TwitterAPIをRustやPythonで触ってみた
新卒2年目エンジニアの平岡です。
2年前の今頃は有機合成化学の研究室で、試薬を混ぜてひたすら実験をしていました。
この記事ではTwitter APIを題材に、普段業務で触れる機会の少ないインフラ周りや複数の言語を触るなどして遊んだ話を書きます。
Twitter API
何かの情報を集める際、google検索だけでなくTwitter検索を使うこともあり、タイムリーな情報や口コミ等の情報はTwitter検索が適していると思います。
TwitterではAPIを提供しており、タイムラインの取得・投稿や検索結果の取得ができるようです。
search APIを使ったキーワード検索を題材に、アプリの実装からAWSでの公開まで広く浅く触れてみました。
使用申請
TwitterAPIを利用するための各種トークンを発行してもらうために申請が必要です。
こちらから申請できます(要ログイン)。使用目的などを英作文し、申請から約3時間後には使用可能な状態になりました。
認証
Twitter公式のドキュメントにOAuth 1.0とOAuth 2.0、Basic認証について載っています。OAuth 1.0では個人アカウントでログインしたときと同じ機能が使えるのに対し、OAuth 2.0では公開されている情報までしか扱えないようです。
今回触ってみたsearch APIでは特にどれを用いても問題ないですが、例えば一般に公開されていない鍵アカウントのタイムラインの取得はOAuth 2.0の認証ではできないと思われます。
OAuthとは何ぞや、という方は、以下の記事が参考になります。
- 一番分かりやすい OAuth の説明
大まかな概念はこの記事でつかめます。
- OAuth 2.0 の仕組みと認証方法
OAuth 1.0とOAuth 2.0の違いと仕組みについて書かれています。
やりたいこと
- TwitterAPIをたたいて結果をブラウザで見られるようにしたい
- ローカルからだけでなく外からでも見れるようにしたい
- 普段触っていない言語を触ってみたい
ということを漠然と思いながら、以下のステップで進めていきました。
- コマンドライン上で結果を取得する(Python)
- 取得した結果をブラウザに表示する
- 公開する(AWS)
- Rustでも実装してみる
コマンドライン上で結果を取得する(Python)
まずは、日本語の記事が多くて書きやすいPythonで書くことにしました。
環境
- Ubuntu20.04(WSL2)
- Python3.8.5
実装
参考記事の通りの実装でコマンドライン上での動作を確認できました(自分が書いたコードは後述します)。
今回は無料で使うことのできるStandard searchを触っています。こちらでは7日間のツイートを検索することができます。search APIは複数種類用意されており、30日間のツイートを検索できるものや2006年以降のツイートを検索できるものもあるようです。
Standard searchの使い方や用いることができるパラメータについてはこちらに載っています。
