

この記事は約19分で読めます。
こんにちは。自称ソフトウェアエンジニアの橋本 (@hassaku_63)です。
仕事で OpenSearch を検討することになったんですが、未だに複雑すぎてわけがわかりません。ほんとに難しいですね、OpenSearch は...。
何回もぐるぐるしているうちになんとなく全体像や単語の理解がふわっと掴めてきたので、ここらでひとつ一次情報にあたって体系的な整理をしてみようと思いました。
あくまで自分用の整理ですが、多分ほかの人にも有用であろうと思ったのでアウトプットがてら書き起こしてみることにします。
この記事単体でも約13,000字の大作になりましたが、まだ必要な背景知識の一部を言及した程度です。とはいえ、私的にはまともな技術検討が成立するための前提として特に重要性が高いと判断したトピックしか述べていないつもりなので、本家ドキュメントの膨大なページ数を通読するよりはマシかと割り切っていただけるとありがたいです。
主な情報源:
- おことわり
- この文書の目的
- 本記事執筆にあたっての前提条件
- 背景知識の履修 (1) - 主要な構成概念
- OpenSearch のインデックスを構成する物理的・論理的な要素
- AOS ドメイン (クラスタ) を構成する要素
- ここまでのまとめ
- つづく
おことわり
筆者は OpenSearch 自体に対して深い知見があるわけではなく、OpenSearch のドキュメントをある程度通読しつつ開発環境での検証をいくぶんか行ったことがある程度のレベルです。そのため、内容の厳密さや正確さは保証できないことをご承知おきください。正確な情報は最新の公式ドキュメントを参照してください。
本記事は複雑なサービスである OpenSearch/AOS のサイジング問題に関する脳内俯瞰マップを構築することが目的であるため、比喩などを用いて説明した箇所についても技術的に厳密性・正確性を欠く可能性があることを承知の上お読みくささい。
また、OpenSearch に関する資料を軽く眺めたことがある人であれば知っているような単語に関しては、説明を省略する場合があります(例えば「インデックス」「ドキュメント」など)。
この文書の目的
コンピューティングリソースやストレージの要件に関する見通しを付けるために読む、まとめとして本記事を執筆した。
ゴールはコンピューティングやストレージの構成要件に関わる変数を整理して、何を明らかにすればクラスタ構成を仮定できるようになるか示すこと。また、クラスタ構成の仮定が出来ることによっておおよそ発生する稼働コストの推定精度を上げること。
なお、AWS ドキュメント(下記)にも記載があるように、基本的に実測なしで精緻なサイジングを計画することは難しい。本記事もあくまで初期予測に一定の指針を与える参考情報としての利用を想定しており、この記事の内容をもって精度の高いサイジングが行えることを保証するものではない。
Amazon OpenSearch Service ドメインのサイズを決定するための完璧な方法はありません。ただし、ストレージのニーズ、サービス、および OpenSearch 自体を理解することから始めることで、ハードウェアのニーズに関する、情報に基づいた初期予測を行うことができます。
出典: Amazon OpenSearch Service ドメインのサイジング: https://docs.aws.amazon.com/ja_jp/opensearch-service/latest/developerguide/sizing-domains.html
本記事執筆にあたっての前提条件
筆者にとっての OpenSearch (Service) の主な利用モチベは AWS におけるセキュリティイベントの保存・分析基盤を意識しており(SIEM のようなログ・イベントの分析基盤のようなものをイメージしていただくとよいかも)、そのようなワークロード ではない 目的にはフィットしない記述が入っている可能性がある。
本記事時点の最新情報に、できる限り準拠する。OpenSearch のバージョンは特に明言のない限りは 2.11 以降(執筆時点では 2.19 が最新。OpenSearch Service でサポートされる OpenSearch のバージョンは 2.17 が最新)であるものと想定する。
OpenSearch Service クラスタをデプロイするリージョンは ap-northeast-1 を用いるものとする。
スコープ外
以下のトピックについてはスコープ外とする。
- セキュリティや通信要件に関わる設定項目
- 認証・認可 (IAM Role および OpenSearch におけるロール、あるいは FGAC)
- サブネットの配置(e.g. プライベートサブネットにデプロイする場合の VPC Endpoint の要否や L3/L4 の通信要件)
- Pipeline
- Dashboard
- Data Stream
