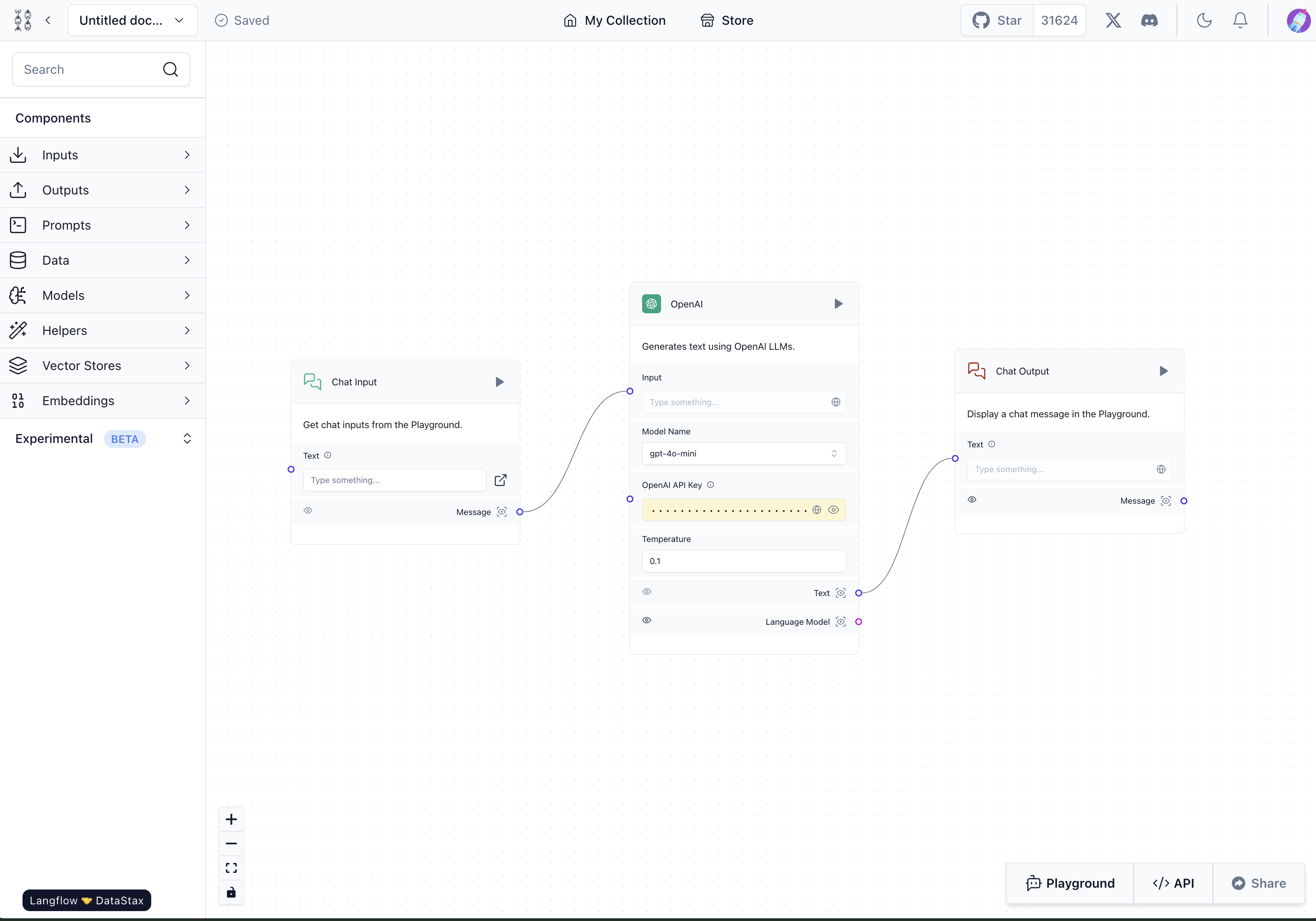
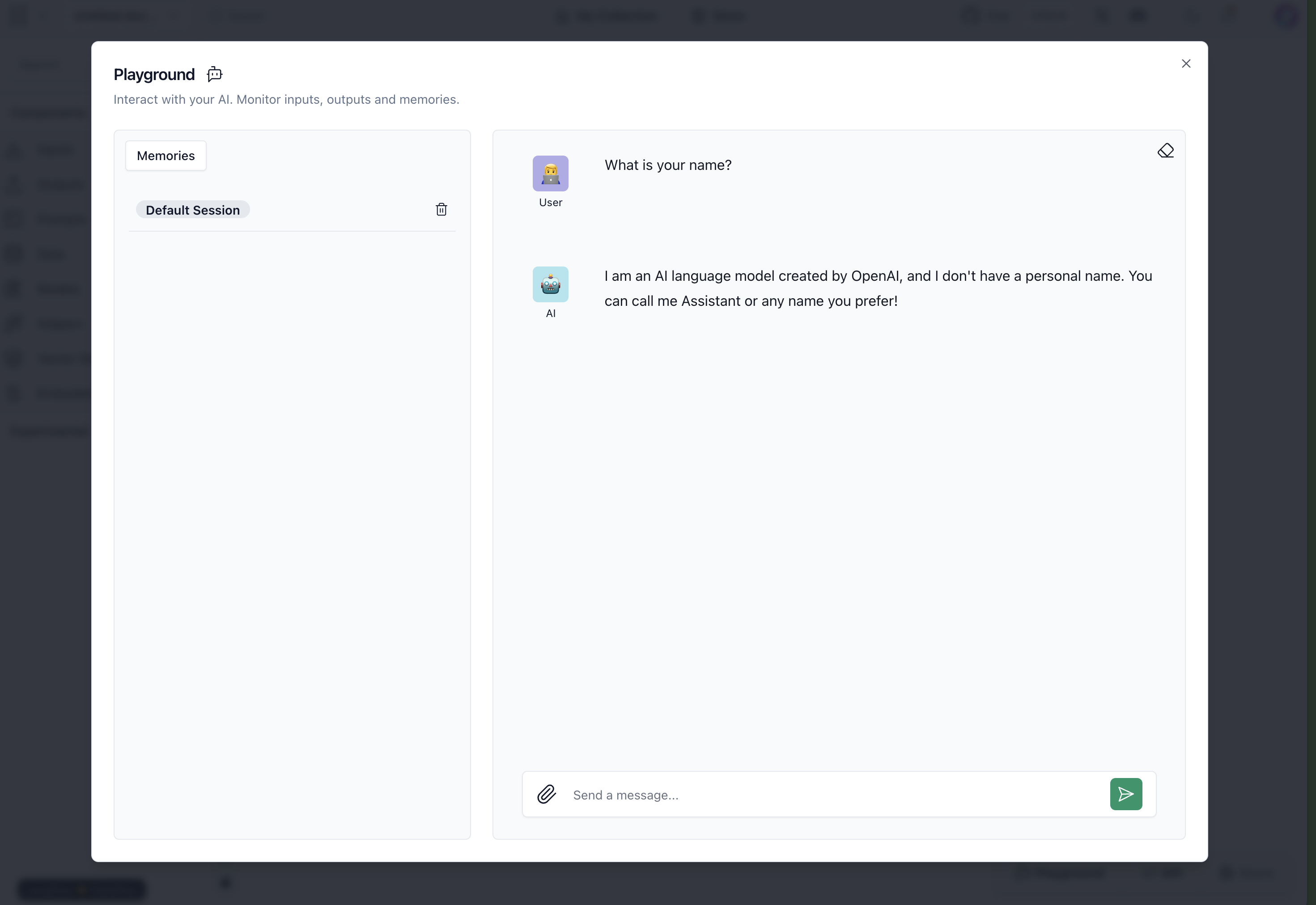
このように構成した後、各コンポーネントの右上にある実行ボタン(▶)や画面右下のPlaygroundボタンを押すと、以下のように作成したFlowが動作します。
Langflowの動作原理
Langflowは公式ドキュメントで動作原理を説明していませんが、動作原理を理解するとLangflowを使う際に、役に立つと思うので簡単に説明します。
前述の例のFlowには、Pythonコードで構成された3つのコンポーネントがあります。
各コンポーネントは、実行前は静的に存在しますが、実行ボタンを押すと、内部的に各コンポーネントが他のコンポーネントに関連する情報と自分のコードをパラメータとしてLangflowのバックエンドAPIを呼び出します。上の画面で線がつながった順番で反復文が実行され、各コンポーネントがビルドされます。このとき、内部的にPythonの組み込み関数execが呼び出され、各コードは動的にメモリに読み込まれて実行されます。
LangflowはFlowの構成情報とFlowを構成する各コンポーネントのコード情報を利用して動的に実行する方式で動作します。