
サイバーエージェントが主催する生成AIに特化した技術勉強会「CA. ai#1」。社内における生成AIの活用法の紹介をはじめ、生成AIの力を最大限に活かす話題の生成AIツールを徹底解説します。
AWS Japan様をゲストにお迎えし、CAを代表する基盤モデル「OpenCALM」の開発に取り組んだ、弊社AI事業本部 基盤モデル開発者・石上 亮介とのパネルディスカッションも開催! 今ホットなキーワードをピックアップし、生成AIの未来についての見解をお話いただきました。
本記事は、2025年03月27日(木)に開催した「CA.ai #1 サイバーエージェントが主催する生成AIに特化した技術者向けの勉強会」において発表されたパネルディスカッション「生成AIの進化と未来戦略 〜サイバーエージェント x AWSが語る最前線〜」に対して、社内の生成AI議事録ツール「コエログ」を活用して書き起こし、登壇者本人が監修役として加筆修正しました。
パネリスト
■ AWS Japan 技術統括本部 Machine Learning Developer Relations
久保 隆宏
2021 年より AWS の機械学習領域専門のデベロッパーリレーションに従事。 AWS が機械学習をはじめるのに最適なプラットフォームになるよう、戦略の立案、コンテンツの開発、フィードバックの収集に基づくサービス開発チームへの提案まで一気通貫で活動。近年特にプロダクト開発チーム向けの機械学習活用支援に従事。 GitHub で公開している ML Enablement Workshop は AWS Japan の中で最も Star 数の多いリポジトリの一つに。
■ 株式会社サイバーエージェント 基盤モデル事業部 機械学習エンジニア
石上 亮介
2021年 株式会社サイバーエージェント 中途入社。前職はAIベンチャーにてデータ分析業務に従事。現在はAI事業本部で「極予測LP」の開発、大規模言語モデル(LLM)をはじめとした基盤モデルプロジェクトのリードを担当。画像やテキストを対象としたマルチモーダルなAIの社会実装に従事している。
モデレーター
■ 株式会社サイバーエージェント AI事業本部 極AI予測チーム
イ ドンホ
2023年にサイバーエージェントに新卒入社。AI事業本部の極AI予測チームにて、機械学習エンジニアとして広告効果改善に向けたデータ分析とモデル開発を担当。統計から機械学習、MLOpsまで、幅広い領域で活躍中。CA.aiコミュニティリーダーとして、生成AI開発を促進するためのコミュニティを運営。
オープニング
イ ドンホ:ここから第2部、司会とパネルディスカッションのモデレーターを担当いたします、イ・ドンホと申します。よろしくお願いいたします。本日のテーマは「生成AIの進化と未来戦略」としております。それぞれ自己紹介していきましょうか。

久保:私はAWS Japanで、機械学習領域のDeveloper Relationsを担当している久保と申します。Developer Relationsの役割は、機械学習といえばAWSと思っていただけるように、ブログの執筆やサンプルコードの開発、そして今回のようなイベントでの登壇などを行うことです。それに加えて、AWSのサービス開発チームに対して「こういったフィードバックがありました」と伝え、サービス改善につなげていくことも重要な仕事の一つです。
特に私が力を入れているのは、機械学習および生成AIを実際のプロダクション環境で使っていただくという部分です。昨年は、AWS上で生成AIが実際にサービスや本番業務に使われた事例を収集・公開しました。おそらく現時点では、AWS Japanの中で最も日本国内の生成AI活用事例に詳しいと思います。また、お客様向けに生成AIをプロダクションに導入するためのワークショップの提供も行っています。もともと機械学習の研究者としても活動していた経験がありますので、そういった知見も活かしながら取り組んでいます。本日はどうぞよろしくお願いいたします。
石上:サイバーエージェント基盤モデル事業部の石上と申します。普段は、いわゆる基盤モデルの開発に携わっており、例えば弊社のLLM開発にも取り組んでいます。具体的には、CALMと呼ばれる大規模言語モデルの開発などを担当しています。
本日ご一緒している久保様とは、実はAmazon Bedrock Marketplaceにて、CyberAgentLM3を取り上げていただいたことをきっかけにやりとりをさせていただいております。そうしたご縁もあり、本日ご一緒できることを嬉しく思います。よろしくお願いいたします。
イ ドンホ:はい、私は2年前にサイバーエージェントに新卒で入社したイ ドンホと申します。現在はAI事業本部に所属し、広告効果を予測する機械学習モデルの開発を行うエンジニアとして働いています。
私自身も、生成AIについては業務の中で実際に活用しながら、同時に日々学びを深めているような立場ですので、本日はお二方にいろいろと質問させていただければと思っています。どうぞよろしくお願いいたします。
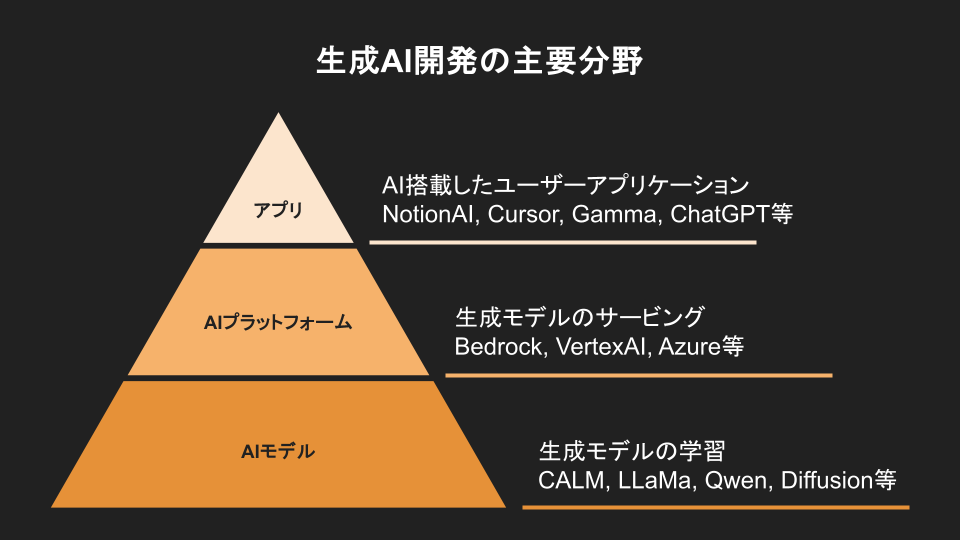
イ ドンホ:それではさっそく生成AIについてお話できたらと思います。生成AIの開発といっても非常に多岐にわたるため、ざっくりとこのような図で分類してみました。
