Elasticsearch AWS上でのClusterの設定
こんにちは!メディアシステム開発部の杉本です。
今回は、11月末にトライアルリリースをしたauスマートパスアプリ向け検索連動広告で利用しているElasticsearchのCluster機能の設定について紹介をさせてもらいます。
Cluster機能を利用することで、可用性の確保、レイテンシの低減が期待できます。
Elasticsearchでは標準でmulticastの設定となっており、Cluster機能を使うのはさほど難しいことではありません。
ただし、AWSはmulticastに対応していないため、AWS上のMulti-AZ構成でCluster機能を利用するのには少し工夫が必要です。
その前に注釈
- 10月にリリースされたAmazon ESのお話はないです。
- もう少し早く発表されてたら検証し採用してたかもですが今回は見送りました。
- kibanaも関係ないです。
- 最近はElasticsearchの情報検索してもkibana情報が多くて閉口しちゃう。
まずは、簡単に広告商品の紹介
auのAndroid端末にプリインストールされているスマートパスアプリ向けの検索連動型広告です。ナンノコッチャ ですね。
こうして、こうするとでてくる、これです。
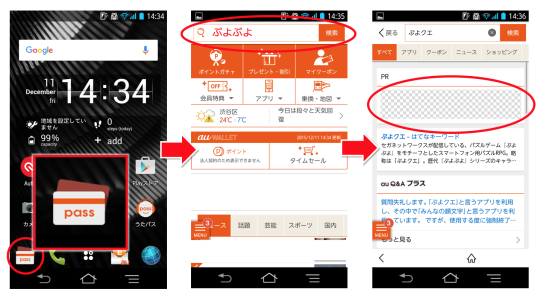
※ 画面イメージは2015年12月時点のキャプチャとなります。
※ 掲出される広告は検索ワードや案件状況によりかわります。
※ iPhoneユーザーはAppleストアからダウンロードしてみて下さい。
広告品質やユーザーと広告との接触状況、キーワードとの広告コンテンツの適合度などなど様々な情報を元に掲出する広告を決めているのですが、このプロダクトでは「キーワードとの広告コンテンツの適合度」の判定にElasticsearchを利用することにしました。
ElasticsearchでのClusterの設定
前置きが長かったですね。それでは本題。
流石に本番環境は披露できないので、似たような環境をブログ用に用意してみました。
環境
- AWS EC2 t2.micro インスタンス * 4台
- Amazon Linux
- Elasticsearch 1.7
- plugin
- elasticsearch-cloud-aws 2.7.1 (今回のキモとなるプラグイン)
- elasticsearch-kopf (確認用 head等でも可)
Clusterの設定手順
- ロールの準備
- インスタンスの準備
- Elasticsearchのインストール
- elasticsearch.ymlの設定
- 確認
ロールの準備
{
"Statement": [
{
"Resource": [
"*"
],
"Action": [
"ec2:DescribeInstances"
],
"Effect": "Allow"
}
],
"Version": "2012-10-17"
}
まずは、AWS上で上記インラインポリシーを持ったロールを作成して下さい。
自分は”EsDescribeInstancesPolicy”という名前のpolicyにしました。
インスタンスの準備
最終的には4台構成としますが、 まずはt2.microインスタンス1台を用意しAMIを取ります。
インスタンス作成時に気をつけなければならないのは、先ほど作成したロールを割り当てるのを忘れないようにする事ぐらいです。それ以外については、ポチポチしながら作成していって下さい。 セキュリティグループを設定するのであれば9200番ポートを開けるのを忘れずに。
Elasticsearchのインストール
インスタンスが用意できたので、SSHでログインし、Elasticsearchをインストールしていきます。
今回はサービス化していくためにrpmでインストールしています。
rpm --import https://packages.elastic.co/GPG-KEY-elasticsearch