このような動作方式のおかげで、UIを利用して自由にコードを修正でき、Flowのデータさえあれば、Langflowのバックエンドロジックを使用してどこでも同じ動作を実行できます。さらに、FlowのデータとLangflowバックエンドの依存関係をパッケージ化してデプロイすれば、LLMアプリケーションを簡単にデプロイすることも可能です。
カスタム機能の作成
Langflowを選択した最も重要な理由の1つは、機能を自由にカスタマイズできることです。以下の簡単な例で見てみましょう。
Langflowのコンポーネントは、それぞれが1つの関数だと考えると分かりやすいです。上記のコードのように入力パラメータと出力パラメータを定義し、parse_json_markdown_to_strのようなメソッドを定義すればいいです。それ以外の形式は自由なので、アイデアさえあれば、カスタム機能を簡単に実装できます。
このように構成したカスタムコンポーネントは、UIから直接コードを修正して作成できます。また、再利用したい場合は、Langflowを使うプロジェクトにカスタムコンポーネントを集め、以下のように--components-pathにカスタムコンポーネントが定義されているフォルダ名を指定すればいいです。
カスタムコンポーネントについてより詳しくは、Langflowカスタムコンポーネントの公式ドキュメントを参照してください。
Langflow導入記
Langflowの導入にあたり、私たちの要件を満たすためにいくつかの方法を適用しました。
Langflowのリポジトリをフォークして使う
前述のようにLangflowは、現在急速にアップデートされているオープンソースプロジェクトとして、着実に新しい機能が追加されており、新しいプロジェクトであるため、内部で大小のバグが引き続き発見されています。また、既存の機能の一部は私たちの組織に合わせて、一部変更して使用したいというニーズもありました。このような状況を考慮して、私たちはLangflowプロジェクトを内部でフォークして使用することにしました。ただし、そうすると、今後バージョンをアップグレードするときに衝突が発生し、メンテナンスが難しくなるリスクが大きいため、以下のような原則を立てました。
- Langflow自体のコードを変更することはできるだけ避ける
- 内部要件を満たすためにLangflowコードに新しい機能を追加することが避けられない場合、できるだけ既存のコードと衝突しないように作業する
- バグのためコードを修正する必要がある場合、まず、最新バージョンに修正されているかどうかを確認し、バージョンを上げることの優先度をより高く設定する
カスタムコンポーネントを使って共通で使用できる機能を実装する