まず一番上の層では、LT会でもAIエージェントやさまざまなアプリの紹介がありましたが、実際にAIを活用したアプリケーションの部分があります。このアプリを開発するには、石上さんからもご説明があったように、AIモデル、特に最近注目されている基盤モデルが必要になってきます。そのため、モデルを構築し、学習させるという役割の方々がいらっしゃいます。
さらに、そのモデルを実際のアプリに組み込むためには、モデル単体では呼び出すことができないケースもあります。そこで、プラットフォームとして、アプリ開発者に対してAIモデルを提供する役割の方も必要になります。
今日はAIの基盤モデルを開発されている石上さんと、プラットフォーム構築に深く関わっていらっしゃる久保さんにご参加いただいていますので、それぞれの視点からお話を伺えればと思っています。
石上:少し補足させていただくと、AWSさんはAIモデルはもちろん、AIプラットフォーム、さらにはアプリケーションの部分に関しても非常に幅広く取り扱われている印象があります。ですので、そのあたりについても幅広くお話を伺えるのではないかと期待しています。
久保:ちなみに、AWSが提供しているモデルとしては、Amazon自身が開発している基盤モデルであるAmazon Novaがあります。また、AIプラットフォームについては、SageMaker に代表される機械学習・基盤モデルの開発・運用を行う機能が充実している領域です。さらにアプリケーションの面では、Amazon Q、特に開発者向けのサービスとしてはAmazon Q Developerも提供されています。
こうした点を踏まえて、モデルからプラットフォーム、アプリケーションまでトータルでお話しできればと思っています。
イ ドンホ:ありがとうございます。本日のディスカッションでは、こちらにご用意した9つのトピックに沿って進行していきたいと考えています。
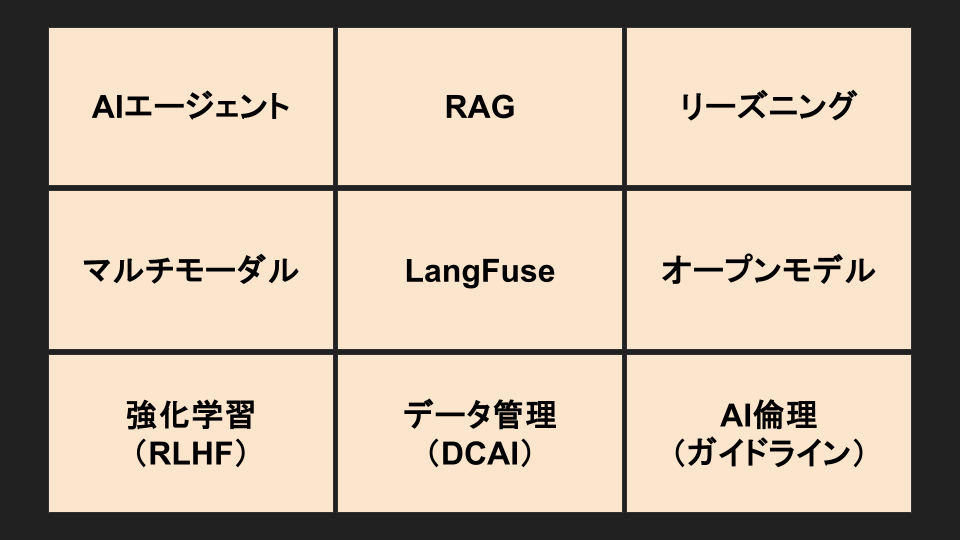
まず最初に、一部のLT会でも多く取り上げられていたテーマであるAIエージェントについてお話ししたいと思います。
AIエージェント
これからのAIエージェントを実際に機能させていくために、特に重要になってくるであろうAIの機能や開発要素について、注目している点があれば教えていただけますか?

石上:自分は基盤モデルの開発者という立場でもあるので、まず一番重要だと思っているのは、AIエージェントに使われる基盤モデルの「賢さ」、つまり、使われているモデルがGPT-4.5なのかClaude 3.7なのかといった部分です。この基盤モデル自体がある程度の知性や性能を持っていないと、どれだけAIエージェントの設計や構築を工夫しても、最終的にはその性能に限界が来てしまうというのは、おそらく多くの方が共通認識として持っているところではないかと思います。ですので、まず前提として、ベースとなる基盤モデルの性能が今後さらに高まっていくことが非常に重要だと考えています。
もうひとつ注目しているのは、その賢いベースモデルをもとに、次に「賢いAIエージェントシステム」をどう作り込んでいくか、というフェーズです。ここでは、単に優れた基盤モデルを使うだけではなく、そのモデル自体にも追加の調整や特化が必要になるのではないかと考えています。
というのも、OpenAIが現在開発・公開している「Deep Research」というリサーチ系のAIエージェントサービスがありますよね。そこで開発者の方が話されていた内容として、そのDeep Research専用にOpenAI o3モデルを使って、エンド・ツー・エンドでリサーチタスクができるように追加でチューニングを施しているという旨のコメントがありました。
つまり、単にo3をそのまま活用するのではなく、AIエージェントに特化させるような形で、基盤モデル自体をさらに進化させているというアプローチです。そうすることで、より賢いAIエージェントシステムを構築していこうというのが、OpenAIの取り組みなのではないかと捉えています。
ですので、私の考えとしては、まず基盤モデル自体の賢さが大前提として必要であり、そこに加えてAIエージェント向けにさらに作り込みを行うことで、非常に優れたシステムが実現できるのではないかと考えています。
久保:私はもともと強化学習にも関わっていたので、「エージェント」という言葉を聞くと、まず強化学習におけるエージェントを思い浮かべます。その考え方自体は、今の生成AIの文脈におけるエージェントにも大きく共通する部分があると感じています。つまり、エージェントというのは、エージェントそのもの、エージェントが動作する環境、そしてその環境の中でエージェントが取りうるアクション、この3つの要素で基本的には構成されていると思います。
エージェント自身の「賢さ」という点については、先ほど石上さんからもお話があったように、ここ数年で非常に進化しています。では、エージェントが私たちにとって望ましい結果、つまり報酬を得るためには何が必要なのかというと、それはエージェントが実際にどのようなアクションを取れるのかということ、そしてそのアクションを実行可能な環境が整っているかどうか、この2つが重要になってくると考えています。
アクションに関しては、まさに今日の講演でも触れられていたMCPですね。以前はテキストを出力するだけだったのが、今ではブラウザの操作も可能になり、APIを呼び出したりと、いわゆるツールユースの領域が一気に広がっています。こうしたAIエージェントが取れるアクションの拡張という流れは、今後も非常に注目されるトレンドだと思います。
