




こんにちは、SRE部の廣瀬です。
本記事では、ZOZOTOWNでカートに商品を入れる際に使われているデータベース群の内、SQL Server(以降、カートDBと呼ぶ)にフォーカスします。ZOZOTOWNでは数年前から、人気の商品(以降、加熱商品と呼ぶ)が発売された際、カートDBがボトルネックとなる問題を抱えています。様々な負荷軽減の取り組みを通じて状況は劇的に改善されていますが、未だに完璧な課題解決には至っていません。
そこで今回は、加熱商品の発売イベントにおける負荷軽減の取り組みを振り返ります。また、直近の取り組みとして、SQL ServerのCDCを用いた新たな負荷軽減の検証内容をご紹介します。
背景 - カートDBのボトルネックについて
加熱商品の発売イベントに関する対策について、最初に言及した記事としては以下が挙げられます。この記事では人気の福袋商品を加熱商品として紹介していますが、それ以外にも加熱商品は様々な種類のものが存在します。
上記記事を参考に、加熱商品の発売イベントにおけるカートDBのボトルネックについてご説明します。
ZOZOTOWNのカート投入の仕様
ZOZOTOWNでは、「カートに入れる」ボタンを押したタイミングで在庫が確保されます。つまり、カートに入った商品はそのまま注文完了まで進めば、確実に購入できます。ECサイトによっては、「カートに入れる」ボタンを押したタイミングでは在庫が確保されません。代わりに、注文完了後に順次在庫の確保処理を実行して、在庫が確保できない場合はキャンセルのお詫びメールを送信する仕様になっています。ZOZOTOWNのカート投入の仕様は現実世界でのショッピングの体験を再現しており、個人的に好きな仕様の1つです。本仕様により、「カートに入れる」ボタンを押したタイミングで以下のようなクエリ(以降、在庫更新クエリと呼ぶ)がカートDBに対して実行されます。
update 在庫テーブル set 在庫数 = 在庫数 - 1 where PK = ***
SQL Serverの論理リソース競合について
SQL Serverでは、データを更新する際に様々なリソースに対して排他制御をかけます。様々な排他制御の内、本記事で言及する「行ロック」と「ページラッチ」について簡単に説明します。
「行ロック」は、行(レコード)に対して読み書きする際に獲得する必要のある論理的なリソースです。この仕組みによって「1つのレコードを一度に更新できるのは、1つのクエリだけ」といったルールを実現できます。
「ページラッチ」は、複数のレコードを格納している8KBの物理領域に対して読み書きする際に獲得する必要のある論理的なリソースです。基本的には「行ロック」も「ページラッチ」も、同一リソースへの書き込み(以降、writeと呼ぶ)は競合し、同一リソースへの読み取り(以降、readと呼ぶ)は競合しません。
表にまとめると以下の通りです。
| write/write | read/write | read/read | |
|---|---|---|---|
| 行ロック | 競合する | 競合する | 競合しない |
