
はじめに
こんにちは!2024年10月にCA Tech Job インターン生として就業させて頂いた、早稲田大学創造理工学研究科 修士1年の大岩将です。インターンではAI事業本部の Dynalyst にて、「ユーザのプライバシーに配慮した広告配信の実現」に関するデータ分析の業務に携わらせていただきました。この記事では、私が1カ月の間に取り組んだ内容についてご紹介します。
Dynalystにおける広告配信の現在と今後直面する課題
Dynalystは、Real Time Bidding (以下、RTB) を通してオンライン広告配信を行うプロダクトです。RTBはオークションを通して広告枠の売買を行う仕組みであり、広告枠の売り手である SSP (Supply Side Platform)と買い手であるDSP (Demand Side Platform)からなります。広告枠を買い取ったDSPは広告主に代わってそこに広告を表示し広告配信の費用対効果の最大化を試みます。DynalystはこのDSPにあたるプロダクトです。入札はユーザが広告配信面を訪問するたびにリアルタイムにおこなわれますが、その際Dynalystでは「ユーザの情報」、「広告枠の情報」、「広告内容に関する情報」を機械学習モデルの特徴とし、ユーザが広告をクリックする確率(以下CTR) / CV(ユーザの商品購入や資料請求などのゴールとなるアクション) に至る確率(以下CVR)を予測することで、最適な入札金額を決定しています。
3rd Party Cookie の利用による情報取得
また各種情報の中でも、「ユーザの情報」の取得には 3rd Party Cookie の仕組みが利用されています。3rd Party Cookie を用いることで、配信面に訪問したユーザの広告主サイトでの行動履歴を把握することが出来るため、ユーザの嗜好や特性など詳細なユーザ情報を得られます。このようにしてクロスサイトで得られたユーザ情報は、従来からオンライン広告配信の最適化に大きく貢献してきました。
インターネット広告におけるプライバシー保護の動向
しかし昨今では、プライバシー保護の観点から、ブラウザが 3rd Party Cookie の利用を制限する動きがあります。すでにApple社の提供するブラウザ (Safari) では完全に3rd Party Cookieの利用がブロックされており、現在この流れが他ブラウザにも波及している状況です。
オンライン広告配信プロダクトにおいて、3rd Party Cookie の廃止は取得出来る「ユーザの情報」の質 が著しく低下することを意味します。これにより、現在稼働している機械学習による CTR、CVR 予測モデルの精度も大きく低下することが考えられます。予測精度は広告配信により得られる利益(≒ CV数) の大きさに直結するため、広告配信事業としても、このままでは大幅な利益減が想定されます。
Privacy Sandbox API のプライバシー保護の仕組み
Safariと同様に主要なブラウザの一つであるGoogle Chromeにおいても、近い将来に3rd Party Cookie の廃止が宣言されています。それと同時に、前述の「3rd Party Cookie 廃止によるオンライン広告事業への悪影響」を抑えるため、Google Chrome はプライバシー保護とオンライン広告ビジネスによる利益獲得の双方を保証する試みとして Privacy Sandbox Project (*9)を立ち上げました。
同プロジェクトの Protected Audience API では、ブラウザ上で RTB に変わるオークションを行い、内部ではユーザ情報を用いた入札が可能です。一方、各アドテクベンダー (以下、DSP) にはそれらの情報の一部のみの送信が許される、情報にノイズが付与される、送信が遅らされることでリアルタイムの取得を困難にする、といった仕組みを用いることでプライバシーを保護します。広告事業者の視点では、特に「ブラウザ上でユーザ情報や利用情報が保持・管理された後まとめて広告事業者にデータを送信する」という仕組みが従来との大きな違いです。以下でこの仕様が CV 計測にどのような影響を与えるかを解説します。
1) 現在ではGoogle Chromeは3PC廃止を撤回し、ユーザーの選択肢を高める新しいアプローチを導入することがアナウンスがされています。
