

この記事は約5分で読めます。
(前編はこちら)
こんにちは。荒井です。
前回の記事では、Amazon S3 Tables 上に Apache Iceberg テーブルを作成し、Athena からクエリできるところ並びに Glue データカタログには登録されていないところまで確認しました。
この記事では、AWS Glue ETLジョブから Amazon S3 Tables 上の Apache Iceberg テーブルにアクセスしてみるところまでやってみようと思います。
やってみよう
こちらのページをもとに試してみます。
1. IAMロール作成
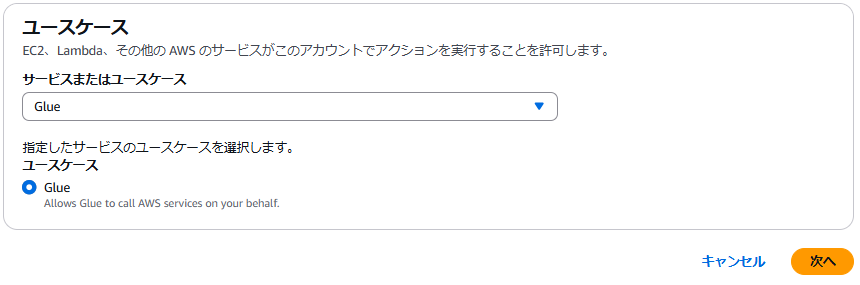
IAMのページを開き、ロールを選択し[ロールの作成]をクリックします。
信頼されたエンティティには AWS のサービスを選択し、サービスまたはユースケースとして Glue を選択します。
許可する必要のあるポリシーは以下の3つです。
- AmazonS3FullAccess
- AmazonS3TablesFullAccess
- AWSGlueServiceRole
ドキュメントには AWSGlueServiceRole は記載されていませんが、実際に動かすと以下の通り権限不足で失敗します。
GlueJobRunnerSession is not authorized to perform: glue:GetDatabase on resource
また、ETL ジョブのログを CloudWatch Logs に出力させるために、追加で CloudWatchLogsFullAccess を許可しました。
尚、今回は検証のため強い権限を与えていますが、必要に応じて絞ってあげるのが良いでしょう。
適当に名前を付け、IAMロールを作成します。
2. Apache Iceberg クライアントカタログ JAR の最新バージョンの Amazon S3 テーブルカタログの準備
AWS Glueジョブから S3 Tables で管理されている Apache Iceberg テーブルを操作するには、AWS が提供する専用の接続ライブラリが必要となります。
このライブラリはGlueの標準環境には含まれていないため、別途用意する必要があります。
そのため、Maven というリポジトリから Apache Iceberg クライアントカタログ JAR の最新バージョンの Amazon S3 テーブルカタログをダウンロードし、Amazon S3 バケットにアップロードします。
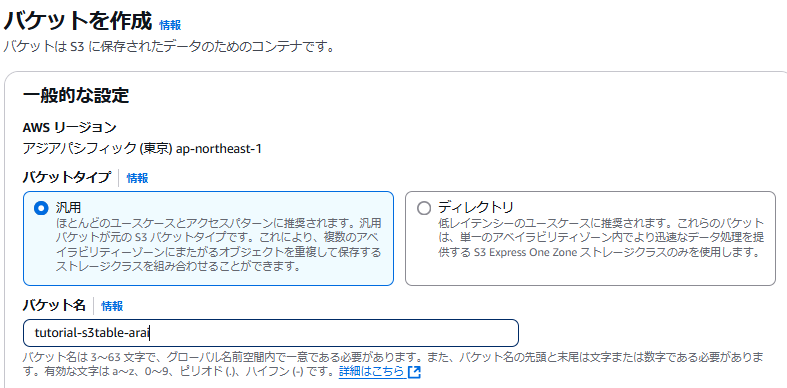
ここでの S3 バケットは S3 テーブルバケットではなく、普通の S3 バケットです。
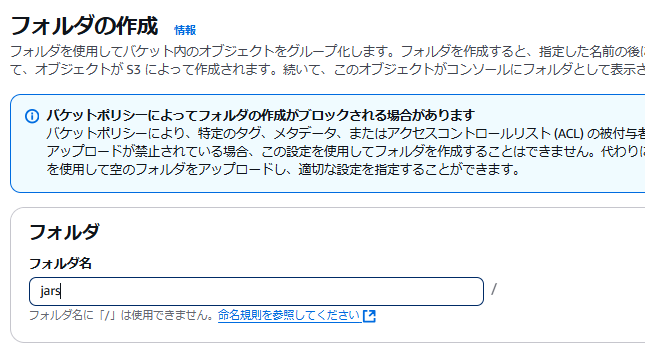
別途 S3 バケットを作成し、バケット直下に /jars というフォルダを作りその下にダウンロードしてきた jar を配置します。
コンソール / CLI のどちらからアップロードしても問題有りません。
因みにテーブルバケットの方に書き込もうとするとエラーが出ます。
aws s3 cp s3-tables-catalog-for-iceberg-runtime-0.1.5.jar s3://tutorial-s3table-arai/jars/ upload failed: ./s3-tables-catalog-for-iceberg-runtime-0.1.5.jar to s3://tutorial-s3table-arai/jars/s3-tables-catalog-for-iceberg-runtime-0.1.5.jar An error occurred (NoSuchBucket) when calling the CreateMultipartUpload operation: The specified bucket does not exist
3. S3 テーブルをクエリするための AWS Glue ETL PySpark スクリプトを作成
公式ドキュメントを参考に、スクリプトを準備しローカルに .py 形式で保存します。
指定された名前空間(データベース)名とテーブル名が存在するか確認し、存在した場合は select を、存在しなかった場合はテーブル構造のみを作るものとなっています。
そのままだとインデントエラー等で動かなかったので、参考までに修正したものを記載します。
★がついている箇所を各自の環境の情報に直してください。
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
from pyspark.sql import SparkSession
spark_conf = SparkSession.builder.appName("GlueJob") \