| ページラッチ | 競合する | 競合する | 競合しない |
競合が発生すると、片方のクエリはもう片方のクエリが「行ロック」や「ページラッチ」を解放するまで待たされることになります。つまり、論理リソースの競合が発生するということは該当クエリの実行時間の遅延につながるということです。
なお、SQL Serverのロックについては以下の記事で詳しくまとめていますので、良かったらご覧ください。
加熱商品の発売イベントにおけるDB論理リソース競合
通常時は、様々な商品がカートに投入されている状況のため、複数の在庫更新クエリが同時に同一リソースへ更新要求を出すことはほとんどありません。したがって、「行ロック」も「ページラッチ」も大幅なクエリ遅延につながるような競合は発生しません。
しかし、加熱商品の発売イベントでは、特定の人気商品に対して在庫更新クエリが集中します。このような状況下では大量の「行ロック」および「ページラッチ」競合が発生し、クエリの実行時間の大幅な遅延やクエリタイムアウトエラー多発に繋がってしまいます。ワーストケースでは、クエリの遅延によりワーカースレッドが枯渇して、カートDB全体のスループットが著しく下がるという障害が発生することもあります。
このリソース競合を図示すると以下のようになります。

カートDBのボトルネックまとめ
ここまでの内容をあらためてまとめます。
- ZOZOTOWNでは「カートに入れる」ボタンを押したタイミングで在庫が確保され、内部的には在庫更新クエリが発行されている
- 在庫更新クエリを実行するためには「行ロック」および「ページラッチ」という論理リソースを獲得する必要がある
- 加熱商品の発売イベントでは、特定の商品にカート投入要求が集中し、DB内部で「行ロック」「ページラッチ」関連の論理リソース競合が多発する
- 論理リソース競合多発によってクエリの処理時間が遅延しタイムアウトエラー多発や、ワーカースレッド枯渇によるDB全体のスループット激減という障害につながることもある
このように、CPU負荷やディスク負荷の高騰といった物理リソース起因ではなく、SQL Server内部で獲得する必要のある論理リソース競合がボトルネックである点が特徴的となっています。
次は、カートDBのボトルネックに対するこれまでの対応策を振り返っていきます。
カートDBボトルネック対策の歴史
1.在庫分割による排他制御の分散
こちらの記事で紹介しているように、加熱商品の論理在庫を分割することで、在庫更新クエリによる排他制御を分散させる案です。
この対応のイメージ図は以下の通りです。

この案を2018年に実装して以降、2015年から3年連続で障害が発生していた福袋発売イベントを無障害で乗り切れています。一方で、以下のような課題も抱えていました。
- 運用負荷が大きく、年に1回の福袋発売イベント時だけ発動していた
- 効果は限定的で、分割するメリットが無いほどの少ない在庫数に対しては適用できない
