
目次
はじめに
このブログの目的 (と、ごあいさつ)
こんにちは。SREの gumamon です!
最近、Kubernetesを使う現場がどんどん増えてきました。
Kubernetesは自律的にいろいろ動いてくれる分、「今なにが起きているのか」を把握するのが意外と難しいです。
特に、構成が動的に変わるKubernetesでは、サービスディスカバリ機能のある監視ツールが欠かせません。
そんな中で、Kubernetesのメトリクス監視といえば、今やPrometheusがデファクトスタンダードです。
このブログでは、PrometheusがどのようにKubernetesの情報を集めているのかを、ハンズオン形式で体験しながら理解していきます。
「とりあえず動かして理解したい!」という方は、ぜひ一緒に試してみましょう!
対象読者と前提知識
本記事は、Prometheusの初学者を対象としています。
「これからPrometheusを触ってみたい」「仕組みを理解しながら学びたい」といった方に向けて、基本的な概念や構成をハンズオン形式で解説していきます。
ハンズオンの内容を円滑に進めるために、以下の知識・環境を前提としています:
- Kubernetesの基本的なコンポーネント(Pod、Service、Nodeなど)についての理解
- 本記事では詳細なKubernetes解説は行いませんが、基礎的な用語を把握していることが望ましいです。
- Kubernetes自体を構成するコンポーネントについても概要を把握できていると理解がスムーズです。
- Dockerの実行環境が手元にあること(必須)
- ハンズオンでは kind (kubernetes in docker)を用いて仮想的なkubernetes環境を構築します。
- 実行環境はLinuxが推奨ですが、MacやWSL(Windows Subsystem for Linux)でも問題ありません。
Prometheusとは
Prometheusの概要
Prometheusは、CNCF(Cloud Native Computing Foundation)によってホストされている、オープンソースのモニタリングツールです。
もともとはSoundCloud社によって開発され、現在ではクラウドネイティブな監視基盤として広く採用されています。
主な用途は、メトリクス(数値データ)ベースの監視です。対象となるシステムからメトリクスを定期的に収集し、それを時系列データとして保存・可視化・アラートの発火などに活用します。