その一方で、少し見落とされがちなのが「環境」だと感じています。たとえば、ブラウザを操作させるといった場合に、人間の使用しているコンピューターに直接アクセスさせるのはリスクが高すぎます。ですので、安全に操作できるサンドボックス環境や、適切に権限が制限された実行環境が必要になるのではないかと考えています。
例えば、StripeのSDKなどでは、AIエージェント用のSDKが提供されており、その際に予算を設定できる仕組みがあります。5000円までなら問題ない、といった指定ができるということです。こうした制約を設ける環境の用意も、AIエージェントに行動を委ねていく際には非常に重要な要素となります。
また、AWSはインフラの会社でもありますので、AIエージェントのインフラをどれだけ簡単に、あるいは便利かつ安全に構築できるかという点は、今後注目すべきトレンドだと考えています。
RAG

イ ドンホ:はい、ありがとうございます。AIエージェントをどのような環境で活用していくかという点については、まさに久保様が日々試行錯誤されているところかと思いますし、まだまだ道半ばといいますか、実際の事例も少ない状況ですので、今後の進展がとても楽しみな領域だと感じています。
さて、ここからはもう少し一般的にも知られている機能について話してみたいと思います。一部でも話題に上がっていたRAGですね。最近では、多くのAIエージェントでRAGが基本機能といえるくらい広く使われています。
私自身、広告分野に関わっている中で感じるのが、ドメインの不安定さやトレンドの変化の速さです。ナレッジソースが頻繁に更新されることも多く、そうした状況下でRAGの精度をどう担保していくかが課題になっています。
そこでお伺いしたいのですが、ナレッジが流動的な状況やデータの不安定性がある中でも、RAGの精度を保つために意識すべき点、あるいは評価を行う際に「ここを見ればいい」というようなポイントがあれば、ぜひ教えていただけないでしょうか?
石上:精度を担保するという観点では、やはり高品質なシステムを構築することが求められます。そのうえで評価の話、つまり「どこを見ればよいか」という点についてですが、これはやや一般論にはなってしまうかもしれません。ただ、RAGを専門に扱っている方であれば当然のこととして受け止められると思いますが、基本として押さえておきたい点です。
RAGという仕組み自体が、検索と生成の2つのパートで構成されています。まず、データソースから情報を検索して取得し、その取得した情報をもとにLLMが回答を生成する、というのがオーソドックスな流れです。
ですので、まず評価すべきポイントとして挙げられるのは、「検索で正しく情報を取得できているかどうか」、つまり検索精度の部分です。検索パートで的確な文章が取れていない場合、その後の生成も当然ずれてしまうため、ここの精度は非常に重要になります。
次に、検索で得られた情報をLLMに入力して回答を生成する際の「回答の品質」も見ていく必要があります。具体的には、ハルシネーションが発生していないか、つまり間違ったことを言っていないかどうか、そしてユーザーのクエリに対して過不足なく、きちんと回答ができているかといった点です。
このように、RAGの評価は大きく「検索の精度」と「生成された回答の品質」の2つの観点に分けて考えることが重要になります。
今のところ、RAGに関するプラクティスやナレッジもかなり出てきている印象があります。たとえば、RAGASと呼ばれるような評価項目のフレームワークがあり、「こういう観点で評価するとよい」というガイドラインが提示されていたりします。また、LangChainのようにRAGを構築できるライブラリの中にも、評価をサポートする機能やツールが備わってきており、以前に比べると評価環境自体は整ってきていると感じています。
ですので、RAGの評価そのものに関しては、ある程度実践可能な状態にはなってきていると思います。一方で、正直なところ、RAGが「うまく機能するかどうか」という点に関しては、結局のところ「どれだけデータソースがきれいに整備されているか」に強く依存していると感じます。
特に、社内のドキュメントを見てみると、雑に作られたスライドや、Notion上に断片的に散在している情報、あるいはSlack上の細かいやり取りの中にしか存在しない知見など、なかなか構造化されていない情報が多いのが現実です。ですから、RAGを本当に有効に活用するには、いかにそういった情報を整理して、AIネイティブな形式で使いやすいデータとして蓄積しておけるかが、最終的には最も重要なポイントになるのではないかと考えています。
イ ドンホ:ありがとうございます。私もまさに同じように感じていて、データ管理こそがAI開発の“命”ではないかと思うことがよくあります。特にRAGのような仕組みを取り入れる場合、ナレッジソースをどう整備・運用していくかは、精度や運用性に直結する非常に重要なポイントです。
それでは、ここから久保さんへの質問になります。RAGをより効率的に実装・運用していくうえで、一般的に知られていることも多いかと思いますが、久保さんご自身が「これをやっておくと効率が上がる」「これは押さえておくと良い」と感じているチップやノウハウがあれば、ぜひご紹介いただけないでしょうか?