他にもクエリチューニングを実施する等の様々な対策を施してきましたが、限界を迎えていました。具体的には、対策を入れて上昇していくDBの処理能力を、加熱商品の発売イベント時のトラフィックがさらに上回るようになっていきました。
そこでSQL Serverのレイヤだけで対応するのではなく、ワークロードを加味した別DBの選定等、課題の根本的な解決を目指すことになりました。成果の第一弾として、2021年にカート決済機能リプレイスのPhase1がリリースされましたので、そちらをご紹介します。
2.キューイングシステムの導入によるキャパシティコントロール
これまでのカートDBでは、在庫更新クエリ数が増えれば増えるほど、カートDBへのリクエスト数も増える状況になっていました。そこで、カート決済機能リプレイスのPhase1という位置づけで、カートDBの前段にキューイングシステムを設置しました。これにより、在庫更新クエリが増えても、キューイングシステムの後段に位置するカートDBへの更新リクエスト数を一定に保つことが可能となりました。
キューイングシステムの概略図は以下の通りです。

より詳しい情報は下記のテックブログ達にまとまっております。よろしければご覧ください。
この対応を入れたことで、下図のようにレイテンシ、エラー率の両面で劇的な効果を上げることができました。

ここまで、カートDBボトルネック対策の歴史を振り返りました。ワークアラウンドな対応にとどまっていた「在庫分割による排他制御の分散」と比べて、「キューイングシステムの導入によるキャパシティコントロール」は、あらゆる加熱商品に有効な負荷軽減の取り組みとなりました。しかし、ここまでの対策を実施しても論理リソース競合によるクエリタイムアウトの多発という障害の発生を完全に無くすことはできませんでした。
次項では、現状のシステム構成でも障害が発生してしまう要因を説明します。
現在のカートDBが抱えるボトルネック
現在のカートDBのボトルネックに関するワークロードの概略図を以下に示します。
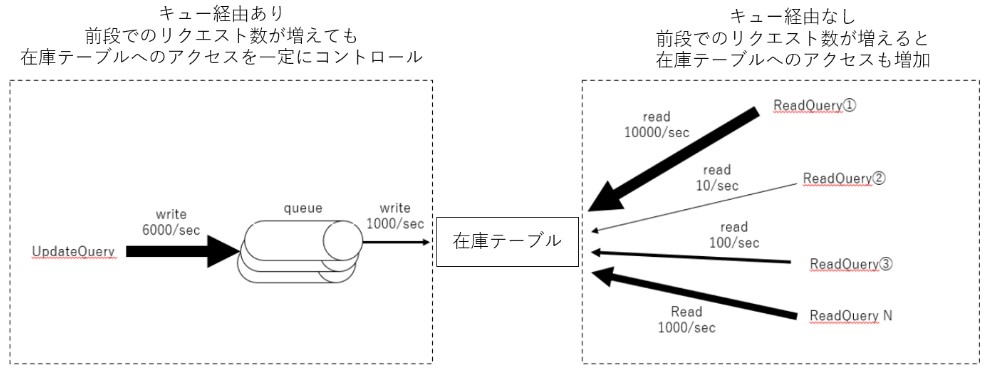
在庫テーブルに対しては、常にwriteとreadの両方のリクエストが発生しています。writeは基本的に在庫更新クエリのみであり、キューイングシステムの導入によってキャパシティをコントロール可能な状態になっています。一方で、readは様々なリクエストで発生し、各リクエスト毎に同時実行数も異なります。例えば秒間10000リクエストのreadクエリもあれば、秒間10リクエストのreadクエリもあります。また、大半のreadはキューを経由しないため、アクセス増加に伴って秒間リクエスト数も増加していきます。
readとwriteはページラッチの競合が発生するため、writeのリクエスト数を一定に保ったとしてもreadの数が増えるほどページラッチ競合の発生リスクは増加していきます。したがって、readの増加によるreadとwriteのページラッチ競合が現在のカートDBのボトルネックということになります。なお、上述の内容は以下の記事に記載されている方法で調査を行い特定しました。よろしければご覧ください。
