みなさんこんにちは、電通国際情報サービス(ISID)コーポレート本部 システム推進部の佐藤太一です。
先日、TECHPLAYでDataflowに関連するお話をしました。
その日の模様が公開されていますので、ご興味のある方は是非ご覧ください。
さて、このエントリではBigQueryにおいて利用できる再帰クエリ(WITH RECURSIVE句とUNION ALL)について紹介します。
再帰クエリを使うと、表形式しか扱えないRDBにおいて木構造のデータを扱えます。 木構造のデータとは、例えば会社における組織図のようなものを想像してください。
ちなみに、Oracleなら再帰クエリはSTART WITH句とCONNECT BY句で実現していましたよね。
- 前提となるデータ
- 一番簡単な再帰クエリ
- 再帰クエリに配列を導入する
- 再帰クエリに導入した配列のオフセット位置を使う
- 再帰クエリと条件分岐を組み合わせる
- 再帰クエリと副問い合わせを組み合わせる
- 再帰クエリに導入した配列をソースに副問い合わせする
- まとめ
前提となるデータ
再帰クエリの話を始める前に、まずはこのエントリで取り扱うデータ構造について説明しておきましょう。
今回の説明に使うのは以下のような組織図をデータベースに格納したものです。
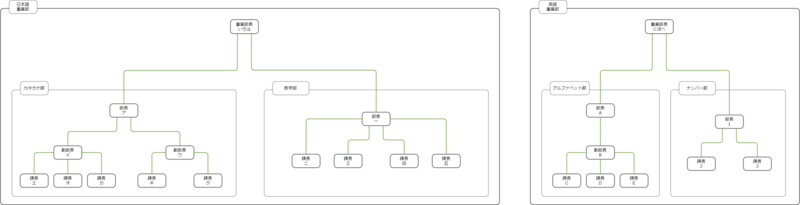
二つの事業部があり、それぞれに事業部長(いろは、にほへ)がいます。 事業部長が統括する事業部には、それぞれの部署には部長がいます。日本語事業部にはカタカナ部と数字部があり、英語事業部にはアルファベット部とナンバー部があります。 部長の下には副部長がいる部門(カタカナ部、アルファベット部)とそうでない部門(数字部、ナンバー部)があります。 副部長の有無に関わらず、部門内にはいくつかの課があり、それぞれに課長がいます。
データを定義するクエリ
それでは、BigQueryに投入可能なCREATE TABLE文をお見せしましょう。
create or replace table taichi_test.organization ( # 1. id int64 not null, # 2. parent int64, # 3. department string, # 4. title string not null, # 5. name string not null # 6. );
- taichi_test については、読者の皆さんがご自分で用意したデータセット名を指定してください。
- idカラムはこのテーブルのプライマリキーとなるものです。なお、BigQueryに一意制約はありません。
- 各レコードが親となるレコードのidを指定するためのカラムです。親がいない事業部長はnullになります。例えば、部長の親レコードは事業部長です。
- 部署名を格納するカラムです。事業部長の部署名は事業部名になります。
- 図の中では箱の一行目に書かれている役職名を格納するカラムです。
- 図の中では箱の二行目に書かれている社員名を格納するカラムです。
データを投入するクエリ
データを投入するためのINSERT文です。
insert into taichi_test.organization values (1, null, "日本語事業部", "事業部長", "いろは") , (2, 1, "カタカナ部", "部長", "ア") , (3, 2, "カタカナ部", "副部長", "イ") , (4, 2, "カタカナ部", "副部長", "ウ") , (5, 3, "カタカナ部", "課長", "エ") , (6, 3, "カタカナ部", "課長", "オ") , (7, 3, "カタカナ部", "課長", "カ") , (8, 4, "カタカナ部", "課長", "キ") , (9, 4, "カタカナ部", "課長", "ク") , (10, 1, "数字部", "部長", "一") , (11, 10, "数字部", "課長", "二") , (12, 