久保:「これをやればいいよ」という点で言うと、まずベースになるのは、いわゆる「Advanced RAG」と呼ばれる論文でまとめられている手法だと思います。そこに記載されている内容は、実は本質的には昔から検索システムで言われてきたことと大きくは変わっていない部分も多いです。
たとえば、ユーザーの問い合わせをより明確に、具体的にするためのクエリ拡張や、データソースを適切に整備すること。そして、生成時には複数の生成結果を並び替え組み合わせて回答を作成するなど、いくつかの「鉄板」な手法があります。こうした方法をきちんと実装していくことが、まずはオーソドックスかつ効果的なアプローチになると思います。
ここまでがテクニカルな観点からのお話になりますが、私自身はビジネス側も見ているので、RAGの「精度をどこまで上げればいいのか?」という点が、実は非常に重要だと感じています。
日清様の事例では、RAGの精度が上がっていくことで業務効率も向上していく、という相関関係を示すデータが出ていた一方で、ある程度精度が向上した段階からは、精度の向上に比べて業務効率の伸びは緩やかになることも分かっています。
つまり、RAGの性能をひたすら上げることが目的なのではなくて、あくまで「業務」や「サービス」に資するためにRAGを活用している、という前提を忘れないことが大事です。どこまでの性能が必要なのかという“天井”を見極めたうえで、そこに向かって必要な改善を行う。この視点がとても重要だと考えています。
リーズニング
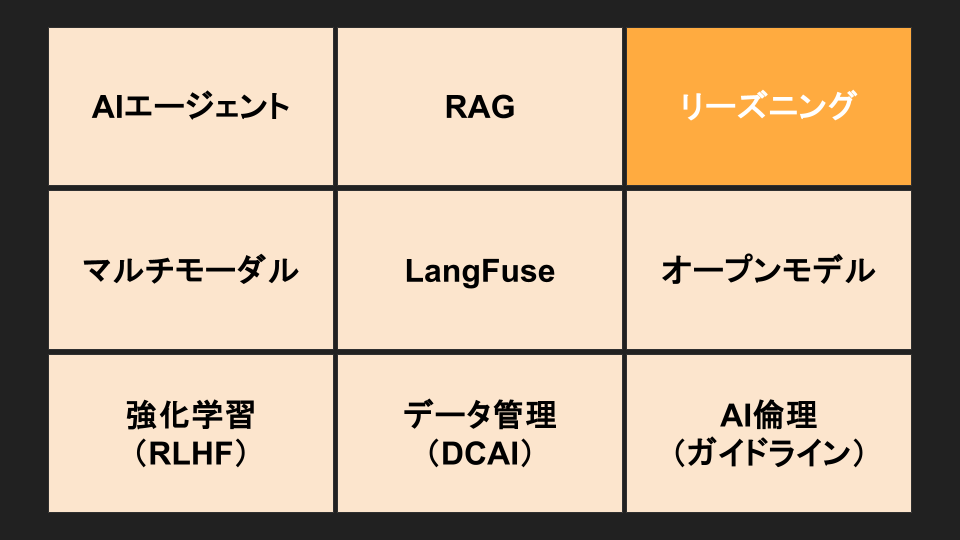
イ ドンホ:ありがとうございます。おっしゃる通りで、RAGに何をどこまで求めるかという視点はとても重要ですし、その延長線上にあるテーマとして、今まさに注目されているのが「リーズニング」だと思います。
ここからは、石上さんと久保さんのお二人にお伺いしたいのですが、リーズニングに関して、普段一番難しいと感じているポイントについて教えていただければと思います。
石上:リーズニングについては、視点によって2つの側面があると考えています。まず、開発者目線、つまり基盤モデルを開発する立場から見ると、モデルがどういう思考プロセスを経ているのか、どういった「シンキング」をしているのか、そしてその思考の深さや長さがどの程度なのかという点は非常に重要です。それによって、最終的なアウトプットの質に大きく影響してくるからです。
一方で、1ユーザー、あるいはプロダクト利用者の視点で見ると、実際にはシンキングのプロセスはプロバイダー側で非表示にされているケースも多く、正直なところ「結果さえ正しければいい」と捉えている人も多いのではないかと思います。
ただ、リーズニングが複雑になると、当然シンキングの長さも伸びてきますし、その分トークン数も増えます。今のモデルの多くが従量課金である以上、長く考えれば考えるほどコストが高くなってしまうという現実的な問題もあります。
理想を言えば、できるだけ短く、簡潔なシンキングで高精度なアウトプットが得られるようになることが望ましいのですが、現状では「長く考えるほうが性能が出やすい」という傾向があるため、そこは今の技術的なトレードオフとして、ある程度受け入れるしかないのかなと考えています。
久保:リーズニングについては、先ほど石上さんからもお話があったように、「どれだけ考えるか」をどうコントロールするかという点が、利用する側にとっての大きなキーワードになってきていると感じています。
最近リリースされたAnthropicのClaude 3.7では、シンキング用のバジェットを設定できるようになっていて、「このくらいの範囲内で考えていいよ」というように、シンキングに費やすリソースをある程度コントロールすることが可能になっています。これは従量課金のある環境では、非常に実用的な機能だと思います。
こうしたコスト面のコントロールは、利用者側が直面する現実的な課題として存在していますが、開発側にとってのチャレンジはまた別のところにあります。それは「シンキングを学習するためのデータソースをどう用意するか」という点です。
人間は通常、思考のプロセスすべてを明示的に書き出してくれるわけではありません。したがって、「正しい答えに至るまでの思考の過程」をデータとしてどのように構造化し、どのようにモデルに学習させていくか。また、その思考プロセスに対して、どう評価を行えばよいのか。これらは非常に難しいテーマでありながら、今後のリーズニング系モデルの発展にとって重要なトピックだと考えています。
石上:今、例えばDeepSeek R1というシンキングモデルであったりとか、あとはo1、o3というChatGPTのモデルがあると思うんですけれども、それらはおそらくリーズニングに特化して追加学習がされたモデルだと言われていると思います。
一方で、最近のClaude 3.7の最新版ですと、リーズニングに特化されて作られたモデルというわけではなくて、リーズニング機能、それから一般的な生成の機能、両方を一つのモデルの中に入れたものだと、確かAnthropicの方がおっしゃっていたと思います。
なので、そのあたり、リーズニングに特化させるというよりは、もう初めからリーズニングもさせるし、汎用的なモデルとしても使えるように作り込むことで、全体としての能力や使い勝手が上がるというのが、今けっこう新しいトレンドとして出てきているのかなと思います。
そのあたりは、今後いろんなプロバイダーがどんどん取り入れていくんじゃないかなと思いますね。
久保:確認を取ったわけではないのですが、私がなぜAnthropicが一つのモデルにまとめたのかと考えているかというと、おそらくエージェントで効率的に活用するためではないかと思っています。
というのも、エージェントはタスクの初期段階では、かなり細かくタスクを分解したり、状況を理解したりと、リーズニングに使うバジェットが多く必要になる場面が多いです。一方で、タスクの終盤になってくると、与えられた内容に対してすぐに答えを返せばよいというケースも増えてきて、必ずしも複雑なリーズニングを行う必要はなくなってきます。
そうなると、シーンごとに「考えるときはこのモデル」「考えなくていいときは別のモデル」といったように、アプリケーションのコード上でモデルを切り替えるのは、開発や運用の面でかなり手間がかかると思います。そこで、一つのモデルの中で「今はじっくり考えるべきか、あるいはすぐに答えていいか」を判断しながら、トータルでエージェントのタスクをこなせるように設計しているのではないかと、個人的には考えています。
マルチモーダル
イ ドンホ:RAGやリーズニングについては、まだまだ多くの課題が残っているのが現状です。その一方で、これからさらに注目されてくるのが、マルチモーダルの領域だと感じています。
少し質問の範囲を広げる形になりますが、ここでお伺いしたいのは、マルチモーダルモデルやマルチモーダルエージェントに関してです。具体的には、マルチモーダルであることによって、開発や設計の中でさらに重要になってくるポイントがあるとすれば、それはどのような点かというところについて、石上さんにご紹介いただければと思います。
何か注目している観点や、実際の開発で意識している点があれば、お聞かせいただけますか?
