TL;DR
背景
こんにちは。CADDi AI Lab MLOpsチームの中村遵介です。普段は機械学習エンジニアチームの作るモデルをVertex Endpointsを使用してAPIとして提供したり、パイプラインに組み込んで推論結果をデータ提供したりするお仕事をしています。モデルは様々な種類がありますが、一番多いのは図面画像から特定の値を推論したり、何らかのクラスに分類するようなモデルです。
そのような中で「API提供するとサーバ代かかるし、ユーザにAPI使ってもらうのもちょっと手間があるしなぁ」と考えることがあり、ふと「Chrome extensionでMLモデルを提供しちゃえば、ユーザはextensionを入れるだけでモデルを使えるようになるし、実行コストもユーザのローカル環境にお任せできるしでWin-Winでは?」と思ったので実際にやってみました。
ユーザ体験設計
Chrome extensionは非常に強力で、様々な体験を作ることができます。今回はお試しとして以下のように設計しました。
- 提供するモデルは、図面画像に書かれている物体の最大寸法値を推論するもの※1
- 社内で使用している図面画像管理Webサービスに対してChrome extensionを提供する
- 図面画像管理Webサービス上に出てくる図面を右クリックすると、「AIで推論する」のようなメニューが出てくる
- 「AIで推論する」というメニューを選択すると、その場で対象の画像に対してMLモデルで最大寸法値を推論する
- 推論した最大寸法値は、ブラウザのコンソールに出力する
技術検証の段階なので、提供するMLモデルが1つだけだったり、推論の出力先がブラウザコンソールだったりします。
こちらが実際にできたものの動画です。動画内のWebサービスが社内向け図面管理サービスで、対象図面は社内サンプル図面です
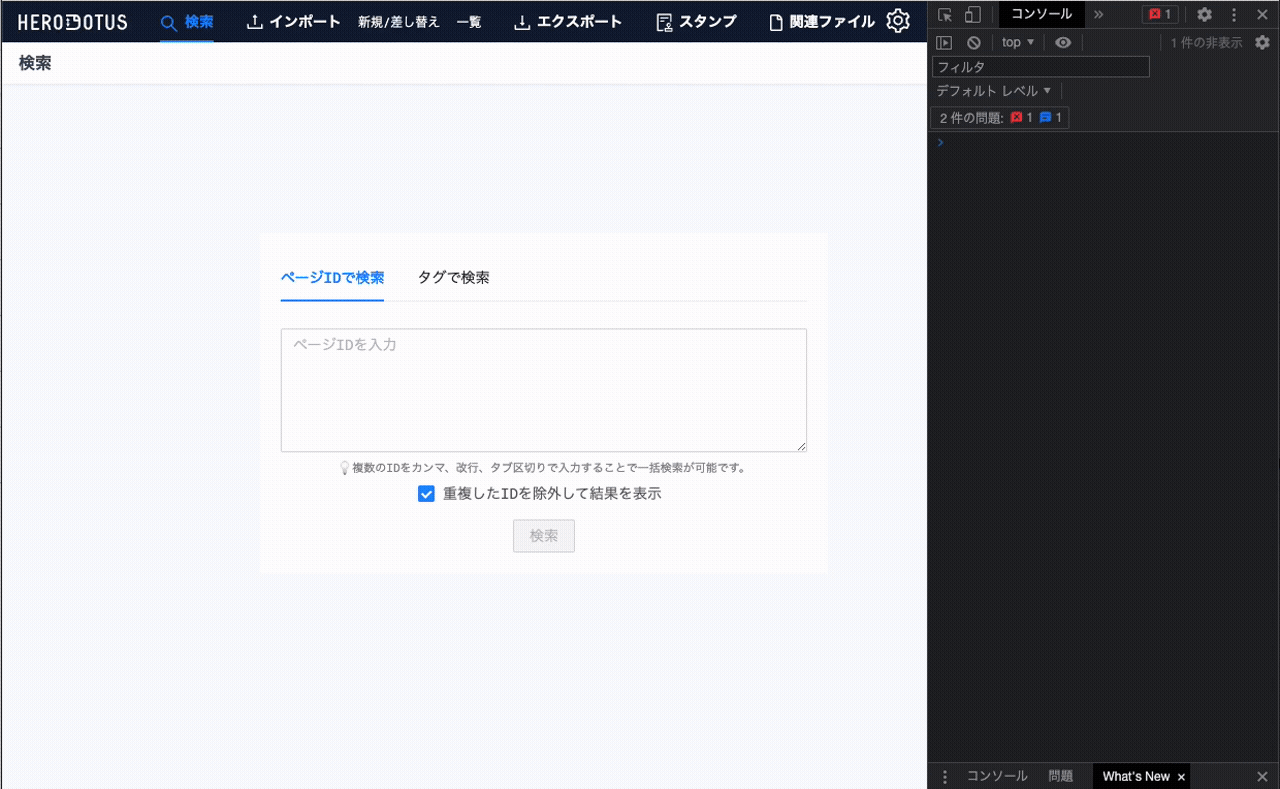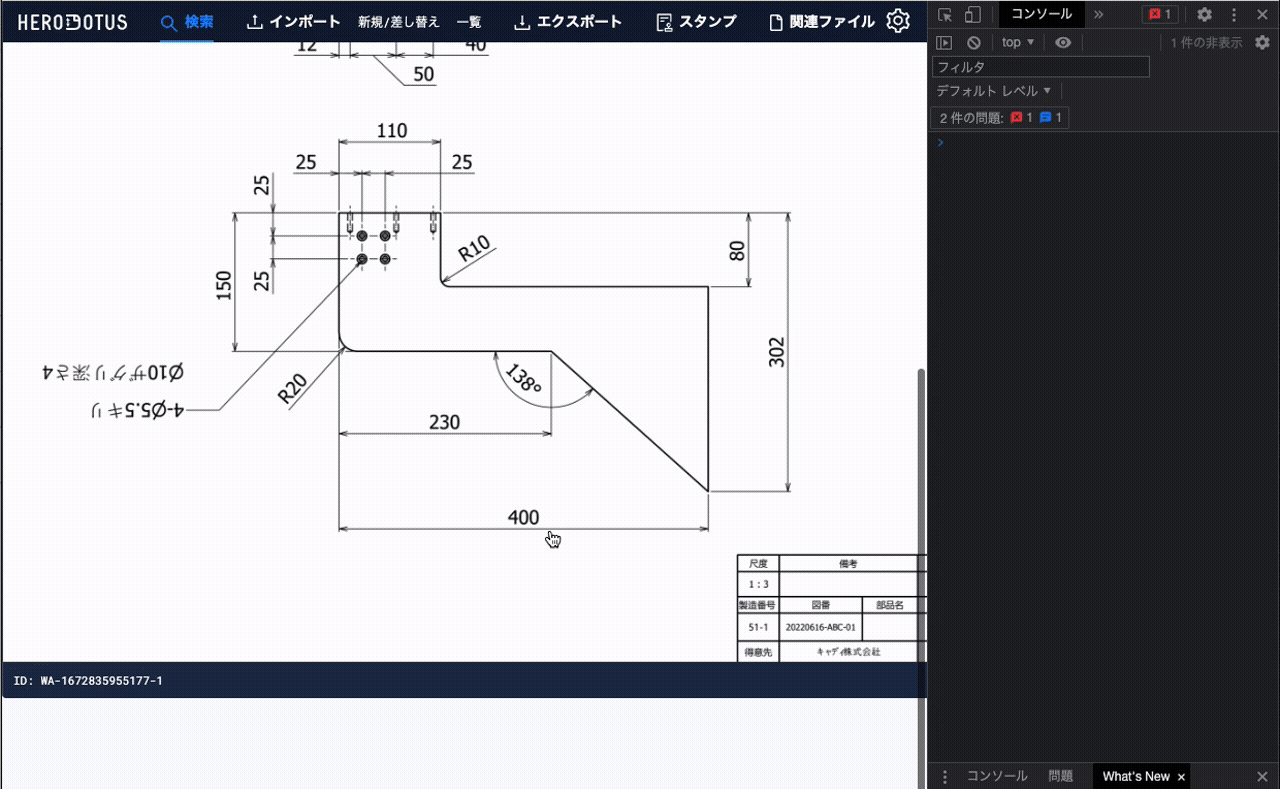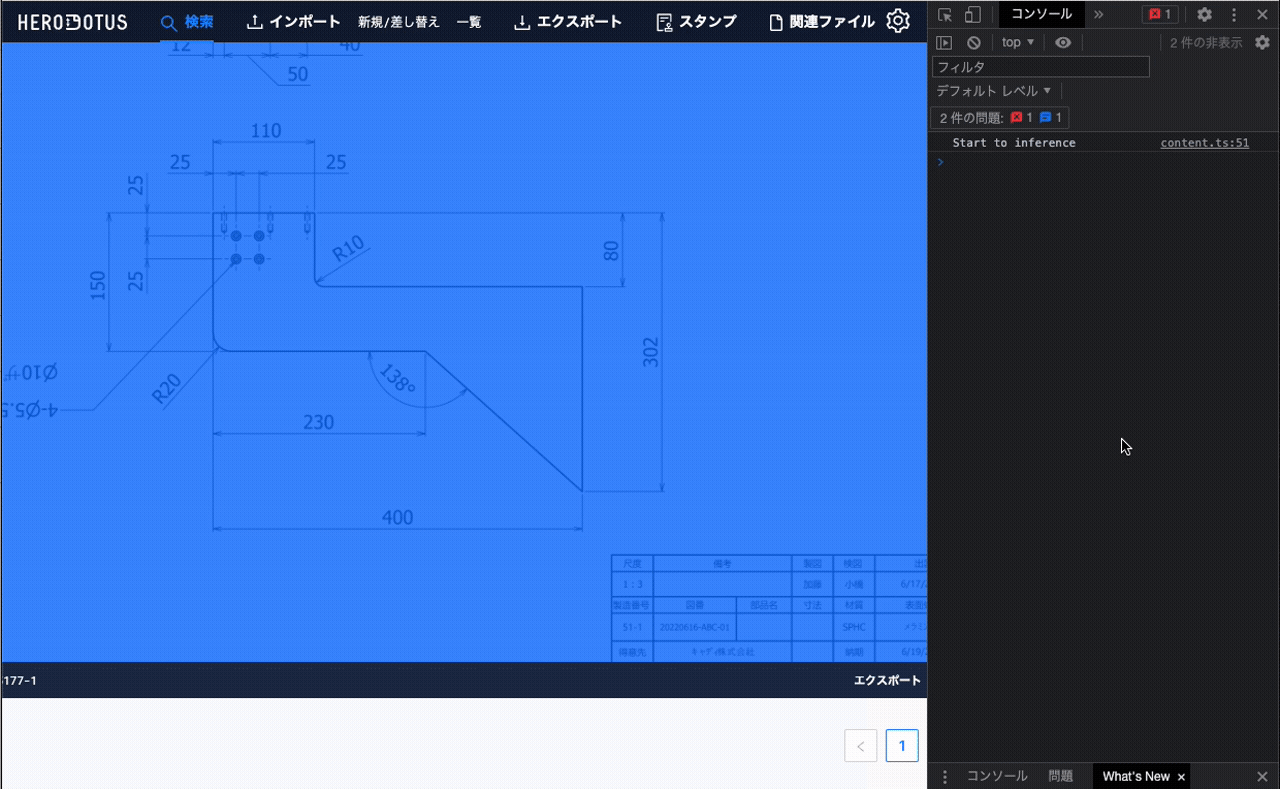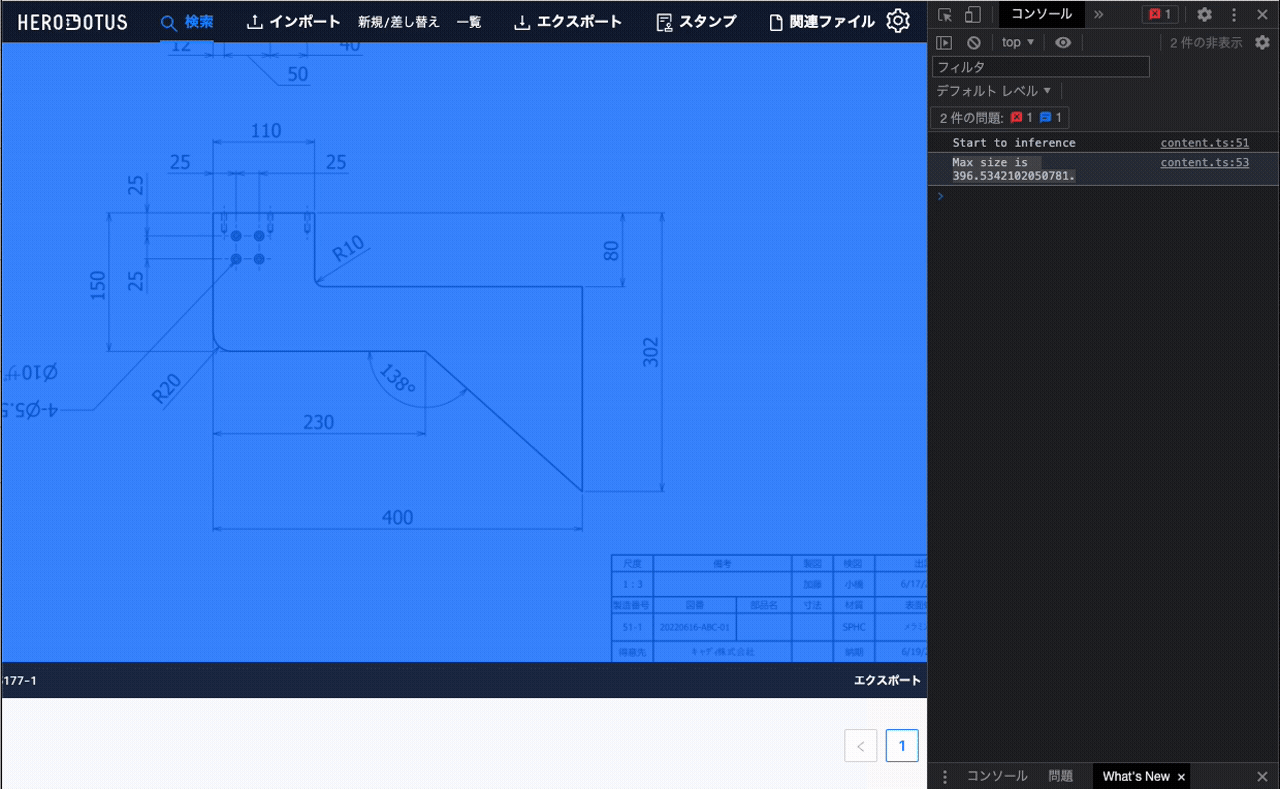
※1 … 最大寸法値推論モデルは、図面に記述された寸法値から、物体の大体の最大サイズを推論します。最大寸法値が直接図面に書かれていないような図面であっても推論可能です。