同プロジェクトで提供される広告配信の仕組み上では、ブラウザ (Google Chrome) 側でユーザ情報を保持してから各アドテクベンダー (以下、DSP) に情報を送信します。その際、ユーザ情報に対してノイズを付与したり、また送信を遅らせたりすることでプライバシーを保護します。広告事業者の視点では、特に「ブラウザ上でユーザ情報を保持してからまとめて広告事業者にデータを送信する」という仕組みが従来との大きな違いです。
従来のCV計測の仕組み
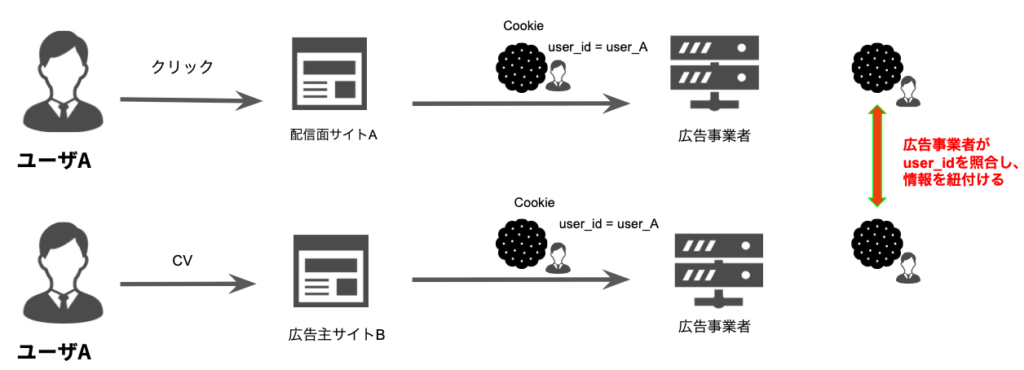
図1 従来のCV計測の流れ
従来(現在)は、3rd Party Cookieを用いることでユーザの識別を行い、CV 計測に役立てていました。例えば DSP が独自に管理するユーザの ID を書き込む Cookie を準備すれば、広告配信面にユーザが訪問 、クリックした際に DSP がそのユーザの ID を取得できます。次に広告主サイトにユーザが訪問 (CV) した際も同様にユーザ ID を取得できるので、広告事業者がユーザID から過去の広告訪問履歴を検索することでクリックと CV の紐づけが可能となります。
Privacy Sandbox におけるCV計測の仕組み
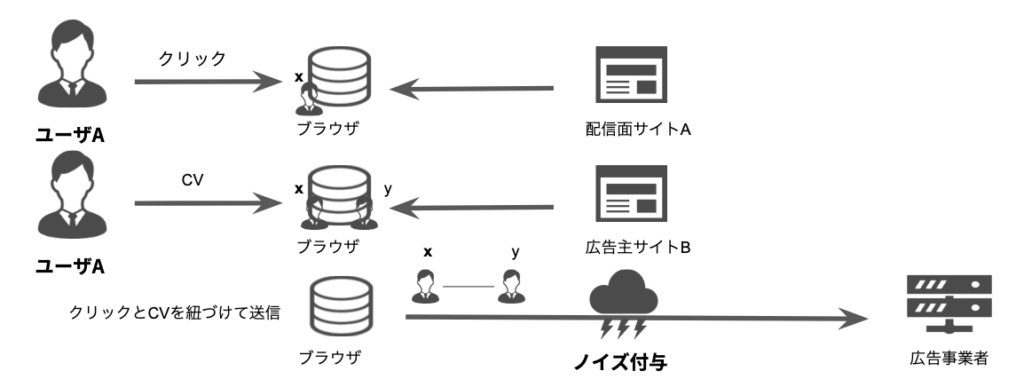
図2 Privacy Sandbox 環境下におけるCV計測の流れ
一方で、Privacy Sandbox 環境下では、Cookieの送信が行われません。そのため広告事業者がユーザIDを用いた情報の紐づけを行うことが出来なくなってしまいますが、代わりにそれらの情報をブラウザが保持します。即ちブラウザが内部でユーザのクリックとCVを紐づけた上でそれを広告事業者に送信するのですが、この際に情報にノイズを付与することにより、ユーザのプライバシーを保護します。
ε-label-DPによるプライバシー保護シミュレーション
AI 事業本部では Privacy Sandbox APIの検証に参加しており、定期的にGoogle Chromeに仕様についてのフィードバックを行っています。この検証の過程で、例えば予測モデルに入力する特徴量に当たるデータの一部は、modeling signal(*1) という仕組みを通してのみ取得可能で、取得可能な情報の総量に制限があることが分かっています。その一方で、Privacy Sandbox API がデータ送信時にラベル ( ≒ CVの有無 ) に対して行うノイズ付与の具体的な方法は、チーム内では未だ明確ではありませんでした。もしこのノイズ付与方法がわかれば、その機構を用いてシミュレーションを行うことで、Privacy Sandbox 環境下におけるCVR予測モデルの挙動を確認することが出来ます。
そこで、本インターンではラベルに対するノイズ付与機構が ε-label-DP と呼ばれるプライバシー保護基準を満たすと仮定してシミュレーション実験・考察を進めました。ε-label-DP は差分プライバシー (Differencial Privacy) に基づいてラベル情報のプライバシー保護を保障する枠組みで、2つの異なるデータにそれぞれノイズを付与した際の識別可能性を規定します。また、ε-label-DPの ε はプライバシー保護の度合いを表すパラメータであり、上記の識別可能性の度合いを制御します。差分プライバシーについては (*2) が詳しいです。
Randomized Response Mechanism
ε-label-DPを満たすノイズ付与機構として、本インターンではRandomized Response Mechanism(*7) を使用しました。具体的なノイズ付与の方法はとてもシンプルで、各データに確率 1-p でラベルの真値をflip (1 なら 0、0 なら 1) します。真のラベルが flip されない確率 p とプライバシー保護水準 ε は以下の関係を満たします。
プライバシー保護水準 ε と真のラベルである確率 p の関係を以下に示します。
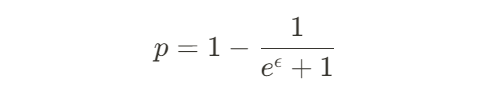
表1 プライバシー保護水準 ε と真のラベルである確率pの関係

現状の課題
以上の背景を踏まえて、現状考えられる課題・疑問を以下のように整理しました。
(分析系)
- ノイジーなデータを学習データに用いることで予測モデルの精度がどの程度悪化するのか?