石上:ちょうどホットなトピックとして、今週、GPT-4oのイメージジェネレーション機能が一般に開放されました。
これは、従来のGPT-4oの機能の一部として、画像生成に関する機能が利用可能になったというもので、業界的にもかなりインパクトの大きいニュースだったと感じています。
では、なぜこれがこれほどまでに大きなインパクトを持ったのかというと、従来のテキストtoテキスト、つまりユーザーがテキストで指示を出し、テキストで回答を得るという一方向のやり取りだけではなくなった点にあります。今回のアップデートによって、テキストtoイメージという形で、テキストから画像を生成することができるようになったのです。
この変化が重要なのは、従来であればテキスト、テキスト、テキストというやり取りの流れが、テキストに対して画像が返ってきて、さらにそこに対してまたテキストで指示を出し、その画像を編集する、といった新しいインタラクションが可能になったことにあります。これまで、画像生成や画像編集といった処理には、それぞれ特化した単一のモデルを使う必要がありました。たとえば、着色や線画の抽出、一部分の編集や画風変換といったタスクごとに異なるモデルが用いられていたのが一般的でした。
しかし、今回のGPT-4oのイメージジェネレーション機能では、そうした複数の画像処理タスクを、一つの統合モデルで対応できるようになったという点が大きな進歩です。今後さらに機能は進化していくと思いますが、現在の時点でも、その汎用性の高さは非常に注目されています。
実際、ChatGPTが登場したとき、自然言語処理(NLP)分野では、従来は個別に扱われていたタスクが、一つの大規模モデルで包括的に解けるようになったという大きな転換点、いわゆる「ChatGPTモーメント」がありました。同じように、今回のGPT-4oの画像生成機能は、コンピュータビジョンの領域における「ChatGPTモーメント」と言えるような現象なのではないかと感じています。
このような背景からも、今回の機能追加は業界全体に大きなインパクトを与えるものであり、非常にホットなトピックとなっていると思います。
久保:私もChatGPTの画像生成機能には驚きました。
この中にも、たとえばGANを使ったImage TranslationやStyle Transferといったワードを聞いたことがあったり、関連する論文を読んだりしていた方がいらっしゃると思います。そうした領域って、従来は本当にそのタスクに特化したモデルを一つ用意して、ようやく実現できるようなものだったはずなんですよね。それが、いまやテキストでちょっと指示するだけでサッと画像が出てくる。「そんなバカな!」と思ってしまうくらい驚きはあります。それくらい、技術がすごいスピードで進んでいることを実感しました。
こうした自由度の高い表現が可能になってきているというのは、2つの大きな意味を持っていると考えています。ひとつは、以前エージェントの話の中でも触れた「エージェントが取りうる行動」の幅が広がっているという点です。これまでテキストだけだったインタラクションが、画像を介したやり取りまで可能になってきていて、これが非常に強力な変化だと感じています。
これによって、コミュニケーションの手段そのものが広がりますよね。人間同士でも、言葉だけでうまく伝えられないときはホワイトボードに図を書いて説明する、みたいなことって普通にあると思います。そうした“マルチモーダルなコミュニケーション”がAIでも可能になることで、より正確な意思疎通が実現できるようになるのではないかと考えています。
そしてもう一つは「環境」の面です。たとえばホワイトボードに書かれた文字を読み取るとか、音声を理解するとか、人間が自然にやっているような環境認識が、マルチモーダルモデルによって実現可能になってきています。これによって、言葉では伝えきれないニュアンスや意図をAIがくみ取れるようになってくるんじゃないかなと思っています。
たとえば、皆さんが使っているようなCoding Agentでも、コードだけでなく、インフラ構成図のようなビジュアル情報を読み取る場面ってありますよね。マルチモーダルなモデルがそういった図表を読み込めるようになると、まさに人間のように資料を読み解き、より正確な提案やコーディングが可能になってくるのではないかと、個人的にはかなり期待しています。
Langfuse
イ ドンホ:さて、ここからは少し話題を変えて、日々のモデル開発に関するお話をお聞きしたいと思います。キーワードとしては「Run:ai」「Weights & Biases」など、学習支援や管理のためのプラットフォームが挙げられているのですが、Langfuseに限らず、さまざまなツールが存在している状況かと思います。
石上さんは実際にモデルの学習をご担当されている方ですので、普段どのような学習プラットフォームをどのような目的で使用していらっしゃるのか、また特に注目して見ているポイントがあれば、ぜひこの場にいらっしゃるデベロッパーの方々にご紹介いただければと思います。いかがでしょうか?