技術選定
ざっくり以下の技術を選択しました。MLモデルをONNX形式に変換し、それをTypeScriptでロードして実行します。 途中までは、MLモデルはONNXエクスポートしたものをRustでラップしWASMを使ってTypeScript側に関数提供する方法も考えたのですが、TypeScript側にONNXのランタイムが出ていたのでよりシンプルな構成にしました。
- MLモデル
- 学習: PyTorch
- 推論: ONNX
- Chrome Extension
- MLモデルのランタイム: onnxruntime-web
- 開発自体の言語・フレームワーク: typescript + webpack
実装
Chrome extensionのマニフェスト
Chrome extensionではマニフェストと呼ばれる定義ファイルを作成するのですが、今推奨されている書式は Manifest V3 と呼ばれる形式なので、それに則ります。Manifest V2は現在の予定だと2024年でdeprecatedになります(Manifest V2 support timeline) V2からV3の移行は比較的簡単にできるようです(Migrating to Manifest V3)。
まず、画像を右クリックした際に出てくるメニューに「AIで推論する」という項目を追加するため、Chromeのバックグランドで実行するスクリプトファイルが必要になります。
さらに、今回は図面画像管理Webサービスの中の画像を取得するため、特定のページの要素(<image>)にアクセスする権限が必要です。そのため、バックグランド実行とは別のコンテンツスクリプトを作成して、それぞれをマニフェストに登録する必要があります。
また、コンテンツスクリプトはMLモデルであるONNXファイルを実行時にロードします。図面管理画像WebサービスからこのONNXファイルにアクセスしても良いよ、という許可を与える必要があります。
manifest.jsonは以下のようになります
{
"name": "Some cool name",
"description": "very clear instructions.",
"version": "1.0.0",
"manifest_version": 3,
"action": {},
"background": {
