サーバサイドエンジニアの松木 (@tatsuma_matsuki) です。Safie解析プラットフォームやSafie APIの開発を主に担当しています。
この記事はSafie Engineers' Blog! Advent Calendar 4日目の記事です。
解析プラットフォームでは、学習済みモデルおよびランタイムをSafieクラウド上に登録することで、Safieサービスで録画したカメラの映像・画像に対して、任意の推論処理を実行し、その実行結果をイベントとして保存することができます。
まだサービス公開はされていませんが、まずは社内エンジニアで利活用の推進したいという思いから、Safie解析プラットフォームを利用したアプリケーションの開発を実践しています。
私はサーバサイドのエンジニアで、機械学習の分野には明るくないのですが、今回解析プラットフォーム上でのアプリ構築を一から自力で開発可能にするために、学習済みモデルの作成と推論処理の実装を初めてやってみました!
結果として、なかなか高い精度を出すまではまだ少し時間がかかりそうですが、その作業・開発工程をこの記事で共有したいと思います。
開発するアプリケーション
まずは適当に思いついたものを開発してみよう!ということで、オフィスにいる弊社のCTOがカメラに写ったら検知して、通知(メール・Slack)を出すようにすることを目標としました。
弊社の五反田オフィスは、4F、5F、8Fの3フロアあり、分析対象として使えそうなカメラが10台弱ほど設置されています。様々なアングルや大きさで人が写りこみますが、全てのカメラで汎用的に使用できるアプリケーション(モデル)を作成できればベストです。

画像や動画の収集は簡単!
Safie社内で学習用の画像を集めるのはとても簡単です!
オフィス内にカメラが既に常時稼働しており、過去の映像も全て確認できるため、Safie Viewerからポチポチやるだけで画像がどんどん集まります。
Safie Viewerのストリーミング画面を開いて、右上のカメラのアイコンをクリックするとその時に写っている画像のスナップショットが取得できます。
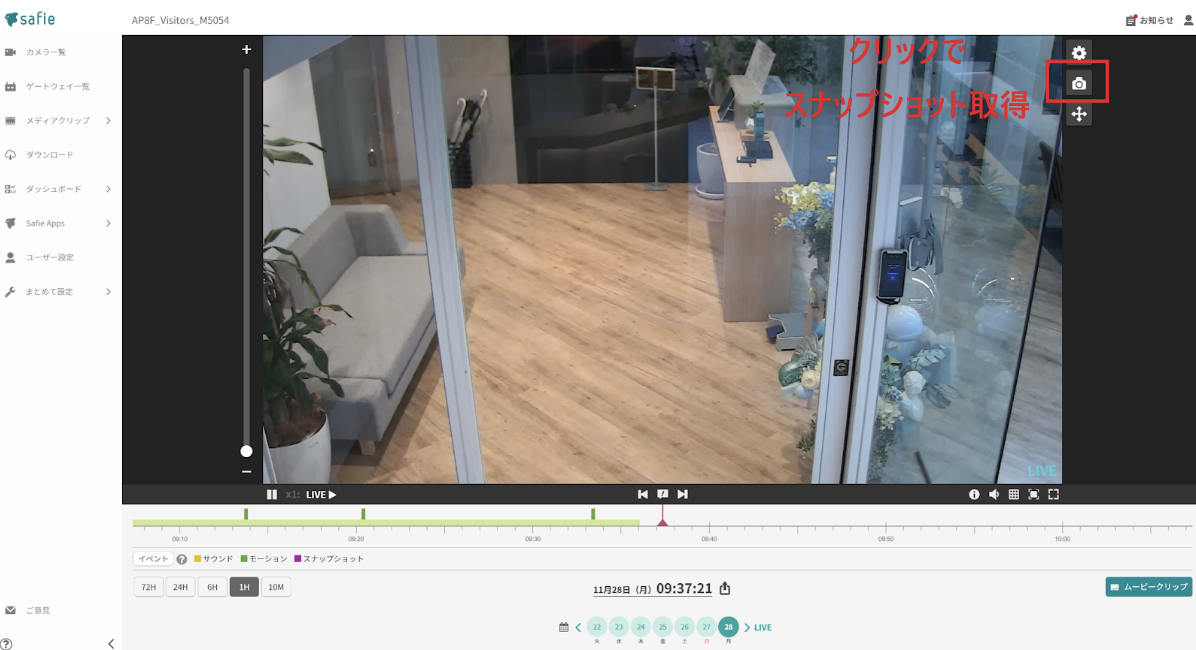
実質1~2時間ほどで、様々なカメラから合計400枚ほどの学習用画像が集まりました。
学習(モデル作成)
今回開発するアプリケーションの場合、入力画像を「CTOが映っている」「CTOが写っていない」の二つに分類するモデルを作成する必要があります。
Efficientnetという有名な分類系のモデルをベースモデルとしてファインチューニングします。
また、以下のKaggleのnotebookを参考にして、学習処理部分を実装しました。
以下では、その処理内容をざっくりと順を追って説明します。
データの分割
まず、scikit-learnのtrain_test_split関数を使って、集めた画像を用途ごとに分割します。
今回は、70%の画像を学習データ、15%の画像を評価データ、残りの15%をテスト用データとしてランダムに分割しました。
filepaths = [] labels = [] # `label_file_path`で指定したパスには、<画像ファイルのパス>,<ラベル> が列挙された # CSVファイルが置かれています。 with open(label_file_path) as f: reader = csv.reader(f) for row in reader: filepaths.append(row[0]) labels.append(row[1]) f_series = pd.Series(filepaths, name="filepaths") l_series = pd.Series(labels, name="labels") df = pd.concat([f_series, l_series], axis=1) train_df, tmp_df = train_test_split( df, train_size=0.7, shuffle=True, random_state=123, stratify=df["labels"] ) valid_df, test_df = train_test_split( tmp_df, train_size=0.5, shuffle=True, random_state=123, stratify=tmp_df["labels"], )
データの拡張
深層学習ライブラリであるKerasのImageDataGeneratorを使ってデータを拡張します。
gen = ImageDataGenerator(
horizontal_flip=True,
rotation_range=20,
width_shift_range=0.2,
height_shift_range=0.2,
zoom_range=0.2,
)
aug_img_count = 0
required = 100 # 作成する拡張画像の枚数
aug_gen = gen.flow_from_dataframe(
df,
x_col="filepaths",
y_col=None,
target_size=img_size,
class_mode=None,
batch_size=1,
shuffle=False,
save_to_dir=target_dir, # `target_dir`で指定したディレクトリに作成されます。
save_prefix="aug-",
color_mode="rgb",
save_format="jpg",
)
while aug_img_count < required:
images = next(aug_gen)
aug_img_count += len(images)
ベースモデルの読み込み