次項では、現状のボトルネックを踏まえた負荷軽減の取り組みについてご紹介します。
直近でのカートDB負荷軽減の取り組み
現状のボトルネックを踏まえて、システムを以下の構成に変更することで論理リソース競合を軽減できるのではと考えました。
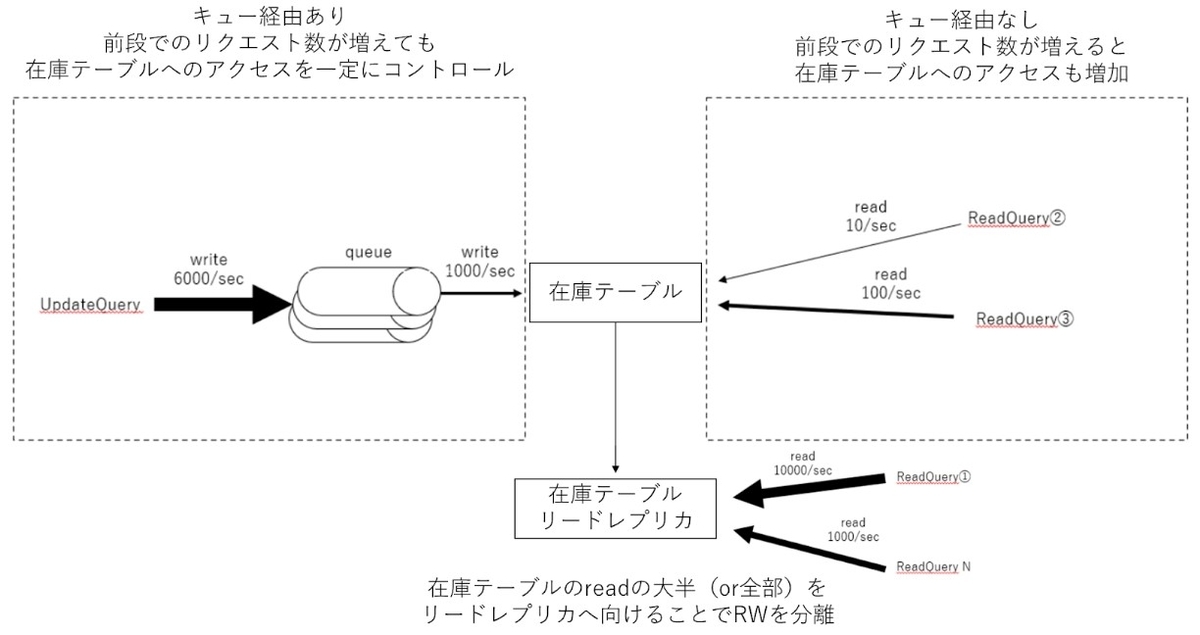
コンセプトとしてはシンプルで、タイムラグが許容されるreadはリードレプリカにアクセスを向けることで、readとwriteの競合発生の軽減を期待するというものです。リードレプリカへのデータ同期方法として、トランザクションレプリケーションとCDCという2パターンを検討しました。
トランザクションレプリケーションとは、SQL Serverが提供するレプリケーションの仕組みです。
CDC(Change Data Capture)とは、SQL Serverが提供する、テーブルに対するレコードの更新を記録できる機能のことです。
両者のおおまかな比較を以下の表にまとめます。
| CDC | 同一サーバー内でのレプリケーション | |
|---|---|---|
| サーバーの追加管理 | 〇(不要) | 〇(不要) |
| リードレプリカの レコード更新 |
◎(1セッションからの直列な更新&リクエスト回数が圧縮可能) | 〇(1セッションからの直列な更新) |
| 運用 | △(カラム追加時などに運用が発生) | 〇(不要) |
| 実装 | △(データ同期処理など自作が必要) | 〇(楽) |
| リスク | △(予期せぬトラブルが発生する懸念) | 〇(トラブルの知見が社内に豊富) |
CDCの方がレコードの更新情報をリードレプリカに適用する回数を圧縮できるため、競合の軽減という観点では優れています。しかし、レプリケーションの方が社内で実績もあり、同一リソースへ同時にwriteが複数発生する現状と比較すると競合の軽減も見込めます。したがって、まずはレプリケーションを使ったリードレプリカ案で負荷試験を実施しました。
負荷試験では「在庫が減るスピード」に着目しました。理由は、在庫がはけ切った場合は更新が行われなくなり、readとwriteの競合も解消するためです。「いかに速く在庫が減る状況をつくれるか」を重要視しました。それ以外にも、加熱商品の発売イベントでは論理リソース競合が多発したりワーカースレッドが枯渇したりする実情を踏まえて、以下の4項目を負荷試験のキーメトリクスとしました。
- 在庫が減るスピード
- ロック競合の平均待ち時間
- ページラッチ競合の平均待ち時間
- ワーカースレッド獲得の平均待ち時間
リードレプリカに向けるクエリの決定方法
在庫テーブルには様々な種類のreadクエリが実行されています。種類が膨大なため全てをリードレプリカに向けるのは実装コストが高くなります。また、タイムラグが許容できないreadクエリはリードレプリカに向けることができません。したがって、加熱商品の発売イベントにおいて実行回数が多いreadクエリの中から、タイムラグが許容できる上位数種類のクエリをリードレプリカに向けました。
