
本記事はCyberAgent Advent Calendar 2022 18日目の記事です。
AI事業本部の久米(@kume_ru)です。
5月頃から分散データベース / NewSQLであるCloud Spannerに初めて触れ始め、半年ほど設計・実装を行っているところです。
普段MySQLやPostgreSQLなどのRDBMSを使用している自分が、特に特徴的だと思ったSpannerの仕様を3点、
- インターリーブと呼ばれる親子関係
- STRUCTと呼ばれるオブジェクトとその操作
- インデックスの考え方
紹介します。
インターリーブ・STRUCTは重点的に触れ、インデックスについては過去の登壇資料を参照して補足的に触れます。
Cloud Spannerとは
Cloud Spanner(以下Spanner)はGoogle Cloudが提供するデータベースであり、フルマネージドのRDBMS・高いスケーラビリティ・高可用性といった特徴を持ちます。
インターフェースはSQLですが、内部的にはKVSで構成されているため、純粋なRDBMSとは少し使い勝手が異なります。
SQLはGoogle 標準 SQLに加え、PostgreSQLが6月にGAしています。
Google 標準 SQLはBigQueryでも使われているので、馴染みのある方もいると思います。
本記事では全てGoogle 標準 SQLで書かれています。
基本的にRDBMSと同じようにテーブル設計・クエリ操作ができますが、分散データベースであるが故にテーブルやインデックスの設計でホットスポット問題を考慮する必要があったり、STRUCTを含めたSpannerに適したSQLの書き方があったりします。
設計・実装には様々なSpannerの知識が必要ですが、より良いパフォーマンスが出せるよう日々試行錯誤しながら楽しんでいます。
インターリーブとは
RDBMSで親子関係を定義する際は外部キーを使いますが、Spannerではインターリーブと呼ばれる2つ目の定義方法があります。
インターリーブは頻繁にJOINを行うテーブル同士に適しており、親子のデータを物理的に連続して格納することで、子テーブルの取得を高速に行うことができます。
例えば「外部キー」で親子関係を持つ以下のテーブルを定義します。
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
FirstName STRING(1024),
LastName STRING(1024),
SingerInfo BYTES(MAX),
) PRIMARY KEY (SingerId);
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
FOREIGN KEY (SingerId) REFERENCES Singers (SingerId)
) PRIMARY KEY (SingerId, AlbumId);
それぞれのテーブルにデータを登録すると、下図のような順番で書き込まれます。
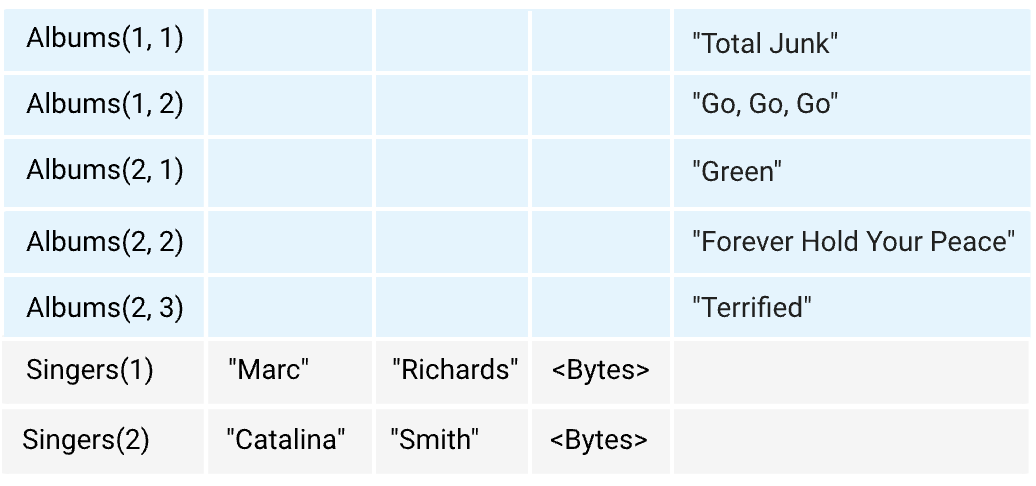
Spannerはデフォルトで主キーを昇順(設定すれば降順)にソートして保存します。
ソート順が近いAlbums同士やSingers同士は近い位置に書き込まれますが、異なるテーブル、特にSingers(1)とそれを親に持つAlbums(1, 1)・Albums(1, 2)などは全く違う場所に書き込まれます。
一方で「インターリーブ」で親子関係を持つ以下のテーブルを定義します。
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
