機械学習で芸能人の顔を分類してみよう!
みなさん、機械学習やってますか? お久しぶりです。mediba広告システム開発部の原です。
前回はChrome Extensionを活用して広告のプレビューとかに活用しよう!って記事を書きました。
広告のプレビューをchrome-extensionで解決する
その後、部署が広告システム開発部に移りましての再登板。今回は機械学習について記事を書いていきます。 アドテク分野でも活用できますしね。
今回の記事では機械学習でどんなことが出来るのか、という紹介ができればな、贅沢を言えば、読んだ皆さんに「よし、じゃあやってみようかな」と思っていただくことに主眼をおいているので、技術的な目新しさとかは考慮していません。
こんなことが出来るんだ、見ているみなさんに気づいていただければ成功かな、と思っています。
開発環境
最初に環境の話です。 本記事の作成・検証環境は以下のとおりです。
- Mac OS X 10.10.5
- Python 2.7.10
- OpenCv 2.4.12
- tensorflow 0.9.0
- Network Kanji Filter Version 2.1.4
機械学習とは?
つづいて機械学習について、ですが。 これが何なのか、というのはそれだけで記事が何本も書けてしまうので、今回は簡単な説明にとどめます。
すごく大雑把に言うと、
データの持っている傾向、パターンをコンピュータによるデータ解析でつかもうぜ
という取り組みのことだと思ってください。
例えばスパムメールかどうかを本文などから判断できるか、アクセスの傾向からユーザの性別や年代を特定することが出来るか、といった課題が、よく機械学習の例として挙げられます。
その中から、今回はGoogleが自社開発したオープンソースの人工知能ライブラリ「TensorFlow」 を使った画像分類に取り組んでみたいな、と。
芸能人の顔を画像から分類する
さて、今回の取り組みは、タイトルの通り「機械学習で芸能人の顔を分類する」という内容です。
よく人の顔を例えるのにしょうゆ顔とかソース顔っていいますが、あれってデータ的な傾向はあるのかな、あるとしたら画像解析で分類できないかな、というチャレンジになります。
具体的には以下に分類できないかな、と。
- しょうゆ顔
- しお顔
- ソース顔
- みそ顔
豚骨がないのが残念ですが、果たしてコンピュータは画像から顔の特徴を数値化、分類できるでしょうか。
データ作り
まずは学習させるデータを作ります。
今回は顔のデータを分類するので、画像データそのものとどんな顔なのかというラベルが必要になります。
つまり、コンピュータに「こういう顔をしょうゆ顔と言うんですよ」と教えていくわけです。
どういう課題に対してどんなデータが必要なのかというのは機械学習のキモなのですが、それを書くと文量がとてもすごいことになるので今回は割愛させてください。
リストアップ
まずはしょうゆ顔、ソース顔、しお顔を代表する人たちを調べます。
こちらからリストを拝借しました。
できあがったリストはこんな感じ(person.txt)。
soy Mukai 向井理
soy Higashi 東山紀之
sio Oikawa 及川光博
sio Eita 瑛太
sauce Abe 阿部寛
sauce Hirai 平井堅
miso Matsuken 松平健
miso Watanabe 渡辺謙本来であればそれぞれ10人位欲しいところですが、今回は機械学習ってこんなことできるよ、という例を示すのが目的なのでこのくらいにしておきます。
画像の収集
リストに上がった芸能人の画像を収集します。
どうやってもいいですが、wgetを再帰的に利用するのが便利なので今回はシェルスクリプトでBingのURL叩く方法でやってみました。
APIでもいいんですが、Googleはオフィシャルにはクローズしています(利用はできるようですが)し、アカウント認証なども必要になりますので、ここは簡単にすませましょう。