.config("spark.sql.catalog.s3tablesbucket", "org.apache.iceberg.spark.SparkCatalog") \
.config("spark.sql.catalog.s3tablesbucket.catalog-impl", "software.amazon.s3tables.iceberg.S3TablesCatalog") \
.config("spark.sql.catalog.s3tablesbucket.warehouse", "arn:aws:s3tables:ap-northeast-1:<AWSアカウントID>★:<S3tableバケット名>★") \
.config("spark.sql.defaultCatalog", "s3tablesbucket") \
.config("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions") \
.config("spark.sql.catalog.s3tablesbucket.cache-enabled", "false")
sc = SparkContext.getOrCreate(conf=spark_conf.getOrCreate().sparkContext.getConf())
glueContext = GlueContext(sc)
spark = glueContext.spark_session
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
# --- Namespace and Table Variables ---
namespace = "s3table_iceberg★"
table = "daily_sales★"
# --- run_sql function ---
def run_sql(query):
try:
result = spark.sql(query)
result.show()
return result
except Exception as e:
print(f"Error executing query '{query}': {str(e)}")
return None
def main():
try:
print(f"Ensuring namespace '{namespace}' exists...")
run_sql(f"CREATE NAMESPACE IF NOT EXISTS {namespace}")
print("-" * 30)
table_full_name = f"{namespace}.{table}"
print(f"Checking if table '{table_full_name}' exists...")
table_exists = spark.catalog.tableExists(table_full_name)
if not table_exists:
print(f"Table '{table_full_name}' does not exist. Creating table structure...")
print("-" * 30)
print("CREATE TABLE")
# Use the schema matching the pre-loaded 'daily_sales' data
create_table_query = f"""
CREATE TABLE IF NOT EXISTS {table_full_name} (
sale_date date,
product_category string,
sales_amount double
)
PARTITIONED BY (month(sale_date))
"""
create_result = run_sql(create_table_query)
if create_result is None:
print("Failed to create table. Exiting.")
raise Exception("Table creation failed")
print("-" * 30)
print(f"Table '{table_full_name}' created.")
else:
print(f"Table '{table_full_name}' already exists.")
print("-" * 30)
print("SELECT FROM TABLE")
run_sql(f"SELECT * FROM {table_full_name} LIMIT 20")
except Exception as e:
print(f"An error occurred in main execution: {str(e)}")
raise
finally:
job.commit()
if __name__ == "__main__":