石上:私は基盤モデルの開発者として日々取り組んでいますので、実験管理の観点からは、機械学習モデルの開発においてWeights & Biasesというサービスを活用しています。これを使って、学習がどのように進んでいるかを細かく追いながら実験を進めています。
たとえば画像生成モデルの場合、学習の途中でどんな画像が生成されているかといった出力もリアルタイムでモニタリングできるので、モデルの挙動を視覚的に確認しながら、チューニングや改善の方向性を見定めるのにとても役立っています。
とはいえ、AWSにはさまざまな強力なサービスが揃っていると思いますので、プラットフォームの使い方や選定のポイントについては、むしろ久保さんにお話しいただいた方が参考になるのではないかと思います。久保さん、いかがでしょうか?
久保:AWSでもエージェントを構築する際には、Amazon Bedrock Agentという仕組みがあり、エージェントの開発を支援するだけでなく、いわゆるObservability、つまり監視や挙動の追跡といった機能も提供しています。もちろん、Langfuseのようなエージェント監視ツールもAWS状にホスティングして利用することが可能です。
こうしたLangfuseのような監視ツールが重要になる理由には、大きく2つの観点があると考えています。まず開発フェーズにおいては、エージェントにある程度の判断や行動を委ねるという性質上、従来の決定的なコードとは異なり、挙動が非決定的になることがあります。そのため、どのようなプロンプトで、どのような処理が行われ、最終的にどうなったかという一連の流れを可視化するObservabilityが非常に重要になります。こうした背景から、開発の現場ではこの種のツールのニーズが高まってきていると感じています。
もう一つは運用フェーズです。もちろん、障害が発生した際にどこで問題が起きたのかを追跡する目的もありますが、それに加えて、AWSのコミュニティの方から伺った話の中で印象的だったのが、実際にエージェントをデプロイして利用が進むと、想定以上にコストがかかることがあるという点です。エージェントはリーズニングなども含めて大量のトークンを消費するため、使用状況によってはかなりのコストインパクトが発生します。
そうした状況では、高性能なモデルからコスト効率の良いモデルへ切り替えるといった対応が求められますが、その際にモデルを変えても挙動に問題が起きないかを確認する必要があります。そういったテストや運用監視の場面でも、こうしたツールが重要になってくると思います。
このように、開発と運用の両面において、エージェントに特化した監視や分析のためのツールが強く求められてきていると実感しています。
オープンモデル
イ ドンホ:今回も学習の話が出てきたということで、モデルそのものについても少し触れておきたいと思っていまして、その前段としてこの質問をさせていただきました。
先ほどDeepSeekの話も出てきたように、最近はオープンモデルの性能が非常に高くなってきています。その一方で、ChatGPTのようなクローズドモデルのパフォーマンスの高さも依然として注目されていますし、クローズドな設計だからこそ実現できている部分もあるのではないかと感じています。
そこでお二方に伺いたいのですが、肌感覚として、これからの主流は本当にオープンモデルになっていくと思われますか? それとも、クローズドモデルにもまだ大きなメリットや競争力が残っているとお考えでしょうか?
石上:おそらく今もそうですが、今後もしばらくはオープンモデルとクローズドモデルの両方が並行して存在し続けるのではないかと考えています。
現状を見ると、アメリカのビッグテックは基本的にクローズドモデルを主流としています。たとえばGemini、Claude、ChatGPTといった代表的なモデルはいずれもクローズドで提供されています。一方で、中国のモデルはオープンな方向に進む傾向が強いように感じています。
たとえば先ほども話に出たDeepSeekは非常に強力なオープンモデルとして注目されていますし、アリババが開発しているQwenというモデルも、非常にパフォーマンスが高く、かつオープンに公開されていることで知られています。このように、オープンなモデルが次々に登場している一方で、クローズドなモデルも引き続き進化を続けており、両者が共存している状況です。
特にDeepSeekは最近非常に注目されているモデルで、つい先日、3月24日頃に新しいバージョンが公開されました。このモデルは、ベンチマークのスコア上でGPT-4.5と同等の性能を示しており、しかもMITライセンスで提供されていて商用利用も可能です。これはかなり大きな意味を持っていると思います。
これまで、クローズドモデルとオープンモデルの間には明確な性能差があるというのが一般的な見方でしたが、DeepSeekのようなモデルの登場によって、そのギャップが急速に縮まりつつあります。オープンなモデルでありながら極めて高性能、かつ商用利用も可能という点で、今後の勢力図にも大きな影響を与える存在になっていくのではないかと感じています。
久保:DeepSeekはクジラのマークが象徴的ですが、まさにそのイメージ通り、登場したときの衝撃は「クジラ級」だったと思います。
先ほど触れられたベンチマークでは、最新のモデルはClaude 3.7と同等の性能を持っているのではないかという話も出ています。ただ、現時点ではベンチマークスコアのみで評価されている部分が大きいので、実際の使用感や運用面でどの程度パフォーマンスを発揮するのかというのは、これから実証されていくフェーズに入ってくると思います。
それでもやはり一番の衝撃は、あのモデルがMITライセンスで公開されたという点です。これは大きなインパクトがあったと感じています。正直、もう“暴力的”とも言えるムーブメントだと感じています。
従来のオープンモデル、いわゆるオープンウェイトのモデルであっても、たとえばLlamaのように独自ライセンスが設定されていて、一定の利用制約が設けられていたりしました。アリババのQwenに関しても、Apache 2.0のモデルもありますが、一部には独自ライセンスが存在していて、利用に対する懸念を持つ声もあったかと思います。
その中でDeepSeekのモデルがMITライセンスで公開されたというのは、衝撃でした。MITライセンスで世の中に放たれた以上、このモデルは消えることがなく、今後の様々なオープンモデルのベースになると思います。
この流れを受けて、DeepSeekに続く企業が現れるのか、それともこれは唯一無二のムーブだったのかという点は、今後の議論のひとつになると思います。そして、この1モデルを中心に、オープンモデルの進化がさらに予測できない方向へ進んでいく可能性があると感じていて、非常に注目しています。
石上:これから登場が予定されているモデルについても、非常に注目が集まっている状況ですよね。