勿論、データボリューム拡充等の理由で必要であれば、そうした手続きを踏んだ上で、APIを使うのが適切だと思います。
#!/bin/bash
# 人物データファイル定義
PERSON="./person.txt"
# 中間ディレクトリ定義
tmp="../tmp"
# アウトプットディレクトリ定義
out='../data/img_origin/'
# アウトプットディレクトリを絶対パスで取得
SCRIPT_DIR=`dirname $0`
pushd $out
aout=`pwd`
popd
# URLエンコード関数定義
urlencode () {
echo "$1" | nkf -WwMQ | tr = %
}
# 画像収集関数定義
imageGather () {
if [ $# -ne 3 ]; then
return false
fi
class=$1
enName=$2
jaName=$3
# 人物名をエンコード
encodedName=`urlencode $3`
echo $encodedName
# URLを作成
url="https://www.bing.com/images/search?&q="
url=$url$encodedName
# テンポラリディレクトリ作成・移動
mkdir -p $tmp/${class}/${enName}
pushd $tmp/${class}/${enName}
# wgetでJPEG画像のみ収集
wget -r -l 1 -A jpg,JPG,jpeg,JPEG -H \
-erobots=off \
--exclude-domains=bing.com,bing.net \
$url
find . -type f \( -name "*.jpg" -o -name "*.JPG" -o -name "*.jpeg" -o -name "*.JPEG" \) | \
awk \
-v "out=$aout" \
-v "class=$class" \
-v "enName=$enName" \
'{
command = sprintf("cp %s %s/%s_%s_%05d.jpg", $0, out, class, enName, NR)
# コマンドを実行して結果を取得
buf = system(command);
# stream をclose
close(command);
}'
popd
}
# 画像収集実行
while read line; do
imageGather $line
done 1:実行した結果、202枚(執筆時現在)の画像が集まりました。 ……学習にかけるには、いかにも不安なボリュームです。本来ならば元リストを拡充するところですね。 まあ重ねて書きますが、「こんなことできるよ」が今回の記事の目的なので気にしません。
顔だけを切り出す
続いて、あつめた画像について、pythonとOpenCVで顔部分だけを切り出します。
# -*- coding: utf-8 -*-
import sys
import cv2
# 引数格納
params = sys.argv
argc = len(params)
if(argc != 2):
print '引数を指定して実行してください。'
quit()
# 画像ディレクトリ定義
inDir = "../data/img_origin/"
outDir = "../data/face_only/"
errDir = "../data/error/"
#カスケード分類器ロード ※必要に応じて変更してください。
cascade_path = "/usr/local/Cellar/opencv/2.4.12_2/share/OpenCV/haarcascades/haarcascade_frontalface_alt.xml"