"service_worker": "background.js"
},
"content_scripts": [
{
"matches": [
"https://example.com/*"
],
"js": [
"content.js"
]
}
],
"permissions": [
"activeTab",
"tabs",
"contextMenus",
"scripting"
],
"content_security_policy": {
"extension_pages": "script-src 'self'; object-src 'self'"
},
"web_accessible_resources": [
{
"matches": [
"https://example.com/*"
],
"resources": [
"model.onnx"
]
}
]
}
バックグラウンドでのメニュー画面追加
実装はTypeScriptで行います。 バックグラウンドで実行して欲しい内容としては、Chromeで画像を右クリックした際に「AIで推論する」というような内容をメニューに挿入することです。
また、メニューを選択した際は、コンテンツスクリプト側に何からの手段で該当の画像を送信する必要があります。このバックグラウンドとコンテンツの間のデータ送信はメッセージ機能で簡単に実現することができます。
chrome.runtime.onInstalled.addListener((): void => {
chrome.contextMenus.create({
id: "inference-cnn",
title: `AIの結果を見る`,
contexts: ["image"]
});
});
chrome.contextMenus.onClicked.addListener((info, tab): void => {
if (tab?.id && info.srcUrl) {
const message = { type: "inference-cnn", imageUrl: info.srcUrl };
chrome.tabs.sendMessage(tab.id, message);
}
});
推論処理
これもTypeScriptで記述します。このスクリプト内でやることは以下の通りです。
