GraphQL 採用における反省と Apollo Server の運用について
こんにちは。武田(@tkdn)です。
GraphQL を API として採用したサービスを今年序盤にリリースしています。具体的な内容は今年の夏サミ 2020 の公募枠でお話させていただいたのでよろしければ資料もご参考ください。
今日は GraphQL や Apollo Server についての振り返りと反省を中心に供養しておきます。GraphQL 採用に迷いがある開発者、Apollo Server を採用しようとしている開発者へ向けた知見になれば幸いです。
まとめてみたら GraphQL みが思いの外少なくなりましたが、GraphQL Advent Calendar 2020 の 23 日目の記事です。
なぜ GraphQL を採用したか、リリース後どうだったか
最近話題になっていた Netflix の技術記事で組織内の API アーキテクチャの変遷に名称を与えていました。記事にあるような Federated Gateway といったドメイン単位のグラフサービス群をいくつも持つ巨大化した構造では当然なく、我々の API は本当にミニマムな構成です。
我々の API は KDDI の認証システムや同 VPC 内で別サービスとして切り出したポイント参照・付与 API 通信をブリッジする役割を備えながら、Web フロントエンドでの利活用を目的とした、いわゆる Aggregated Gateway/BFF な立ち位置の GraphQL API です。
新規サービスとしてリリース後にどう転んでいくか、不確実なプロダクトの将来のために以下 2 つのことを考え GraphQL を採用しました。
- 価値検証のための変更をフロントエンドでハンドルしやすくする
- プロダクトの伸長を考慮し API 自身の変更容易性を持たせる
これらの採用理由に妥当性があったのかを考え供養していきます。
1. 価値検証のための変更をフロントエンドでハンドルしやすくする

新規サービスは当初から価値検証のためフロントエンドのコード変更が多く見込まれていました。そのため UI に必要とされる情報に追加があるたびにスキーマを変更したり、API の開発が多く発生したりするとそれだけリリースのリードタイムは長くなってしまいます。自由なクエリによるレスポンスバリエーションを最大限に活かせるよう、クライアントからリクエストするクエリが多く変更されることを見越していました。
ただ残念ながらリリース後クライアントからリクエストされるクエリはほとんど変更されていません。 今後変更が求められることを望んでやみませんが、ある程度ユースケースが固まった状態からクエリが変更されるというようなことは我々の場合は頻繁に起こるものではなかったということでしょう。リリース後生じる変更のホットスポット見極めは今後の課題となりそうです。
2. プロダクトの伸長を考慮し API 自身の変更容易性を持たせる

今年は2020年5月に au のポイントは Ponta ポイントと統合される、ということもありました。ポイントを扱うサービスにとっては変更もやむなしでスピード感が求められたり、ステークホルダーのニーズに答えるべく当初予定していなかった機能変更などが発生したり、クライアントからのクエリの変更こそありませんでしたが、API のコードは比較的多く変更されています。
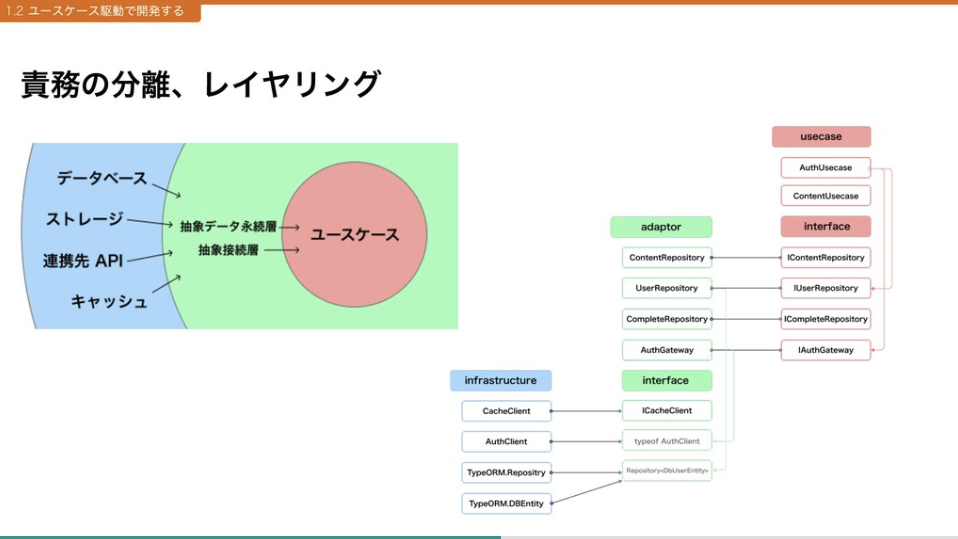
