
こんにちは、子供の寝かしつけ後の歩き方がほぼASIMOになる志水です。
手動で構築したAWSリソースをIaCで利用したいケースは、IaCを導入するタイミングや導入後急ぎの運用で手動追加したタイミングなどで出てきます。
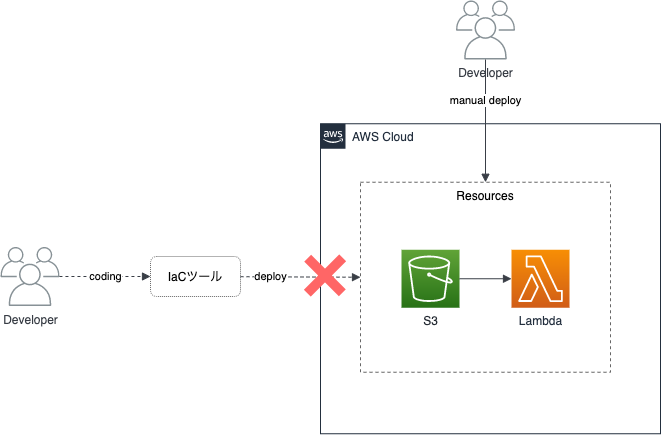
そのとき真っ先に浮かぶIaCツールはTerraformかと思われます。
Terraformだと terraform import でインポートでき、 terraform plan で差分確認をして対象のリソースとコードの差を見つつ取り込みが可能です。また、 terraform show でインポート後のリソースのコードを確認してコードに落とし込めるので、取り込みも容易です。このようにTerraformでの取り込みの開発体験はすごく良く出来ています。
しかし、CDKを使いたいのです。TerraformよりCDKが好きなのです。もうfor_eachやdynamicを使いたくないしHCLを書きたくないのです。実はCloudFormationでも出来るけど、やっぱりCDKが良いのです。どうにか出来ないのかなと思い実際にやってみて、良い点悪い点などが見えてきたので共有します。
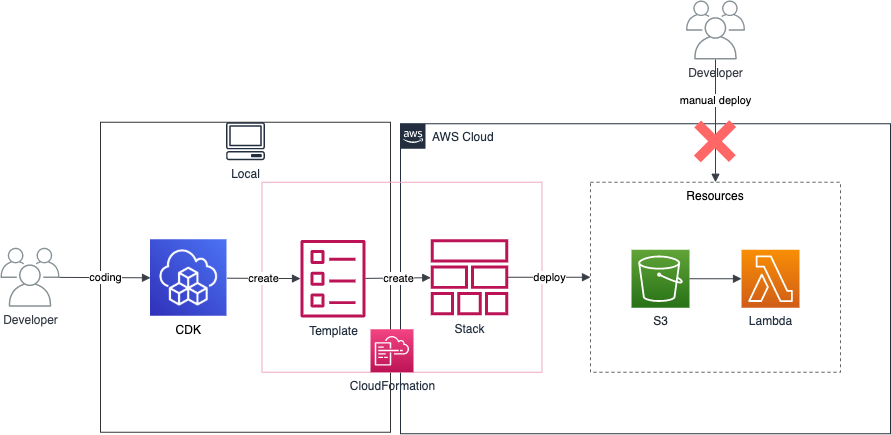
ちなみに、CDK/Terraform/CloudFormationの立ち位置は下記記事で書いておりますので参考にしてください。
Architecture as Codeってなぁに? 〜Infrastructure as Codeを超えて〜
importの目的
CDKの取り込みについて説明する前に、まずその取り込みの目的について整理していきます。まず、CDKコードで管理していないリソースをコードから利用したいとい場合、その目的は下記の2つに分かれます。
- 対象のリソースの情報を利用したい
- 対象のリソースを変更したい
よくコードにリソースを取り込みたいという場合は2番を考えることが多いですが、1番のケースも多く存在します。例えば、他のタスクで作成したS3バケットを利用してLambda関数やIAM Roleを作成したい場合です。この場合、構築対象はLambdaやIAM Roleになり、S3は情報(arnなど)を利用したいだけとなり1番のケースに該当します。この時、S3は変更予定がない場合は1番ですが、S3も変更予定がある場合は2番のケースになります。ちなみに、SAMだと既にあるS3バケットが存在していると、それをフックして起動するLambdaを作る事が出来ないので、その点CDKやTerraformで取り込む方針にすると良いかもです。
このようにケースによって1番か2番で分かれるので、取り込みたいと考えたときに、そのリソースの変更を今後行いたいかどうかが重要になってきます。全て2番で考えても良いのですが、やはり1番の方が簡単に出来るので、目的をまず考えるべきです。
importの方法
目的を整理したところで、その方法になります。目的に対する取り込む方法は下記になります。
- 対象のリソースの情報を利用したい
- arnをべた書き
- from*メソッドの利用
- 対象のリソースを変更したい
- cdk importを利用(今回の目的)
今回の目的は2-1のcdk importになるので、1の2つについては簡単に説明します。
1-1は利用したいリソースのarnやリソース名をコードにベタ書きして別のリソースを構築するときに利用する方法です。1-2は利用したいリソースを from* メソッドを利用して読み込み専用のインスタンスと取得し、そのインスタンスを利用して構築対象に渡す方法です。例えばLambdaに対して特定のS3バケットの読み込み権限のみ付けたい場合は grant* メソッドを利用出来ます。1-1/1-2の使い分けについては、利用するリソースによるのでCDKのドキュメントを参考に使い分けましょう。
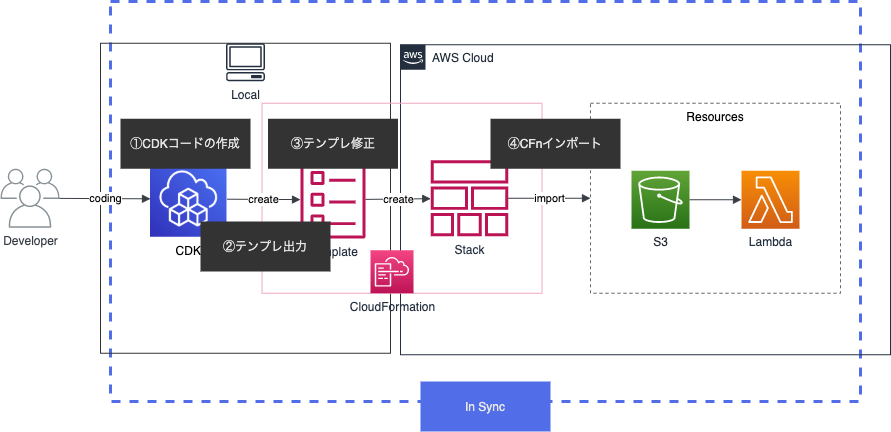
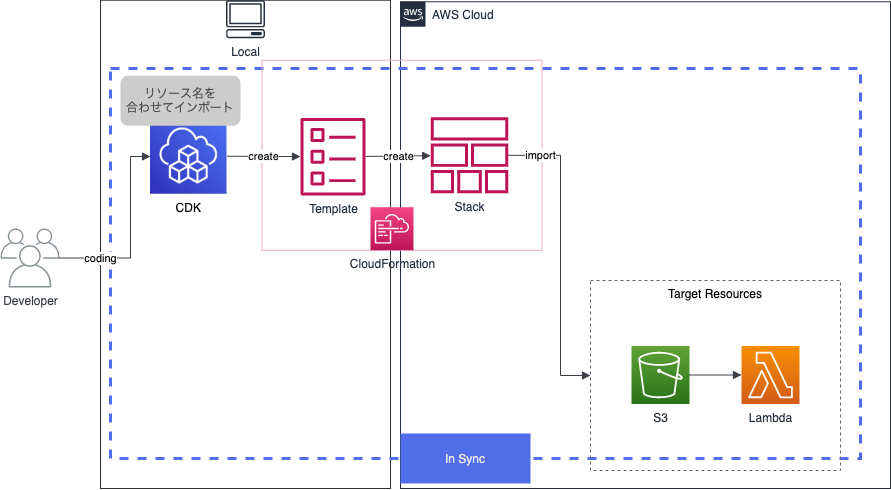
2-1はCDKのコードとして取り込む方法です。まず、CloudFormation(以降CFn)のresource imports機能を利用してリソースを取り込みます。その時に取り込んだスタック名とCDKのスタック名を一致させることによりCDKとしてリソースを取り込む方法になります。