- バックグラウンドスクリプトから推論開始メッセージを受信する
- メッセージから画像のURLを取り出す
- 画像のURLから画像をロードする
- 画像をロードし終えたら、MLモデルに入力できるように前処理を行い、Tensor型にする
- MLモデルをロードする
- MLモデルのロードを終えたら、推論する
- 推論を終えたら、結果を出力する
XXXを終えたら、と書いてあるところは実際に処理の終了を待ってあげる必要があります。普段Pythonを書いていると非同期処理が出てきた際に一瞬ビクッとしますが(私だけかも)、直列に実行していくだけなのでシンプルにawaitすれば十分です。実際に記述するのはそこまで大変ではありません。
必要な画像の前処理は、グレースケール化とリサイズでした。どちらも画像ライブラリによって差異が大きく、その差分を吸収するのは大変なので結構雑に実装してしまいました。きちんとやるならば、実験時と同等の挙動を示すように前処理を実装する必要があります。
import { InferenceSession, Tensor } from "onnxruntime-web";
const asTensor = (image: HTMLImageElement): Tensor => {
const canvas = document.createElement('canvas');
canvas.width = image.width;
canvas.height = image.height;
const canvasContext = canvas.getContext('2d');
if (canvasContext != null) {
canvasContext.imageSmoothingEnabled = true;
canvasContext.imageSmoothingQuality = "low";
}
// 雑にリサイズして雑にグレースケールにする
canvasContext?.drawImage(image, 0, 0, 1024, 1024);
const imageData = canvasContext?.getImageData(0, 0, 1024, 1024);
const input = new Float32Array(1024 * 1024);