特徴的なのは、Prometheus自身が監視対象にプル型でアクセスし、HTTPエンドポイントからメトリクスを取得する点です。この仕組みにより、監視対象を柔軟に検出・更新できるため、構成が頻繁に変化するKubernetesとの相性が非常に良くなっています。
また、Prometheusは専用のクエリ言語「PromQL」を備えており、柔軟な集計・フィルタ・可視化が可能です。Grafanaなどの可視化ツールと組み合わせることで、強力な監視ダッシュボードを構築することができます。
参考:Prometheus/OVERVIEW/What is Prometheus?
Prometheusの特徴と強み
Prometheusには、Kubernetesをはじめとするクラウドネイティブな環境に適したさまざまな特徴があります。以下に、代表的な機能や強みを紹介します。
プル型によるメトリクス収集
監視対象に対してPrometheusが定期的にアクセスし、HTTPエンドポイントからメトリクスを取得します。これにより、構成変更に強く、柔軟な監視が可能になります。サービスディスカバリとの統合
KubernetesやConsulなどと連携し、監視対象を自動で検出・更新することができます。Kubernetesのように動的に変化する環境と特に相性が良いです。シンプルなメトリクス形式(テキストベース)
メトリクスは人間が読めるテキスト形式で提供されるため、開発者や運用者が直接確認・デバッグしやすいという利点があります。強力なクエリ言語(PromQL)
メトリクスの集計やフィルタ、演算を柔軟に記述できる専用のクエリ言語が用意されており、複雑な条件での監視や可視化も対応可能です。豊富なExporterエコシステム
OSやミドルウェア、クラウドサービスなどを対象とした多数のExporterが公式・非公式に提供されており、必要な監視対象をすぐにカバーできます。
また、独自アプリケーション用のExporterも容易に作成できるため、カスタムメトリクスの取り込みも柔軟に対応できます。Grafanaとの親和性
PrometheusのデータソースはGrafanaで広くサポートされており、グラフやダッシュボードを簡単に構築できます。Alertmanagerによるアラート機能
条件を満たすメトリクスに対してアラートを発火し、メールやSlackなどに通知することができます。アラートのグルーピングや抑制も可能です。軽量かつ単一バイナリで動作