今回Langflowを導入して感じたのは、Langflowはまだ実際の業務で使うのは難しいということがわかりました。それよりは、個人的にLLMアプリケーションを実装してみたい場合、簡単に使うレベルのプロジェクトだと感じました。そのため、実装されているものの、実行してみたら動作しない機能もあり、当然あるはずの機能がまだ実装されていない場合もありました。
前述でLangflowを選択した理由の一つは、カスタマイズ機能を自由に実装できることだと言いましたが、私たちはそのメリットを活かして、現在Langflowで提供されていないが必要な機能や、性能が不足している機能を独自開発しました。そのうち、2つのコンポーネントを例として紹介します。
Flow Runner
一つ目は「Flow Runner」です。以下は私たちが独自開発したFlow RunnerのUIです。
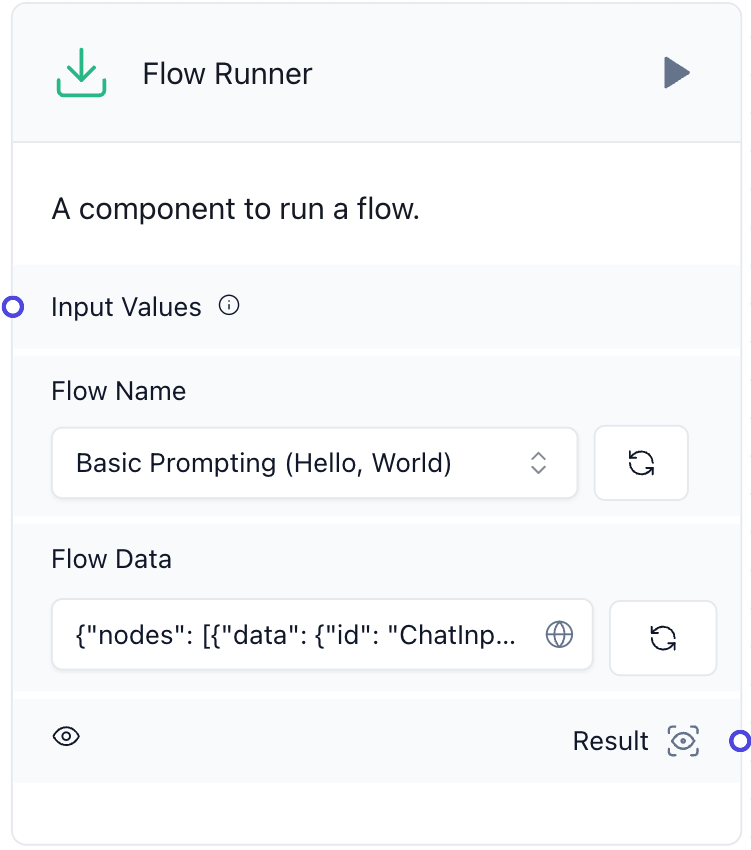
Langflowでは、複数のFlowを作成してそれぞれを実行することはできますが、相互に連携して実行する機能はサポートされていませんでした。そのため、同じ機能を複数のFlowに繰り返し追加する必要がある場合や、Flowが大きくなりすぎて理解しにくくなる場合が発生しました。これらの問題を解決するために、1つのFlow内で他のFlowの実行、または繰り返し実行ができる機能を実装しました。この機能は、1つのFlowで他のFlowの内部ロジックを呼び出す方法で動作します。
Prompt Store