- Privacy Sandbox 環境下で実際に得られるノイジーなデータに対する評価と、3rd Party Cookie によって得られるデータに対する評価ではどの様な差が生じるか?
- 取得できる情報の制約により、予測精度がどの程度悪化するのか?
(改良系)
- ノイジーなデータを用いる場合に、予測精度の悪化を防ぐには?
- ノイジーなデータを用いる場合に、適切な評価を与えるには?
- 予測精度を最大にするためには、限られた情報をどのように活かすべきか?
本インターンでは、この中の一部課題に対して実験を行いました。
Privacy Sandbox 環境下におけるCVR予測精度分析
現状課題における
「 1. ノイジーな学習データを用いることで予測精度がどの程度悪化するのか? 」
「 2. 1. の評価と Privacy Sandbox 環境下で実際に得られるノイジーなデータに対する評価とでどの様な差が生じるか?」
に対して答えを得るべく、前述のRandomized Response Mechanismを用いたシミュレーション実験を行いました。
実験概要
本実験では、まずDynalystで実際に使用しているデータに対して、プライバシー保護水準 ε を
0 ≦ ε ≦ 15と変化させながら、Randomized Response Mechanismによりノイズを付与します。このデータが、Privacy Sandbox 環境下において取得可能なデータだとみなすことが出来ます。次に、そのデータを用いてCVR予測モデルを学習します。
そして、ノイジーなデータで学習させたモデルに「真のデータ (3rd Party Cookieを用いて得られるデータ)」を予測させることで課題 1. に、「ノイジーなデータ (Privacy Sandbox 環境下で得られると仮定できるデータ)」を予測させることで課題 2. に対する分析を行います。
使用モデル
本実験では、Dynalystでも実際に用いられている FFM (Field-awared Factorization Machine)(*3) という予測モデルを使用しました。FFMは特徴量どうしの交互作用をその埋め込みの内積を用いて表す FM (Factorization Machine) 系モデルの一つで、更にこのFFMでは埋め込みをField (one-hot encoding 前の特徴量単位) ごとに用意することで、より高い予測精度を得ることが出来ます。
また使用する特徴量についても、Dynalystで現在用いているものの中から、Privacy Sandbox 利用環境(*4)においても利用可能な特徴量を使用しました。
評価方法