10, "数字部", "課長", "三") , (13, 10, "数字部", "課長", "四") , (14, 10, "数字部", "課長", "五") , (15, null, "英語事業部", "事業部長", "にほへ") , (16, 15, "アルファベット部", "部長", "A") , (17, 16, "アルファベット部", "副部長", "B") , (18, 17, "アルファベット部", "課長", "C") , (19, 17, "アルファベット部", "課長", "D") , (20, 17, "アルファベット部", "課長", "E") , (21, 15, "ナンバー部", "部長", "1") , (22, 21, "ナンバー部", "課長", "2") , (23, 21, "ナンバー部", "課長", "3");
BigQueryではINSERT文を複数並べるよりも、このようにBulk INSERTをすると高速にデータの投入が終わります。
一番簡単な再帰クエリ
では再帰クエリを実行していきましょう。再帰クエリの詳細なリファレンスはBigQueryのRECURSIVE キーワードを参照してください。
with recursive org_rec as ( select id ,parent, department, title, name, "" as manager # 1. from `taichi_test.organization` where parent is null union all select b.id, b.parent, b.department, b.title, b.name, a.name as manager # 2. from org_rec a,`taichi_test.organization` b where a.id = b.parent ) select department, title, name, manager from org_rec where id < 15 order by id;
このクエリでは、部署名、役職名、社員名に加えて、当該社員のマネージャーが誰なのかを検索します。
- 再帰クエリではカラム数を合わせる必要があり、親レコードがない場合には空文字を選択しています。
- 再帰クエリにおける上位レコードから社員名を選択しています。これによってマネージャーが誰なのか分かるのです。
このSQLの実行結果を見てみましょう。
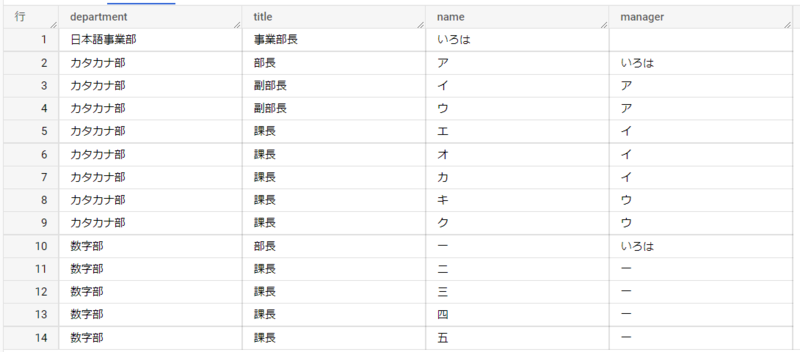
部長であるアさんと一さんのmanagerとしていろはさんが選択されていますね。 副部長や、課長の皆さんについても、対応するマネージャーが選択されています。
再帰クエリに配列を導入する
次は再帰クエリから得られる木構造において、親に向かう経路を分析してみましょう。 それには、再帰しながら配列を組み立てていくSQLを発行します。
with recursive org_rec as (
select id ,parent, department, title, name,
array[name] as path # 1.
from `taichi_test.organization`
where parent is null
union all
select b.id, b.parent, b.department, b.title, b.name,
array_concat(a.path, [b.name]) as path # 2.
from org_rec a,`taichi_test.organization` b
where a.id = b.parent
)
select department, title, name,
array_length(path) as level, # 3.
array_to_string(path, ", ") as route # 4.