インストールや構成が比較的簡単で、導入のハードルが低い点も魅力です。
NOTE
ハンズオンでは以下のExporterを使用します
kube-state-metrics:
Kubernetesリソース(Pod、Deployment、Nodeなど)の状態情報をメトリクスとして提供するExporterです。クラスター全体の構成や状態を把握するために利用されます。node-exporter:
各ノードのCPU使用率、メモリ、ディスク、ネットワークなど、OSレベルのハードウェア/システムメトリクスを収集するExporterです。
ハンズオン環境を構築しよう
ハンズオン環境の説明
本ハンズオンでは、以下のGitHubリポジトリを使用します:
以下は、最終的に構築される環境の構成図です:
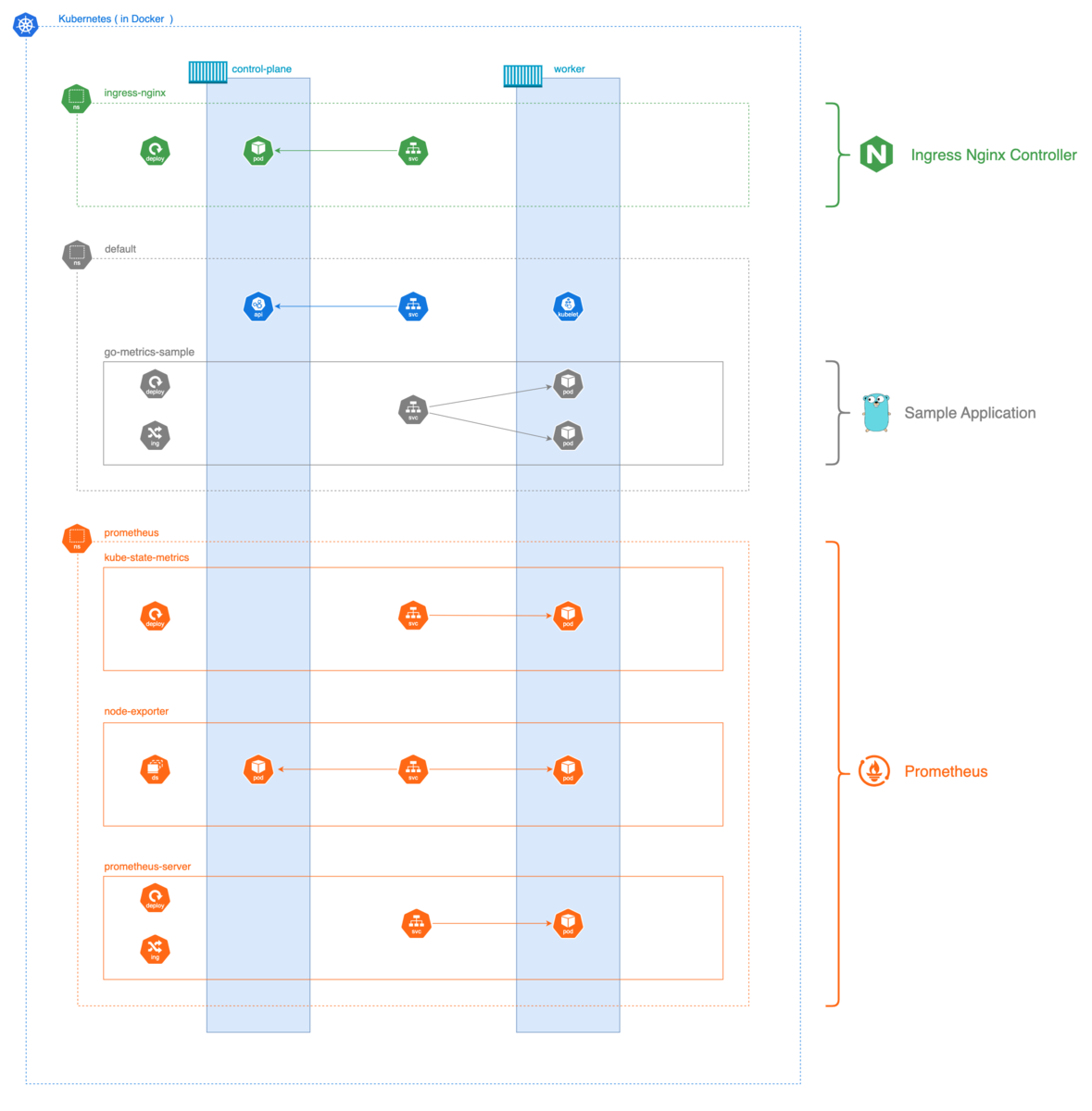
構成図の補足
- Kubernetesクラスタは
kindによりDocker上に構築されています - Ingress NGINX Controller により、ローカルからのアクセスが可能です
- サンプルアプリケーション(go-metrics-sample)がメトリクスを提供します
- Prometheusは3つのコンポーネントで構成されています:
prometheus-server: メトリクスの収集・保存・提供を行う本体node-exporter: 各ノードのハードウェア/OSメトリクスを提供kube-state-metrics: Kubernetesリソースの状態をメトリクス化
- 各ExporterはPrometheusにより自動的に発見・監視されます
構築手順
1) ハンズオン環境のGitHubリポジトリをローカルにcloneしてください:
git clone https://github.com/gumamon/test-prometheus.git
2) v0.1.1にcheckoutしてください
git checkout v0.1.1
3) リポジトリ内のREADME/Getting Started に従って構築してください:
NOTE
このリポジトリは、Kubernetes(kind)上にPrometheusとExporter、サンプルアプリケーションをデプロイし、監視の基本を体験できる構成になっています。 構築には docker, kind, helm, helmfile を使用します。
Prometheusを触ってみよう
無事にハンズオン環境は構築できましたか?早速Prometheusを触っていきましょう!