# 執筆時デフォルトで含まれている顔認識データセット
# haarcascade_frontalface_default.xml
# haarcascade_frontalface_alt.xml
# haarcascade_frontalface_alt2.xml
# haarcascade_frontalface_alt_tree.xml
# haarcascade_profileface.xml
image_path = inDir + params[1]
print image_path
#ファイル読み込み
image = cv2.imread(image_path)
if(image is None):
print '画像を開けません。'
quit()
#グレースケール変換
image_gray = cv2.cvtColor(image, cv2.COLOR_RGB2GRAY)
#カスケード分類器の特徴量を取得する
cascade = cv2.CascadeClassifier(cascade_path)
#物体認識(顔認識)の実行
facerect = cascade.detectMultiScale(image_gray, scaleFactor=1.1, minNeighbors=1, minSize=(1, 1))
if len(facerect) == 1:
print "顔認識に成功しました。"
print facerect
#検出した顔の処理
for rect in facerect:
#顔だけ切り出して保存
x = rect[0]
y = rect[1]
width = rect[2]
height = rect[3]
dst = image[y:y+height, x:x+width]
new_image_path = outDir + params[1]
cv2.imwrite(new_image_path, dst)
elif len(facerect) > 1:
# 複数顔が検出された場合はスキップ
print "顔が複数認識されました"
print facerect
if len(facerect) > 0:
color = (255, 255, 255) #白
for rect in facerect:
#検出した顔を囲む矩形の作成
cv2.rectangle(image, tuple(rect[0:2]),tuple(rect[0:2] + rect[2:4]), color, thickness=2)
#認識結果の保存
new_image_path = errDir + params[1]
cv2.imwrite(new_image_path, image)
quit()
else:
# 顔検出に失敗した場合もスキップ
print "顔が認識できません。"
quit()引数として渡されたファイル名の画像ファイルを、収集した画像ディレクトリをデータソースから取り出して、「顔」を探しています。
もし「顔」を見つけることが出来たら、その範囲を切り出して別ディレクトリに書き出します。
本来であればこのファイルが正しく存在しているか、正常な画像ファイルであるか等のバリデーションチェックも必要でしょうが、ここでは割愛。
途中で読み込んでいるカスケード分類器ですが、本項執筆環境で一番効率よく動いたものを採用しています。
検出したい顔の特徴などの理由で、別のxmlを使うほうが良いかもしれませんので、色々ためしてみてください。。
なお、この仕組だと1つの画像から複数の顔を検出することがあります。集合写真は勿論、影などによる誤検知とかが理由です。
同様の理由で、顔が見つからない、なんて場合も。
そこで、顔が認識できなかった場合、複数の顔が検出された場合はエラー処理しました。
この辺の処理はどのようなデータがどれだけ欲しいか次第ですね。
続いてこのpythonスクリプトを実行するためのシェルスクリプトです。
#!/bin/bash
# 画像ディレクトリ定義
out='../data/img_origin/'
# 画像処理スクリプト名定義
script='recognize.py'
for file in `ls ${out}`; do
python ${script} ${file}
doneシンプルです。