from org_rec where id < 15 order by id;
- 配列を社員名で初期化します。
- 上位階層から来た配列に現在の階層における社員名を追加します。
- array_length関数を使って配列の長さを得ることで階層における位置を選択しています。
- 各社員から階層をたどる経路は、array_to_string関数を使って配列を結合すると得られます。
このSQLの実行結果を見てみましょう。
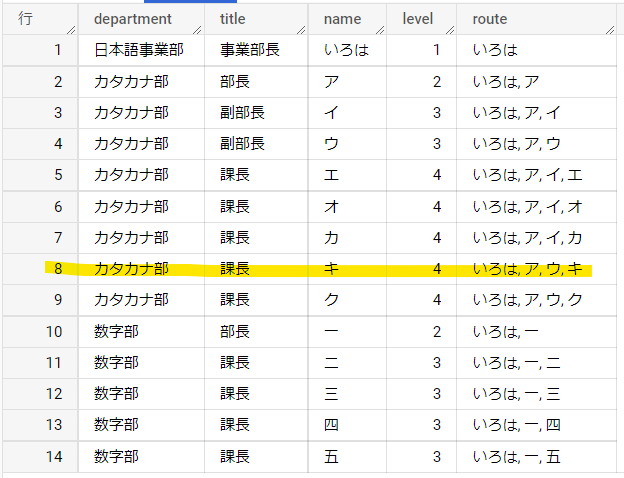
例えば、8行目のキさんについて選択されたレコードを見てください。
組織図でキさんからいろは事業部長までの経路を確認するとこのようになっています。
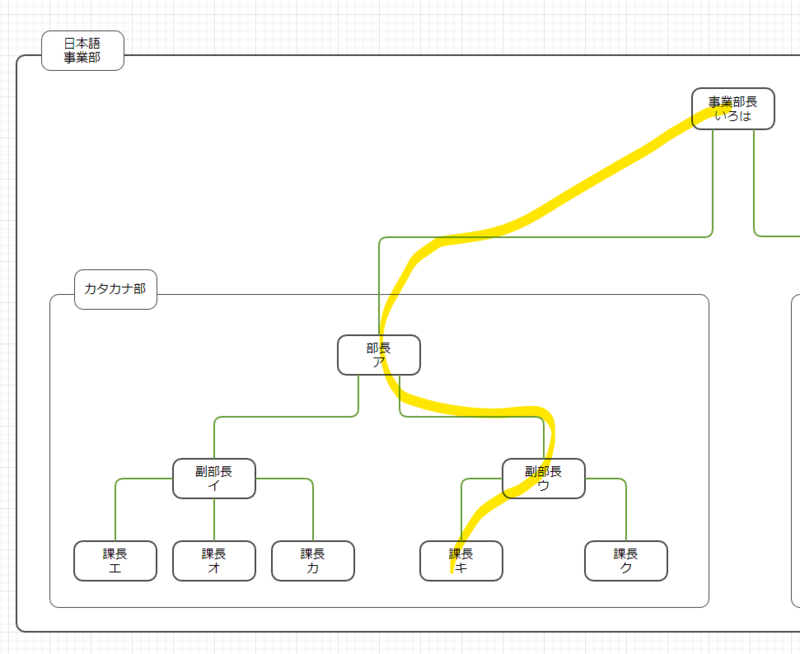
いろは事業部長から見てキさんはア部長の部下であるウ副部長の部下ですね。 つまり、levelカラムが示すように4層目にいて、その経路は「いろは→ア→ウ→キ」となるわけです。
再帰クエリに導入した配列のオフセット位置を使う
再帰クエリで木構造をたどるには配列を使うと説明しましたが、配列なのでオフセット位置を直接指定できます。
例えば、以下のようなクエリが考えられます。
with recursive org_rec as (
select id ,parent, department, title, name,
array[name] as path
from `taichi_test.organization`
where parent is null
union all
select b.id, b.parent, b.department, b.title, b.name,
array_concat(a.path, [b.name]) as path
from org_rec a,`taichi_test.organization` b
where a.id = b.parent
)
select
path[offset(0)] as bigboss, # 1.
count(path[offset(0)]) as members # 2.
from org_rec
group by bigboss # 3.
- 各社員の列にある0番目の要素には必ず事業部長が入っています。
- レコードとして事業部長が出現する回数を数えています。
- 事業部長でグルーピングしています。
このSQLの実行結果を見てみましょう。
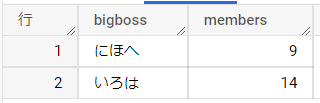
各事業部長に連なる社員が事業部長本人を含めて何名なのか選択されていますね。
再帰クエリと条件分岐を組み合わせる
再帰クエリで作った配列のオフセット位置を使ってマネージャーを選択してみましょう。
with recursive org_rec as (
select id ,parent, department, title, name,
array[name] as path
from `taichi_test.organization`
where parent is null
union all
select b.id, b.parent, b.department, b.title, b.name,
array_concat(a.path, [b.name]) as path
from org_rec a,`taichi_test.organization` b
where a.id = b.parent
)
select title, name,
path[offset(array_length(path)-2)] as boss # 1.