DIP にのっとり責務を分割しレイヤ化したアーキテクチャを採用したおかげで、リリース時点でカバレッジ 90 を超えるテストコードを配置できています(カバレッジが高いからすばらしいというわけではありません)。網羅されたユニットテストはコードを触るうえでの安心感が違いますし、変更における影響範囲について不安がないというのはやはり開発者にとって重要だと感じます。ただレイヤが多重なので変更によっては触るコード範囲が大きいという苦言もなくはないです。
また同期をとるためのモブプロはコロナ禍になった状況でも行い、コミュニケーションにズレのないワークフローとチームのおかげで、認識齟齬を圧倒的に減らすことができています。API の変更容易性を担保したコードベースとチーム力がプロダクトを支えているひとつの柱と言えそうです。
Apollo Server 運用におけるあれこれ
GraphQL 採用理由と振り返りについて書きましたが、以下は採用した Apollo Server の性能からロギング、運用においてできていることやできていないことを中心に書いていきます。
Apollo Server の性能
我々のアプリケーションで利用している範囲ではほとんど性能の問題はありません。
弊社では負荷試験で以前から Gatling という Scala 製のストレスツールを利用しています。リリース前の局面以外では Go 製の Vegeta を利用することもありましたし、自身も試しに Node 製の autocannon や周辺の診断ツールを使ってみたこともあります。選択肢として Gatling に軍配が上がるのは、試験で生成されたレポーティング HTML(下記画像は今回のもの)が見やすいという点や時間経過によりリクエスト数を増やしていける点などです。
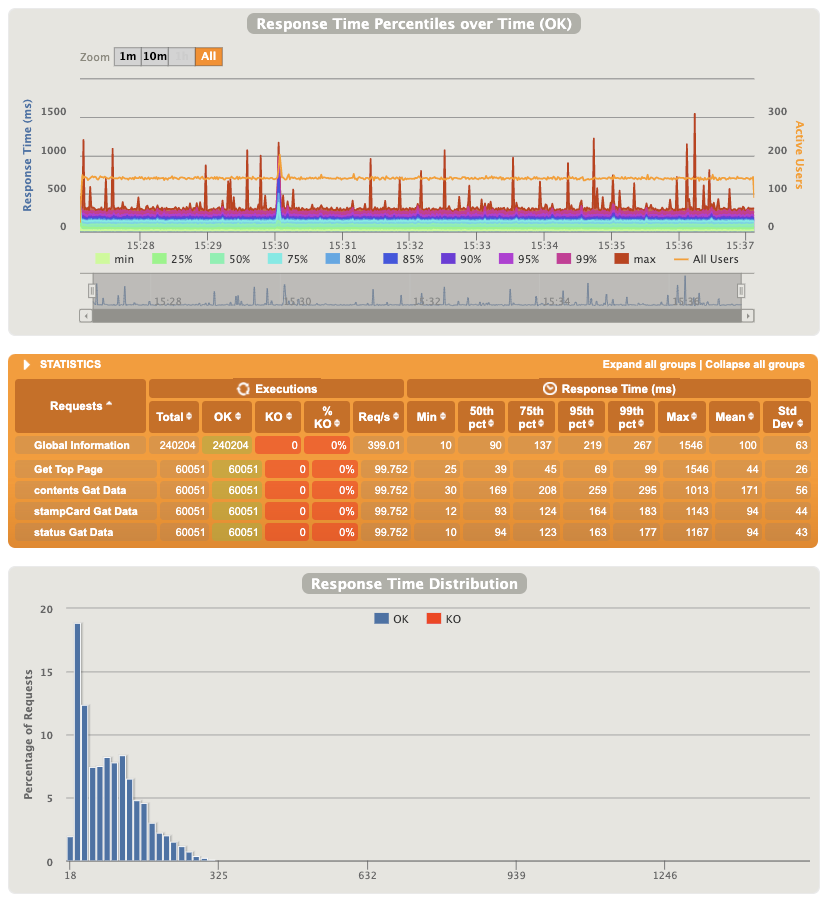
今回は以下の条件でリクエストを処理できており、CPU/メモリなどのサーバリソースにも何ら問題はありませんでした。
| 項目 | 詳細 |
|---|---|
| Node.js | v12 |
| API | Apollo Server v2.9 |
| CPU コア | 2 |
| クラスタ内コンテナ数 | 2 |
| リクエスト | 100 req/sec * 600 秒 |
かなり控えめなリクエスト数で安心しきっているな? とお思いかもしれません。 ですが、新規サービスとして需要予測が控えめだったことに加えて、2018 年に弊社で初めて Node.js でフロントサーバと API サーバをプロダクションで利用した際、CDN を挟まない状況で負荷試験の惨憺たる結果に愕然とした記憶から今回肩透かしのような安堵を得ています。
当時と今を比較し Node.js が依存するエンジン V8 の性能向上やライブラリのバージョン差異による考察を深く行っていないので以下の条件を鵜呑みにはしないでほしいのですが、当時の苦い負荷試験での条件は下記になっています。
| 項目 | 詳細 |
|---|---|
| Node.js | v8 |
| SSR | Next.js v6 |
| API | graphql-yoga(リリース当時は Apollo Server v1 に依存) |
| CPU コア | 2 |
| クラスタ内コンテナ数 | 8 |
| リクエスト | 100 req/sec * 600 秒 |
当時は知見が少なかったこともありますが、この条件下で実施された負荷試験では 30 req/sec も処理できませんでした。当時試験を担当した開発者は「コンテナがいくつ必要なんだ…」「今から作り変えるか…」など不安を募らせながら改善していったという経緯があります。今なら改善のアプローチや選択肢が思いつきそうですが、どこから手をつければよいやらと頭を抱えてしまっていたのは事実です。