2つ目は前述で紹介したPrompt Storeです。以下は私たちが開発したPrompt StoreコンポーネントのUIです。
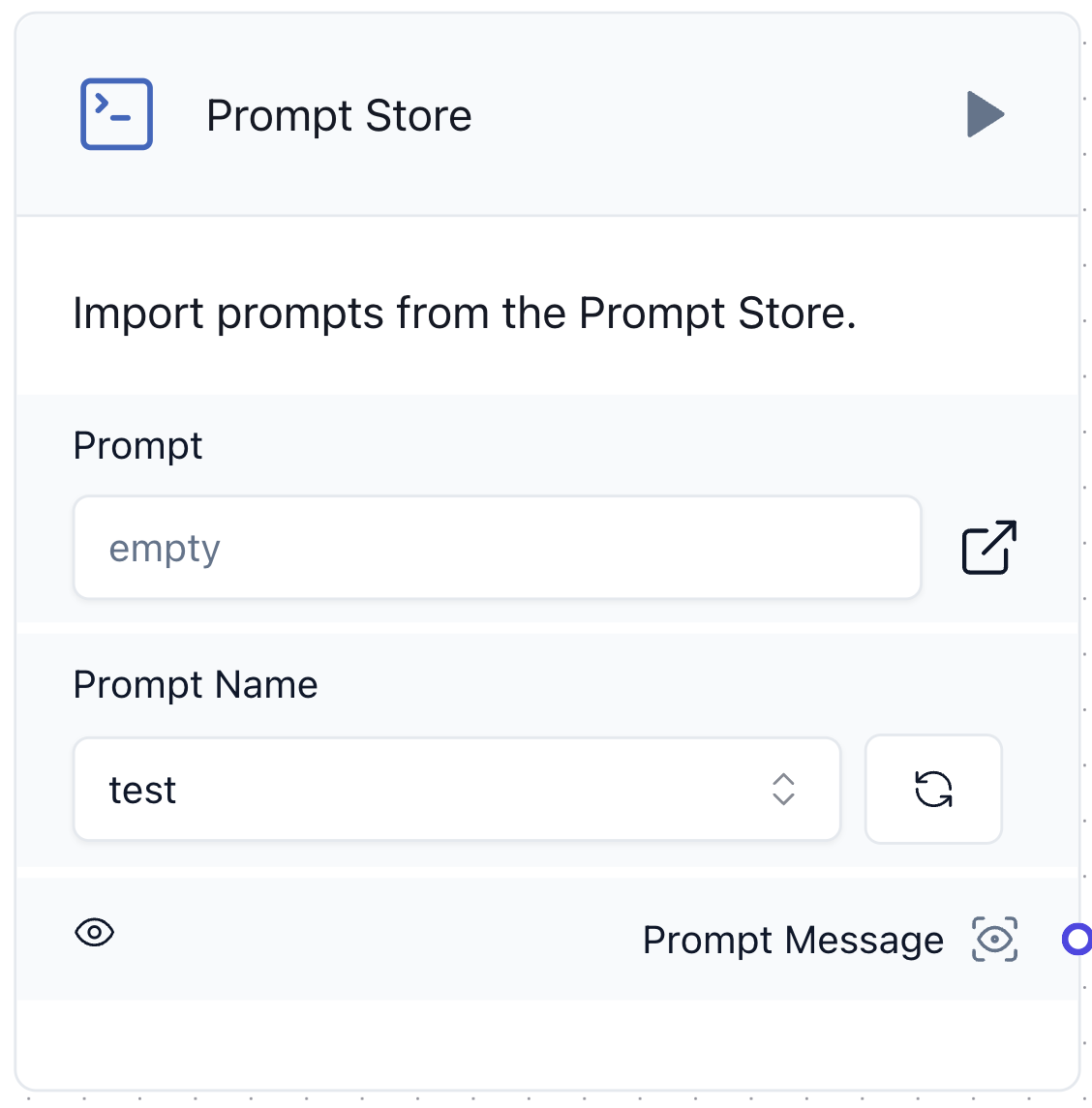
既存のプロンプトコンポーネントは、その都度プロンプトを直接入力する必要があり、LLMアプリケーションの中核であるプロンプトの再利用が困難でした。そこで、以下のようにDBからプロンプトを取得するPrompt Storeコンポーネントを開発しました。
カスタムコンポーネントを簡単に適用し、デプロイするための構造設計
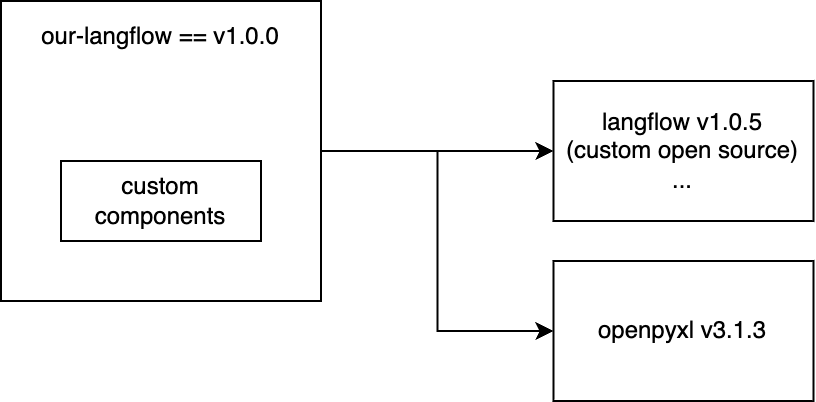
カスタムコンポーネントを効果的に使うためには、Langflowを使うプロジェクトにそのコンポーネントのコードが定義されている必要があります。LangflowのUIで直接コードを追加してカスタムコンポーネントを作成することもできますが、これでは1回限りの使用となり、再利用ができません。そのため、再利用性を考慮してカスタムコンポーネントを定義するのが一般的です。また、カスタムコンポーネントを使用するには、Langflowに依存するプロジェクトで実装する必要があることに加えて、新しい機能に必要な新しい依存関係(例:openpyxl)も考慮する必要があります。このような状況で考えられる構造は以下のダイアグラムのようなものです。