Privacy Sandbox 環境下では ε-label-DP の枠組みに従いラベルにノイズが付与されますが、εの値 (= プライバシー保護水準) に関してはそれぞれの DSP が決められた範囲から値を設定する仕様で、明確に値が定まっているわけではありません。従って、本実験では ε の値を0から15まで変化させながら、各種評価指標の値を観察することにしました。
2) ε の値は将来的には今回の様な各アドテクベンダーの検証結果を元に Chrome が決定する予定です。
実験結果
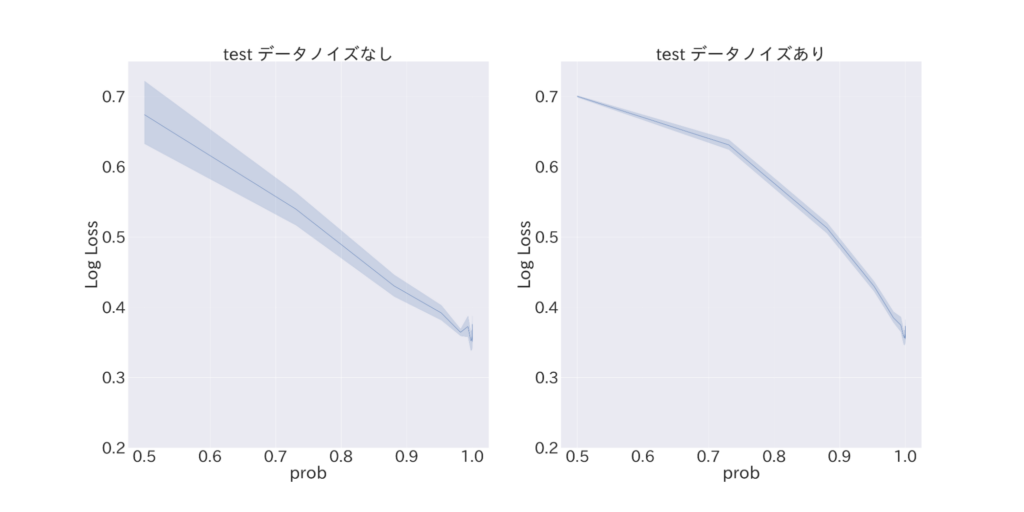
図3 真のラベルである確率pを変化させた際のlogloss
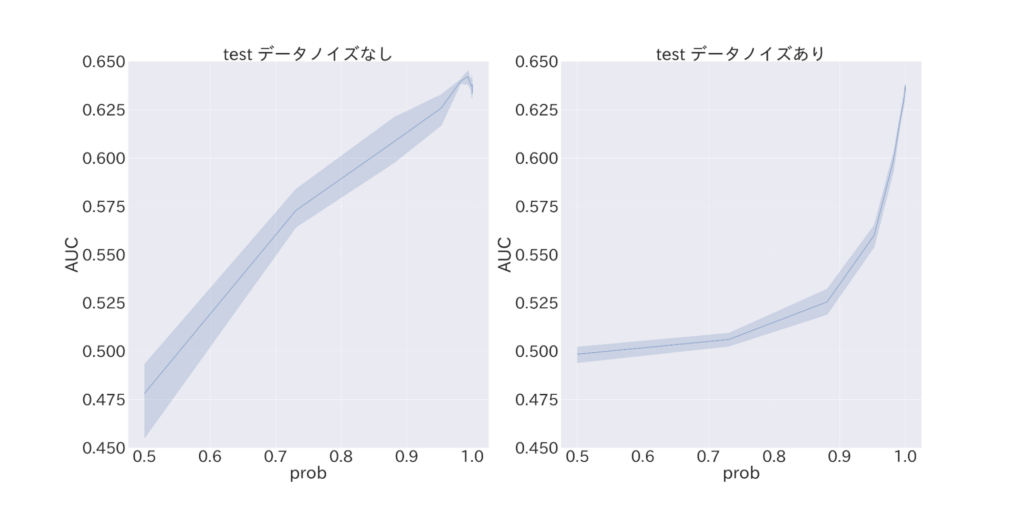
図4 真のラベルである確率pを変化させた際のAUC
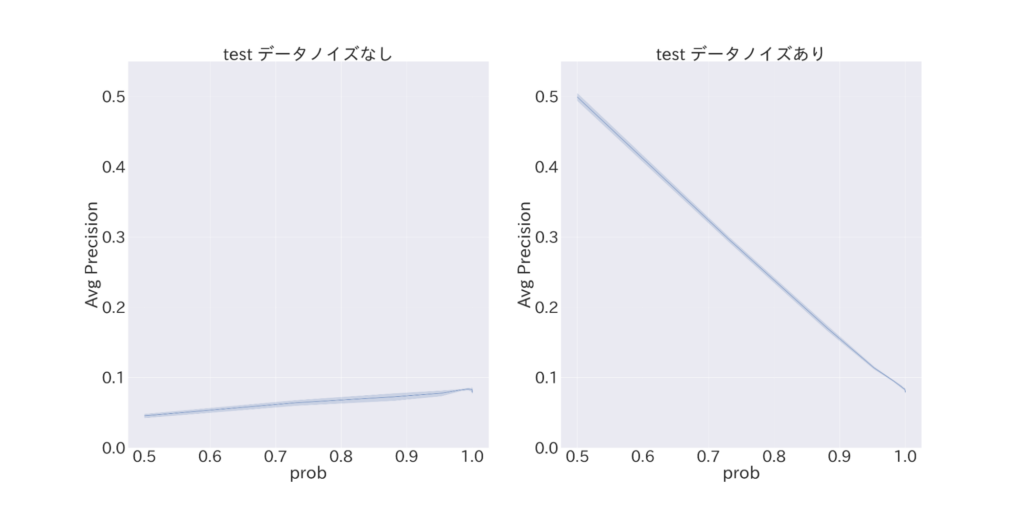
図5 真のラベルである確率pを変化させた際のaverage-precision
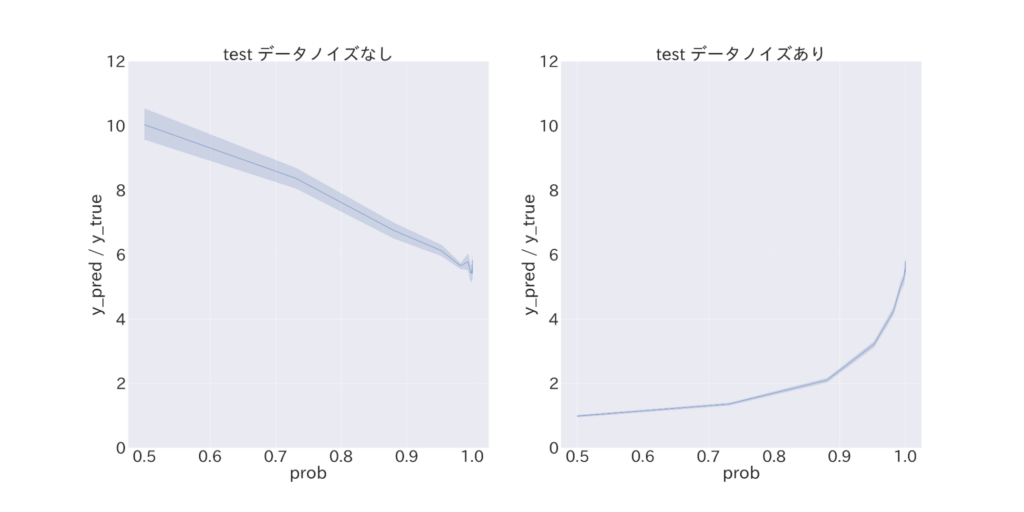
図6 真のラベルである確率pを変化させた際のcalibration
以上の図は、各種評価指標について、横軸を p (= ラベルが真のラベルである確率) とした際の信頼区間つきグラフです。
まず logloss の図3 (a) を見ると、予測確率誤差が p に対して線形に悪化することが分かります。また、図3 (b) と比較してみると、(b) の方がやや logloss の値が大きいことが分かります。このことから、Privacy Sandbox 環境下で logloss によるナイーブな予測確率精度評価を行った場合、過大評価をしてしまう傾向にあることが示唆されます。
続いて、二値分類の観点から評価値を分析してみます。AUC (= Recall (再現率) と FPR (誤って正例と検出してしまう確率) の観点から二値分類精度を示す指標) の図4 (a) を見ると、特にp < 約0.6 (ε ≒ 0.5) と比較的多量のノイズが入るような状況では二値分類を行うに足る情報が全く確保出来ておらず、モデル改良など何かしらの対処法を考える必要がありそうです。同様に二値分類精度を示す指標である Average-Precision について、 図5 (b) では図5 (a) と全く異なる評価値の動きを見せていることが分かりますが、これはノイズによりデータ中の正例負例の比率が大きく変化していることに起因する現象です。すなわち、機械学習モデルによる予測が 評価値Average-Precision に与える影響よりも、データの持つ性質が与える悪影響が上回ってしまっている状況にあります。使用データのラベル分布が不均衡であることが根本的な問題ですが、このような設定では、ノイズが付与された場合に適合率による予測精度のナイーブな評価を行うことが困難であることが示唆されます。