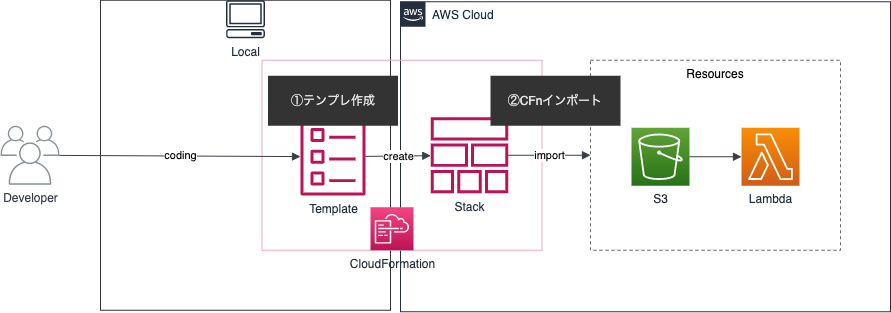
CloudFormation resource imports
CloudFormation resource importsとは、CFn管理外のリソースをCFnテンプレートを作成して、インポートを行いCFn管理にする方法です。流れとしては下記になります。
- CFnのテンプレートを書く
- CFn resource importsする
インポート時は下記2点が必要になります。
- DeletionPolicy属性が付いている(RetainじゃなくDestroyでも可)
- テンプレートとリソースが一致している
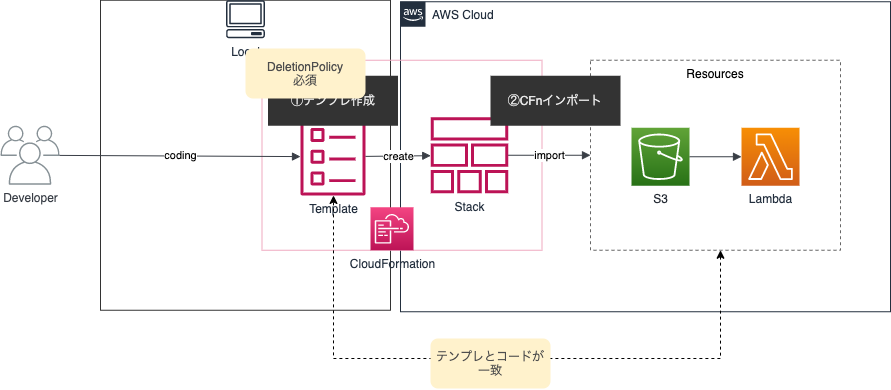
このCloudFormation resource importsを利用してCDKのインポートを行っていきます。
CDKインポートの方法
次にようやくCDKインポートについて説明します。インポートの方法はAWS CDKで既存リソースをCDK管理下に置く方法 - Qiitaの記事を参考にしました。
CDKインポートの流れは下記になります。
- CDKで対象のリソースのコードを書く
- CFnテンプレートの出力
- テンプレートをインポート用に修正
- CFn resource importsする
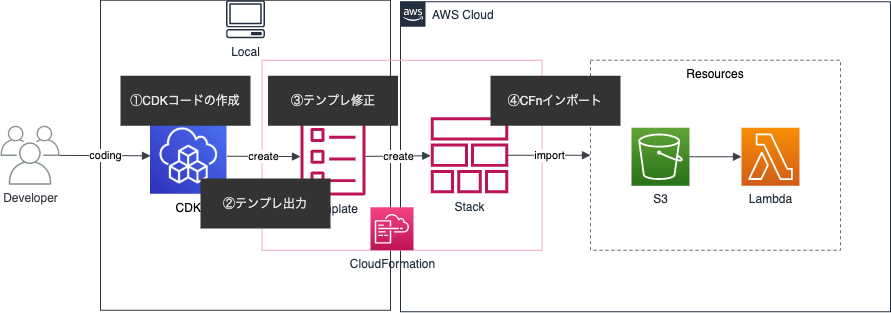
コードを作りインポートするという流れはCFn resource importsと同じですが、CDKインポートの違う部分はCFnテンプレートを作る部分です。CDKコードからCFnテンプレートを生成し、インポート用に修正していきます。インポート時はCFn resource importsの注意点に加えて下記に注意が必要です。
- CDKコードのスタック名とCFnインポート時のスタック名を一致
- テンプレートからCDKのメタデータを削除
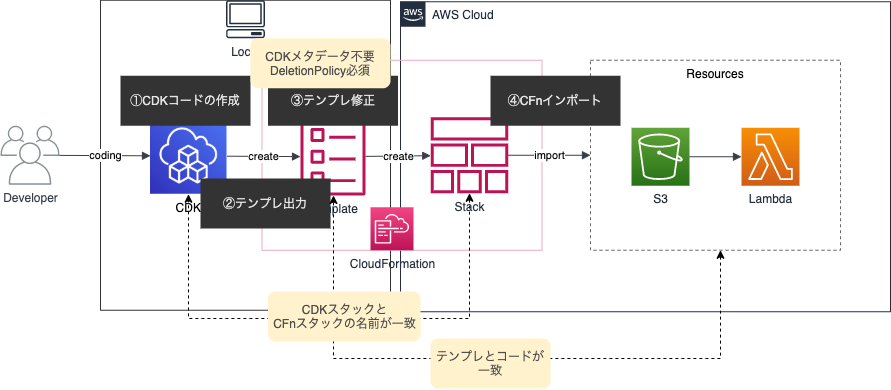
上記を行うことで、CDKコードとリソースが同期され、CDKコードからリソースをデプロイ出来るようになります。
やってみる
インポートを実行する場合、おそらく対象が多かったり別のタスクでも実施したりと複数回実行することが想定されるので、出来る限りコード化をしてやってみました。実行環境はCloud9で言語はPythonを利用しています。
CDKで対象のリソースのコードを書く
まずはS3バケットを作成するCDKコードを作成します。S3バケットは既にDeletionPolicyが設定された状態で出力されるので、今回は明示的に入れてはいませんが、デフォルトで入らないリソースもあるので、その場合は入れておきましょう。
- bucket_name = 'hogehoge-import'
- bucket = s3.Bucket(self, bucket_name, bucket_name=bucket_name)
また、上記のスタックをapp.pyから呼び出す部分は下記のようになっており、ImportCdkStackがCFnスタックの名前になるので、メモしておきます。
- ImportCdkStack(app, "ImportCdkStack")
CFnテンプレートの出力
上記で作成したスタックはまだ実行せず、テンプレートを出力するだけで良いです。$ cdk synth ImportCdkStackでテンプレートを確認しつつ、cdk.outへテンプレートが出力されていることを確認します。
- $ ll cdk.out/ImportCdkStack.template.json
- -rw-rw-r-- 1 ec2-user ec2-user 5946 Mar 23 21:29 cdk.out/ImportCdkStack.template.json
テンプレートの中身を見ると、確かにDeletionPolicyが入っていることが確認出来ます。
- "hogehogeimportAAAAAAAA": {
- "Type": "AWS::S3::Bucket",
- "Properties": {
- "BucketName": "hogehoge-import"
- },
- "UpdateReplacePolicy": "Retain",
- "DeletionPolicy": "Retain",
テンプレートをインポート用に修正