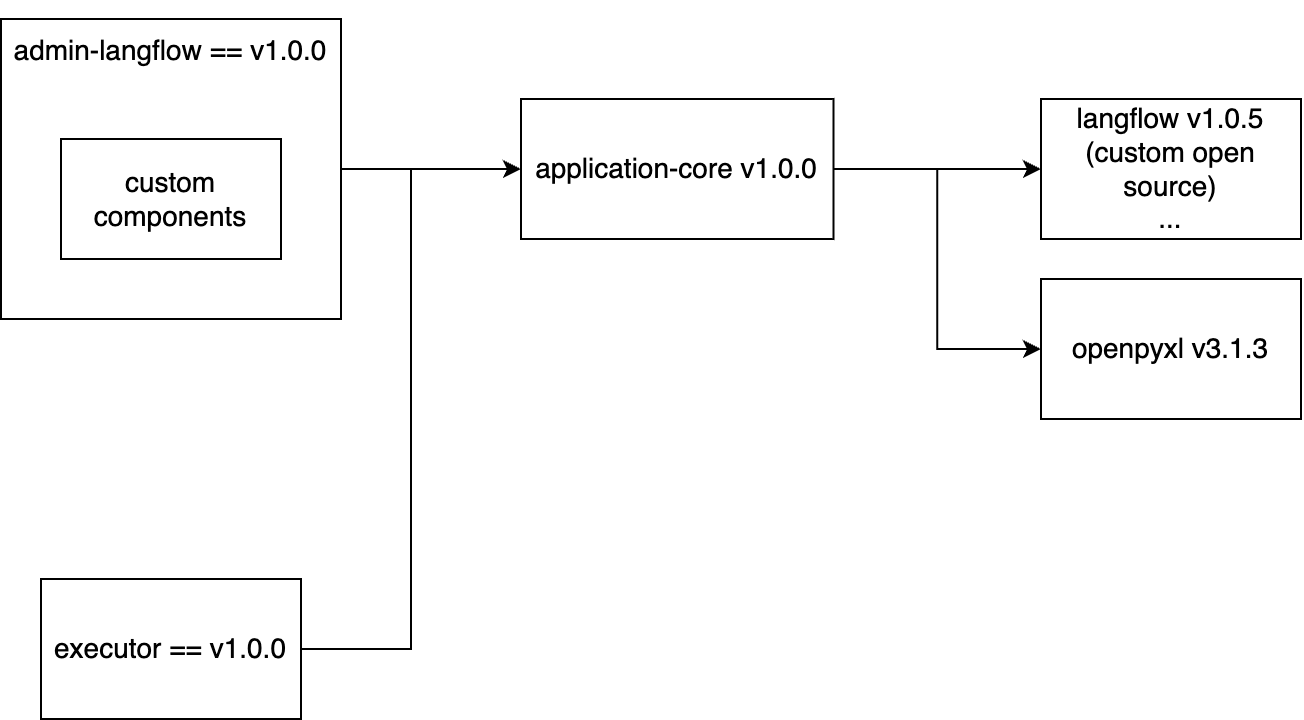
私たちは2つのモジュールが必要でした。1つはFlowを編集できるLangflow UIモジュールで、もう1つはFlowを実行してユーザーにLLMアプリケーションとして提供するモジュールです。このとき、両方のモジュールはLangflow v1.0.5とopenpyxl v3.1.3に該当する依存関係を共通に持つ必要があります。そのため、私たちは共通の依存関係を管理する「application-core」という名前のモジュールを間に配置しました。そして、管理者用モジュールを「admin-Langflow」、実際にLLMアプリケーションを実行するためのユーザー用モジュールを「executor」と定義して以下のような構造で設計しました。
3. LLMアプリケーションを簡単にデプロイできるシステム構築する
私たちは、LLMアプリケーションの結果を素早く確認できるように、簡単にデプロイできるシステムを構築しようとしました。しかし、現在のLangflowは個別インスタンスでデプロイできる機能が十分に構築されていないため、既存の機能を拡張しました。以下のようにLangflowでFlowを作成し、管理者ページでデプロイボタンをクリックするだけでデプロイできるようにしました。このデプロイボタンをクリックするだけで、LLMアプリケーションを他のサービスと連携できるAPIインスタンスが作成されます。