出力層付近を除いたモデルを読み込み(include_top=False)、2クラスの分類結果を出力するように置き換えます。今回はEfficientnet B3のモデルを利用しています。
base_model.trainable = Trueにするとファインチューニング、Falseにすると転移学習となります。
base_model = tf.keras.applications.efficientnet.EfficientNetB3(
include_top=False, weights="imagenet", input_shape=img_shape, pooling="max"
)
base_model.trainable = True
x = base_model.output
x = Dropout(rate=0.4, seed=1)(x)
output = Dense(class_count, activation="softmax")(x)
model = Model(inputs=base_model.input, outputs=output)
model.compile(
Adamax(learning_rate=lr), loss="categorical_crossentropy", metrics=["accuracy"]
)
学習の実行
引数に、学習用データ(train_gen)と検証用データ(valid_gen)を指定してmodel.fit()を実行すると学習がスタートします。
model.fit(
x=train_gen,
epochs=epochs,
verbose=1,
callbacks=callbacks,
validation_data=valid_gen,
validation_steps=None,
shuffle=False,
initial_epoch=0,
)
model.save(model_save_path)
コンソールの出力を見ていると、accuracyやval_accuracyの値が良くなっていくのが分かります。とりあえず、学習はうまく進んでいるようです。
Epoch 1/40 20/20 [==============================] - ETA: 0s - loss: 8.0606 - accuracy: 0.7800 validation loss of 9.0880 is 0.0000 % below lowest loss, saving weights from epoch 1 as best weights 20/20 [==============================] - 76s 3s/step - loss: 8.0606 - accuracy: 0.7800 - val_loss: 9.0880 - val_accuracy: 0.7000 Epoch 2/40 20/20 [==============================] - ETA: 0s - loss: 6.8788 - accuracy: 0.9050 validation loss of 7.7559 is 14.6582 % below lowest loss, saving weights from epoch 2 as best weights 20/20 [==============================] - 34s 2s/step - loss: 6.8788 - accuracy: 0.9050 - val_loss: 7.7559 - val_accuracy: 0.7000 Epoch 3/40 20/20 [==============================] - ETA: 0s - loss: 6.2107 - accuracy: 0.9225 validation loss of 6.1968 is 20.1025 % below lowest loss, saving weights from epoch 3 as best weights 20/20 [==============================] - 34s 2s/step - loss: 6.2107 - accuracy: 0.9225 - val_loss: 6.1968 - val_accuracy: 0.9167 Epoch 4/40 20/20 [==============================] - ETA: 0s - loss: 5.6444 - accuracy: 0.9350 validation loss of 5.6057 is 9.5382 % below lowest loss, saving weights from epoch 4 as best weights 20/20 [==============================] - 35s 2s/step - loss: 5.6444 - accuracy: 0.9350 - val_loss: 5.6057 - val_accuracy: 0.9500 Epoch 5/40 20/20 [==============================] - ETA: 0s - loss: 5.1150 - accuracy: 0.9500 validation loss of 4.9568 is 11.5753 % below lowest loss, saving weights from epoch 5 as best weights 20/20 [==============================] - 37s 2s/step - loss: 5.1150 - accuracy: 0.9500 - val_loss: 4.9568 - val_accuracy: 