次に先程出力したテンプレートを修正します。修正は下記のPythonコードを利用します。基本的にはCDKMetadataを削除するだけなので、その部分を削除して再配置しているだけになります。
- import json
- import_stack_name = 'ImportCdkStack'
- json_open = open('cdk.out/' + import_stack_name + '.template.json', 'r')
- json_load = json.load(json_open)
- del json_load['Resources']['CDKMetadata']
- import_dir_name = 'cfn-import'
- j_w=open(import_dir_name + "/s3-versioned.json","w")
- json.dump(json_load,j_w,indent=2)
- j_w.close()
CDKで実行されたテンプレートはcdk.outのディレクトリに配置されるため、そのテンプレートを読み込み修正をして、転送用のディレクトリ(今回はcfn-import)に配置しています。以降はこのcfn-importディレクトリにあるテンプレートを利用します。
CFn resource importsする
インポートを実行する前に、修正したテンプレートを実行出来るようにするためS3バケットへ転送します。
で、バケット作ったり転送するのも面倒だったのでCDKで下記のスタックを作成して実行します。下記はテンプレート用のS3バケットを作成し、上記で作成したcfn-importディレクトリ以下を作成したバケットへ転送しています。s3deployが使えるようになってたので使いたかっただけです。
- bucket_name = 'hogehoge-cfn-import'
- bucket = s3.Bucket(self, bucket_name,
- block_public_access=s3.BlockPublicAccess(
- block_public_acls=True,
- block_public_policy=True,
- ignore_public_acls=True,
- restrict_public_buckets=True
- ),
- bucket_name = bucket_name
- )
- key_prefix = "import/"
- s3_deployment = s3deploy.BucketDeployment(self, "DeployWebsite",
- sources=[s3deploy.Source.asset("./cfn-import")],
- destination_bucket=bucket,
- destination_key_prefix=key_prefix
- )
- template_url = 'https://' + bucket.bucket_regional_domain_name + '/' + key_prefix + 's3.json'
- CfnOutput(self, 'template_url',
- value = template_url
- )
これでテンプレートは転送されたので、それを利用してインポートを行います。下記PythonコードはCFn resource importsを行い、エラーが無ければchange setを実行しています。なので、これを実行するとS3バケットに対してcfn resource importsが完了します。
- import boto3
- from pprint import pformat
- import time
- import logging
- logger = logging.getLogger(__name__)
- fmt = "%(asctime)s %(levelname)s %(name)s :%(message)s"
- logging.basicConfig(level=logging.INFO, format=fmt)
- cfn = boto3.client(service_name='cloudformation')
- ## この辺りはメモったものから適宜修正
- stack_name = 'ImportCdkStack'
- change_set_name = 'import-change-set'