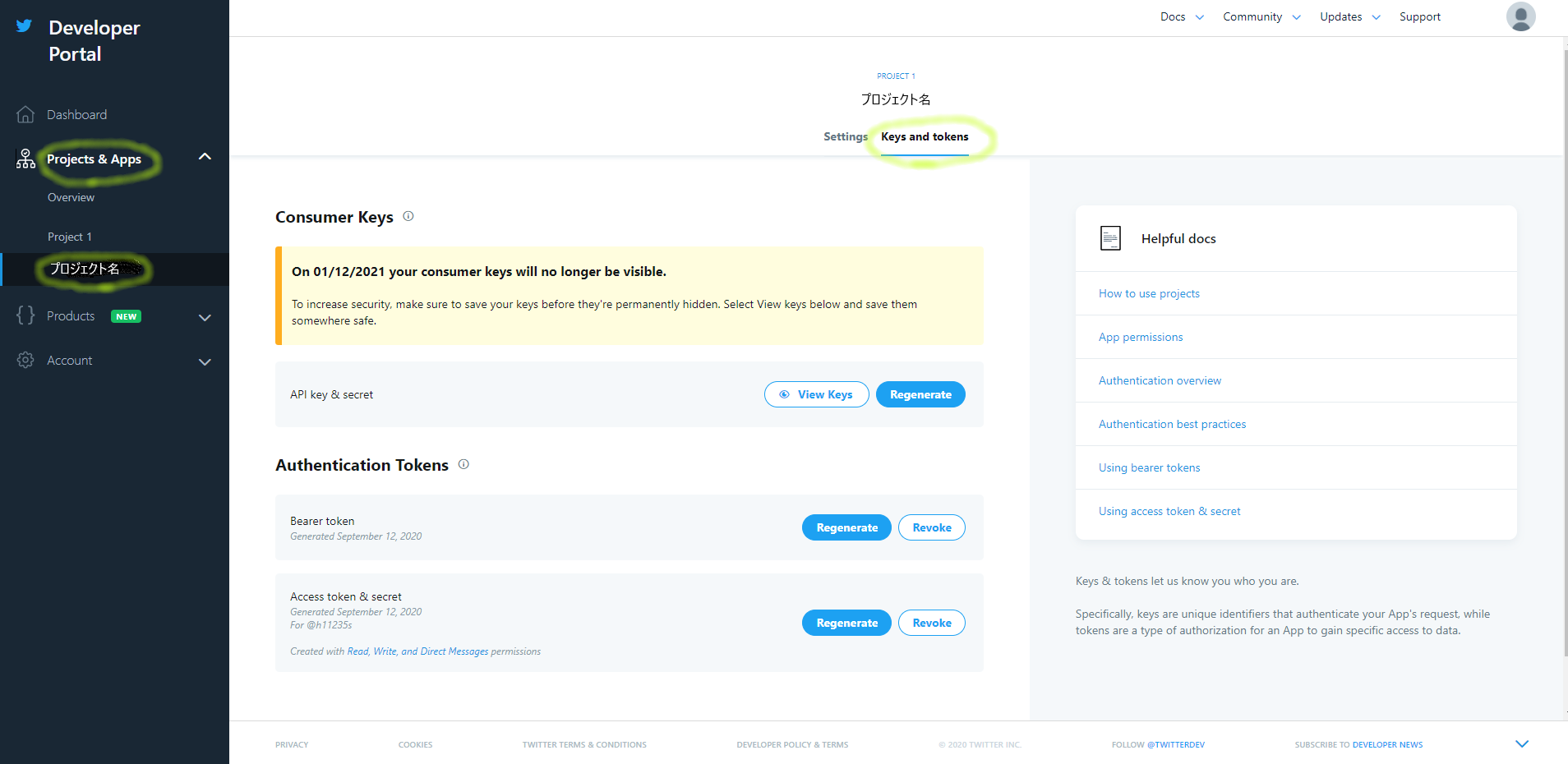
また、各種トークンについては開発者用管理画面から、自分のプロジェクトのKeys and tokensタブにて確認することができます。申請時に発行されたトークンを忘れてしまった場合も、ここで再生成することができます。
取得した結果をブラウザに表示する(CGI)
参考記事:PythonでCGIを用いたWebアプリケーションを作る
CGIサーバーを起動する
import http.server http.server.test(HandlerClass=http.server.CGIHTTPRequestHandler)
このファイルを実行すればCGIサーバーが起動します。
$ python cgiserver.py Serving HTTP on 0.0.0.0 port 8000 (http://0.0.0.0:8000/) ...
同階層にindex.htmlを配置して http://localhost:8000 にアクセスすると、そのhtmlが表示されます。
index.html
formにキーワードを入力し、Twitter APIを叩くPythonファイルを実行させます。
出力先を target="result"で指定してiframe内に検索結果を表示させることで、検索時に画面遷移をさせないようにしました。
<!DOCTYPE html> <html> <head> <title>CGI Sample</title> <meta http-equiv="Content-Type" content="text/html; charset=UTF-8"> </head> <body> <form action="./cgi-bin/search.py" method="POST" target="result"> <input type="text" name="text" value="test" /> <input type="submit" name="submit" /> </form> <iframe name="result" style="top: 200px;height:500px;width:100%;border:0px;margin:100px"></iframe> </body> </html>
search.py
各種キー・トークンはconfigファイルに記載しました。
CONSUMER_KEY = "-----------------" CONSUMER_SECRET = "-----------------" ACCESS_TOKEN = "-----------------" ACCESS_SECRET = "-----------------"
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import config
import urllib from requests_oauthlib
import OAuth1
import requests
import cgi
def main():
# configの値を使う
CK = config.CONSUMER_KEY