なお、各クエリの実行回数はこちらの仕組みを用いて取得しました。
負荷試験の実施方法
まずはコンセプトをDBレイヤ単体で検証するために、開発環境でJdbcRunnerというツールを使って試験を実施しました。その後、プロダクション環境ではDBレイヤ単体の試験ではなく、アプリ側の負荷状況の変化もみるために、実際のユーザートラフィックを再現する形で試験を実施しました。
試験の実施には弊社のエンジニアが公開した「Gatling Operator」というOSSツールを使用しました。詳しくは以下のテックブログをご覧ください。
レプリケーションを使ったreadとwriteの分離
レプリケーションを使ってリードレプリカを作成する案の負荷試験の結果を以下に示します。図は在庫が減るスピードを示しています。
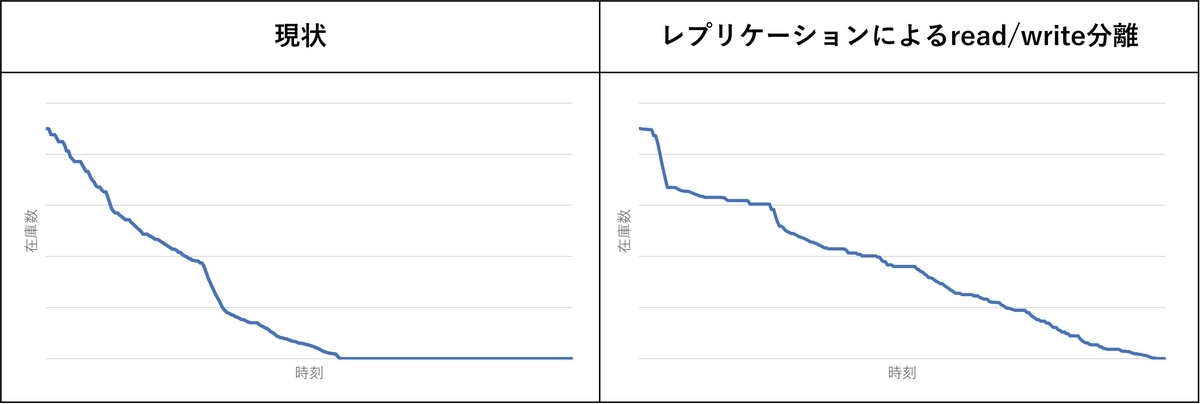
図の通り、レプリケーション案では在庫の減るスピードが逆に鈍化してしまいました。また、数分間レベルの大幅な同期遅延も発生しました。ロック競合、ページラッチ競合、ワーカースレッド獲得の各種平均待ち時間も上昇していました。
レプリケーションでは、マスタ側の同一レコードに100回updateが行われた場合、レプリカ側のレコードに対しても100回updateが行われます。ただし、リードレプリカに更新を適用するのはレプリケーションに関連するエージェント1プロセスのみであるため、更新処理が直列化されます。これだけでも大幅なページラッチ競合の軽減を期待していましたが、そうなりませんでした。
CDC案もあるため原因の深掘りは行いませんでしたが、レプリケーションを使ったリードレプリカ作成によるreadとwriteの分離では、状況は改善できないと結論づけました。
CDCを使ったreadとwriteの分離
まず、CDC(Change Data Capture)という機能を簡単に説明します。この機能はDB単位で有効化した後、テーブル単位で個別に有効化します。有効化した後でテーブルに更新を加えると、サイドテーブルへ変更の履歴が保存されます。サイドテーブルをSELECTすると以下のような結果が得られます。

「_$operation」カラムはどのような更新が行われたかを示します。
- 1:delete
- 2:insert
- 3/4:update
- 3が古い値
- 4が新しい値
「$update_mask」カラムは、どのカラムが更新されたかをマスク値として持っています。例えば画像内の「0x04」は3列目が更新されたことを示しています。
なお、同期の仕組みを実装する際は、サイドテーブルを直接SELECTすることは行わず、cdc.fn_cdc_get_net_changes_capture_instanceを使います。このシステム関数を利用すると、指定した期間の最終的なカラムの値だけを取得できます。例えば、特定の期間に特定の1レコードへ1000回updateが行われたとしても、最新の値だけが適用すべき変更として取得できます。これにより、リードモデルとして作成したテーブルへの更新回数の圧縮が期待でき、リードモデル側のreadとwriteの競合発生を最小限に抑えることが期待できます。