最後に、確率予測モデルの出力する予測値の平均的な傾向について評価を行います。テストデータ全体に対する予測値の合計と正例サンプルのサイズの比率について図6 (a) を見てみると、 ノイズの大きさに対して評価値が線形に悪化していることが分かります。二値不均衡データに対して確率予測モデルを当てる場合には、多数データにダウンサンプリングを行ってから学習を行い、その後予測値を適当に補正するアプローチが一般的(*5)です。使用モデルにおいても同様の処理を行うことで予測精度を向上させているのですが、ノイズにより使用データのラベル分布が変わった結果、予測値補正処理が効かずに予測確率が過大になってしまったと推察されます。一方で ε の値が判明している場合には、元データのラベル分布からノイズデータのラベル分布を推定することが出来るため、その分布に応じて予測値補正処理のチューニングを行うことで予測精度の改善が期待されます。
Privacy Sandbox 環境下におけるCVR予測精度改善
前章において、ラベルにノイズが付与された場合 (Privacy Sandbox 環境下) では各種評価指標の値が悪化してしまうことが実際に確認できました。そのことも踏まえて、課題の1つ
「4. ノイジーなデータを用いる場合に、予測精度の悪化を防ぐには?」
に対して答えを得るべく、調査・実験を行いました。
従来研究
教師あり学習においてラベルがノイジーであるような状況は往々にして見られます。例えば、人間による画像へのラベリング(アノテーション)では、人為的ミスによるラベルへのノイズが発生します。このような状況に対するアプローチとして、信頼に足るサンプルを選別して利用する方法(*6)(*7)が挙げられます。各サンプルの信頼度を推定する具体的な手法としては、教師なし学習(クラスタリング)と半教師あり学習を組み合わせる枠組みが提案されています。この枠組みでは、各クラスターにおいて多数決により代表ラベルを定め、代表ラベルと異なるラベルを持つサンプルは「ラベルデータ無し」として半教師あり学習を行うことで、ノイズに頑健な予測を試みています。