CKS = config.CONSUMER_SECRET
AT = config.ACCESS_TOKEN
ATS = config.ACCESS_SECRET
# フォームからキーワードを受け取る
word = cgi.FieldStorage().getvalue('text', '')
count = 10 # 一回あたりの検索数(最大100/デフォルトは15)
range = 10 # 検索回数の上限値(最大180/15分でリセット)
# iframeに埋め込むHTML
html_body = """
<!DOCTYPE html>
<html>
<head>
<title>検索結果</title>
<style>
h1 {
font-size: 3em;
}
</style>
</head>
<body>
<h1>TwitterAPI Result</h1>
<div>%s</div>
</body>
</html>
"""
if not word:
print("キーワードを指定してください")
else:
tweets = search_tweets(CK, CKS, AT, ATS, word, count, range)
print(html_body % (''.join(tweets)))
def search_tweets(CK, CKS, AT, ATS, word, count, range):
# 文字列設定
word += ' exclude:retweets' # RTは除く
word = urllib.parse.quote_plus(word)
# リクエスト
url = "https://api.twitter.com/1.1/search/tweets.json?lang=ja&q=" + \
word+"&count="+str(count)
auth = OAuth1(CK, CKS, AT, ATS)
response = requests.get(url, auth=auth)
data = response.json()['statuses']
# 2回目以降のリクエスト
cnt = 0
tweetsCount = 0
tweets = []
while True:
if len(data) == 0:
break
cnt += 1
if cnt > range:
break
for tweet in data:
tweetsCount += 1
user = tweet["user"]
tweets.append(str(tweetsCount) + "件目
")
tweets.append("name:" + user["name"] + "\n" + "
")
# tweets.append(user["statuses_count"]) # 投稿数
# tweets.append(user["friends_count"]) # フォロー数
# tweets.append(user["followers_count"]) # フォロワー数
tweets.append("投稿日時:" + tweet["created_at"] + "\n" + "