詳しい実装例は本記事の末尾のAppendixで紹介します。
CDCを使ってリードレプリカを作成する案の負荷試験の結果を以下に示します。図は在庫が減るスピードを示しています。
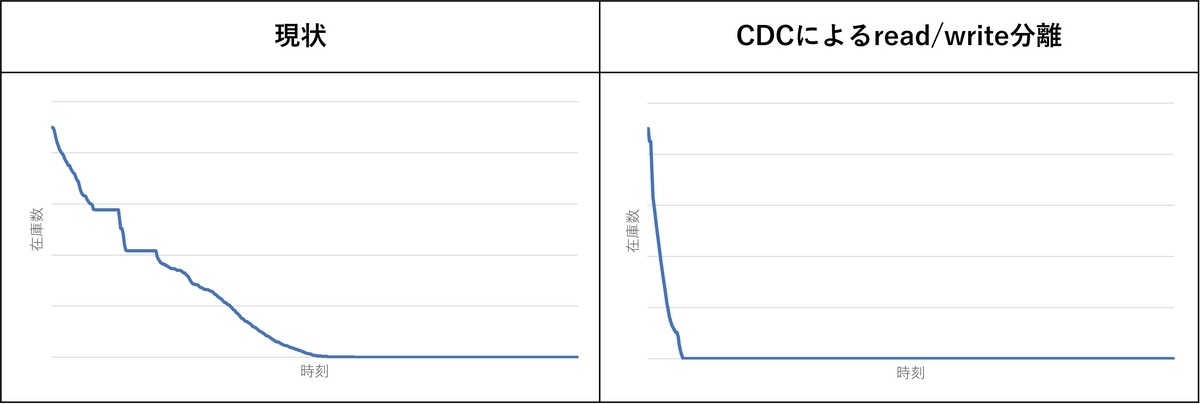
図の通り、在庫が減るスピードは9倍速と劇的に改善されました。また、同期間隔10秒に対して遅延時間は最大でも約15秒と安定していました。キーメトリクスとしていた各種待ち時間も下図の通り劇的に低減しました。

リクエスト数が多いreadクエリをリードレプリカに向けることでreadとwriteの競合発生を低減できました。また、競合による待ち時間が低減したことで、各クエリの処理速度が向上して在庫が減るスピードも大幅に高速化できました。
以上の結果から、CDCを用いたリードレプリカ案は、現在カートDBが抱えているボトルネックに対して非常に有効な手法であると結論づけました。
Limitation
今回の負荷試験では、CDCを使ったreadとwriteの分離でボトルネックの劇的な改善がみられました。
しかし、制限もいくつか存在します。まず第一に、ワークロードの性質の変化に弱い点が挙げられます。秒間リクエスト数が少なかったreadクエリの突発的なスパイクによって、別の箇所へボトルネックが移動する懸念があります。
次に、同期遅延の発生を許容しなければならない点が挙げられます。結果整合性が許容できないクエリの場合は、論理リソース競合の一因になっているとしても、リードレプリカにreadクエリを向けることはできません。
このように、アプリケーションが持つ性質次第では本手法は使えない可能性もあります。ですが、プロダクション環境でのワークロードを模した今回の負荷試験では非常に良い結果を得られました。
まとめ
本記事ではZOZOTOWNが長年抱えている、加熱商品の発売イベントにおけるDBボトルネック起因の障害と、その対策の歴史を振り返りました。また、直近の負荷軽減の取り組みとして、SQL ServerのCDCを用いたリードレプリカの作成によるreadとwriteの分離案を紹介しました。
この方法によって、ボトルネックとなっていた論理リソース競合を劇的に改善させ、在庫が減るスピードも既存の9倍速となる結果を負荷試験で達成できました。諸事情によりプロダクション環境への導入は見送ることになりましたが、提案手法のコンセプトが有効であることを実証できました。
今後の展望
カートDBは未だにボトルネックを抱えている状態です。今後の対応としては以下のような案が考えられます。
- 課題解決に適したDBを選定してワークロードをオフロードする
- カートDBへの更新リクエストだけではなく、参照処理なども含めキューイングさせる
- 加熱商品の発売時は抽選制にするなどアプリ側の仕様を変えることでワークロードの性質も変える
最後に
ZOZOでは、一緒にサービスを作り上げてくれる方を募集中です。ご興味のある方は、以下のリンクからぜひご応募ください!