from org_rec order by id;
- オフセット位置として配列の長さから2を引いた値を使っています。
これを実行すると以下のようなエラーになって期待した通りには動作しません。
Array index -1 is out of bounds (underflow)
事業部長はマネージャーがいないので配列の長さが1です。それによってこのようなエラーになる訳です。 ここでは、case句を使って問題に対処してみましょう。
with recursive org_rec as (
select id ,parent, department, title, name,
array[name] as path
from `taichi_test.organization`
where parent is null
union all
select b.id, b.parent, b.department, b.title, b.name,
array_concat(a.path, [b.name]) as path
from org_rec a,`taichi_test.organization` b
where a.id = b.parent
)
select department, title, name,
(case
when array_length(path) < 2 then null # 1.
else path[offset(array_length(path)-2)] # 2.
end) as manager
from org_rec where id < 15 order by id;
- 配列の長さが2を下回るものについてはnullを選択しています。
- 配列の長さが2を下回らないものについては、長さから2を引いた値を指定することでマネージャーを選択しています。
このSQLの実行結果を見てみましょう。
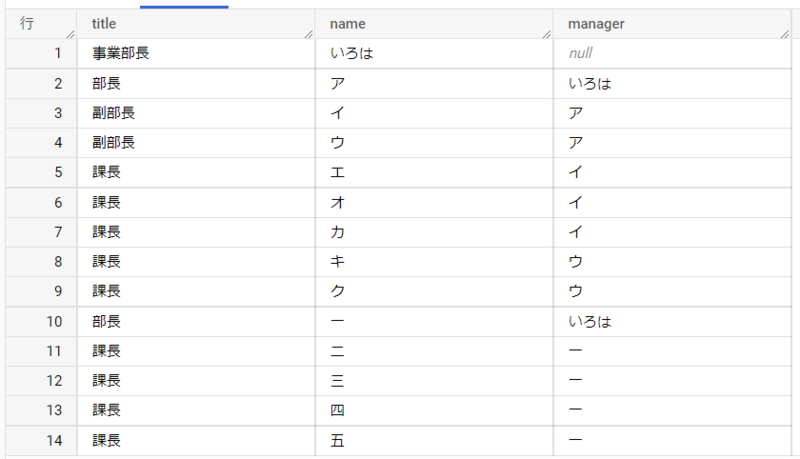
最初に説明したクエリと同じ結果が得られていますね。
再帰クエリと副問い合わせを組み合わせる
次は、再帰クエリで作った配列を使って各社員にとっての事業部長を選択してみましょう。
with recursive org_rec as (
select id ,parent, title, name,
array[id] as path # 1.
from `taichi_test.organization`
where parent is null
union all
select b.id, b.parent, b.title, b.name,
array_concat(a.path, [b.id]) as path # 2.
from org_rec a,`taichi_test.organization` b
where a.id = b.parent
)
select title, name,
(select name
from `taichi_test.organization` where id = path[offset(0)] # 3.
) as bigboss
from org_rec where id < 15 order by id;
- 配列をidで初期化します。
- 上位階層から来た配列に現在の階層におけるidを追加します。
- 各レコードに含まれる配列の0番目は必ず事業部長のidが入っています。つまり、特に条件を指定せずにオフセット位置を指定できます。
このSQLの実行結果を見てみましょう。
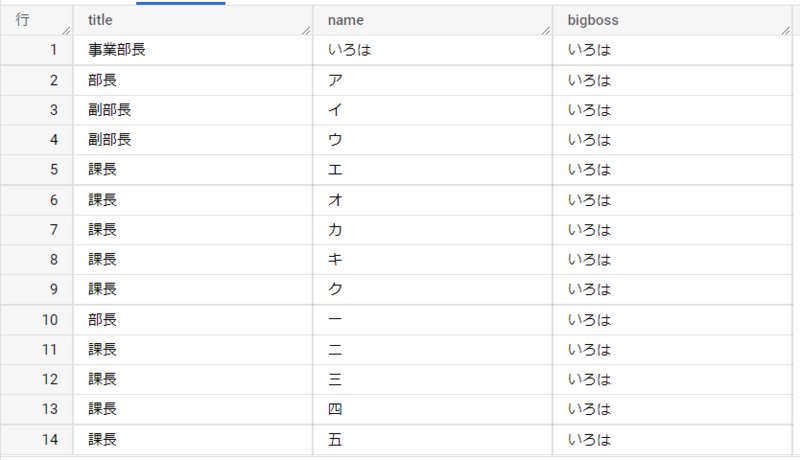
bigboss列にいろは事業部長が入っていますね。事業部長だけは自己参照しており奇妙な状態になっていますが、これに対する対処は皆さん、ご自分でやってみてください。
説明のためにSELECT句の中で副問い合わせをしましたが、あまり褒められたものではありません。こういう時は本来INNER JOINを使って情報を付加しましょう。