")
tweets.append( "いいね数:" + str(tweet["favorite_count"]) + "\n" + "
")
tweets.append( "リツイート数:" + str(tweet["retweet_count"]) + "\n" + "
")
tweets.append(tweet['text'] + "\n" + "
")
maxid = int(tweet["id"]) - 1
url = "https://api.twitter.com/1.1/search/tweets.json?lang=ja&q=" + \ word+"&count="+str(count)+"&max_id="+str(maxid)
response = requests.get(url, auth=auth)
try:
data = response.json()['statuses']
except KeyError: # リクエスト回数が上限に達した場合のデータのエラー処理
print('上限まで検索しました')
break
return tweets
if __name__ == '__main__':
main()
search.pyには実行権限を付けておきます。
$ chmod 755 search.py
検索する
「http://localhost:8000」 にアクセスし、フォームにテキストを入力して送信するとTwitterでの検索結果が表示されました。 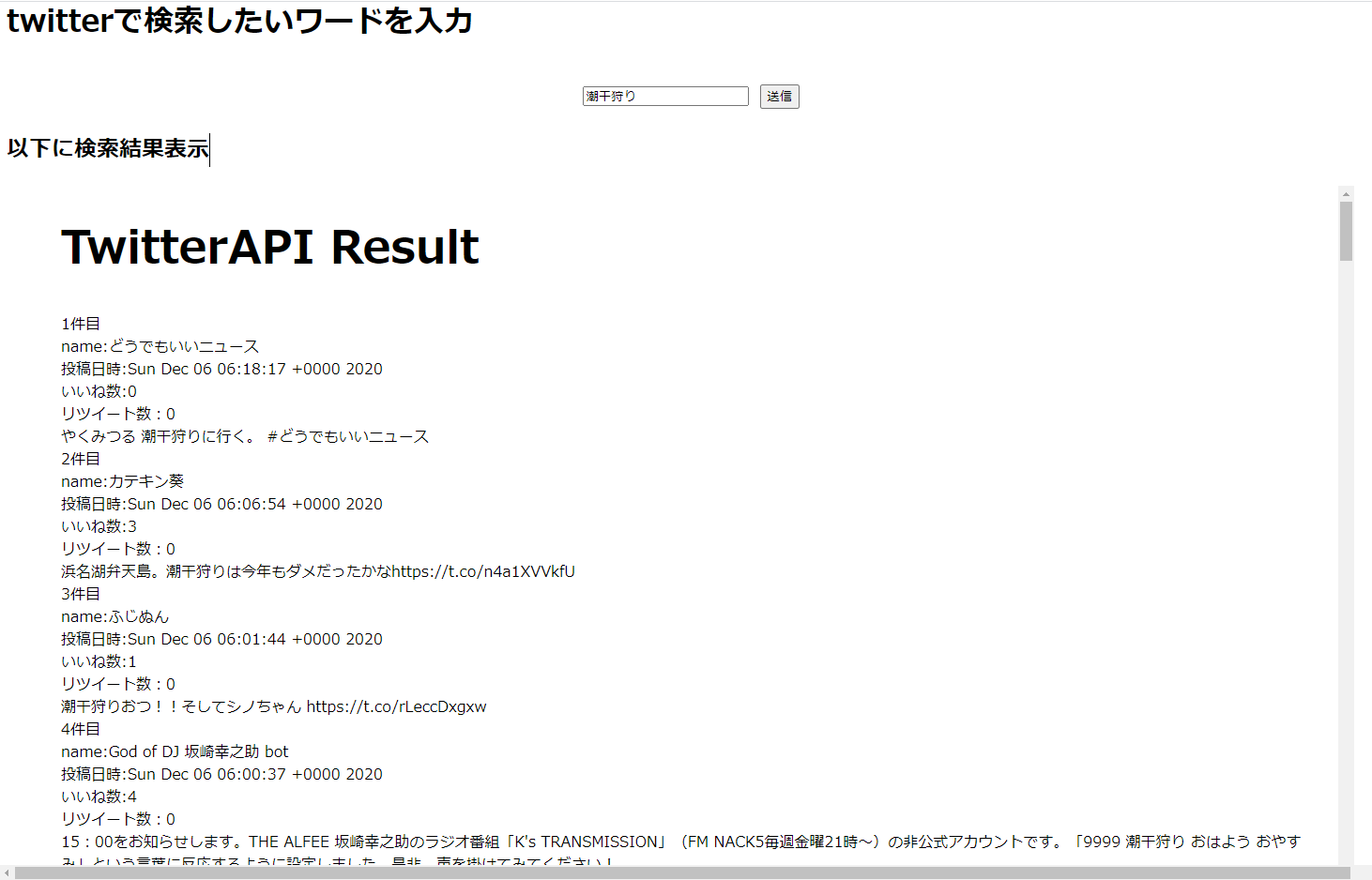
公開する(AWS)
フォルシア入社後の研修でAWSを触る機会があり、EC2を立てるのはとても簡単だったのでAWSのEC2での公開を試みました。
アカウント作成
公式のフローに従ってプロフィールを入力します。お支払方法(クレジットカードなど)の登録が必要なのですが、無料枠で遊ぶこともできます。
EC2を立ててsshする
サインイン後EC2で検索し、ダッシュボードに移ります。
ダッシュボード内やインスタンスタブから「インスタンスを起動」をクリックします。
今回は無料枠で使うことのできるAmazon Linux 2 AMI (HVM)を使います。
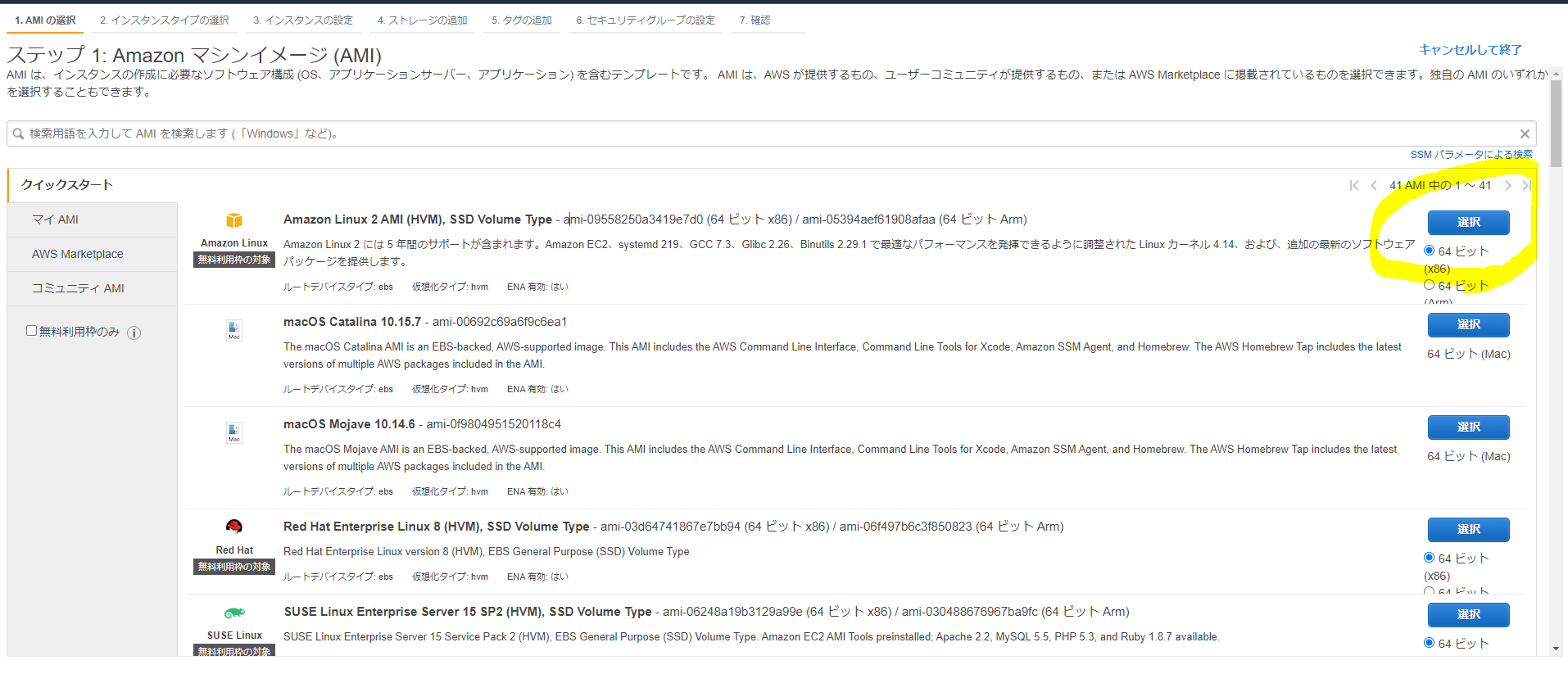
「インスタンスタイプの選択」では、無料枠で使えるものがt2.microのみです。
「セキュリティグループの設定」に移り、必要なポートを設定します。
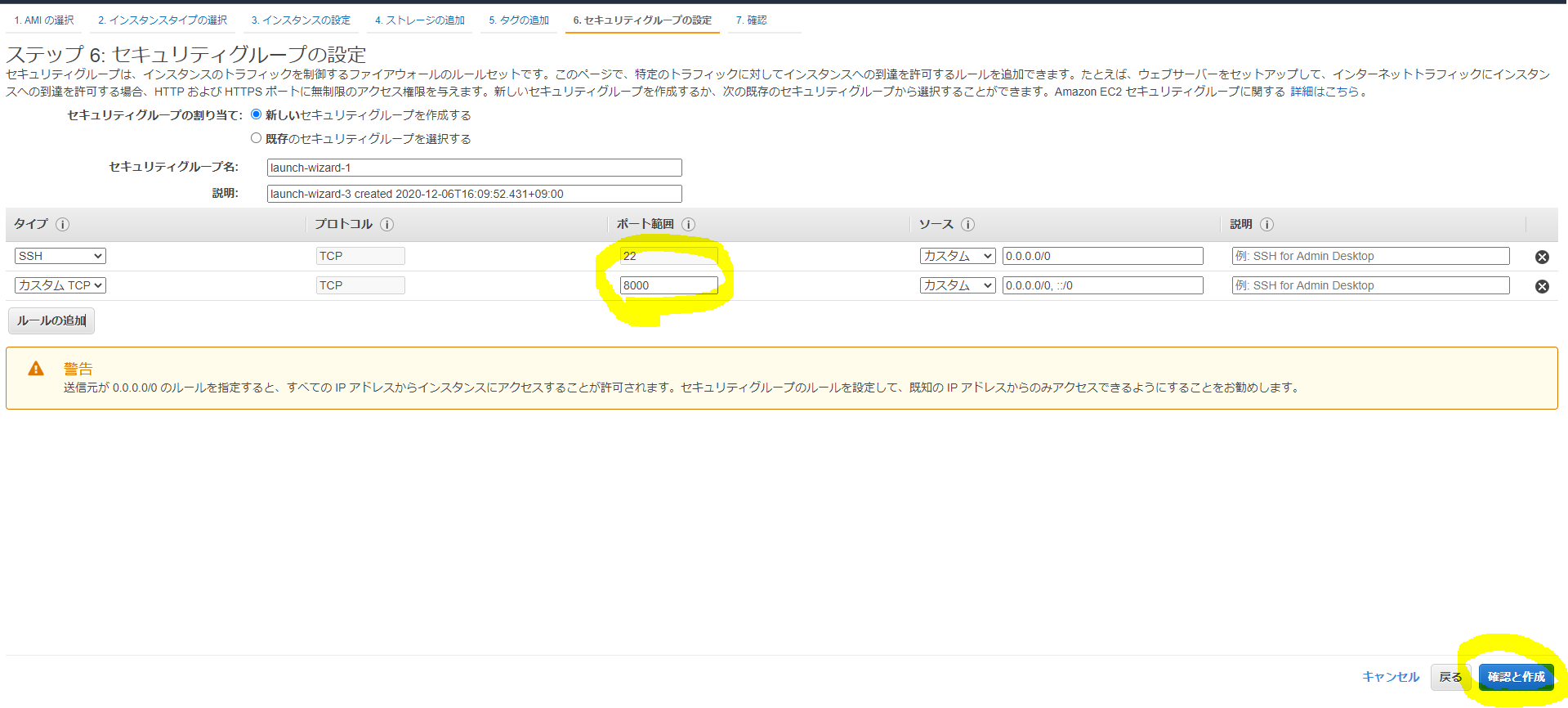
「確認と作成」→「起動」をするとキーペアについて確認されます。 初回はキーを作成してダウンロードします。
.ssh以下など適切な場所に配置し、chmod 600 で権限を変更します。 起動しているインスタンス一覧が見れるページにて、インスタンスの状態が実行中になればssh接続できます。「パブリック IPv4 DNS」(ec2-xx-xx-xx-xx.us-east-2.compute.amazonaws.com)を確認します。