これを導入した結果、デプロイとフィードバックサイクルが短縮され、LLMアプリケーション開発において発生するボトルネックをかなり解消できました。
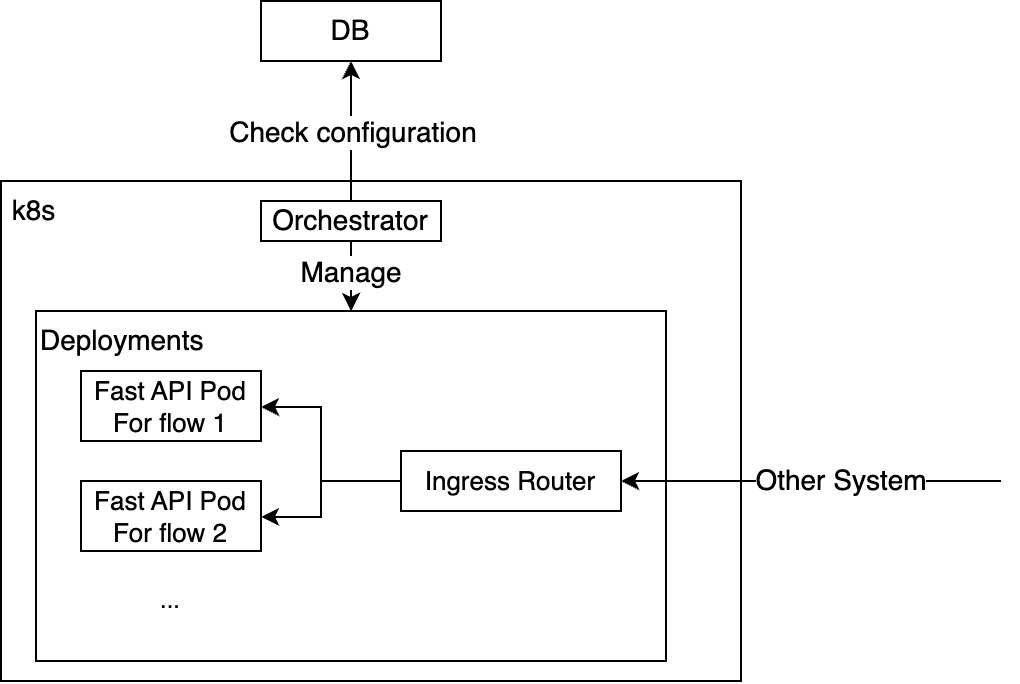
デプロイメント構造
デプロイメントはオーケストレーターコンポーネントが管理します。このコンポーネントは、データベースにアクセスしてFlowを読み込み、Kubernetes APIを使用して該当デプロイメント(deployment)を作成します。デプロイされたFlowごとに1つのポッド(pod)が作成されますが、ポッドを共通ドメイン名のサブパスにマッピングして、すぐにLLMアプリケーションのAPIを呼び出せるように設定しました。
実際のポッド内部では、各Flowを以下のようにJSON形式でロードし、ユーザーからの入力を受けて実行されます。このように、ユーザー入力をFlowのチャット入力コンポーネントの入力として処理し、必要に応じていくつかのパラメータを修正した後、最終的にチャット出力を返すようにすることで、ユーザーが作業環境で定義したFlowを実際のデプロイ環境でも同じく呼び出せるようにしました。
3つのアプローチを導入した結果