0.9833 Epoch 6/40 20/20 [==============================] - ETA: 0s - loss: 4.6689 - accuracy: 0.9675 validation loss of 4.5310 is 8.5913 % below lowest loss, saving weights from epoch 6 as best weights 20/20 [==============================] - 34s 2s/step - loss: 4.6689 - accuracy: 0.9675 - val_loss: 4.5310 - val_accuracy: 0.9833 Epoch 7/40 20/20 [==============================] - ETA: 0s - loss: 4.2913 - accuracy: 0.9900 validation loss of 4.2057 is 7.1782 % below lowest loss, saving weights from epoch 7 as best weights 20/20 [==============================] - 34s 2s/step - loss: 4.2913 - accuracy: 0.9900 - val_loss: 4.2057 - val_accuracy: 0.9500 Epoch 8/40 20/20 [==============================] - ETA: 0s - loss: 3.9923 - accuracy: 0.9750 validation loss of 3.9645 is 5.7369 % below lowest loss, saving weights from epoch 8 as best weights 20/20 [==============================] - 34s 2s/step - loss: 3.9923 - accuracy: 0.9750 - val_loss: 3.9645 - val_accuracy: 0.9500 Epoch 9/40 20/20 [==============================] - ETA: 0s - loss: 3.7193 - accuracy: 0.9725 validation loss of 3.6385 is 8.2214 % below lowest loss, saving weights from epoch 9 as best weights ...
推論処理の実行
テスト用のデータをmodel.predict()の引数に渡すことで推論を行うことができます。
推論の結果は、[0.00226656, 0.99773353] というように、その画像がそれぞれのクラスである確率のようなものを表しているため、数値が最も大きいクラスを分類結果として使います。
image_generator = ImageDataGenerator().flow_from_dataframe(
test_df,
x_col="filepaths",
y_col="labels",
target_size=image_size,
class_mode="categorical",
color_mode="rgb",
shuffle=False,
batch_size=batch_size,
)
results = []
predicts = model.predict(image_generator, verbose=1)
for i, p in enumerate(predicts):
file = image_generator.filenames[i]
label_index = image_generator.labels[i]
predicted_index = np.argmax(p)
results.append((file, predicted_index, label_index, p))
print(results)
精度の評価
最初に用意した15%のテスト用画像(61枚)に対して評価してみた結果が以下の通りです。
label precision recall f1-score support
0 1.0000 0.8571 0.9231 21
1 0.9302 1.0000 0.9639 40
さくっとやった割に簡単に精度が出て、かなり驚きました。
AIモデル作成は簡単ではなかった
しかし!
別途、別の人が用意したテスト用の画像に対して推論を実行して評価すると、precision 0.5, recall 0.8!!という残念な結果でした。ほとんどランダムで0, 1選択したのと変わらない!!
全くの未知の画像に対して精度を出すことの難しさがわかりました。。
おそらく私が集めた学習用データセット全体に対してかなり偏りがあるのではないかという考察をしているのですが、実際のアプリケーションとして使えるレベルにするにはもう少し試行錯誤が必要そうです。
精度を出すためにはもう少し勉強が必要そうですが、分類系の学習済みモデルの作成~推論処理の実装までを一通り経験することができました!
Safieのサービスを利用すると画像収集の部分はかなり楽なので、その点は大きなメリットがありそうです。が、まだまだ手間であることには変わりないので、ラベル付きのCSVのような形である程度まとまった単位で画像ダウンロードできるようになるとなお良さそうです。この辺りはフロントチームと連携して利便性を向上させていきたいと思います。
推論の精度を上げて、無事にアプリケーションが完成しましたらまたこの記事で結果を共有したいと思います!