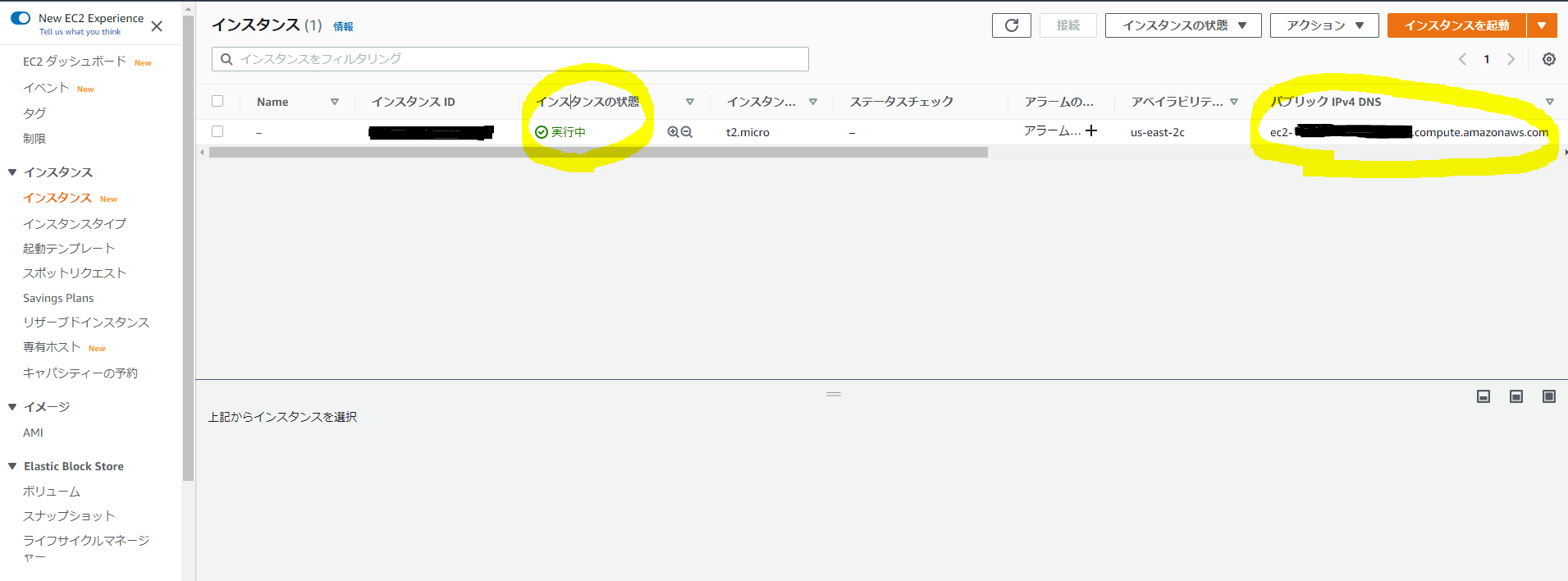
ssh -i ~/.ssh/${key} ec2-user@${パブリック IPv4 DNS}
あとは好きに遊ぶことができます。
Docker
インスタンスを終了すると環境やソースが消えますが、インスタンスを起動する都度環境を作り直すのはとても手間がかかります。
そこで、Dockerfileを作りコマンド1回の実行で環境構築を済ませるモチベーションが生まれました。Python3.8.5とpipを入れて、必要なライブラリをpip installすれば環境は完成です。
FROM python:3.8.5 # ユーザ作成 RUN groupadd web RUN useradd -d /home/python -m python WORKDIR /home/python # pip RUN wget https://bootstrap.pypa.io/get-pip.py | python RUN apt-get update && apt-get install -y urllib3 requests_oauthlib requests # サーバ設置ファイル ADD cgiserver.py /home/python ADD index.html /home/python # cgi-binフォルダを作成 RUN mkdir cgi-bin ADD search.py /home/python/cgi-bin ADD config.py /home/python/cgi-bin RUN chmod 755 /home/python/cgi-bin/search.py # ポート番号を指定して、CGIサーバを起動 EXPOSE 8000 ENTRYPOINT ["/usr/local/bin/python", "/home/python/cgiserver.py"] USER python
AWS上でアプリ起動
必要なファイルが少ないので手動でscpしました。
$ tree . ├── aws_init.sh ├── cgi-bin │ ├── config.py │ └── search.py ├── cgiserver.py ├── docker │ └── python_cgi │ └── Dockerfile ├── index.html
権限に問題のないホームに置きます。
scp -i ${key} index.html cgiserver.py docker/python_cgi/Dockerfile cgi-bin/search.py cgi-bin/config.py aws_init.sh ec2-user@ecxx-xx-xx-xx-xx.us-east-2.compute.amazonaws.com:~
インスタンスにssh後、Dockerを入れてbuild, runすれば環境構築・CGIサーバーの起動が完了です。以下のシェルスクリプトを用意してscpし、実行しました。