vim /etc/yum.repos.d/elasticsearch.repo
リポジトリの登録
[elasticsearch-1.7]
name=Elasticsearch repository for 1.7.x packages
baseurl=http://packages.elastic.co/elasticsearch/1.7/centos
gpgcheck=1
gpgkey=http://packages.elastic.co/GPG-KEY-elasticsearch
enabled=1
インストール
yum install elasticsearch
chkconfig --add elasticsearch
clusterの利用とその確認に辺りプラグインを追加
Kopf(環境確認)
/usr/share/elasticsearch/bin/plugin --install lmenezes/elasticsearch-kopf/master
Elasticsearch-cloud-aws(自動clustering aws対応)
/usr/share/elasticsearch/bin/plugin -install elasticsearch/elasticsearch-cloud-aws/2.7.1
elasticsearch.ymlの設定
設定ファイルはelasticsearch.ymlです。
通常であれば下記にあると思います。
vim /etc/elasticsearch/elasticsearch.yml
clusterを利用するために必要な項目については下記です。
cluster.name: aws-cluster # node同士でクラスタ名は同じにする
discovery:
zen.ping.multicast.enabled: false
type: ec2
cloud:
aws:
region: ap-northeast
node.auto_attributes: true
cluster:
routing:
allocation:
awareness:
attributes: aws_availability_zone
設定については以上です。 下記コマンドでElasticsearchを起動し
service elasticsearch start
http://xxxx.xxxx.xxxx.xxxx:9200/
へアクセスして、起動を確認してみてください。
ロールを設定することで、設定ファイルにsecret_keyを記載する必要もないのでよりセキュアな状態で構築できます。
1インスタンスでの設定を確認できたら、AMIを作成し、作成したAMIを元に4台のインスタンスを起動させて下さい。
確認
正常に設定が完了していれば後は確認するだけです。
http://xxxx.xxxx.xxxx.xxxx:9200/_plugin/kopf/
へアクセスをすると、下記のような画面が確認できるかと思います。
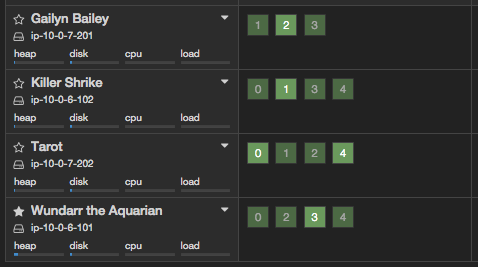
キャプチャから確認いただけるようにサンプルでは5つのshardに3つのreplicaをもたせる形でindexの作成を行いました。
設定については以上となります。
試しに、インスタンスを1台停止させてみてください。
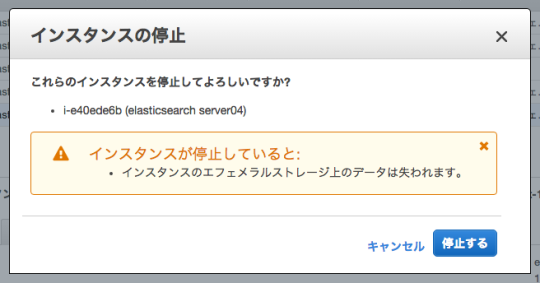
下記のようにすぐにindexが再分配され、Cluster全体として問題なく動作していることが確認できるかと思います。
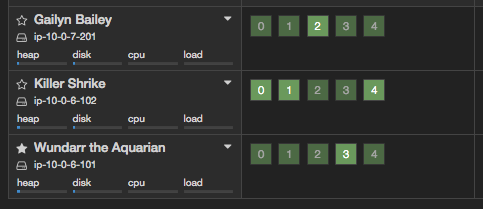
また、インスタンスを再起動させれば自動で対象のインスタンスを見つけ出し、indexが再分配がされたことを確認できるはずです。
このようにElasticsearchでは簡単にClusteringが行えるので、可用性の確保のためにも積極的に利用していきたいですね。