FirstName STRING(1024),
LastName STRING(1024),
SingerInfo BYTES(MAX),
) PRIMARY KEY (SingerId);
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
) PRIMARY KEY (SingerId, AlbumId),
INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
インターリーブは子テーブルの主キーの先頭に親テーブルの主キーをそのまま設定する(今回であればSingerIdをAlbumsの1番目の主キーにする)ことに加え、テーブル定義の最後に
INTERLEAVE IN PARENT {PARENT_TABLE_NAME}
と宣言することで設定できます。
インターリーブの場合は親デーブルの主キーを子テーブルの主キーに使用するため、主キーがどのテーブルのものかわかるように命名するのが良いです。
仮にSingersだけに注目してSingerIdの代わりにIdと命名していると、AlbumsのカラムがId, AlbumId, AlbumTitleとなり、AlbumsではIdが何者かわかりにくい状況となってしまいます。
それぞれのテーブルにデータを登録すると、下図のような順番で書き込まれます。
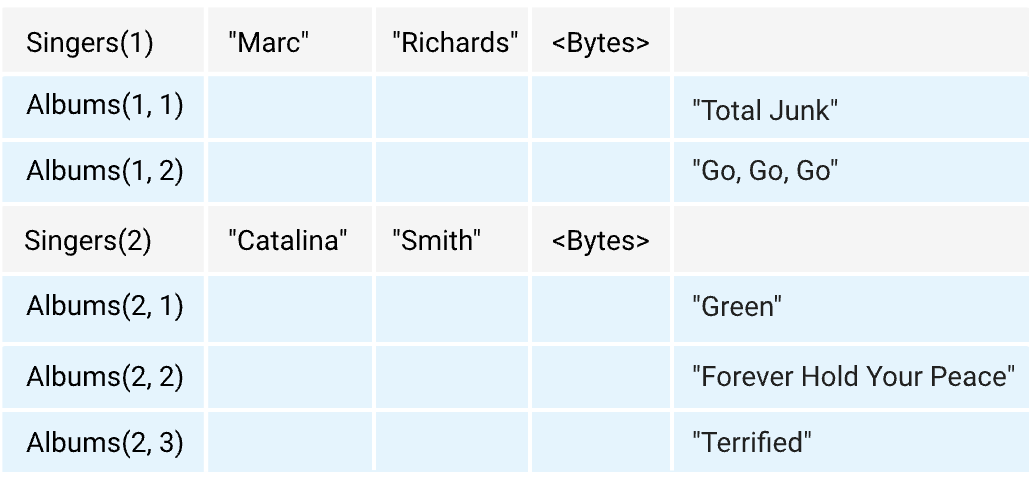
ある親のデータの間に子のデータが割り込んで保存されます。
このような順番で保存されているとき、親のデータが指定されれば子のデータは直後に存在するため、子のデータを探しに行く必要がなく、高速にJOINが行われます。
STRUCTとは
SELECT AS STRUCT ...
という書式で作成できます。
ただしSTRUCTは最終的なクエリ結果としては出力できないため、ARRAYで囲ってあげる必要があり、
ARRAY(SELECT AS STRUCT ...)
というような形式で使うことが多いです。
例えば先程のCustomersテーブルに対して
SELECT ARRAY(SELECT AS STRUCT * FROM Customers LIMIT 2);
というクエリを実行すると、以下の結果が得られます。
Customer [[CustomerID1, FirstName1, LastName1], [CustomerID2, FirstName2, LastName2]]
要は、SELECTで指定したカラムすべてを含んだオブジェクトが作成され、さらにそれをARRAYとして「1レコード」で取り出すことができます。
以下のようなJSONが「1レコード」に入っている感じです。
{
[
{
"CustomerID": "CustomerID1",
"FirstName": "FirstName1",
"LastName": "LastName1"
},
{
"CustomerID": "CustomerID2",
"FirstName": "FirstName2",
"LastName": "LastName2"
}
]
}
これの何が嬉しいかというと、1:多の親子関係があるとき、普通にJOINすると子の数だけ行が生成されますが、 STRUCTのARRAYを使用すると親の数になります。
具体的な使用例として、少し複雑なクエリになりますが、
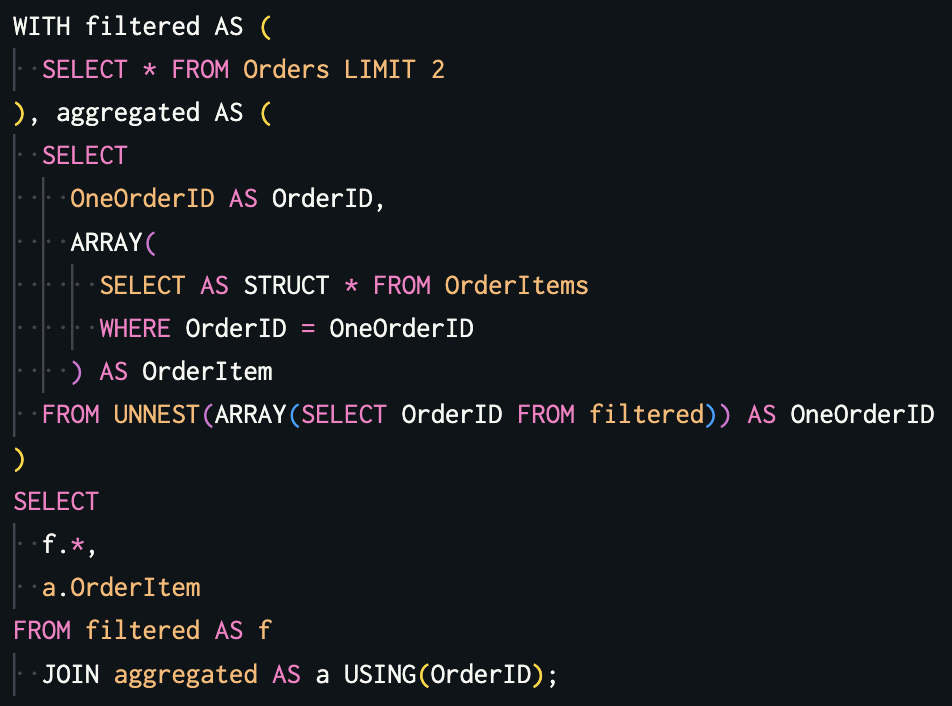
を実行すると、次のような結果が得られます。