with recursive org_rec as (
select id ,parent, title, name,
array[id] as path
from `taichi_test.organization`
where parent is null
union all
select b.id, b.parent, b.title, b.name,
array_concat(a.path, [b.id]) as path
from org_rec a,`taichi_test.organization` b
where a.id = b.parent
)
select a.title, a.name, b.name as bigboss
from org_rec as a inner join `taichi_test.organization` as b on a.path[offset(0)] = b.id
where a.id < 15 order by a.id;
再帰クエリに導入した配列をソースに副問い合わせする
最後は、もう少し複雑なクエリを実行してみましょう。
所で、最初のCREATE TABLE文の説明に奇妙な部分があったのはお気づきでしょうか? departmentカラムに入るデータが、事業部長を表すレコードの時だけ事業部名が入っています。 本来的には単一のカラムに複数の意味合いを持たせることは望ましくないのですが、ついうっかりデータを圧縮するためにやってしまいました。
私の手抜きによるやらかしに、データの洗い替えをせずにSQLだけで対処してみましょう。
with recursive org_rec as (
select id ,parent, department, title, name,
array[id] as path
from `taichi_test.organization`
where parent is null
union all
select b.id, b.parent, b.department, b.title, b.name,
array_concat(a.path, [b.id]) as path
from org_rec a,`taichi_test.organization` b
where a.id = b.parent
)
select
(select department
from `taichi_test.organization` inner join (
select level from unnest(path) as level with offset where offset = 0 # 1.
) as levels on id = levels.level) as unit,
department, title, name
from org_rec order by id;
- BigQueryではunnest関数を使うと配列をテーブルであるかのように扱えます。また、併せてwith offset句を使うとクエリの中で配列のオフセット位置を参照できます。
このSQLの実行結果を見てみましょう。
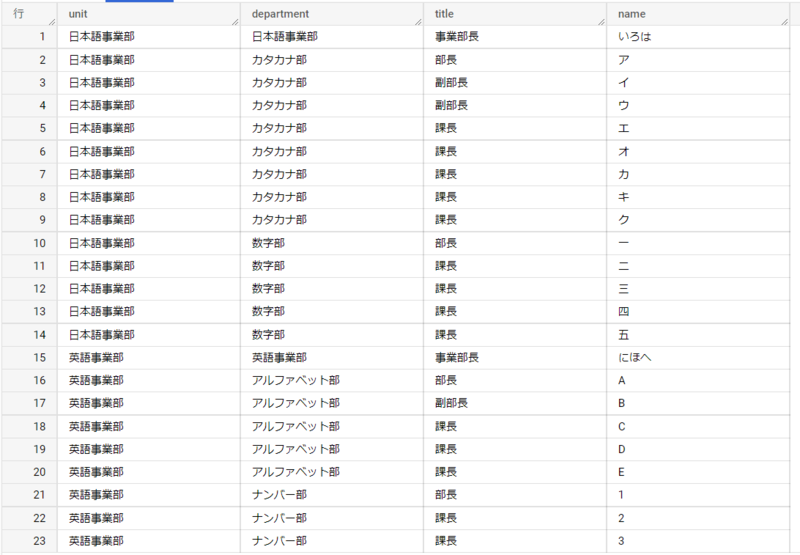
各レコードに事業部名が選択できていますね。
まとめ
今回エントリでは、BigQueryにおける再帰クエリの使い方について詳しく説明しました。 再帰クエリを使う上で配列と組み合わせることはある種のイディオムなのですが、あまり知られていません。 これを知っているだけで、データ分析の幅は確実に広がりますので是非使いこなしてください。
私たちは同じチームで働いてくれる仲間を探しています。今回のエントリで紹介したような仕事に興味のある方、ご応募をお待ちしています。
執筆:@sato.taichi、レビュー:@yamashita.tsuyoshi (Shodoで執筆されました)