- import_bucket_name = 'hogehoge-import'
- template_bucket_name = 'hogehoge-cfn-import'
- key_prefix = "import/"
- response = cfn.create_change_set(
- StackName=stack_name,
- ChangeSetType='IMPORT',
- ChangeSetName=change_set_name,
- ResourcesToImport=[
- {
- 'ResourceType': 'AWS::S3::Bucket',
- 'LogicalResourceId': 'import-bucket',
- 'ResourceIdentifier': {
- 'BucketName': import_bucket_name
- }
- },
- ],
- TemplateURL='https://' + template_bucket_name + '.s3.ap-northeast-1.amazonaws.com/' + key_prefix + 's3.json',
- )
- logger.info('response create_change_set')
- logger.info(pformat(response))
- while True:
- response = cfn.describe_change_set(
- StackName=stack_name,
- ChangeSetName=change_set_name,
- )
- logger.info('response describe_change_set')
- logger.info(pformat(response))
- if response['Status'] == 'CREATE_COMPLETE':
- break
- time.sleep(3)
- response = cfn.execute_change_set(
- StackName=stack_name,
- ChangeSetName=change_set_name,
- )
- logger.info('response execute_change_set')
- logger.info(pformat(response))
- while True:
- response = cfn.describe_stack_events(
- StackName=stack_name
- )
- logger.info('response describe_stack_events')
- logger.info(pformat(response['StackEvents'][0]))
- if response['StackEvents'][0]['ResourceStatus'] == 'IMPORT_COMPLETE':
- break
- time.sleep(3)
- logger.info('finish import')
上記を行うと、CDKとしてもインポートが完了しているので、$ cdk diffを実行すると差分無しの状態になっています。以降このコードにLambdaを追加するなりCDKコーディングをエンジョイしてください。
CDKインポートで同期される背景
何故上記の流れでCDKコードとリソースが同期されるのか説明します。
まず、CFn resource importsの役割はCFnテンプレートとリソースが同期することです。
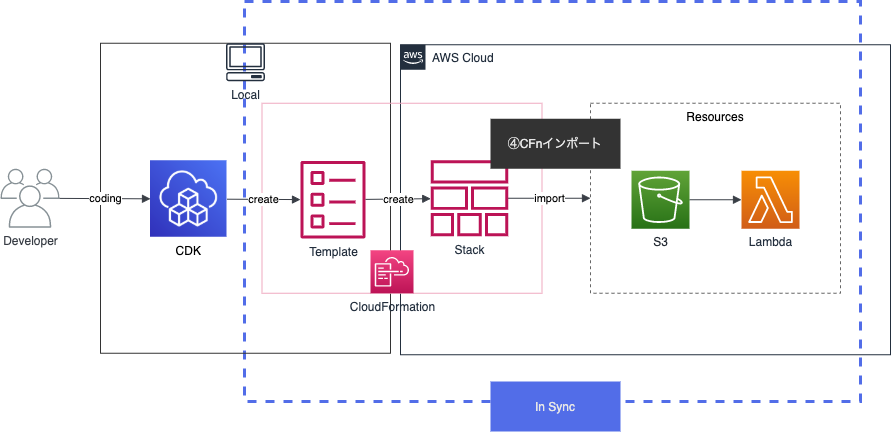
その為CDKコードとリソースが同期するには、CDKコードとCFnスタックを同期させる必要があります。そこで、まずCDKコードから生成されたCFnテンプレートを利用することでコードとテンプレートが同期します。更に、CFn resource importsを行う時のスタック名をCDKスタックと一致させることでCFnスタックとも同期することが出来ます。
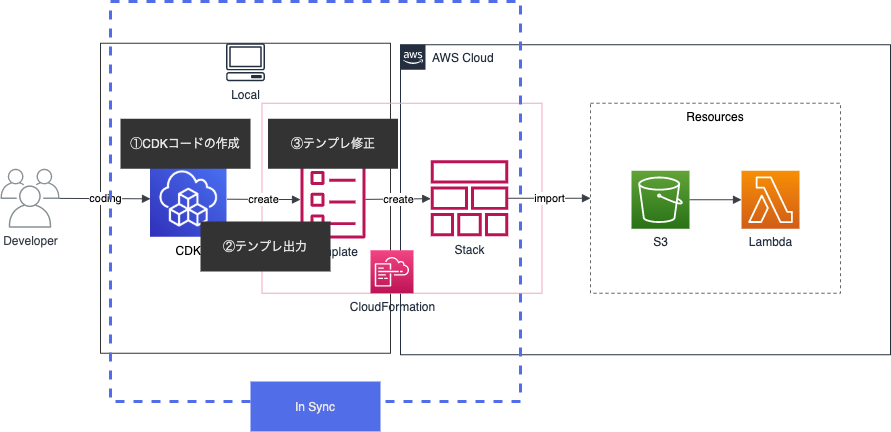
それらを行うことで、CDKコードとCFnスタックが同期され、結果的にCDKコードとリソースが同期されることになります。
CDKインポートの課題