PrometheusのWeb UIを開いてみる
Prometheusをデプロイすると、Web UI を通じて現在の状態や収集したメトリクスを確認することができます。
ブラウザで以下のURLにアクセスしてください:
NOTE
このドメインは、ハンズオン環境に構成されたIngressによってローカルにルーティングされています。名前解決がうまくいかない場合は、/etc/hostsにエントリを追加してください。
PrometheusのWeb UIでは、次のような情報を確認できます:
- ステータス情報(Targets、Configuration など)
- 現在のメトリクス一覧
- PromQLクエリの実行結果
- アラート状態(Alertmanagerと連携している場合。※今回は連携していません。)
収集したメトリクスを確認してみる
Web UIが開けたら、まずは [Query > 右上の「︙(三点リーダー)」メニュー > Explore metrics] を開いて、現在のメトリクス一覧を確認してみましょう。
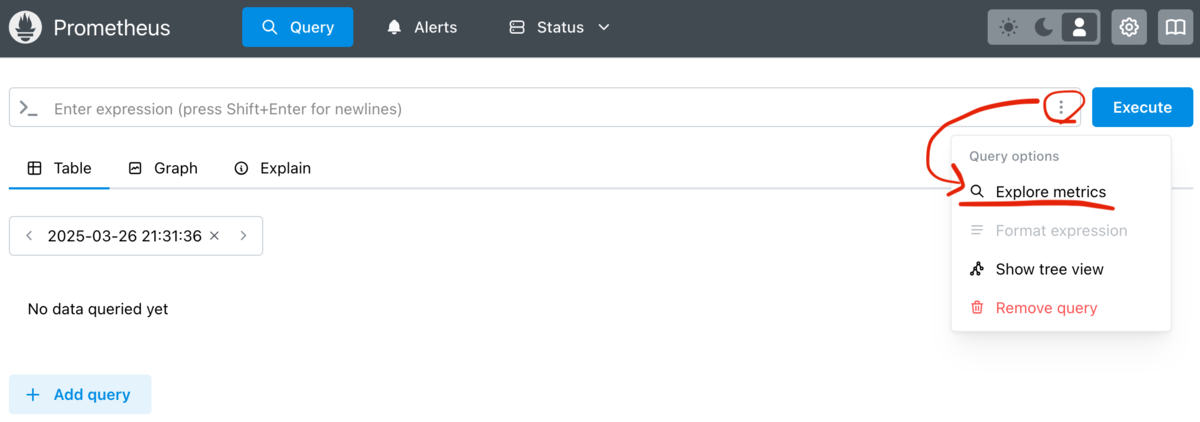
以下のようにMetricのリストが出力されているはずです。
これが現在Prometheusが収集しているメトリクスの一覧になります。
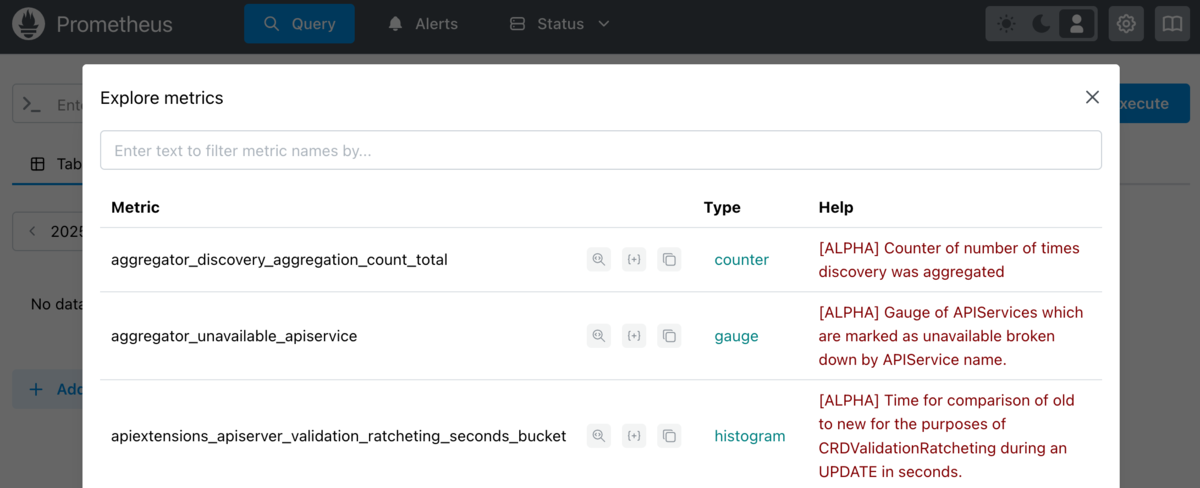
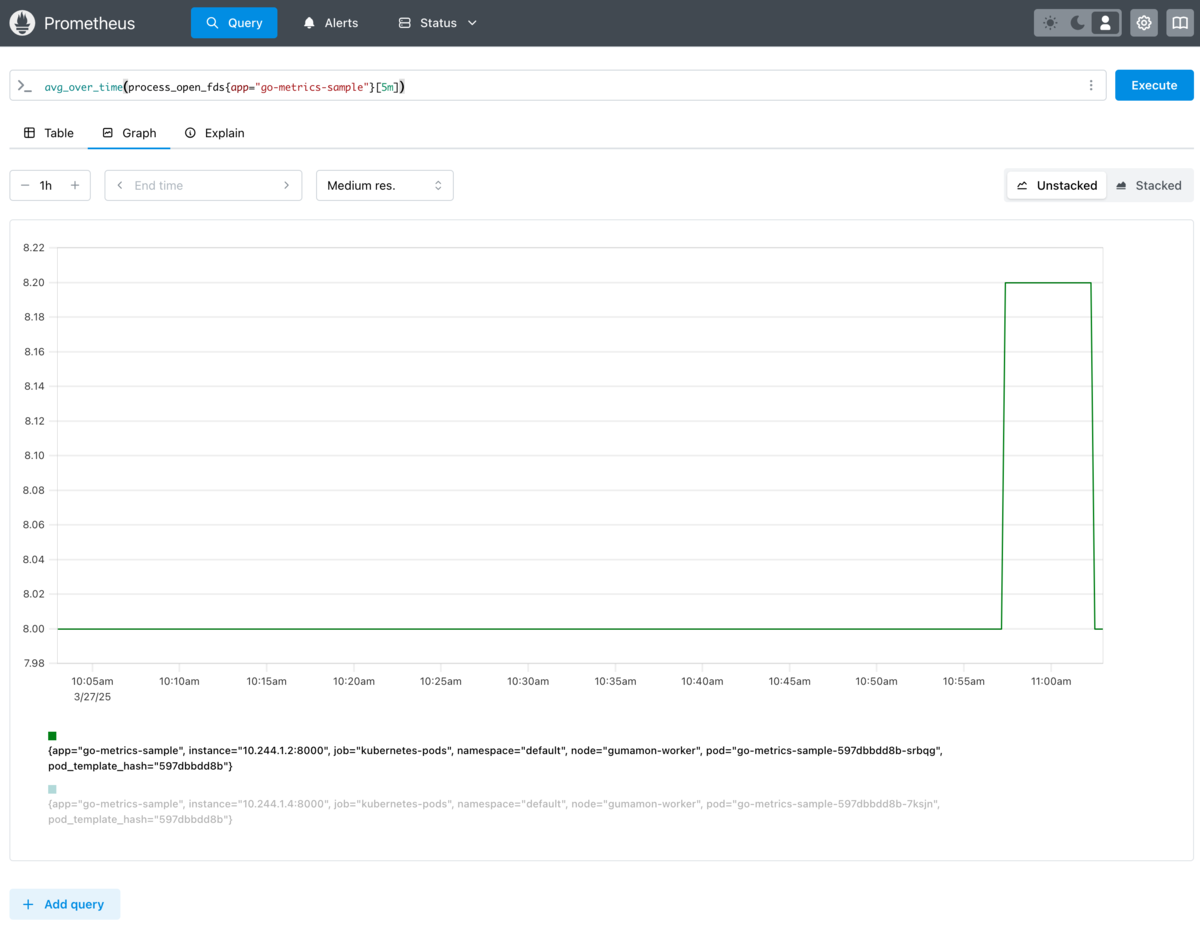
次に、PromQLを使って実際にメトリクスをグラフ化してみましょう。
ここでは例として、各ノードのCPU使用率を確認してみます。
1) PrometheusのWeb UI上部にある [Graph] タブを開きます
2) クエリ入力欄に以下のPromQLを入力します:
rate(node_cpu_seconds_total{mode="user",node="gumamon-worker"}[5m])
3) [Execute] ボタンをクリックすると、下部に数値が表示されます
4) 表示形式を [Graph] に切り替えることで、CPU使用率の推移をグラフで確認できます
NOTE
上記のクエリは、5分間隔でCPU使用時間の変化量を示すもので、対象を以下条件で絞り込んでいます。
mode="user"によってユーザーCPU時間を対象にしています。node="gumamon-worker"によってWorker Nodeを対象にしています。- グラフが4本あるのは