try:
main()
except Exception as e:
print(f"Job failed with error: {str(e)}")
sys.exit(1)
ポイントになるのは最初の6行かと思いますので、何をやっているかについて調べたものを参考までに記載します。
* spark_conf = SparkSession.builder.appName("GlueJob") \
* Sparkセッション設定の開始とアプリ名設定。
* .config("spark.sql.catalog.s3tablesbucket", "org.apache.iceberg.spark.SparkCatalog") \
* 's3tablesbucket' という名前のSpark SQLカタログを登録し、Icebergの標準カタログインターフェースを指定
* .config("spark.sql.catalog.s3tablesbucket.catalog-impl", "software.amazon.s3tables.iceberg.S3TablesCatalog") \
* 's3tablesbucket' カタログの具体的な実装クラスとして、AWS提供のS3 Tables用カタログクラスを指定
* .config("spark.sql.catalog.s3tablesbucket.warehouse", "arn:aws:s3tables:ap-northeast-1:<AWSアカウントID>★:<S3tableバケット名>★") \
* 's3tablesbucket' カタログが管理するIcebergテーブルのデータとメタデータの格納場所 (Warehouse) をS3テーブルバケットのARNで指定
* .config("spark.sql.defaultCatalog", "s3tablesbucket") \
* このSparkセッションで、デフォルトで使用するカタログを 's3tablesbucket' に設定
* .config("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions") \
* Apache Iceberg用のSpark拡張機能を有効化 (Iceberg特有のSQL構文などを使えるようにする)
* .config("spark.sql.catalog.s3tablesbucket.cache-enabled", "false")
* 's3tablesbucket' カタログのメタデータキャッシュを無効化 (常に最新のメタデータを参照する設定)
4. ETLジョブ作成
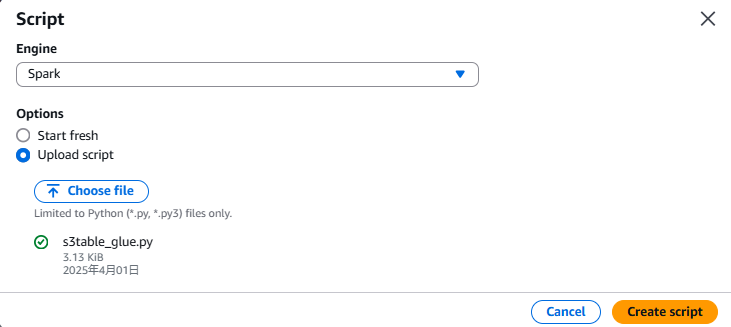
AWS コンソールから Glue のページを開き、ETL Jobs を選択→[Script editor]をクリックします。

先ほど作成したファイルをアップロードします。
Job detailsから、ジョブの名前を入力し、先ほど作成したIAMロールを指定します。
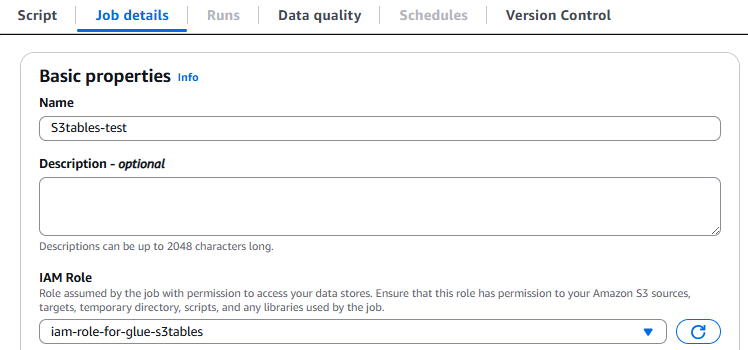
[Advanced properties]を開き、Dependent JARs path にアップロードした Apache Iceberg クライアントカタログ JAR を指定します。

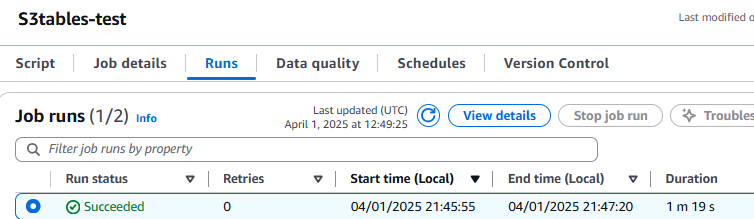
[Save]→[Run]をクリックし、無事に Succeeded になったら完了です。
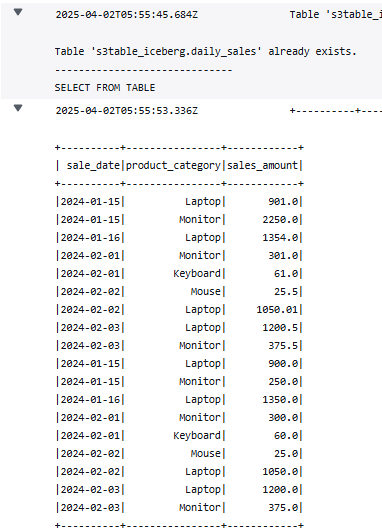
ジョブの output ログに、指定したテーブルの select 結果が出ていることが確認できます。
終わりに
AWS Glue ETLジョブから Amazon S3 Tables 上の Apache Iceberg テーブルにアクセスが可能であることが分かりました!
S3 Tables は Apache Iceberg に最適化しているため、公式のニュースブログによると「セルフマネージドテーブルストレージと比較すると、最大 3 倍のクエリパフォーマンスと最大 10 倍のトランザクション/秒が期待できます。」と記載があり、今から利用を検討する際には選択肢の一つになり得ると思います。
また、今回は取り上げませんでしたが、Lake Formation を利用することによりきめ細やかな権限設定も可能となっていますので、要件によってはこれ一択という場合もあるでしょう。
しかし、Glue コンソール上のデータカタログ(Databases, Tables)には登録できなかったため、例えばコンソール上からテーブルのスキーマやパーティションが見れないなど可視性が悪いという欠点もあります。
この記事がどなたかのお役に立てば幸いです。
荒井 泰二郎 (記事一覧)
2023年8月入社 最近ジムに通い始めました