CDKインポートを行うと既存リソースがCDKのコードで管理出来るので、取り込み後は通常のCDK開発の流れと同じになり最高です。
ただし、取り込みの方法で少し癖があります。癖があるのはCDKインポートというより、CFn resource importsになります。CFn resource importsの注意点に「テンプレートとリソースが一致している」がありました。
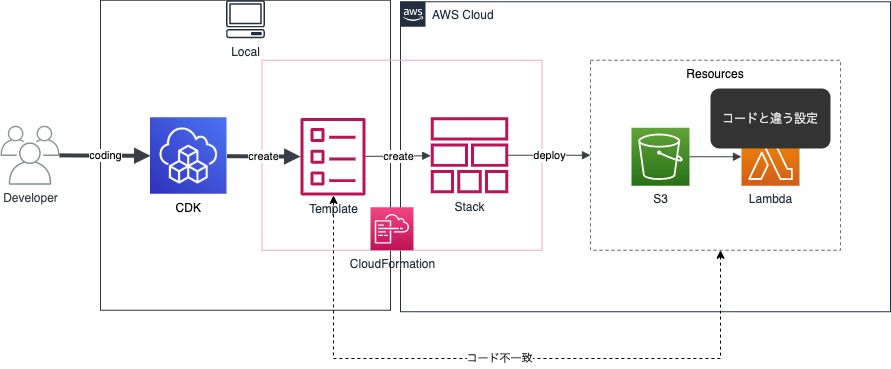
もしこのテンプレートとリソースが一致しない場合、実はインポート時にエラーが出ないのです。もちろんリソースがS3でテンプレートがEC2だとエラーは出ますが、対象が同一リソースになっているとエラーになりません。例えば、対象のリソースのテンプレートを用意して一部の設定だけテンプレートとリソースが違った場合、取り込み自体は完了しCFn管理下になります。しかし、リソース側の変更は起こらず、CFnテンプレート(とCDKコード)とリソースの設定差異がある状態になります。
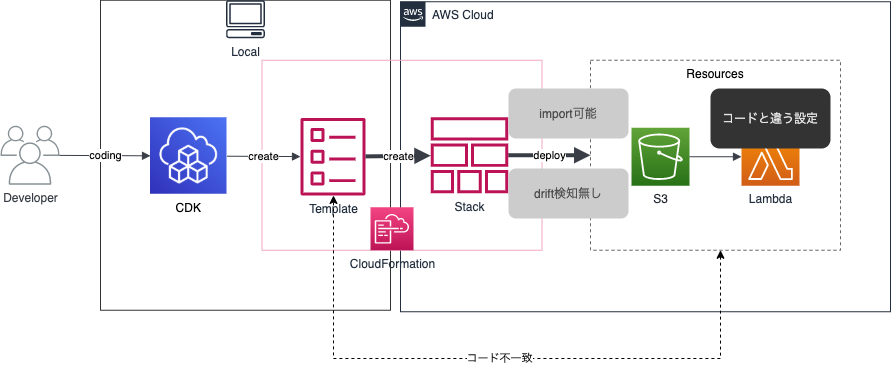
ここでテンプレートとリソースの差分を検知するCloudFormationのドリフト機能を利用するとどうなるでしょうか。実は差分が検知されません。残念。原因は分かってないですが、おそらく既にCFnスタックが差分無しの状態で取り込めているのと、本来の機能と用途が違うためかと思われます。ドリフト検知機能は、テンプレートを作成した後にリソースが変更されたものを検知するという機能に主眼を置いているためです。
更に調査を進めます。このテンプレートとリソースに設定差異がある状態で、更にCDKコードから別の設定を入れるとどうなるでしょうか。
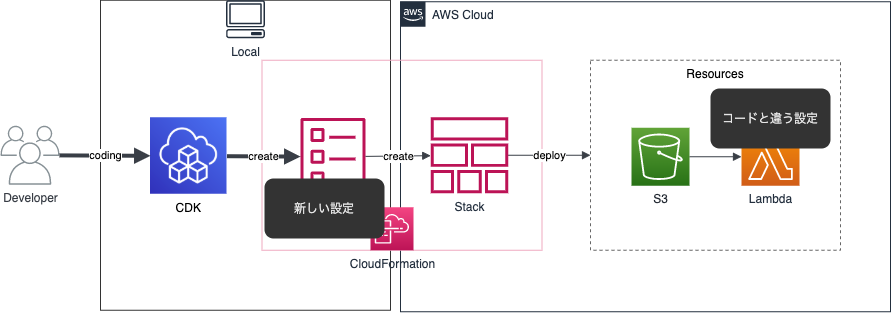
CDKから差分確認してみると、元の設定は差分として出ずに変更を加えた設定のみが出てきます。この原因もおそらくインポート時のものと同じで、既にスタックが元々の差分を無いものとして取り込んでいるためかと思われます。そして、デプロイするとやはり今回の変更部分のみがアップデートされていました。
つまり、取り込み後に別の変更を加えると、元々差異のある設定に変更が起こらず、いわゆる先祖返りは起こらないという結果になりました。言い方を変えると、CDKに取り込んだ後は想定外の変更はされないというメリットにもなります。本番環境にデプロイして想定外の変更をされると泣けますしね。
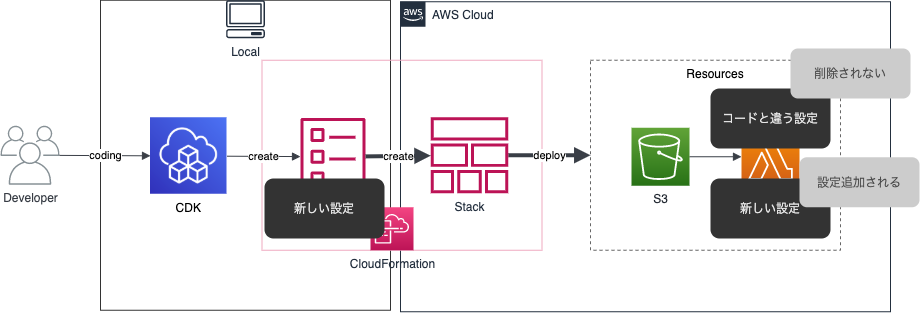
まとめると、CDKインポート(CFn resource imports)の弱点は下記になります。
- CFnテンプレとリソースの差異がある状態で取り込むと、差異がある状態で取り込んでしまう
- 取り込み後に別の変更を加えても先祖返りは起こらないので、常にコードとリソースに差異がある
テンプレートを一致させるために
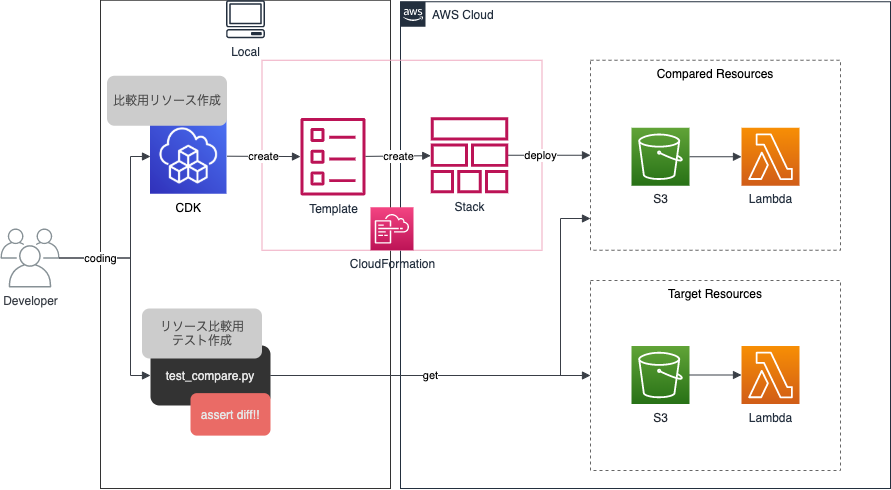
つまり、CDKインポートとの良い付き合い方は、取り込み時にコードをリソースと一致させることになります。一致させるために、取り込み用のリソースとは別の比較用のリソース作成し比較する流れが良いです。
まず、CDKコードから取り込み用とは別に比較用にリソースを作成します。対象のリソースは一旦デフォルトの設定で作成しましょう。そして、取り込み用と比較用のリソースを比較するテストコードを作成し、差分がある場合はテストがコケるようにしましょう。
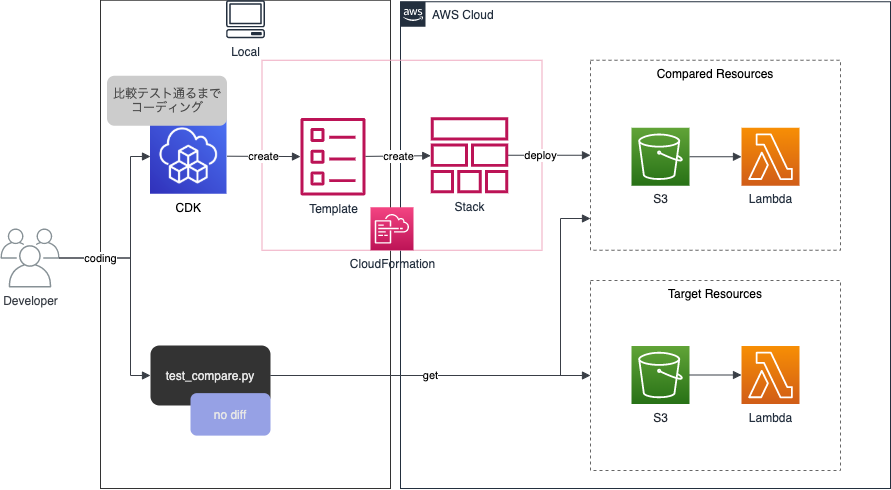
そして、テストコードからエラーが無くなるようにCDKコードを修正していき、リソースの設定を一致させていきます。流れとしてはTDDに近いですね。最終的にテストが通れば完了で、対象のリソースが一致したということになります。もちろん、比較用のテストコードも比較対象のオプションを漏れなく記載する必要があります。
差分が無くなれば比較対象のリソースは不要になるのと、CDKコードはインポートで再利用するため、 cdk destroy で削除します。
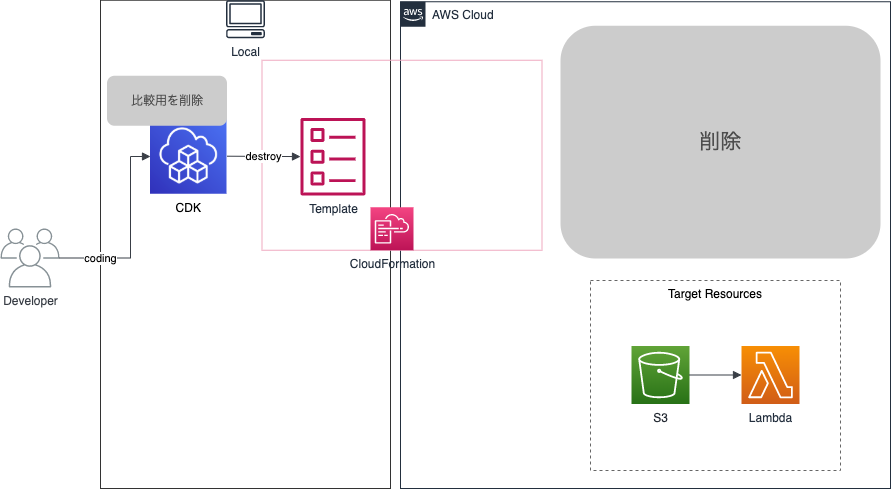
そして、最後に作成したCDKコードから先程説明したCDKインポートの手順を踏んでインポートすることで差分が無い状態のCDKコードが出来上がります。
やってみる
では、リソースの比較についてやってみましょう。