cpu={0,1,2,3}があるためです。
- Dockerを通じてローカル環境のCPUコア数が透過的に見えています。
このように、Prometheusではクエリを使って詳細なメトリクス分析が可能です。
必要に応じて条件を絞ったり、集計関数を組み合わせたりして、柔軟な監視が行えます。
Prometheusによる監視の全体像をつかもう
Exporterが収集する情報の流れ
Prometheusの概要で述べたとおり、Prometheusは監視対象にプル型でアクセスし、HTTPエンドポイントからメトリクスを取得します。
早速どのようなHTTPエンドポイントから情報を収集しているかを確認してみましょう。
収集先のエンドポイントを確認する手順
1) PrometheusのWeb UIにアクセスします:
2) 上部メニューから [Status > Target health] をクリックします
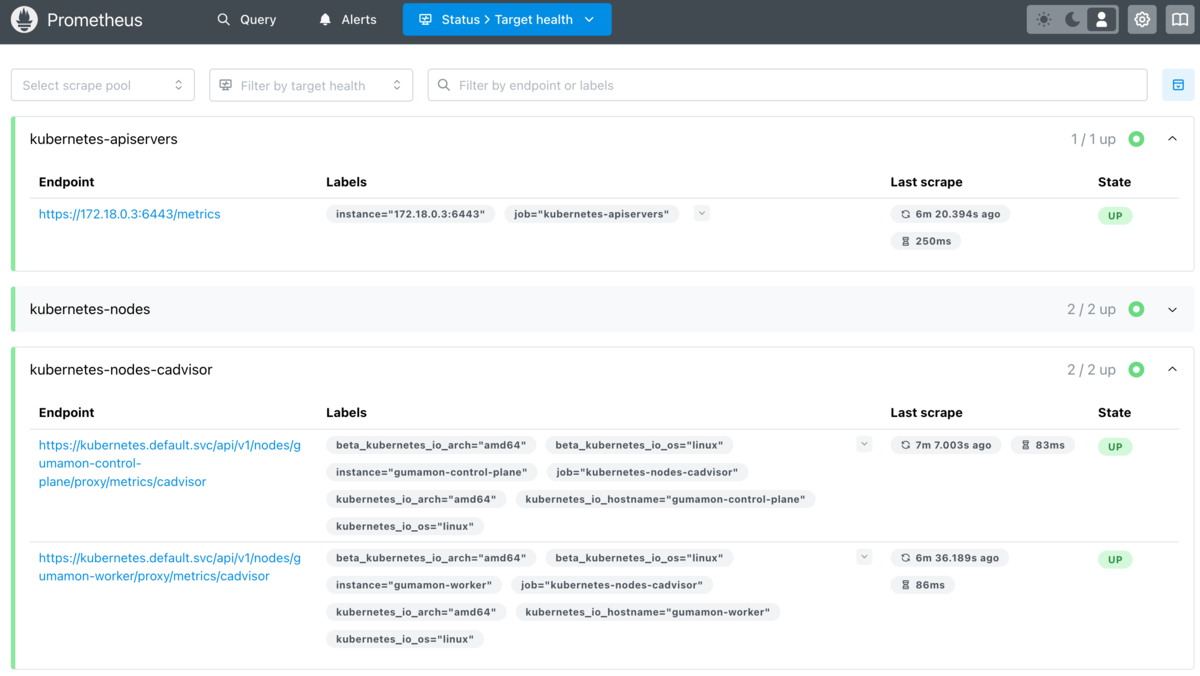
3) Targets画面では、現在Prometheusが監視している各エンドポイントの一覧が表示されます。
ここには以下のような情報が含まれます:
- Exporterのラベル名(job名)
- 対象のエンドポイント(IPアドレス:ポート)
- 現在のステータス(UP / DOWN)
- 最終スクレイプ時刻やレスポンスタイム
NOTE
本来、Endpoint のリンクをクリックすると、実際にそのExporterが提供している生のメトリクス(テキスト形式)をブラウザで確認することができるのですが、ハンズオン環境では閲覧することができません。
Endpointはprometheus-serverがKubernetesの中から観測したIPアドレス/ドメインであり、Kubernetesの外にあるブラウザからはアクセスができない為です。
監視対象がどう登録されているか
Prometheusが監視対象をどのように把握しているか、その仕組みを理解するためには、設定ファイルの内容を確認するのが近道です。
Prometheusでは、監視対象(Target)の登録を scrape_configs というセクションで定義します。
ハンズオン環境では、以下のコマンドで prometheus-server のConfigMapを確認することができます:
kubectl -n prometheus describe cm prometheus-server | less