しかし、このフレームワークは特に画像分類タスクにおいて優れた予測精度を示す一方で、データのクラス数が少ないほどノイズへの頑健性が失われることが同論文(*7)で報告されています。また、(ノイズの無いor少ない)画像データでは、その特性からクラスタリング自体の精度も高いことが考えられますが、本インターンで扱うデータはいわゆる表形式データです。前章の実験結果からも、バイナリであるラベルを予測するという意味で精度の高いクラスタリングを行うことは難しいことが考えられます。
教師あり学習と層化k分割交差検証を用いたノイズ除去フレームワーク
そこで本インターンでは、従来手法をそのまま適用する代わりに、教師あり学習と層化k分割交差検証を用いたノイズ除去フレームワークを提案し、ノイズ除去による学習精度向上を試みました。
具体的なノイズ除去フレームワークは以下の通りです。
- (真ラベルyにε-label-DPを満たすノイズ付与を行い、ノイズラベルy_noisedとする)
- 特徴量Xとy_noisedを用いて層化k分割交差検証を行い、各ノイズラベルに対して予測値を割り当てる
- ノイズラベルと予測値の差分の絶対値を計算し、ノイズラベルの不確実性とみなす
- 不確実性が閾値を上回るラベルをノイズありラベルとみなし、ラベルの値を反転させる
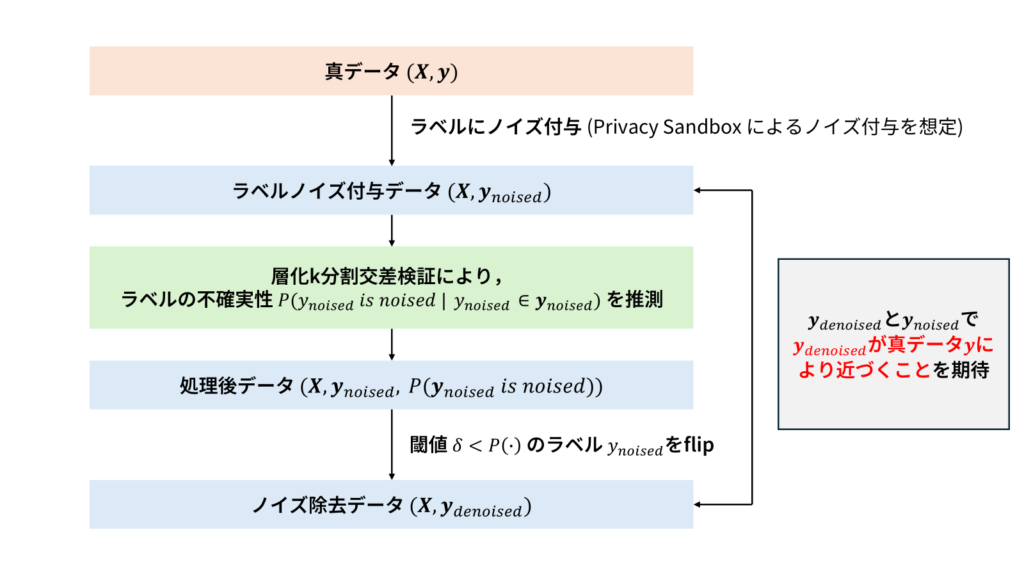 図7 ノイズ除去フレームワークの概要
図7 ノイズ除去フレームワークの概要
層化k分割交差検証では、各Foldごとのラベル分布がデータ全体のラベル分布と変わらないように交差検証を行います。学習データとテストデータの分布の差分が小さくなることで、より精度の高い学習を行うことが可能です。得られた教師あり学習モデルの予測値を真のラベルを推定する値として解釈することで、予測値と実測値の差の絶対値を、各ラベルの不確実性としてみなすことが可能です。そして、不確実性がある閾値を超えた場合に、そのラベルをノイズ付与ラベルとみなし値を反転させることで、ノイズ除去効果が期待されます。実験内容
本実験では、人工データ・実データを用いて先述のノイズ除去フレームワークのノイズ除去効果を調査しました。本記事では、人工データを用いた実験結果について紹介します。
本実験では、ε-label-DPを用いてノイズを付与したラベルに対して前述のノイズ除去を行い、真のラベルとノイズ除去後のラベルを比較することで、ノイズ除去の効果を測定しました。実験方法、コードと、行った全ての実験結果はGitHub(*8)に記載しています。
実験結果
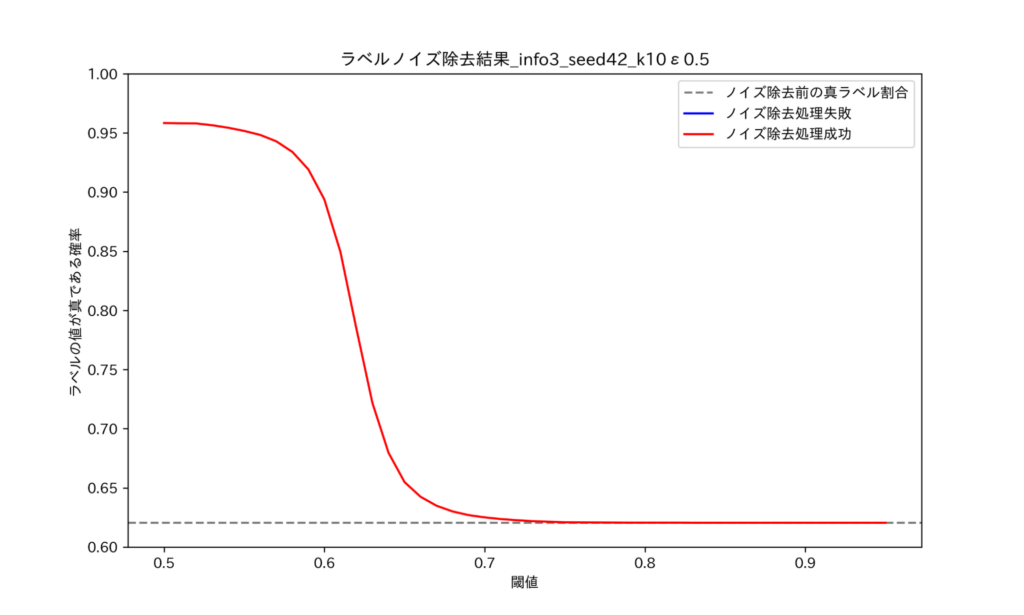 図7 ノイズ除去後ラベルが真ラベルと同一である割合_ε=0.5
図7 ノイズ除去後ラベルが真ラベルと同一である割合_ε=0.5
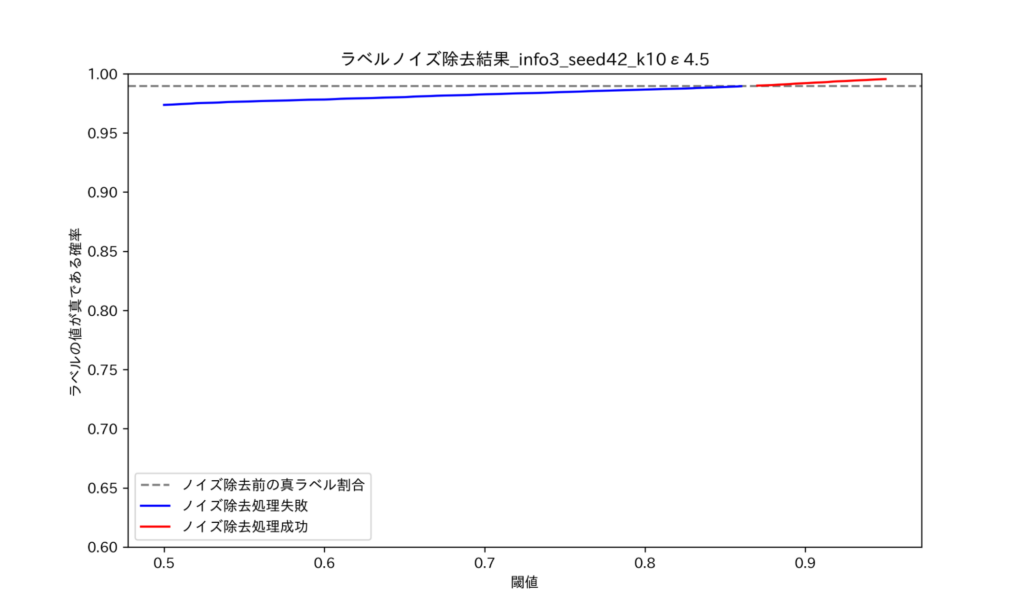 図8 ノイズ除去後ラベルが真ラベルと同一である割合_ε=4.5