S3バケットの比較をすると仮定して、下記コードを準備します。
- import pytest
- import boto3
- import re
- def get_s3_method_list():
- method_list = []
- client = boto3.client(service_name='s3')
- for method_name in dir(client):
- if re.compile('^get.*?bucket').search(method_name):
- method_list.append(method_name)
- return method_list
- method_list = get_s3_method_list()
- @pytest.mark.parametrize("method_name", method_list)
- def test_compare_s3(method_name):
- compare_bucket_list = ['hogehoge-compare', 'hogehoge-import']
- client = boto3.client(service_name='s3')
- response_list = {}
- for bucket_name in compare_bucket_list:
- try:
- response = eval('client.' + method_name)(
- Bucket=bucket_name
- )
- del response['ResponseMetadata']
- except Exception as e:
- # 関数によっては設定無いとエラーになるので回避
- response = {}
- response_list[bucket_name] = response
- assert(response_list[compare_bucket_list[0]] == response_list[compare_bucket_list[1]])
上記はS3バケットの情報取得する関数を一覧で取得し、それを比較するバケット同士に適用して結果を単純に比較してます。これを実行すると下記のように、様々なS3バケット情報取得のメソッドを実行し比較出来ています。
- $ pytest -v tests/integration/test_import_bucket.py
- ===================================================================== test session starts =====================================================================
- platform linux -- Python 3.7.10, pytest-6.2.5, py-1.11.0, pluggy-1.0.0 -- /home/ec2-user/environment/import-cdk/.venv/bin/python3
- cachedir: .pytest_cache
- rootdir: /home/ec2-user/environment/import-cdk
- collected 22 items
- tests/integration/test_import_bucket.py::test_compare_s3[get_bucket_accelerate_configuration] PASSED [ 4%]
- tests/integration/test_import_bucket.py::test_compare_s3[get_bucket_acl] PASSED [ 9%]
- tests/integration/test_import_bucket.py::test_compare_s3[get_bucket_analytics_configuration] PASSED [ 13%]
- tests/integration/test_import_bucket.py::test_compare_s3[get_bucket_cors] PASSED [ 18%]
- tests/integration/test_import_bucket.py::test_compare_s3[get_bucket_encryption] PASSED [ 22%]