- Elasticsearch (on Amazon OpenSearch Service)
用語の表記
ソフトウェア製品としての OpenSearch と、AWS が提供するマネージドサービスとしての OpenSearch Service の区別として、以降は特に断りのない限り前者は "OpenSearch"、後者は "AOS" と表記する。
背景知識の履修 (1) - 主要な構成概念
本セクションの主な出典:
- (1) OpenSearch Documentation - Introduction to OpenSearch
- (2) OpenSearch Documentation - Creating a cluster
OpenSearch, AOS を構成する主要なコンポーネントを整理する。
OpenSearch クラスタの物理的な構成
クラスタを構成するのは「ノード」の集合。ノードには役割によっていくつか種類がある。以下出典 (2) より。

筆者の主観でいくつか抜粋する。
Cluster Manager *1 のイメージは読んで字のごとくでだいたいOK。複数のノードの管理(ヘルスチェックやクラスタへの参加・離脱の制御など)をする役割のほか、ノードに対して「シャード」の割り当てを行う、インデックスの作成・削除、などのオペレーションを行う。ベスプラ構成では Manager 専用ノードを 3 台用意することが推奨される。これは Manager ノードの障害時に発生しうる問題(スプリットブレインなど)を回避し、クラスタの系全体の整合性を保つための最小数。AWS に当てはめるなら 3-AZ 分散が推奨となる。
"Coordinating" は複数あるデータノードからよしなにデータを取得して、集約してクライアントに返すための役割を持つ。
"Data" は実際のデータ(ドキュメントを構成する「セグメント」あるいはインデックスを構成する「シャード」)を保存するノード。自分自身が保持しているローカルのシャードに関するオペレーション(Indexing, Search, Aggregation)に責任を持つ。AOS でも触れるが、実際にデータの実体をどこでどのように保持しているのかはこの概念とは無関係(基本はインスタンスストアか EBS をイメージしておけばよい)。
"Ingest" は Data ノードの手前にある前処理用の役割。フィルタや変換処理を必要に応じて担う。AOS では Pipeline に相当するが、本記事ではこれ以上取り上げない。
"Search" は searchable snapshots へのアクセスを担うノード。Search ノードはオプショナルな役割であるため、それほど重視して覚える必要はない。ただし、AOS で後述するが、これは UltraWarm ノードに対応するのでそれだけ覚えておくとよい。Data ノードの亜種みたいなもの。Searchable snapshots は Read-only で検索も遅くなるが、その代わりに通常のクエリによる検索は可能、かつ S3 のような外部のストレージを裏で使うことができる。このような性質がマッチするワークロードでは有効な選択肢になりうる。例えばログ分析において発生から一定期間が経過したデータを、検索可能な状態を維持しつつよりコストパフォーマンスに優れた方法で格納したい場合が該当。
OpenSearch のインデックスを構成する物理的・論理的な要素
中核となる概念は「インデックス」「シャード」「レプリカ(シャード)」「セグメント」の3つ。
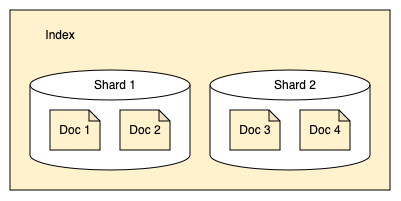
出典: OpenSearch Documentation - Introduction to OpenSearch
1つのインデックスは複数個のシャードから構成される。
シャードは RAID0(ストライピング)や DBMS におけるパーティショニング (e.g. PostgreSQL のテーブルパーティショニング)、あるいは DynamoDB におけるパーティションの類似概念であり、そのモチベーションもこれらとだいたい同じである。
(論理的な意味での)ひとつのデータの集合... OpenSearch で言うところの「インデックス」を構成する中身を、物理的に分割したもの。物理的な配置を分散することでデータ管理や処理効率を向上させることが目的であるため、原則としてあるインデックスを構成する(おそらく)多数のシャードは、データノード間で可能な限り均等な配置となるよう分散されることになる。
シャード1個あたりのサイズが大きすぎればそのシャードに対する読み書きのパフォーマンスが低下する一方、シャード数が多すぎればその分だけ管理側のオーバーヘッドが増える。OpenSearch は、1 シャードあたり 10~50GB 程度が適切だと明言している。
A good rule of thumb is to limit shard size to 10–50 GB.