OrderID, CustomerID, OrderItem OrderID1, CustomerID1, [[OrderID1,ProductID11,1], [OrderID1, ProductID12,1]] OrderID2, CustomerID2, [[OrderID2,ProductID21,1], [OrderID2, ProductID22,2]]
いまサンプルデータではOrder : OrderItem = 1 : 2となっています。
普通にJOINした結果では2 x 2 = 4行取得されますが、STRUCTを使うことで1 x 2 = 2行で集約された形で取得できます。
特にインターリーブではこのようにSTRUCTのサブクエリを使った方法のほうが、普通にJOINするよりもハイパフォーマンスであることがこちらの記事で検証されています。
また、同じ記事でも書かれていますが、SpannerのSTRUCTはgoのstructと相性が良いです。
Spannerのクエリ結果をアプリケーションで使いたい場合、以下のようにするとgoのstructへのマッピング処理を簡単に行うことができます。
type OrderWithItem struct {
OrderId string
CustomerId string
OrderItems []*OrderItem
}
type OrderItem struct {
OrderId string
ProductId string
Quantity int64
}
// rowはクエリ結果の一行単位のデータです
func rowToStruct(row *spanner.Row) (OrderWithItem, error) {
var orderWithItem OrderWithItem
err := row.ToStruct(&singer)
return orderWithItem, err
}
STRUCTは制約も多くとっつきにくい側面もありますが、ハイパフォーマンスに効率良く使える場面も多いかと思います。
インデックスの考え方
MySQLやPostgreSQLではB-treeインデックスが採用されていますが、Spannerでは他のKVSでもあるようにインデックス用の別テーブルを作成します。
例えばOrdersテーブルでCustomerIdに対してインデックスを貼る場合、
CREATE INDEX OrdersCustomerIdIdx ON Orders (customerId);
のような形で作成でき、この結果、以下のようなテーブルが内部で作成されます(実際にこちらのDDLが実行されるわけではありません、あくまでイメージです)。
CREATE TABLE OrdersCustomerIdIdx ( CustomerID STRING(36) NOT NULL, ) PRIMARY KEY (CustomerID);
SpannerではPRIMARY KEYによるホットスポット問題を考慮してテーブル設計を行う必要がありますが、インデックスを作る場合もインデックスに指定したキーがPRIMARY KEYのようになるため考慮する必要があります。
インデックスは検索やソート、ページネーションといったアプリケーションの機能に関連して使用されることもあります。
こちらの過去の登壇資料でページネーションとインデックスについて説明しているので、本記事では深く触れないこととします。
まとめ
Spannerのインターリーブ・STRUCT・インデックスについて紹介しました。
純粋なRDBMSとは異なる仕様や懸念等が様々あり使いのこなすのは難しいですが、かなりのハイパフォーマンスを出せるデータベースです。
また、Spanner以外にも様々なNewSQLがあります。
手軽に触れる環境があるものも多いので、皆さんぜひこの機会にNewSQLを触ってみてください。