for (let i = 0; i < 1024 * 1024 * 4; i += 4) {
const r = imageData?.data[i] ?? 0;
const g = imageData?.data[i + 1] ?? 0;
const b = imageData?.data[i + 2] ?? 0;
input[i / 4] = (255 - (r + g + b) / 3) / 255.0;
}
const tensor = new Tensor('float32', input, [1, 1, 1024, 1024]);
return tensor;
}
const inference = async (tensor: Tensor): Promise<string> => {
// モデルの読み込み
const modelFilePath = chrome.runtime.getURL('model.onnx')
const session = await InferenceSession.create(modelFilePath, {
executionProviders: ["webgl"]
})
// 推論の実行
const feeds = { 'modelInput': tensor }
const outputMap = await session.run(feeds)
const outputData = outputMap.modelOutput.data;
return `${outputData[0]}`
}
const run = async (imageUrl: string) => {
const image = new Image();
image.crossOrigin = 'anonymous';
image.onload = () => {
const tensor = asTensor(image);
console.log("Start to inference...")
inference(tensor).then((inferenced) => {
console.log(`Max size is ${inferenced}.`)
});
};
image.src = imageUrl;
}
chrome.runtime.onMessage.addListener((message, sender, sendResponse): string => {
if (message.type == "inference-cnn") {
run(message.imageUrl).then(sendResponse);
return "OK";
}
return ""
})
ONNX
図面画像から最大寸法値を推論するMLモデルはPyTorch Lightningを使用して学習されています。そこで、モデル定義ファイルと重みファイルをダウンロードし、そこからONNXファイルへと変換します。変換にはPyTorch Lightningのonnx export関数を使用しました。実体はtorchのonnx export関数なので使い方は難しくありません。
ここで、Chrome extensionではONNXファイルのランタイムとしてonnxruntime-web を使用していますが、onnxruntime-webで動かせるONNXには制限がある、ということに気をつける必要があります。比較的新しめのモデルだと未対応の関数を使用していたり、またONNX変換時に最適化をしすぎたりするとonnxruntime-webで動かないことがあります。
また、PyTorchからONNXファイルを変換する際、重みの整数型がint64で出力されますが、onnxruntime-webで動かすためにはint32に変換しておく必要があります。変換にはこちらのonnx-typecastを参照させてもらいました。
誤差
画像の前処理を雑に書いたり、ONNX変換をしていたりするので、元の実験時とだいぶ違う挙動になるのかと思いましたが、意外にも誤差は十分に使用可能な範囲で小さく収まってくれました。
まとめ
onnxruntime-webやWASMのおかげでちょっとした開発をすればMLモデルをChrome extensionとして配布できることがわかりました。 とはいえ、APIによる提供に対して
- モデル更新のタイミングがユーザ依存になる
- ユーザのリソースで計算するため実行が安定しない
- どのモデルがどの程度ユーザに使用されているかが分からない
などの問題はあります。ぱっとお試しで価値検証をしてもらうには良いかもしれませんが、APIをなくせるほどではないなと思いました。銀の弾丸は存在しないので、適切なタイミングで適切な価値を提供できるよう精進していきたいものです。