出典: OpenSearch Documentation - Introduction to OpenSearch
1シャードあたりの容量が増えすぎないことが重要であるが、これは基本的に OpenSearch ユーザーの責務となる。シャード単位で実際に格納されるデータ容量はユーザーが直接コントロールできない。代わりに、以下のような手段で単一インデックスに対する書き込みが増えすぎないような構成を取り、インデックスの利用方法や設定によって間接的に制御することになる。
- プライマリシャード数を増やす。インデックス作成後に後からプライマリシャード数を変更することはできず、Reindex などを用いて別のインデックスに移行する必要が生じるため初期計画の時点である程度の見通しを持つことが重要 *2
- ISM (Index State Management) を用いてインデックスの Rollover を行い、インデックスを分割する
- ISM (Index State Management) を用いてインデックスの Roll-up を行い、古いデータを時系列などで丸めて圧縮したうえで別のインデックスに移動する
- 書き込み対象のインデックスを書き込み時刻の日付のパターンで変化させる(クライアントから透過的に扱いたい場合はエイリアスの併用が効果的)
今挙げた方法はいずれも単一インデックスの肥大化に対処するためのユーザー制御の手段なので、実際どのような設定が必要かは期間あたりの書き込みデータ量の仮定なくして決定できない。このあたりの検討をするにはユーザーの予測に基づく数字を出す必要がある。
シャードは自身の複製を持つことが可能。レプリカシャードと呼ばれる。これは Amazon RDS におけるリードレプリカのようなもので、読み込みのパフォーマンス向上と、障害時のバックアップとしての役割を果たす。そのトレードオフもリードレプリカに類似しており、検索性能と耐障害性の向上と引き換えにディスク使用量の増加や書き込み負荷の増加を招く。
「セグメント」は内部の仕組みや運用の視点では重要な概念となるが、サイジングの計画に必要な知識だけであればそこまで覚えなくてもよい*3。
AOS ドメイン (クラスタ) を構成する要素
基本的な要素は OpenSearch における概念の延長で理解できるところも多い。ただしマネージドサービスな分、OpenSearch における概念とは若干異なる点もある。
基本的に OpenSearch におけるノード1台がそのまま OpenSearch 専用の (EC2) インスタンス1台に対応していると考えてよい*4。
OpenSearch におけるクラスタは AOS においてドメインと呼ばれる。
デプロイオプション
デプロイオプション自体は AOS ドメインの構成要素ではないが、最初にマネジメントコンソールでドメイン作成する際に目にする用語であり、自分は少々混乱したのでここで整理しておく。
ドメインの作成を行うとき、「デプロイオプション」と呼ばれるものがあることに気づくと思うが、これは AWS が推奨するやり方をテンプレート的に提示してくれるウィザード的なものであって個別にそういう機能があるという話ではない。プロダクションユースで推奨とされている "Multi-AZ with Standby" を選択した場合、実際に行う設定は以下の出典の通り。
- ドメインが 3 つのゾーン間にデプロイされました。
- 専用マスターノードおよびデータノードに、現行世代のインスタンスタイプを選択します。
- 3 つの専用マスターノードと 3 つ (または 3 の倍数) のデータノード。
- ドメイン内の各インデックスに 2 つ以上のレプリカ、または 3 の倍数のデータコピー (プライマリノードとレプリカの両方を含む)。
一言で言えば "Multi-AZ with Standby" オプションは「各種ノードを 3-AZ に分割してドメイン全体の耐障害性を高めたうえで、それぞれのゾーンで同じデータの複製を保持できるようにしデータの耐障害性を高める設定」を行うということになる。
AOS におけるノードの種類
主要な出典:
- (3) Amazon OpenSearch Service の UltraWarm ストレージ
- (4) Amazon OpenSearch Service 用コールドストレージ
- (5) Amazon OpenSearch Service 用 OR1 ストレージ
OpenSearch にはない用語を使っている、あるいは直接関係がない場合があるので、ここで対応関係を整理する。
データを保持するための仕組みとしていくつかの方法を提供していて、AOS においてそれらは「XXX ストレージ」と呼称される。
通常のデータノードはデータ保存先として自身にアタッチされた EBS ボリュームを使う。これとは別に UltraWarm, Cold というものも役割の種別として存在している。
| OpenSearch | AOS | ストレージ(AOS) | 補足 |
|---|---|---|---|
| Data ノード | 通常のデータノード | "Hot" ストレージ | データノードインスタンスに接続されたストレージ (EBS ボリューム) を使う |