たとえば、Metaが準備中とされているLlama 4に関しては、すでにいくつか情報が出てきていて、リリースが近いのではないかという期待も高まっています。
また、先ほど話題に挙がったDeepSeekについても、現在公開されている最新版がDeepSeek V3-0324ですが、それに加えて、さらにリーズニングを強化したR2と呼ばれるモデルが、4月か5月にも登場するのではないかという噂も出ています。
こうした動きを見ると、オープンモデルの領域もまだまだ進化が止まる気配はなく、むしろこれからが本格的な盛り上がりのフェーズに入っていくのではないかと感じています。今後のリリースに向けて、引き続き注目していきたいところですね。
強化学習
イ ドンホ:ありがとうございます。やっぱりDeepSeekの衝撃はそれだけ大きかったですし、今日の話の中でも外せないテーマになっていましたよね。
さて、ここからは次のキーワード「強化学習」に話題を移したいと思います。先ほどのDeepSeekの話にも関連する形で、強化学習の活用が話題になっていましたが、実際のところ、強化学習はどれくらい「良いもの」だと感じていますか?どのようなインパクトや可能性を感じていらっしゃるか、率直なご意見をぜひ聞かせていただければと思います。
石上:少し難しい質問ではあるのですが、強化学習の良さというのは、教師あり学習と比較したときに特に際立つ部分があると感じています。
教師あり学習では、正解データを人手でアノテーションする必要があり、「これが正しい答えです」という情報をかなり詳細に書き下さなければならない場面が多いです。それに対して、強化学習では環境と報酬を設計してあげることで、モデル自身が試行錯誤を通じて学習を進めることができます。
たとえば、DeepSeekで活用されているGRPOという手法では、正解例を人間が丁寧にアノテーションしなくても、ルールベースで「この出力は望ましいか、望ましくないか」をある程度簡易に判別できる設定になっています。そのため、大きなアノテーションコストをかけずに、どんどん学習を進められるというのが、DeepSeek R1のトレーニング時の大きなメリットだったと感じています。
このように、タスクの特性や目的に対して強化学習がうまくフィットすれば、教師あり学習よりもはるかに効率よくモデルを鍛えることができるという点は、大きな利点だと思います。
ただ、このあたりは久保さんが強化学習にも精通されていると思いますので、ぜひ久保さんの視点でもお話を伺いたいですね。
久保:強化学習といえば、まず学習の安定性が低いこと、そして学習効率もあまり良くないというイメージがあると思います (参考 : Deep Reinforcement Learning that Matters)。特にゲームの分野では、何万、何千万というフレーム数を回さないと学習が進まない、というのが通説でした。
一般的なモデル開発のフローでは、まず教師あり学習で土台を作ってから、その上で強化学習によるチューニングを行う、という順序が主流です。しかし、DeepSeekのアプローチはそれを逆転させていて、まず最初に強化学習を行い、その後に教師あり学習を加えるという順番を採っています。この構成はとてもユニークで、「こういう作り方もあるのか」と思わせられる部分がありました。
そして、石上さんからも話があったように、論理推論のように正解が比較的明確な問題においては、報酬関数の設計がシンプルに済む場合もあります。強化学習は本来、報酬設計が非常に難しい領域なのですが、明確な基準をもとに学習できる設定にうまく持ち込むことで、これほどまでにリーズニング性能が高いモデルが実現できる、というのは非常に示唆に富んだ結果だと感じました。
ここでも一つ面白いのが、RLHFというと通常は「Human Feedback」を前提としていますが、今回のように人手を介さずに、ある程度ルールベースで報酬を与えて強化学習が成立しているという点です。これにより、AlphaZeroのように人手を介さない自律的な学習に近づいていると感じました。
データ管理(DCAI)
イ ドンホ:ありがとうございます。続けてのテーマが、まさに今、多くの現場で関心が高まっているテーマが「データセントリック」だと思います。
モデルの性能がある程度頭打ちしてきている中で、これからはデータの質をいかに高めていくかが、より重要になってくると私も感じています。先ほどの久保さんのお話にもありましたが、Preferenceデータをどのように確保していくかという点は、今後さらに注目されるポイントです。人手によるフィードバックが不要になる場面も出てきてはいますが、その一方で、ラベリングやアノテーションの重要性自体はむしろ高まっている印象があります。
たとえば、メカニカルタークのような仕組みを使ったアノテーションや、新たな形のデータラベリング市場の動きも活発化しており、どう効率的に高品質なラベル付きデータを得るかというのは、開発現場にとっての大きな課題のひとつです。
では、石上さんご自身は普段のデータ管理において、どのような点を重視されていて、どういった工夫をされているのでしょうか? 非常に広いテーマかとは思いますが、その中でも特に注目しているポイントがあれば、ぜひこの場にいる皆さんにも共有いただけると嬉しいです。
石上:たとえば、基盤モデルの開発における学習データという観点では、特に重要になるのが「量」「質」「多様性」の3つのポイントです。この3つはどれも欠かせない要素で、それぞれがモデルの性能や汎用性に大きく影響を与えると感じています。
まず「量」についてですが、いわゆるビッグデータ的なスケールでの学習が必要になるため、基盤モデルのトレーニングには、単純に大量のデータが求められます。十分な量が確保できていなければ、学習が不安定になったり、汎化性能に欠ける結果になってしまいます。
次に「質」ですが、最近では特に強調されているのがこの部分です。たとえば、大規模言語モデルの学習においては、一般的なウェブデータだけでなく、教育的に高品質なコンテンツ、整った構造を持つデータなどを中心に学習させることで、より効率的に性能を高めることができるということが言われています。量を増やすだけでなく、どんなデータを選び取るかという視点がこれまで以上に重要になってきています。
そして最後に「多様性」です。特定のドメインに偏ったデータだけで学習すると、実際のユースケースに対応できないモデルになってしまう可能性があります。そのため、実応用でカバーしたい範囲を意識しながら、できる限り幅広いデータを取り入れて、言語やトピック、表現スタイルの多様性を担保することが求められます。
このように、基盤モデルの開発においては「量・質・多様性」のバランスをどう取るかが非常に重要です。ただし、これはあくまで学習フェーズの話であって、実際にサービスとして運用するフェーズでは、また別の観点や工夫が求められる場面も多くなってくると感じています。
久保:私が今、特に注目しているのは「合成データ」、つまり人間の手によらないデータの活用です。これは、今後ますます重要になってくるトピックだと感じています。