ConfigMap内には、Prometheusの設定(prometheus.yml)が格納されており、その中に scrape_configs の定義があります。
以下はその一部抜粋です:
scrape_configs: - job_name: prometheus static_configs: - targets: - localhost:9090 - job_name: kubernetes-apiservers bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token kubernetes_sd_configs: - role: endpoints relabel_configs: - action: keep regex: default;kubernetes;https source_labels: - __meta_kubernetes_namespace - __meta_kubernetes_service_name - __meta_kubernetes_endpoint_port_name scheme: https tls_config: ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
サービスディスカバリの仕組み
ここで注目すべきは、kubernetes_sd_configs という設定です。
これは Kubernetesクラスタ内のリソース情報を自動的に取得して、監視対象(Target)を動的に登録するための仕組み です。これが、いわゆる サービスディスカバリ(Service Discovery) に該当します。
role: endpointsにより、Kubernetes内の Service + Endpoints を対象としますrelabel_configsを使って、指定条件(NamespaceやService名、Port名など)に一致したものだけをフィルタし、監視対象に登録します
たとえば上記の設定では、以下の条件を満たすエンドポイントだけが登録されます:
- Namespaceが
default - Service名が
kubernetes - Port名が
https
このようにして、Prometheusは 静的なIP指定ではなく、Kubernetesリソースに基づいて柔軟に監視対象を管理する ことができます。
構成の変化にも自動で追従できるため、Kubernetesのような動的環境では非常に効果的なアプローチです。