sudo yum update sudo yum install -y docker sudo service docker start sudo usermod -a -G docker ec2-user mkdir cgi-bin mv search.py cgi-bin mv config.py cgi-bin sudo docker build -t python_cgi . sudo docker run -d -p 8000:8000 python_cgi
ssh -i ${key} ec2-user@ecxx-xx-xx-xx-xx.us-east-2.compute.amazonaws.com:~
[ec2-user@ip-xx-xx-xx-xx-xx ~]$ chmod +x aws_init.sh
[ec2-user@ip-xx-xx-xx-xx-xx ~]$ ./aws_init.sh
「http://ec2-xx-xx-xx-xx.us-east-2.compute.amazonaws.com:8000」 にアクセスすればローカルと同じCGIアプリを見ることができます。 このURLで外部からも参照することができます。
注意
- データの保存
EC2単体だとインスタンスを終了させると、インスタンス内で行った変更は破棄されます。データの保存にはEBSを併用すると良いです。
- IP
IPを固定しないとインスタンス再起動時にはパブリック IPが変わります(現状ではIPを固定する必要が特に無いためそのままにしています)。
- 課金額
インスタンスを立てたままにするなどして、無料枠を超えた利用が発生すると登録しているクレジットカードから課金が発生します。
最初の12か月間は月750時間までは無料枠で使うことができるらしいです。今回の設定でEC2インスタンスを1台だけ起動する分には立てたままでも課金は発生しない(1台だと最大で月に24×31=744時間)と思われますが、何に課金が発生するかはしっかり確認した上で使いましょう。
Rustでの実装
下準備
rustlingsを一通り解いて、ある程度Rustのソースが読めるようになりました。最初は、
として、Twitter APIを叩いた結果のjsonを返すものを作ろうとしました。
warpで受け取ったパラメータを使ってreqwestでTwitter APIを叩く、というような実装を書いたのですが、warpでjsonを返す処理の中でTwitter APIを叩く処理が上手く書けなかったため、別のcrateを検討しました。RustのWebフレームワークで主要なものに、RocketとActix Webがありますが、Rocketは非同期処理に対応していないためActix Webを使うことにしました。
各crateにはexampleが用意されており、実装の際に参考になりました。
https://github.com/seanmonstar/warp/tree/master/examples
https://github.com/seanmonstar/reqwest/tree/master/examples
https://github.com/actix/actix-web/tree/master/examples
環境
- rustc 1.48.0
- cargo 1.48.0