図8 ノイズ除去後ラベルが真ラベルと同一である割合_ε=4.5図は、それぞれε=0.5, ε=4.5の時のノイズ除去精度を示しており、横軸が閾値、縦軸が真ラベルである確率、灰色の横線がノイズ除去を行わない状態 (における真ラベル確率) を表しています。図を見ると、ε=0.5においてはノイズ除去の効果が非常に高いことが確認できます。本記事に載せていない範囲を含めると、ε=0.5~4.0 (p = 0.65~0.90)においてノイズ除去による効果を確認できました。一方で、実データを用いた実験では ε の大きさに関わらずノイズ除去の効果を確認することが出来ませんでした。このことは、データの学習しやすさにより説明ができると考えられます。つまり、予測値を正確に予測できるようなデータであれば、不確実性についてもより正確に予測することが可能であり、従ってノイズ除去も効果的に行えるということです。実際に、データの学習しやすさを変化させながら実験を行った所、データの学習しやすさが大きいほどノイズ除去の効果が大きくなることが確認できました(*8)。
まとめ本インターンでは、Privacy Sandbox 環境下におけるCVR予測シミュレーション、並びにノイズ除去手法の適用を行いました。挙げた課題に対する実験は概ね行うことが出来ましたが、その一方で、ノイズに頑健な予測手法の更なる調査・分析や、入札に至るまでのシミュレーションなど、主に時間的制約の面で行うことが出来なかった課題も残る結果となりました。
最後に
CA Tech JOB 生として Dynalyst チームにお世話になったこの1か月は、とても充実したものでした。トレーナーの河野さん、メンターの暮石さんは勤務毎に必ず進捗報告・相談の時間を設けて下さり、他にも決して少なくない時間を自分にかけて下さりました。お二人に頂くレビューはもちろん、他愛のない会話の中でも様々なことを教えて頂き、短い期間ではありましたが大きく成長することが出来たと思っています。また、週3回の勤務のうち2回はサイバーエージェントで働くデータサイエンティストや研究者の方々とのランチを組んで下さり、技術的な面はもちろん、サイバーエージェントの文化や魅力についても知ることが出来るとても貴重な機会を頂くことが出来ました。
改めて、トレーナーの河野さん、メンターの暮石さん、親しく接して下さったチームの皆さん、一緒にランチに行って下さった皆さん、担当人事さん、ほか関わって下さった社員の皆さん、本当にありがとうございました。
参考文献
*1) https://github.com/WICG/turtledove/blob/main/FLEDGE.md#32-on-device-bidding