作ったシェルスクリプトを実行したところ、158枚の「顔」と認識される画像が抽出されました。
これらをさらに直接チェックして、イラストや誤検知ファイルを取り除いていき、残った146枚の「顔」画像を元に学習を行うことにします。
学習データ準備
データが揃ったら、それをTensorflowに読ませる準備です。具体的には以下の作業を行います。
- 画像をランダムに並び替え
- train用データとtest用データに機械的に分ける
- データとラベルをセットにしたCSVを作成する
ラベル付けのためのデータ分類用の値は以下とします。
- 1:しょうゆ顔
- 2:しお顔
- 3:ソース顔
- 4:みそ顔
train用データとtest用データの比率については、とりあえず7:3くらいで試してみます。
#!/bin/bash
# 画像ディレクトリ定義
sourceDir='../data/face_only'
trainDir='../data/train'
testDir='../data/test'
# train用データ格納閾値
threshold=70
# カウンタ変数定義
cTrain=0
cTest=0
# 結果出力用CSV作成
trFile='trainDat.csv'
teFile='testDat.csv'
touch ${trFile}
touch ${teFile}
# 顔タイプ返却関数定義
function getFaceType () {
case "$1" in
"soy" ) echo 1;;
"sio" ) echo 2;;
"sauce" ) echo 3;;
"miso" ) echo 4;;
esac
}
# lsとsortを組み合わせてランダムに処理
for file in `ls ${sourceDir}/*.jpg | while read x; do echo -e "$RANDOM\t$x"; done | sort -k1,1n | cut -f 2-`; do
# ファイル名成形
bn=${file##*/}
kw=${bn%%_*}
key=`getFaceType ${kw}`
if [ `expr $RANDOM % 100` -lt ${threshold} ] ; then
#train用のデータ
cp ${file} ${trainDir}/${bn}
echo "${file},${key}" >> ${trFile}
cTrain=$((cTrain+1))
else
#test用のデータ
cp ${file} ${testDir}/${bn}
echo "${file},${key}" >> ${teFile}
cTest=$((cTest+1))
fi
done
echo "Train:${cTrain}"
echo "Test:${cTest}"これを実行して、104枚のトレーニング用画像、42枚のテスト用画像に分け、それぞれCSVに分類コードと一緒に格納しました。
学習の実行
ながなが書いてきたのですが、これまではすべて準備。
Tensorflowで学習していきます。
用意するCNNは
- 入力28x28x3
- 第1畳み込み層とプーリング
- 第2畳み込み層とプーリング
- 高密度結合層1
- 高密度結合層2
- ソフトマックス層
となります。
この構造については、後述の参考ブログから拝借しました。
なんちゃら層とか言葉の意味がわからないよ、という方向けに、参考URLを幾つか上げておきます。
- TensorFlowチュートリアル - 熟練者のためのディープMNIST(翻訳)
- TensorFlowコトハジメ 手書き文字認識(MNIST)による多クラス識別問題
- Theanoによる畳み込みニューラルネットワークの実装 (1)
さて、この学習部分は下記ブログがほとんどそのまま利用できました。先達は偉大ですね。
したがって、ここではコードの全文掲載はしません。 また、後述のgithubにも含める予定はありません。
変更点だけ記載すると、