こういった苦い結果を見ているからか今回の試験結果の良好さを信じきれず、安全をとってリリース直後はコンテナ 8 つで稼働させていましたが、コスト削減のためすぐコンテナ 2 つの稼働に切り替えました。この状態で 1 年近く安定して稼働しており、対向先システムへの疎通失敗に見舞われアラートが上がる以外は何の問題もありません。
アラートはコンテナで動作するアプリケーションのログを Datadog へパイプしモニタリング・検出して発報するのですが、Apollo Server ではログをどうしているかについての失敗、振り返りを以降で書いていきます。
ログとエラートラッキング
Apollo Server はコンテナで稼働させているのは前述通りですが、FireLens を利用したログルーティングにより S3 保管と Datadog へ出力しています。アプリケーションからは LTSV のログフォーマットで標準出力させており、この部分についての成功・失敗について触れていきます。
ログ出力機構の配置失敗
Apollo Server 導入に際して必ず公式ドキュメントを読んだうえでプラクティスを実践し自分たちのプロダクトに合うようカスタマイズさせていったのですが、ロギングに関してはあまりうまくいかなかったことのひとつです。
今でこそしっかりロギングの項目が公式ドキュメントに設けられていますが、リリース前にはこのドキュメントがなく我々のリリース直前である、2020 年 1 月中旬に追加されています。
公式のロギングのプラクティスによれば、リクエストライフサイクルにフックできるプラガブルな機構があるので、そこに適切な出力を仕込めば 1 リクエストに対してコンテキストをかき集めながらログを出力することが可能そうです。
const loggerPlugin: ApolloServerPlugin = {
requestDidStart(requestContext: GraphQLRequestContext) {
console.log(`クエリ:${requestContext.request.query}`)
return {
// resolver オペレーション終えた
didResolveOperation(_requestContext){/** ... */}
// エラーが起こった
didEncounterErrors(_requestContext){/** ... */}
// 他にもバリデーションやクエリのパース処理にフックさせることが可能
}
}
}
const server = new ApolloServer({
typeDefs,
resolvers,
plugins: [ loggerPlugin ]
})
設計・実装当時は公式ドキュメントにロギングについての記載がなかったとはいえ、我々の調査不足やフレームワークのコードリーディング不足もあり、現状 resolver 毎にログを出力する構成になっています。
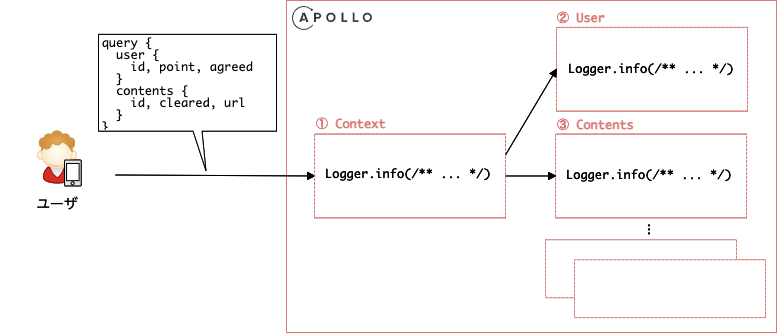