参照:prometheus/configuration/#kubernetes_sd_config
Kubernetesとの連携ロジックの俯瞰
これまでの項目で、Prometheusが scrape_configs を通じてKubernetesクラスタ内の監視対象を動的に検出し、Exporterからメトリクスを収集していることを確認してきました。
ここでは、PrometheusがKubernetesとどのように連携しているのかを、図を用いて俯瞰してみましょう。
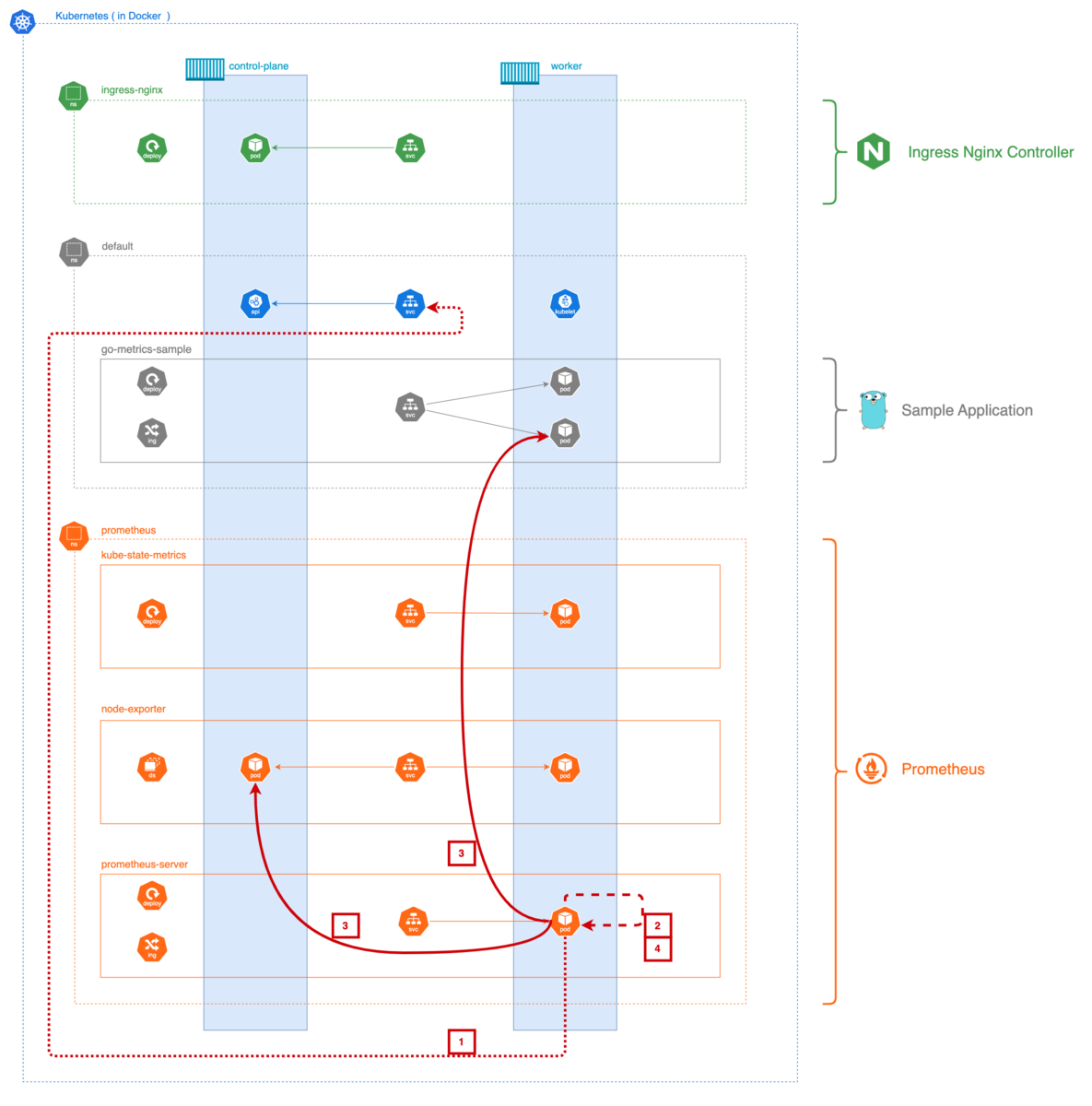
図中の番号に沿って、Prometheusの処理フローは以下のように進みます:
1) Service Discovery の開始
Prometheusは、ConfigMapに記述された kubernetes_sd_configs に基づき、Kubernetes API Server に対して対象リソース(この場合は Endpoints)の情報を問い合わせます。
2) 監視対象エンドポイントのフィルタリング
APIから取得した情報に対し、relabel_configs の条件を適用し、実際に監視する対象(IP/ポート)を選別します。
3) Exporterへのメトリクス収集リクエスト
対象が決定すると、Prometheusは定期的にそのエンドポイントに対してHTTPでアクセスし、Exporterが提供するメトリクスをPull型で収集します。
4) 収集したメトリクスの保存と可視化
取得したメトリクスはPrometheusサーバー内で時系列データとして保存され、Web UIやGrafanaを通じて可視化・分析されます。
このように、PrometheusはKubernetesのAPIを活用することで、クラスタの構成変化に自動的に追従し、動的な監視を実現しています。
設定は一度行えば済み、Podの追加や再起動にも自動で対応できる点が大きな利点です。
PodのEndpointをディスカバリする仕組みについての補足
先ほど例に挙げた go-metrics-sampleの監視は以下のjob:kubernetes-podsを利用しています。
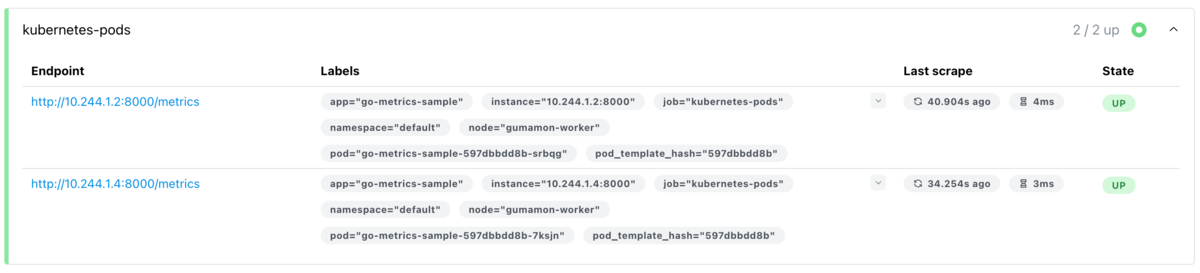
kubernetes-pods のscrape_configsは以下の条件に一致したPodのIP/PortをEndpointに追加します。