- コード値が0〜1ではなく、1〜4なので、NUM_CLASSES = 4にし、tmp配列の添字も1ずらす
- CSVのロードなのでline.splitのデリミタをカンマにする
ホント、これだけで動いちゃうんです。すげぇ。
step 195, training accuracy 0.980769
step 196, training accuracy 0.980769
step 197, training accuracy 0.980769
step 198, training accuracy 0.980769
step 199, training accuracy 0.980769
test accuracy 0.785714実行してみたところ、testデータの正答率は78.6%…
多少不満ですが、データ数が少ないこともあり仕方ないかと。
本項の最後に、TensorBoardによるCNNと学習精度グラフを掲載しておきます。
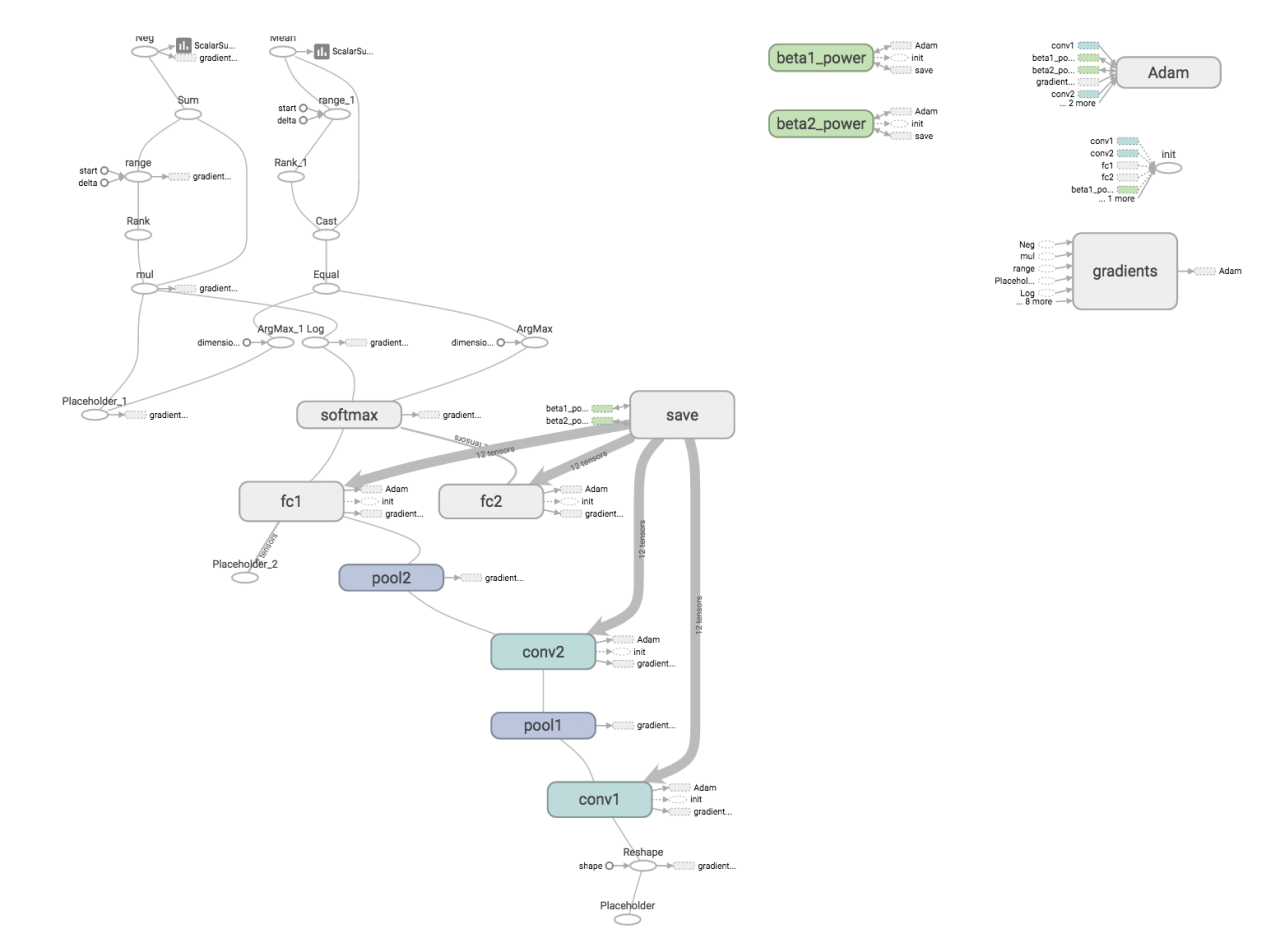
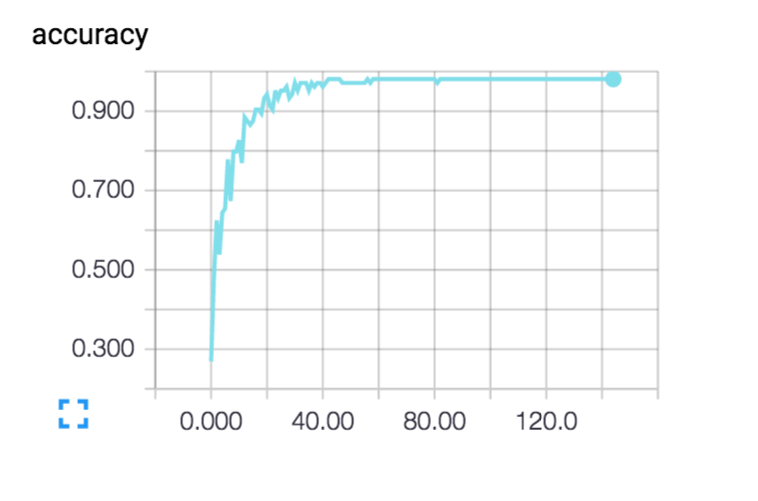
モデルの活用
実行した結果は学習モデルとして、チェックポイントファイルに保存されます。 このファイルを使うことで、別の画像についても同じモデルで分類することが出来ます。
で、ここも先達がやっているわけで。。。
テストコードをつくって、弊社CTOの写真を解析してみます。
{kind=link}
$ python testFaceType.py cto.jpg
22。 つまりしお顔。
……コンピュータ的にはそうなのか。。。
ミソとかを想定していたんだけど、最初に集めるデータのボリュームとラベル付けが足りなかったかなぁ…
機械学習精度向上にむけての考察
今回は少ないテストデータで行ったの結果、ちょっと想定と違う結果が得られたわけですが、色々な改善の余地があると思います。
例をあげますと、
- データの拡充、ラベル付け時点での精度向上
→正しいデータ集め。仮に少ないデータでも、CVに画像の反転や回転機能がありますので、それでかさ増しをするテクニックなんかもあります。
- CNNの構造改良
→今回は前例に倣う形で畳み込み層とプーリングを2重にする構造を採用しましたが、これが最適かどうか、トライ・アンド・エラーで検証していく必要があります。同時に各層で利用している学習パラメータもまだまだチューニングできます。
- そもそもの学習テーマと収集データの方向性が正しいのかの検証
→そして、何よりこの項目が大切です。 機械学習は「データさえ渡せば適用に予測してくれるもの」ではありません!
- どういう課題を解決したいのか?
- そのために適切な学習アルゴリズムはどういうものか?
- そのアルゴリズムを実現するのに必要なデータはどういうものか?
しっかり考えて、適切な方法を試す。その実現のためにこういう汎用的な例から慣れていきましょう!
github
本項で書いたコードについて、下記レポジトリに公開しました。 試してみよう、というかたは是非ご活用ください。
https://github.com/medi-hara/faceClassify
最後に
機械学習について学ぼうとすると、数式とか観念的な記述に多くぶち当たって一見ハードルが高そうに見えます。
が、実際には今回の記事のように多くの先達がトライして、そのログを公開してくださっている分野で、思った以上に入門しやすいジャンルです(熟練はやはり難しいですが)。
だから、コード丸写しでいいからとにかく一度やってみようよ、やってみると意外と楽しいよ、ということを伝えたくてこの記事を書きました。
うまく意図が伝わるといいのですが……
ともあれ皆さん、機械学習、はじめてみませんか?
その他注意など
本記事ではリストが小さいため特に配慮していませんが、検索ボリュームによっては検索エンジン側に負荷をかけないようにwaitをかけるなど各自工夫してください。
本記事のスクリプトを利用してのトラブル等については、一切の責任を負いかねます。