上記の図のようにリクエストは ① 一度 Apollo のコンテキストを通ってリクエスト受信のログ出力を行います。さらにクエリのバリエーションにもよりますが、上記ですと ② User resolver での正常終了をログに出力するだけでなく、③ Contents resolver でもログを出力します。そのため複数ユーザーのリクエストによって出力順は担保されず多段的になるため、一意のリクエストに対して ① ② ③ を束ねるということが難しいため、調査の際の懸念が生じました。いまのところトラブルシュートにおいて問題ありませんが、今後の改善を考慮したいところです。Apollo でロギングを検討される方はぜひ公式ドキュメントどおり plugins を使ってみてください。
ここでは正常リクエストのロギングを取り上げましたが、例外が発生した場合はログだけでなく Sentry にエラーイベントを送信しています。例外発生時、ロギング・Sentry への送信・クライアントにエラー返却をどのように設計・実装しているか、次で説明します。
例外捕捉時のエラーイベントとロギング
Apollo では例外が発生した場合、フレームワーク側がよしなに処理しクライアントにエラーのレスポンスを返却します。
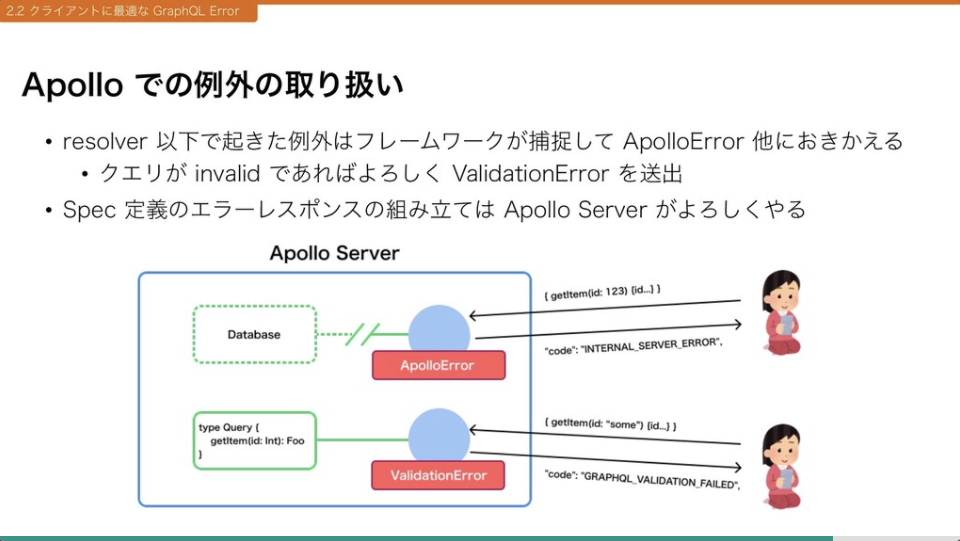
我々のユースケースでは Apollo で例外をつかませる前にリクエスト情報の一部(ヘッダからセッション ID やログのためのメタ情報など)を例外へ取り付け throw するハンドラが resolver に実装されれば大方事足りそうでした。下記のソースコードではコンテキストを引数に受ける exceptionHandler といった例外用の関数です。
// 粗雑な resolver 実装例
export const foo: QueryResolvers["foo"] = async (
_root: unknown,
_args: unknown,
context: ApolloContext,
) => {
/**
* いろいろ割愛
*/
const userFoo = await fooUsecase
.getUserFoo(context.timestamp, context.user)
// exceptionHandler がコンテキストをまぶして例外を送出する
// ⇢ Apollo Server が捕まえてエラーレスポンスを作成する
.catch(exceptionHandler(context));
return userFoo;
};
exceptionHandler での例外送出で Apollo がよしなにエラーレスポンスを返してくれますが、エラー種別によってクライアントでメッセージを変更したり API のスタックトレースを渡さないようにしたり、レスポンスの加工が必要になります。Apollo では formatError オプションが需要を満たしてくれそうです。
設置した formatError 関数は、クライアントに返却するエラーレスポンスを加工しフレームワークがよしなにやる部分を書き換え、Sentry にエラーイベントを送ることも兼ねました。1:Error レベル以上のログ出力、2:Sentry 送信、3:クライアントにエラーを返すという手順の中でエラーオブジェクトを下記のように加工します。
| 処理わけ | 1.Error レベル以上のログを出力する | 2.Sentry にエラーイベントを送る | 3.GraphQLError を返す |
|---|---|---|---|
| スタックトレースは… | 含める | 含める | 含めない |
| 接続先のエンドポイントは… | マスクしない | マスクしない | マスクする |
| エラーコードの置き換えを… | する | する | する |
| ほかログの可読性を高めるための加工を… | いろいろ | やって | こねこねする |