| Search ノード | UltraWarm (UltraWarm ノード + S3) | "UltraWarm" ストレージ | S3 と、ノードが制御するキャッシュソリューションの組み合わせ。専用のマスターノードが必要 |
| - | Cold (ノード不要) | S3 | データは S3 に保持される。Cold 専用マスターノードが必要かつ UltraWarm の利用が前提 |
UltraWarm, Cold のストレージを利用するには、どちらもドメインに「専用のマスターノード」が必要。
ここでいう専用のマスターノードとは、AOS ドメインにおける Manager ノードに他の役割(例えばデータノード)を持たせないようにドメインを構成する必要がある、という意味。UltraWarm 用のノードとは関係のない条件。また、Cold ストレージを管理する専門のノードが必要...という意味でもない。
UltraWarm
UltraWarm は AOS ドメインに専用のマスターノード + S3 バックのストレージ構成を追加するものとなる。クライアントから見ると、読み込みに関しては通常のデータノードと同じように透過的に扱える。
OpenSearch の Search ノードの説明でも簡単に触れたように、この仕組みは OpenSearch における Search ノードの AOS 版である。そのため、その特性も Search ノードと同じである。もし UltraWarm ノード上のインデックスに対して書き込みが必要になった場合、そのインデックスのデータを Hot ノード(のストレージ)に書き戻す必要がある。
ウォームインデックスはホットストレージに戻されない限り読み取り専用であるため、UltraWarm はログなどのイミュータブルなデータに最適です。 (^3)
発生料金はインスタンス料金と、実際に使用した S3 の料金。トラフィックの課金は EC2 などの他のサービスとおおよそ考え方が同じで、AOS の場合 AZ をまたぐノード間の通信や、ノード - S3 間のものは測定も課金もされない。OpenSearch ではシャードの再割り当てなどで内部的にノード間でデータをやりとりするオペレーションが発生しうるが、これは課金対象とはならない。
出典: Amazon OpenSearch Service の料金
このノードを採用して都合がよい点は、以下のようなポイントがある。以下出典 (3) より抜粋。
UltraWarm ノードは、接続されたストレージではなく、Amazon S3 と高度なキャッシュソリューションを使用してパフォーマンスを向上させます。アクティブに書き込みを行っていないインデックス、クエリの頻度が低いインデックス、および同じパフォーマンスが必要とされないインデックスについては、UltraWarm により、データの GiB あたりのコストが大幅に削減されます。ウォームインデックスはホットストレージに戻されない限り読み取り専用であるため、UltraWarm はログなどのイミュータブルなデータに最適です。
UltraWarm では Amazon S3 を使用するため、このオーバーヘッドは発生しません。UltraWarm ストレージ要件を計算するときは、プライマリシャードのサイズのみを考慮します。
ユーザーは、Hot ストレージに保持したデータを UltraWarm に移行することが可能。これは API リクエストによって手動で行える。あるいは、ISM (Index state management) を用いることで自動化することも可能。実行条件には時間経過やインデックスのサイズなどが設定可能である。
Cold
Cold ストレージは、例えるなら S3 Glacier のように、古いデータを長期保存する用途に近いと考えるとわかりやすい。
Hot, UltraWarm との重要な違いは、Cold ストレージ上のデータはそのままでは検索不可能であること。
UltraWarm ストレージと同様に、コールドストレージは Amazon S3 によってバックアップされます。コールドデータをクエリする必要がある場合は、既存の UltraWarm ノードに選択的にアタッチできます。コールドデータの移行とライフサイクルは、手動で、またはインデックスステート管理ポリシーを使用して管理できます。 (^4)
監査等のサービス要件によって、通常の実務では不要だが保持する必要があるインデックスを Cold ストレージに移行することで、データ保持のコストを抑えられる。
また、重要な前提として、Cold ストレージを利用するためにはいくつかの前提が必要となる。特に料金に関係する部分を整理する。(^4)
- OpenSearch Service ドメインでコールドストレージを有効にするには、同じドメインで UltraWarm も有効にする必要があります。
- コールドストレージを使用するには、ドメインに専用のマスターノードがある必要があります。
データノードは不要だが、「専用マスターノード」が必要になる点が課金ポイントとなる。前述の通り「専用」は Manager ノードにデータノードを兼務させたりしないことを意味しており、"Cold ストレージ" に対して係っている言葉ではないので解釈に注意。課金要素はストレージ使用の料金で、UltraWarm と同じく実際に使用した分だけ課金される。