*2) 寺田雅之. 2019. “差分プライバシーとは何か.” システム/制御/情報 63 (2): 58–63.
*3) Juan, Yuchin, Yong Zhuang, Wei-Sheng Chin, and Chih-Jen Lin. 2016. “Field-Aware Factorization Machines for CTR Prediction.” In Proceedings of the 10th ACM Conference on Recommender Systems. New York, NY, USA: ACM. https://doi.org/10.1145/2959100.2959134.
*4) https://privacysandbox.com/intl/ja_jp/
*5) Pozzolo, Andrea Dal, Olivier Caelen, Reid A. Johnson, and Gianluca Bontempi. 2015. “Calibrating Probability with Undersampling for Unbalanced Classification.” In 2015 IEEE Symposium Series on Computational Intelligence, 159–66. IEEE.
*6) Li, Junnan, Richard Socher, and Steven C. H. Hoi. 2020. “DivideMix: Learning with Noisy Labels as Semi-Supervised Learning.” arXiv [Cs.CV]. arXiv. https://openreview.net/pdf?id=HJgExaVtwr.
*7) Tang, Xinyu, Milad Nasr, Saeed Mahloujifar, Virat Shejwalkar, Liwei Song, Amir Houmansadr, and Prateek Mittal. 2022. “Machine Learning with Differentially Private Labels: Mechanisms and Frameworks.” Proceedings on Privacy Enhancing Technologies 2022 (4): 332–50.
*8) https://github.com/shobigrock/conv-denoise-system/tree/main