Appendix - CDCを用いた同期の仕組みの実装
1.DB単位でのCDCの有効化
以下のクエリを実行します。デッドロック等で失敗する可能性があり、その際即時ロールバックが確実に行われるよう、オプションも付けておくと安心です。
set xact_abort on set lock_timeout 500 EXEC sys.sp_cdc_enable_db GO
2.テーブル単位でのCDCの有効化
テーブル単位の有効化は、ロックを獲得できれば基本的に瞬時に完了します。しかし1つめのテーブルに対してCDCを有効化するタイミングでは、関連jobの作成等が行われるため、完了まで数秒かかります。また、その間は該当テーブルへのクエリはブロックされます。したがって、CDCを初めてテーブルに設定する場合は、全くアクセスの無いダミーテーブルに対して設定する方が安全です。ダミーテーブルは例えば以下のようなスキーマで作ります。
CREATE TABLE [dbo].[dummy_table]( [c1] [int] IDENTITY(1,1) NOT FOR REPLICATION NOT NULL, [c2] [int] NOT NULL, CONSTRAINT [PK_dummy_table] PRIMARY KEY CLUSTERED ([c1] ASC)) ON [PRIMARY] GO
次に、ダミーテーブルに対してCDCを有効化します。数秒かかりますが、アクセスが無いためブロッキングは起きないはずです。
EXEC sys.sp_cdc_enable_table @source_schema = N'dbo', @source_name = N'dummy_table', @role_name = null, @filegroup_name = N'primary', @supports_net_changes = 1 GO
そのあと、本当にCDCを設定したいテーブルに対してCDCを有効化します。こちらはアクセスが有るテーブルのため、ブロッキング多発に備えてオプションを設定しておきます。
set xact_abort on set lock_timeout 500 EXEC sys.sp_cdc_enable_table @source_schema = N'dbo', @source_name = N'target_table', @role_name = null, @filegroup_name = N'primary', @supports_net_changes = 1 GO
3.CDCの設定変更
CDC設定による変更履歴データは、期限が切れると自動でクリーンアップされます。期限はデフォルトで4320分(3日後)になっていますが、今回は長すぎると判断し1440分(1日後)に変更しました。
また、クリーンアップ処理時の変更履歴データの1回あたりの削除レコード数をデフォルトの5000から3000に変更しました。理由は、クリーンアップ処理中のCDCサイドテーブルへのロックエスカレーション発生を防止するためです。ロックエスカレーションが発生すると、CDCサイドテーブルへのinsertがブロックされ、リードレプリカ側へのデータ同期遅延の懸念があります。
この設定は以下のクエリで実施しました。
set xact_abort on set lock_timeout 500 go sys.sp_cdc_change_job @job_type = 'cleanup', @retention = 1440, @threshold = 3000
4.CDCを用いた同期の仕組みづくり
CDCを用いてリードレプリカに継続的に変更データを同期するためには、仕組みを自作する必要があります。そのためのテーブルを作成します。
--ウォーターマークの管理テーブル CREATE TABLE [dbo].[CDCWaterMarks] ( [ID] [bigint] IDENTITY(1, 1) NOT NULL, [WaterMark] [binary](10) NULL, [ModifiedAt] [datetime2] NOT NULL, CONSTRAINT [PK_CDCWaterMarks] PRIMARY KEY CLUSTERED ( [ID] ASC ) ON [PRIMARY] ) ON [PRIMARY] --1行だけinsertして、あとは都度updateしていく INSERT INTO CDCWaterMarks VALUES (NULL, sysdatetime()) --同期ログを保存するテーブル CREATE TABLE [dbo].[CDCSyncLogs] ( [ID] [bigint] IDENTITY(1, 1) NOT NULL, [LogMessage] [varchar](4000) NOT NULL, [CreatedAt] [datetime2] NOT NULL CONSTRAINT [DF_CDCSyncLogs_CreatedAt] DEFAULT(sysdatetime()), CONSTRAINT [PK_CDCSyncLogs] PRIMARY KEY CLUSTERED ( [CreatedAt] ASC ) ON [PRIMARY] ) ON [PRIMARY] --同期の遅延時間を計測するためのテーブル CREATE TABLE [dbo].[CDCSyncLatencies] ( [ID] [bigint] IDENTITY(1, 1) NOT NULL, [SyncLatency] INT NOT NULL, [CreatedAt] [datetime2] NOT NULL CONSTRAINT [DF_CDCSyncLatencies_CreatedAt] DEFAULT(sysdatetime()), CONSTRAINT [PK_CDCSyncLatencies] PRIMARY KEY CLUSTERED ( [CreatedAt] ASC ) ON [PRIMARY] ) ON [PRIMARY]
次に、リードレプリカとなるテーブルを元テーブルと同じスキーマで作成します。
create table [dbo].[target_table_read_replica] ( [id] [bigint] ... [column1] [int] ... ... )
続いて、リードレプリカに全件INSERTします。
insert into target_table_read_replica select * from target_table order by id
その後、必要に応じて元テーブルと同じインデックスをリードレプリカにも作成します。次に、リードレプリカへの同期ジョブを作成します。以下のようなクエリをエージェントジョブのステップに登録して実行します。
以下のクエリを使うと10秒ごとにリードレプリカに対して変更履歴を同期します。