[package]
authors = ["hiraoka"]
edition = "2018"
name = "twitter"
version = "0.1.0"
[dependencies]
actix-web = "3.3.2"
actix-rt = "1.1.1"
reqwest = { version = "0.10.9", features = ["json"] }
serde = { version = "1.0.117", features = ["derive"] }
serde_json = "1.0.59"
dotenv = "0.15.0"
qstring = "0.7.2"
コード
bearer_tokenを用いるOAuth2.0認証を使いました。.envファイルにbearer_tokenを書きました。
bearer_token = AAAAAAAAAAAAAAAAAAAAA--------
use actix_web::{middleware, web, App, HttpRequest, HttpResponse, HttpServer};
use dotenv::dotenv;
use qstring::QString;
use reqwest::header::{HeaderMap, AUTHORIZATION};
use serde::{Deserialize, Serialize};
use serde_json::Value;
use std::env;
#[derive(Debug, Serialize, Deserialize)]
struct SearchResult {
search_metadata: Value,
statuses: Vec,
}
#[derive(Deserialize, Serialize)]
struct QueryObject {
q: String,
count: u32,
}
struct Twitter {}
impl Twitter {
pub fn new() -> Self {
Twitter {}
}
pub async fn search(
&self,
_req: HttpRequest,
) -> Result<SearchResult, Box> {
let endpoint = "https://api.twitter.com/1.1/search/tweets.json";
let mut headers = HeaderMap::new();
// .envファイルのトークンの値を読み込む
dotenv().ok();
let bearer_token = env::var("bearer_token").expect("bearer_token is not found");
headers.insert(
AUTHORIZATION,
format!("Bearer {}", bearer_token).parse().unwrap(),
);
let query_str = _req.query_string();
let qs = QString::from(query_str);