インデックスデータを Cold に移行する方法は、UltraWarm の場合と同じく API リクエストによる手動移行と、ISM による自動移行が可能。
また、Cold に移行したデータを読み出したい場合に必要な UltraWarm への書き戻しは API リクエストによって実行可能。
(AOS を利用するユーザー自身のユースケースにおいて)データの保持期限を満了した場合は、Cold 上のインデックスを削除することができる。
OR1
(注)執筆時点では OR2 がリリースされており、特段の理由がないならこれからの新規採用にはおそらく OR2 を選択するのがよい。適宜読み替えること
UltraWarm や Cold はいわば S3 のストレージクラスのようなもので、インデックス単位の参照・保持要件に応じて選択できるストレージの Tier に近い概念だった。
OR1 はそれらとはまた性質が異なり、同列の概念ではないことに注意。ストレージの Tier というよりは、むしろインスタンスタイプによる特性と理解するのがよい。ドキュメントで「OpenSearch 最適化インスタンス」と表現されているインスタンスタイプが、OR1 および OR2 である。
UltraWarm, Cold はインデックスデータの格納にリモートのストレージ (S3) を使う仕組みであるのに対して、OR1 ではデータノードのローカルディスクとリモートストレージを両方使用する。
OR1 はプライマリシャード/レプリカシャードの最適な保持の仕方を提示するものであって、あるインデックス全体を用途に応じた最適なストレージクラスに配置できるようにする UltraWarm や Cold とはモチベーションが異なる。OR1 ではプライマリシャードのデータは自身の接続されたストレージ(EBS ボリューム)に格納する。この点は "Hot" なデータノードの一般的な仕様と同じだが、複製であるレプリカシャードはリモートストレージ (S3) に格納する。
このような性質の違いから、OR1 と UltraWarm の違いを整理する。以下出典(5) より抜粋。
- OR1 インスタンスは、ローカルストアとリモートストアの両方にデータのコピーを保持します。UltraWarm インスタンスでは、ストレージコストを削減するために、データは主にリモートストアに保持されます。使用状況パターンに応じて、データをローカルストレージに移動できます。
- OR1 インスタンスはアクティブであり、読み取りおよび書き込みオペレーションを受け入れることができますが、UltraWarm インスタンスのデータは、手動でホットストレージに戻すまで読み取り専用です。
- UltraWarm は、データの耐久性においてインデックススナップショットに依存しています。一方、OR1 インスタンスは、バックグラウンドでレプリケーションとリカバリを実行します。赤い*5インデックスの場合、OR1 インスタンスは Amazon S3 のリモートストレージから欠落しているシャードを自動的に復元します。復旧時間は、復旧するデータの量によって異なります。
ここまでのまとめ
ここまで登場した概念は主に OpenSearch クラスタ(AOS ドメイン)を構成している物理的な要素に着目したものでした。
本記事ではたびたびインデックスをどう管理するのか (ISM) の側面にも言及していますが、それらは別の記事で扱うことにします。
最後に、ここまでの知識を整理して描けそうな概念図を私なりに作ってみましたので、掲載します。

ここまでの出典では、OpenSearch 的には「コントロールプレーン」「データプレーン」という用語は登場しませんが、これらの名称は ECS などクラスタに類似する構成を持つサービスではコンポーネントの役割として一般的な用語であろうと考え単純化したものです。また、図中の Lifecycle Policy は私が一般化してこの単語を用いただけで、実際に存在する機能に当てはめるとこれはユーザー定義の ISM (Index State Management) を用いて、あるいは手動オペレーションで行われるインデックスの制御を指します。
つづく
ここまででかなり長くなっているので、続編に続きます。
もうちょっと背景知識のインプットに文面を割くことになると思います。コンピューティングやストレージに関係する構成要素についてはだいたい主要なものに触れたと思っているので、次はどう運用するのかの視点、特に ISM (Index State Management) あたりについて触れる予定です。
*1:図中では "Master" と表記されているが、執筆時点では "Cluster Manager" が正式
*3:内部的には、シャードは Apache Lucene における「セグメント」から構成されるインデックスである
*4:実際に EC2 インスタンスが稼働して、EC2 のマネジメントコンソール上で閲覧できるわけではないのであしからず
*5:筆者注: これは "hot" の日本語訳の誤植と思われる