- tests/integration/test_import_bucket.py::test_compare_s3[get_bucket_intelligent_tiering_configuration] PASSED [ 27%]
- tests/integration/test_import_bucket.py::test_compare_s3[get_bucket_inventory_configuration] PASSED [ 31%]
- tests/integration/test_import_bucket.py::test_compare_s3[get_bucket_lifecycle] PASSED [ 36%]
- tests/integration/test_import_bucket.py::test_compare_s3[get_bucket_lifecycle_configuration] PASSED [ 40%]
- tests/integration/test_import_bucket.py::test_compare_s3[get_bucket_location] PASSED [ 45%]
- tests/integration/test_import_bucket.py::test_compare_s3[get_bucket_logging] PASSED [ 50%]
- tests/integration/test_import_bucket.py::test_compare_s3[get_bucket_metrics_configuration] PASSED [ 54%]
- tests/integration/test_import_bucket.py::test_compare_s3[get_bucket_notification] PASSED [ 59%]
- tests/integration/test_import_bucket.py::test_compare_s3[get_bucket_notification_configuration] PASSED [ 63%]
- tests/integration/test_import_bucket.py::test_compare_s3[get_bucket_ownership_controls] PASSED [ 68%]
- tests/integration/test_import_bucket.py::test_compare_s3[get_bucket_policy] PASSED [ 72%]
- tests/integration/test_import_bucket.py::test_compare_s3[get_bucket_policy_status] PASSED [ 77%]
- tests/integration/test_import_bucket.py::test_compare_s3[get_bucket_replication] PASSED [ 81%]
- tests/integration/test_import_bucket.py::test_compare_s3[get_bucket_request_payment] PASSED [ 86%]
- tests/integration/test_import_bucket.py::test_compare_s3[get_bucket_tagging] FAILED [ 90%]
- tests/integration/test_import_bucket.py::test_compare_s3[get_bucket_versioning] FAILED [ 95%]
- tests/integration/test_import_bucket.py::test_compare_s3[get_bucket_website] PASSED [100%]
- ========================================================================== FAILURES ===========================================================================
- ...
