Treasure Dataのhivemallで類似ユーザレコメンドを試す
メディアシステム開発部の野崎です。 メディアシステム開発部では、「auWebポータル」や「auスマートパス」といった、サービスを担当しています。
弊社では一部のサービスでアクセスログなどをTreasure Dataに貯めています。
今後はこのデータを分析活用し、より良いサービスを提供していきたいと考えています。
その一歩として、今回はTreasure Data内で使える機械学習ライブラリhivemallを利用してユーザレコメンドを試してみました。
はじめに
今回は、DACさんのブログを参考にさせていただきました。
「HivemallでMinhash!〜似てる記事を探し出そう。〜」
※ Treasure Dataのブログにも英訳されている、非常にわかりやすい記事です!
この参考記事をなぞる形ですが、サンプルデータではなく、実サービスのデータを入力とします。 あるサービスのユーザごとのジャンル別の閲覧数を入力とし、 あるユーザに閲覧傾向が似ているユーザをレコメンドしてみます。
Minhashとは
minhashは、乱択アルゴリズムと呼ばれます。 大量のユーザデータや文書データを比較したい場合に利用され、 類似しているユーザや文書を推定することができます。
ある2つの集合(ユーザや文章)の類似度は、 Jaccard係数で表すことができます。 Jaccard係数は、積集合を和集合で割った値で表されます。
参考記事にあるように、 2つの集合の要素にあるhash関数を適用しその結果のうち最小値が一致する確率と Jaccard係数は等しくなる性質があります。
この際に使うhash関数をk個用意すれば、 最小値が一致した個数をkで割ればJaccard係数を推定できる。 つまり、2つの集合の類似度を推定できるということになります。
利用する環境
今回利用した環境は以下の通りです。
- hive : 0.13.0 参考
- hivemall : 0.4.2-rc.4
利用する関数の確認
minhashを使います。
関数の定義は、
hivemallのユーザガイドを参考にしながら
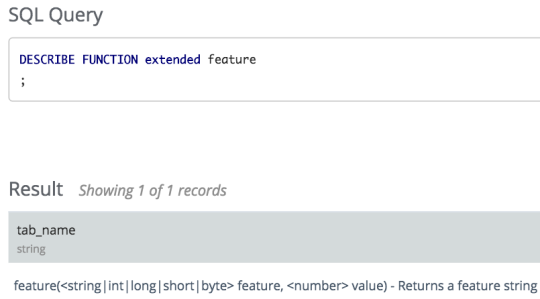
hiveのDESCRIBE FUNCTIONを使って確認するのがわかりやすいです。
(minhash)

第一引数に、item、第二引数に、featuresを取ります。
また、オプションとしてnを取ります。
今回は、itemをuser_idとします。
返り値として、一つのuser_idに対して、n個のhash値が出力されます。
次に、featuresを用意します。
入力データの用意
ユーザガイドのinputページを参考にします。
featuresは、特徴量ベクトルで、indexのみ、またはindexとweightをセットで表します。 hivemallでは、これらをダブルクオーテーションで括った形式で表します。
上記のfeature関数を使います。
とあるサービスの、
user_idに対し、ジャンルごとの閲覧数を合計した
テーブルuserid_by_genreがあるので、それを元にします。
| user_id | genre_id_1 | genre_id_2 | genre_id_3 |
|---|---|---|---|
| 1 | 0 | 2 | 10 |
| 2 | 1 | 4 | 12 |
| 3 | 0 | 8 | 1 |
| 4 | 10 | 4 | 0 |
| 5 | 9 | 7 | 12 |
※記載してあるデータはサンプルです。
このテーブルに対して、 以下のようなクエリでfeature関数を適応します。
(type:hive)
SELECT
user_id AS user_id,
ARRAY(FEATURE(1,
genre_id_1),
FEATURE(2,
genre_id_2),
FEATURE(3,
genre_id_3)) AS feature
FROM
userid_by_genre
以下のような、 user_idとfeatureのデータができます。

これを、別テーブルuser_featureに書き出しておきます。
hashの作成
このテーブルに対して、minhash関数を適応していきます。 n=10とし、一つのuser_idに対して、10個のhash値を生成します。
(type:hive)
SELECT
minhash(
user_id,
feature,
"-n 10"
) AS(
clusterId,
rowid
)
FROM
user_feature
以下のような、hash値が生成されます。
この結果を、別テーブルuser_hashに書き出しておきます。

類似ユーザの集計
テーブルuser_hashの
異なるuser_idからhash値がある個数一致するuser_idを集計します。
今回は、9個以上のものを対象とします。hash関数は10種類あるのでJaccard係数が0.9以上のものとなります。
SELECT
J.Rowid,
Collect_set(rid) AS Related_userid
FROM (
SELECT
L.Rowid,
R.Rowid AS rid,
COUNT(*) AS cnt -- minhashが一致する数
FROM
user_hash l LEFT OUTER
JOIN
user_hash r
ON (
L.Clusterid = R.Clusterid
) -- minhashの値が一致するレコードのみをjoin
WHERE
L.Rowid != R.Rowid --同じuser_idは除外
GROUP BY
l.rowid,
r.rowid
HAVING
cnt > 8 -- Jaccard係数が0.8以下のものは除外
) J
GROUP BY
J.Rowid
ORDER BY
J.Rowid ASC
ここでは、実データはお見せできませんが、 以下のような形式の結果が得られます。 user_id:1に対して、user_id:2,4,5のユーザの閲覧が似ていることになります。
| user_id | Related_userid |
|---|---|
| 1 | [2,4,5] |
| 3 | [7,8] |
| 4 | [10,11] |
この評価に関しても、本記事では詳細を扱いませんが ほぼ同様の閲覧傾向にあるユーザをレコメンドすることができました。
まとめ
参考記事をなぞる形になりましたが、実際のサービスのデータを用いて Treasure Dataのhivamallを用いて、ユーザのレコメンドを試してみました。
どのようなデータを特徴量とするかどうやって特徴量を作るかあたりが戸惑いましたが、 Treasure Data上に生データやhivemallの実行環境が用意されていることで、手軽に試すことができました。
メディアシステム開発部では、Treasure Dataなどを利用してサービスに貢献できるエンジニアを募集しています。 ご興味ある方は、募集職種一覧などをご確認ください。