その理由として、現在学習に利用されているWebコーパスの実情があります。先日の言語処理学会のワークショップでも、Web上のデータというのは非常にノイズが多く、構造的にも整っていないことが多いと聞きました。考えてみれば、広告などの機械生成コンテンツも多く含まれていて、純粋に「人間が自然に書いたテキスト」というものは案外少なかったりするというのが現状です。
そこで注目されているのが、LLMを使って合成データを生成するアプローチです。たとえば、最近テンセントから興味深い論文が発表されていて (参考 : Scaling Synthetic Data Creation with 1,000,000,000 Personas)、その中ではLLMによって多数のペルソナを生成し、それぞれのキャラクターが異なる論理推論の課題に取り組むというような構成を取っていました。たとえばお医者さん、作業労働者、エンジニア、教師など、さまざまなペルソナをLLMで自動的に作り出し、そのうえで推論ベースのデータを生成していくという方法です。
その研究では、10億ものペルソナを生成しており、その多様な視点に基づいたデータを使うことで、リーズニング性能が向上したという結果が示されていました。こうしたアプローチは、人間だけでは到底実現できないスケールや多様性を可能にするという意味で、とても可能性を感じています。
今後は、「LLMでLLMをトレーニングする」という流れがさらに加速していくかもしれません。多様性のあるデータを高いスケーラビリティで生成できるという点において、合成データの活用は、データセントリックな開発において非常に強力な武器になるのではないかと考えています。
AI倫理 (ガイドライン)
イ ドンホ:ありがとうございます。やはり、どれだけ性能や効率が向上しても、それをどう使うか、どのようなガイドラインのもとで社会に出していくかという視点は、これからAIを扱う上で避けては通れないテーマだと思います。
開発者としてはどうしても性能指標やアーキテクチャの工夫といった技術面に目が行きがちですが、その裏側には著作権やプライバシー、無害性、バイアスの制御といった倫理的な課題が常に存在しています。
そこで石上さん、久保さんにお伺いしたいのですが、今の時点で、「エンジニアとしてこれだけは意識しておいたほうがいい」と感じているポイントがあれば、相談のスタンスでも構いませんので、ぜひ一言アドバイスをいただけないでしょうか。実際に現場で感じていることや、大切にしている視点などがあれば教えてください。
石上:一般的なエンジニアの方々にとっては、生成AIをサービスに組み込むという形で扱うケースが多いと思います。その前提に立つと、やはり実装段階で意識すべきポイントはいくつかあると感じています。
たとえば、プロンプトインジェクションのような問題です。ユーザーから悪意のあるプロンプトが送られてきたとき、それにどう対応するか、どう防ぐかという視点は非常に重要です。生成AIは柔軟性がある反面、意図しない挙動をしやすい側面もあるため、攻撃的な入力への耐性を持たせる設計は、サービス運用上のリスク管理として必須だと思います。
また、コストの問題も見逃せません。生成AIはその柔軟性と引き換えに、トークンベースの従量課金がかかる仕組みであることが多く、無制限に動かすと予想以上のコストが発生するケースもあります。ですので、サービスに載せる際には、処理の制限やモデル選定によって、コストが膨らまない仕組みをあらかじめ設計しておく必要があります。
こうした「生成AIならではの注意点」を、最低限のラインとしてしっかりと押さえておくこと。それが、エンジニアとしてサービス開発に携わるうえでまず大事なスタンスなのではないかと思います。
久保:私自身、AIエージェントに関連するインシデントを過去にいろいろと調べたことがあるのですが、いくつか印象的な事例があります (参考 : 生成 AI プロダクトを育てる技術 〜データ品質向上による継続的な価値創出の実践〜)。
たとえば、Air Canadaの事例では、AIが誤った案内をユーザーに行ったことで訴訟にまで発展しました。また、マクドナルドでは、音声認識を活用したチャットボットが誤って注文を処理してしまい、それがSNSで炎上し、最終的にはサービスの中止に至ったケースもありました。
こうした事例に共通しているのは、最終的に「ソーシャルでの炎上」が引き金になっているという点です。技術的な問題以上に、ユーザー側の反応や社会的な評価が、企業やサービスに与えるインパクトの大きさを改めて感じさせられます。
先ほどの話にもあったプロンプトインジェクションや、悪意のある入力によってAIが不適切な発言をしてしまうようなケースは、まさにAI倫理の観点から見ても重要なリスクです。そうしたトラブルを未然に防げるよう、発言内容やシステム挙動に対して事前にしっかりとフィルタリングやガードレールを設けておくことが、サービス運用上、非常に重要だと思います。
炎上が起きたときに一気にブランドの信頼を失う可能性もあるため、こういった対策は「技術的な工夫」というだけでなく、「経営リスクの管理」という意味でも不可欠になってきていると感じています。
クロージング
イ ドンホ:本当にここまでのディスカッション、ありがとうございました。9つのトピックを幅広くカバーしてきましたが、それぞれが深くて、どれも今のAI開発に欠かせない要素だったと思います。
そのうえで、「全部を一度に理解するのは難しい」というのは本当にその通りだと思いますし、だからこそ、最後に石上さんと久保さん、それぞれの視点から「今日これだけは持ち帰ってほしい」という一番のポイントをひとつだけ、共有いただけたらと思います。
まずは石上さんから、お願いいたします。
石上:そうですね、GPT-4の画像生成機能は本当に面白いので、まずはぜひ皆さん自身で触ってみてください(笑)
久保:私は、今日の発表を通して強く感じたのは、「AIエージェントはこれからの技術において欠かせない存在になっていく」ということ、そして「将来、自分がどのように仕事と向き合っていくかを真剣に考えるタイミングに来ているのではないか」という点です。
倫理の重要性はもちろんありますが、それと同じくらい、「自分はこれからどんな仕事をしていくのか」「エンジニアとしてどんな価値を出していけるのか」を、一人ひとりが考え始めるべき時期だと感じています。
AWSとしては、開発環境を提供する立場として、またコミュニティの一員として、こういったテーマについて皆さんと一緒に議論を深めていける場を、今後もどんどん作っていけたらと考えています。今日のような場を通じて、これからの開発や技術との向き合い方を、少しでも共有・探求できたのであれば嬉しいです。
イ ドンホ:ありがとうございます。本当にまだまだお聞きしたいことは尽きないのですが、お時間となりましたので、ここでパネルディスカッションは終了とさせていただきます。
久保様、石上さん、本日は貴重なお話をありがとうございました。