前述で説明した設計通りにプロジェクトを構成し、活用可能なさまざまな機能をLangflowに追加して、内部的にさまざまな目的でLLMアプリケーションを作成できる環境を構築しました。例えば、数式が入力されると結果を返すFlowを1つ作って管理者機能としてデプロイすると、Kubernetes環境にデプロイされます。
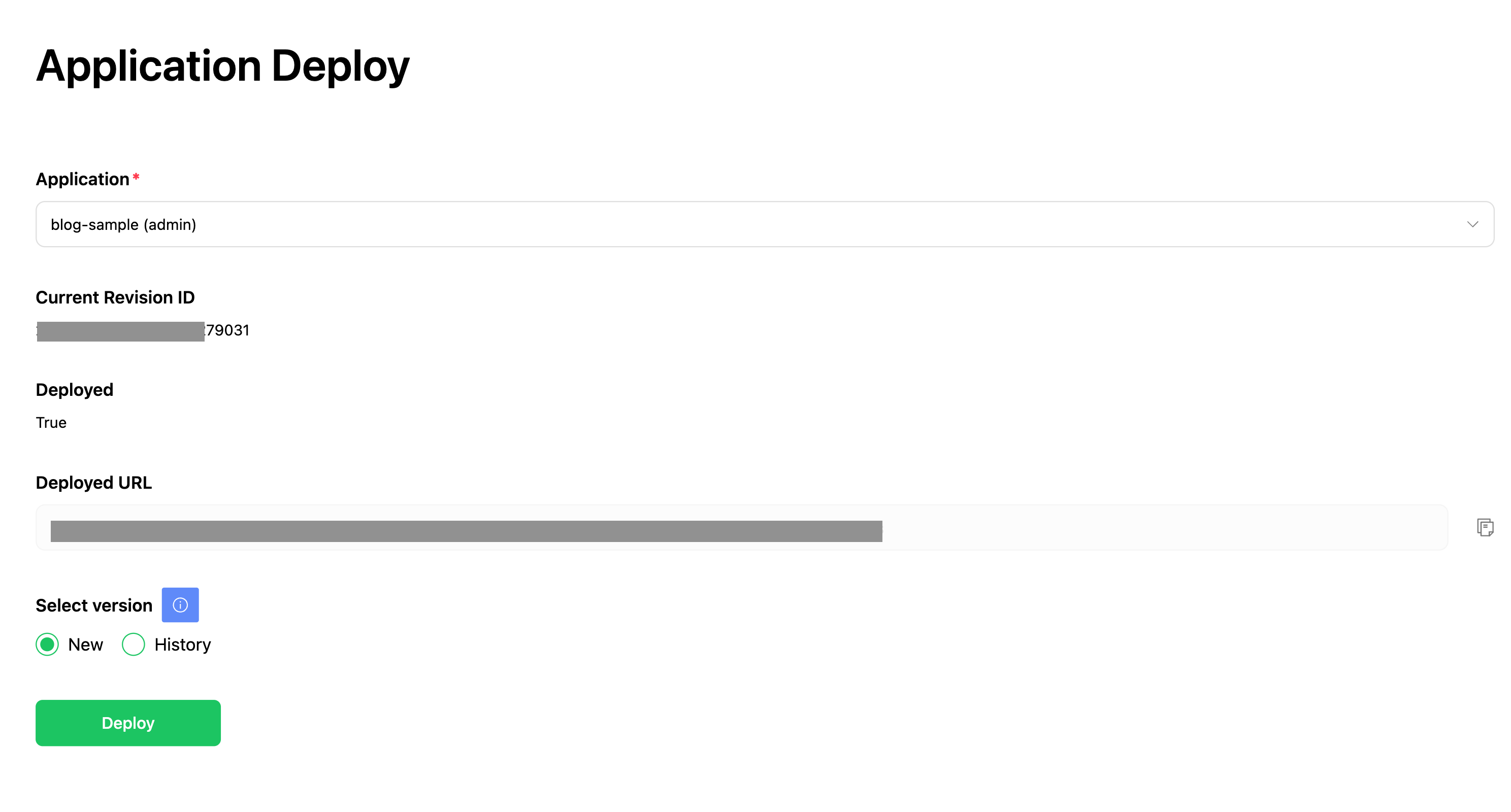
これをSlackアプリと連携し、以下のようにSlackアプリから呼び出して目的の結果を得られるようにしました。
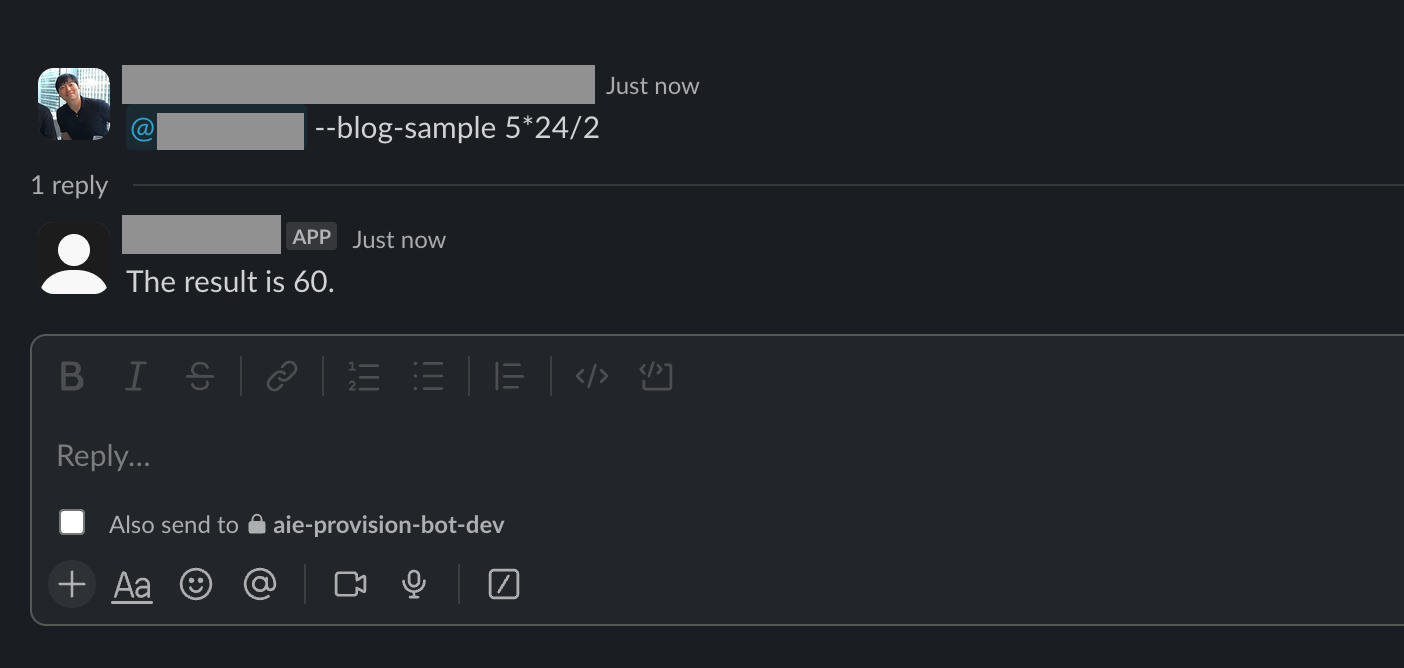
このように簡単に作成・デプロイできる環境を構築した結果、現在、私たちの組織では職種に関係なく、多くのメンバーが業務に必要なLLMアプリケーションを自分で作ってデプロイまでできるようになりました。
おわりに
ここまで、職種に関係なくLLMアプリケーションを簡単に作成・デプロイできる環境を構築する過程で直面した課題と、その課題を解決した方法について説明しました。この作業を通じてLLMアプリケーションの作業サイクルを短縮でき、これにより、アプリケーションの結果の改善により多くの時間をかけられるようになりました。この記事が、私たちと同じような課題を抱えている方に少しでもお役に立てれば幸いです。長文でしたが、読んでいただきありがとうございました。