- PodのAnnotationに以下があること
prometheus.io/scrape: "true"#Scrape対象に含める (trueの場合対象)prometheus.io/port: <ANY>#Scrape対象のPortprometheus.io/path: <ANY>#Scrape対象のPath
このため、以下のようにManifestに記載することで、Podをデプロイする担当者が任意にPrometheusのEndpointを公開することができます。
# Source: go-metrics-sample/templates/deployment.yaml apiVersion: apps/v1 kind: Deployment metadata: name: go-metrics-sample labels: app: go-metrics-sample spec: replicas: 2 selector: matchLabels: app: go-metrics-sample template: metadata: labels: app: go-metrics-sample annotations: prometheus.io/scrape: "true" prometheus.io/port: "8000" prometheus.io/path: /metrics
まとめ
今回は、Prometheusを使ってKubernetes上のメトリクスを収集・可視化する仕組みを、ハンズオン形式で確認してきました。
Kubernetesの構成は日々変化するため、「どこで何が動いているのか」を把握するには、サービスディスカバリのような仕組みが欠かせません。
Prometheusはその点でとても相性が良く、Exporterやクエリ言語(PromQL)などを組み合わせることで、柔軟な監視を実現できます。
この記事が、Prometheusの基本的な動作やKubernetesとの連携のしくみを知るきっかけになっていれば嬉しいです。
NOTE
メトリクスの可視化については、Prometheus単体ではなくGrafana等を使う構成が一般的かと思います。
Prometheusは冗長化を前提とした設計が為されていないという問題もあります。Prometheusと各種サービスの連携については以下のブログにまとめています。
もし興味がありましたら、合わせてご一読いただければと思います。
以上、最後までお読み頂きありがとうございました!