let q = qs.get("q").unwrap();
let count = qs.get("count").unwrap();
let client = reqwest::Client::new()
.get(endpoint)
.query(&[("q", q), ("count", count)])
.headers(headers);
let res: SearchResult = client.send().await?.json().await?;
Ok(res)
}
}
async fn twitter_search(req: HttpRequest) -> HttpResponse {
let result = Twitter::new().search(req).await;
match result {
Ok(res) => HttpResponse::Ok().json(res),
Err(err) => HttpResponse::InternalServerError().body(err.to_string()),
}
}
#[actix_rt::main]
async fn main() -> std::io::Result<()> {
HttpServer::new(|| {
App::new()
.wrap(middleware::Compress::default())
.service(web::resource("/twitter_search").route(web::get().to(twitter_search)))
})
.bind("0.0.0.0:8000")
.expect("Can not bind to port 8000")
.run()
.await
}
cargo runして 「http://localhost:8000/twitter_search?q=keyword&count=10」 など、検索ワード(q)とカウント(count)をパラメータを指定するとTwitter検索結果のjsonが返ってきます。
おわりに
初めからRustでの実装を試みていたのですが、Rustのエラー処理や型の理解が浅く、コンパイルに苦戦したため、Pythonで動くものを作ってからRustで再実装しました。それぞれの領域でベストプラクティスを試せたわけではありませんが、広く触ってみるのは楽しかったです。
Pythonは調べると日本語の記事が沢山出て来る上、普段触っていないにしても動くものを作るまでのコストはRustと比較して低かったです。
一方で、Rustはこれまで自分が触れたことの無い概念が多くあり、学習コストが高かったです。また、Rustの安定版がasync/await構文をサポートしたのは2019年11月と日が浅く、非同期処理・同期処理のサンプルが混在して見つかり混乱することもありました。困ったらgithubのソースやcrateのドキュメントを見るのが一番ですね。もっとRustのコンパイラーと仲良くなりたいです。
平岡 翔舞
2019年新卒入社。旅行プラットフォーム部エンジニア。
2022年には潮干狩りに行きたいです。