set transaction isolation level read uncommitted set lock_timeout 1000 set nocount on declare @watermark varbinary(10) declare @first_lsn varbinary(10) declare @end_lsn varbinary(10) declare @end_time datetime declare @message varchar(4000) declare @merge_count int declare @delete_count int while (0=0) begin begin try select @watermark = WaterMark from CDCWaterMarks with(nolock) --@first_lsnをセット if @watermark is not null begin --管理テーブルに入っているlsnをインクリメント set @first_lsn = sys.fn_cdc_increment_lsn(@watermark) end else begin --初回は最小のlsnを指定 set @first_lsn = sys.fn_cdc_get_min_lsn('dbo_target_table') end --@end_lsnをセット set @end_time = getdate() set @end_lsn = sys.fn_cdc_map_time_to_lsn('largest less than or equal', @end_time) set xact_abort on begin tran --リードレプリカへ更新を反映(ins/upd) merge target_table_read_replica as replica_table using (select * from cdc.fn_cdc_get_net_changes_dbo_target_table(@first_lsn, @end_lsn, 'all') where __$operation in (2,4)) AS master_table --2:ins / 4:upd on replica_table.id = master_table.id when matched then update set replica_table.column1 = master_table.column1 ,replica_table... when not matched by target then insert (id,column1,...) values (master_table.id,master_table.column1,...) ; set @merge_count = @@rowcount --リードレプリカへ更新を反映(del) delete from target_table_read_replica from cdc.fn_cdc_get_net_changes_dbo_target_table(@first_lsn, @end_lsn, 'all') as master_table where master_table.id = target_table_read_replica.id and master_table.__$operation = 1 set @delete_count = @@rowcount --watermarkの更新 update CDCWaterMarks set WaterMark = @end_lsn set @message = 'success : first_lsn: ' + CONVERT(varchar(100), @first_lsn,1) + ' / last_lsn: ' + CONVERT(varchar(100), @end_lsn,1) + ' / merge_count: ' + cast(@merge_count AS varchar(100)) + ' / delete_count: ' + cast(@delete_count AS varchar(100)) insert into CDCSyncLogs (LogMessage) values (@message) commit tran --10秒ごとに同期させるためwait waitfor delay '00:00:10' end try begin catch if @@trancount <> 0 begin rollback end set @message = 'error : ' + cast(error_number() as varchar(100))+ ' : ' + error_message() + ' : first_lsn: ' + CONVERT(varchar(100), @first_lsn,1) + ' / last_lsn: ' + CONVERT(varchar(100), @end_lsn,1) insert into CDCSyncLogs (LogMessage) values (@message) --10秒ごとに同期させるためwait waitfor delay '00:00:10' end catch end
遅延時間を計測するために、以下のクエリ使ったエージェントジョブを別途作成して実行します。1秒ごとに同期の遅延時間を専用テーブルに格納していきます。
set transaction isolation level read uncommitted set lock_timeout 1000 set nocount on while (1=1) begin insert into CDCSyncLatencies (SyncLatency) select datediff(second, sys.fn_cdc_map_lsn_to_time(WaterMark), getdate()) as cdc_sync_delay_sec from CDCWaterMarks with(nolock) waitfor delay '00:00:01' end
5.CDCの無効化
無効化したい場合は、上記手順を逆にたどればOKです。まず同期用のエージェントジョブを停止します。次に、テーブル単位でCDCを無効化します。
set xact_abort on set lock_timeout 500 EXEC sys.sp_cdc_disable_table @source_schema = N'dbo', @source_name = N'target_table', @capture_instance = N'dbo_target_table' GO EXEC sys.sp_cdc_disable_table @source_schema = N'dbo', @source_name = N'dummy_table', @capture_instance = N'dbo_dummy_table' GO
最後にDB単位でCDCを無効化して完了です。
set xact_abort on set lock_timeout 500 EXEC sys.sp_cdc_disable_db GO