クライアントにエラー時のスタックトレースを渡したくないため、最終的に 3 の手前で GraphQLError から省きます。debug オプションを false にしてスタックトレースをそもそも入れないという選択肢ももちろんあります。
またエラー発生時に特定の接続先のエンドポイントがクライアントへむき出しになっては困ります。 AWS のリソースもそうですが、対 KDDI との接続先ももちろんそうです。そのため文字列のマスク加工を 3 の手前で処理しています。便利なオプションはないので利用用途に応じて実装する必要はあるでしょう。
フロントエンドにおけるユーザーケアのために実施しているエラーコードの書き換えは夏サミでもお話したとおりで、GRAPHQL_VALIDATION_FAILED、INTERNAL_SERVER_ERROR といった Apollo がもつ既存のエラーコードも自前のものに置き換えるなどしています。
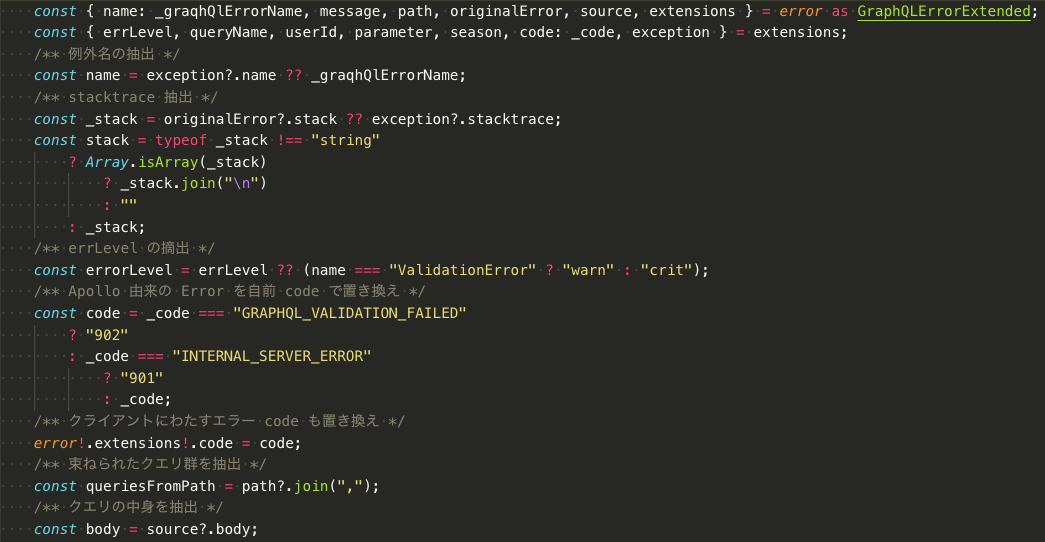
で、結局置き換えや適切なエラーレスポンスへの整形やマスクをかけたら、上記のように一番コードベースで読みづらく割としんどい箇所になりました。しんどくはありますが、この formatError によって例外発生時のレスポンス整形や差し迫った対応に必要なログ出力から Datadog でのエラー検知を行い、Sentry へのイベント送信し Slack へ通知し、デプロイ時や稼働中のトラブルを検知できています。
Renovate と週次アップデート
Apollo とはあまり関係ない話ですが、チームでは Renovate によるパッケージのアップデートを週次で行い毎週リリースに含めています。
- 人間がアップデートするのではなく自動化されたしくみ(Renovate)
- Renovate による PR をチームが判断しマージできる
- パッケージアップデートによるリリースが毎週行うという合意形成ができる
自動化や利便性から Renovate を導入しても 2, 3 が欠如していてはワークしません。2 では暗黙知の一般化とモブプロでの PR マージを、3 ではチームでの合意・協調を進める必要があります。自動化だけが目的ではなく、健全性を保ち腐らないコードベースでリリースし続ける、までチームが合意できてこそと考えます。
ほころびは割れ窓から生まれる
ただし定期的なアップデートもしかるべき手段で検証できていないと危険だなということも運用して半年くらいで経験しました。
とある日の Renovate PR はグリーンな状態だったので通常通りチームは PR をマージし検証のためステージング環境にデプロイしていました。運用してしばらく経っていたのでデプロイやコンテナの代替わりによる入れ替え、ログの注視はそこまで見なくなっていました。デプロイ後しばらくしてからブラウザで画面を確認すると、クライアントアプリケーションの画面は正常に見れている ようだったので品質管理部門に正常性の確認を依頼して検証が正常に終わればリリースされる予定でした。
ただステージングの Datadog ⇢ Slack のアラート通知に見慣れないログが出ており、調査すると API サーバが正常に起動していなかったことがわかりました。よくよく調べると ECS で最初に起動したタスク定義(Renovate PR マージ後のイメージ)では正常起動できず、サーバリソースの異常により以前のタスク定義(正常起動した 1 世代前のタスク)に戻ったため画面は正常に見れていたのです。