- ___________________________________________________________ test_compare_s3[get_bucket_versioning] ____________________________________________________________
- ...
- > assert(response_list[compare_bucket_list[0]] == response_list[compare_bucket_list[1]])
- E AssertionError: assert {'Status': 'Suspended'} == {'Status': 'Enabled'}
- E Differing items:
- E {'Status': 'Suspended'} != {'Status': 'Enabled'}
- E Full diff:
- E - {'Status': 'Enabled'}
- E ? ^ ^^^
- E + {'Status': 'Suspended'}
- E ? ^^^^^ ^
- tests/integration/test_import_bucket.py:40: AssertionError
- =================================================================== short test summary info ===================================================================
- FAILED tests/integration/test_import_bucket.py::test_compare_s3[get_bucket_tagging] - AssertionError: assert {} == {'TagSet': [{...rt5CB87213'}]}
- FAILED tests/integration/test_import_bucket.py::test_compare_s3[get_bucket_versioning] - AssertionError: assert {'Status': 'Suspended'} == {'Status': 'Enabl...
- ================================================================ 2 failed, 20 passed in 2.09s =================================================================
上記の結果を見るとget_bucket_taggingとget_bucket_versioningの関数結果に差分があることを確認出来ます。バージョニングの方の結果を見ると、ステータスに差異があるため、hogehoge-compareバケットにバージョニング設定が入っていることが分かります。その為、バージョニング設定を外して同じような設定にしていくというCDKコードの修正が必要だと分かります。
今回は対象をS3バケットにしましたが、これをVPCにするとboto3のEC2ドキュメントを参考に、メソッド取得を下記のように修正していけば可能になります。
- client = boto3.client(service_name='ec2')
- for method_name in dir(client):
- if re.compile('^describe.*?vpc').search(method_name):
ただし、関数によっては今回みたいに同じ引数を持つものばかりではないので、多少関数を実行する部分は修正が必要になります。
まとめ
本記事では、CDKインポートの方法とその弱点、弱点の乗り越え方について説明しました。
正直取り込みだけでここまでやりたくないという声もあるかと思われます。しかし、我々はCDKを使いたいのです。なにがなんでもCDKに取り込んでやりましょう。
というのは冗談ですが、取り込みコストとしてこのような作業が必要になることを理解しておきましょう。それを加味してCDKで取り込むのかTerraformで取り込むのか、それとも取り込まないという選択肢を取るのかを判断していきましょう。
是非本記事を参考にリソースの取り込み方を考えて頂ければ幸いです。