前提としてアプリケーションは Yarn Workspace を利用した monorepo で管理し、API は依存をすべてバンドルしているのですが、直接的な原因はすぐわかりました。Error: Cannot find module 'node-fetch' といったログとスタックトレースからバンドルされたファイルの以下の箇所に問題があったようです。

基本的にすべてバンドル想定なので上記のような CommonJS require で外部モジュールを読み出すことはないはずです。問題は何だったのでしょうか。
Renovate によりアップデートされた node-fetch に依存の中でバージョン差異が生まれたため 、monorepo ルートの下層パッケージにある api/node_modules/node-fetch へインストールしていました。
これだけなら問題ないはずですが、webpack.config 内の webpack-node-externals の設定にもともとミスがあり、バンドルされるパッケージ内の依存(今回生まれた api/node_modules/node-fetch)をバンドルしないという問題が発生していたのです。
技術的にいたらない部分があったことも悔しいですが、アラートの通知が Slack に流れていたにもかかわらずすぐ気付けなかったことでさらに悔しさが増します。
間接的な要因も考えると、まず Slack におけるステージング環境のアラート検知を放置していたのはよくありません。当時を思い返すともっと良くない部分もあり、ステージング環境の Slack アラート通知は頻繁でそれが当然ということが常態化していたため、重要な通知が埋もれていたのは完全に割れ窓が放置されたといってよいでしょう。
プロダクション環境のオンコールや検知に敏感なチームメンバーが多いことは救いで、実稼働のプロダクション環境については心配をしていませんが、ステージング環境であろうとこういった割れ窓を放置するのはよくありませんね。
まとめ
前半では GraphQL を採用してどうだったか、反省点はなんだったかについて触れてきました。技術的な取り組みとしてやはりフロントエンドフレンドリーなので楽しいという反面、不確実なプロダクト成長に対してはフロントエンドで GraphQL のメリットを存分に享受できたかという点ではマイナス、API の変更容易性やアーキテクチャとしてはまずまずといった感じです。
ロギングやエラートラッキングについてはこれまでチームや組織が培ってきた知見が大きいですが、一部 Apollo Server の具体的なオプションや実装について触れました。Apollo は公式ドキュメントが充実しているので、まずはカタどおりに組み込んでから考えてみるのをお勧めします。またエラーレスポンスには秘匿情報が入らないよう留意するポイントなども書きました。
最後は GraphQL や Apollo から大きく離れましたが、定期的なパッケージアップデートと運用についての反省を書きました。アップデートを順次リリースし続けること、割れ窓を放置しないことについて触れたつもりです。
類似したプロダクトをもう 1 つ最近リリースしてまして、反省や振り返りはまだまだ多いです。クライアントサイドでのローディング UI への取り組みを誤り CLS スコアが落ちたり Context API か Props かの選択で方針が混在したり、Jest を使ったコンポーネントテストのプラクティスなど失敗を含んだ反省文はいくらでも書けそうですが、本日は以上にしておきます。
今月不惑の年に突入した武田(@tkdn)が書きました。
