はじめに
はじめまして、データ推進室データテクノロジーラボ部アーキグループ(以下アーキG)所属の舛谷(ますたに)です。これまでアーキGはAI・機械学習アプリケーションを稼働する環境をKubernetesで構築・運用・管理してきました。
Kubernetesクラスターを運用するにあたって、リソース・コストの最適化はみなさんも頭を悩ませることが多いと思います。アーキGも同様に、稼働するアプリケーションが増えていく中で効率的かつ安定的な環境を目指して改善を繰り返してきました。
今回は我々がこれまで取り組んできた改善について、特にリソースの効率化を実現するために行った施策についてご紹介させていただきます。現在アーキGがメインで利用してるマネージドサービスがAlibaba Cloud Continer Service for Kubernetes(以下ACK)であるため、Alibaba Cloudでしか実現できない内容も含まれますがご了承いただければと思います。
背景
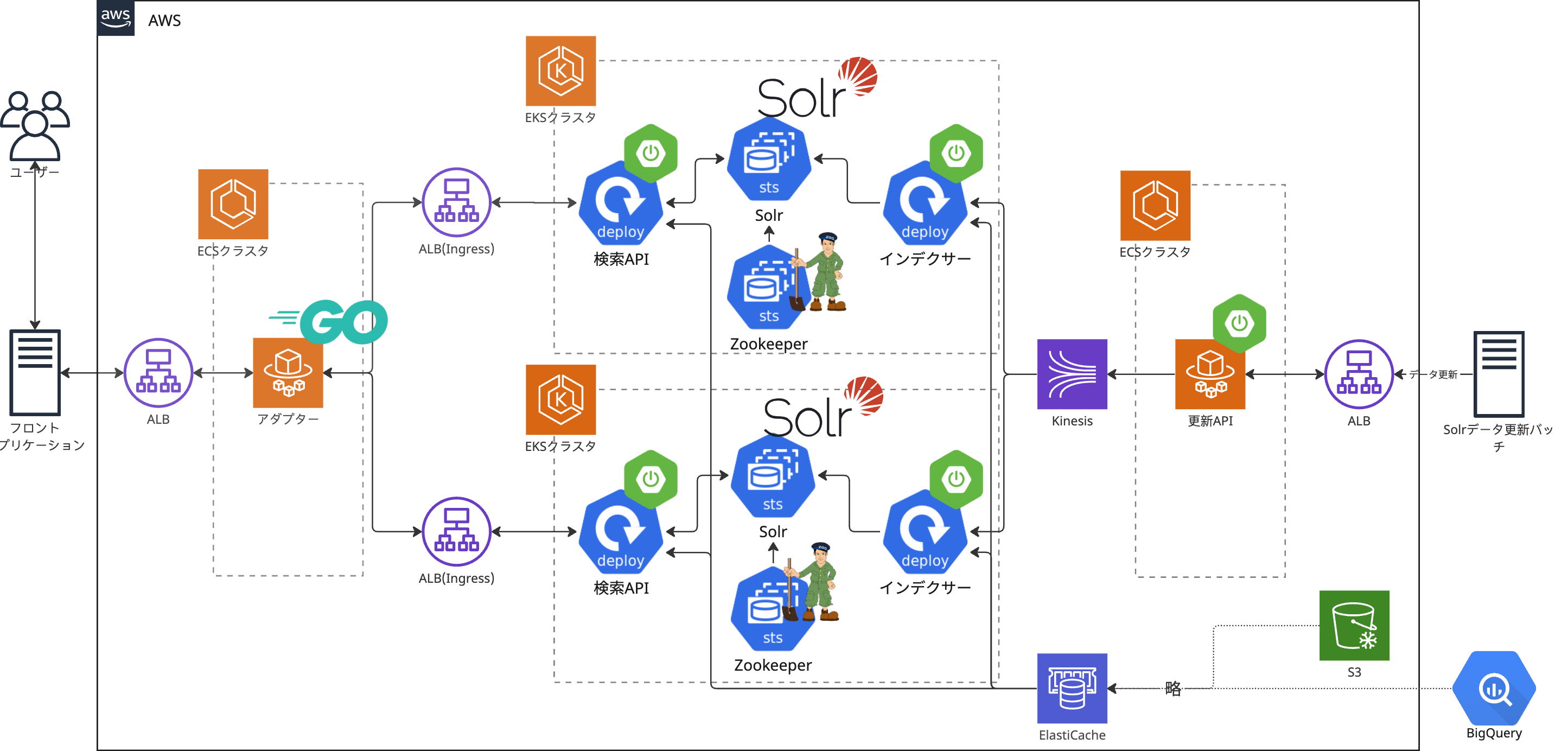
具体的な施策の紹介に入る前に、アーキGが管理するACKで稼働するアプリケーションと、それらをどういった点に気をつけて構築してきたかをご説明します。
データ推進室では「A3RT」と呼ばれるAI・機械学習を用いたAPIプロダクトを社内向けに提供しています。テキスト自動生成や、文章校閲、リスト生成などの機能をリクルートの事業システムに向けて提供しています。(詳細については
こちら
をご覧ください)
A3RTで提供されているプロダクトはCPU/MEMリソースを多く消費するものや、GPUが必要なもの、常駐処理やバッチ処理、月に一回実施される大規模バッチ処理など、用途や求められる性能が異なります。これらを均質的な構成のクラスターにデプロイした場合、一時的にリソースが足りずPodが立ち上がらない、逆にリソースをめちゃくちゃ余らしてる時間がある、スパイクに対してスケールアウトが間に合わないなど様々な問題に直面します。
アーキGではこういった問題を解決するために活動をしてきたというわけです。
Kubernetesクラスターリソース効率化施策
ここから本題です。A3RTをACKで効率よく運用するために行っている工夫について以下のトピックでご紹介していきます。
- ワーカーノード戦略
アプリの用途に合わせた複数のタイプのワーカーノードを用意し運用する戦略について - リソース効率化
過剰にリソースを消費しないように、Alibaba Cloudの提供する機能を活用して最適化した手法について - Podスケジュール高速化
アプリの安定性を高めるためのスケジュール高速化をAlibaba Cloudの提供する機能を活用して実現した手法について
ワーカーノード戦略
用途に合わせてノードを用意する。
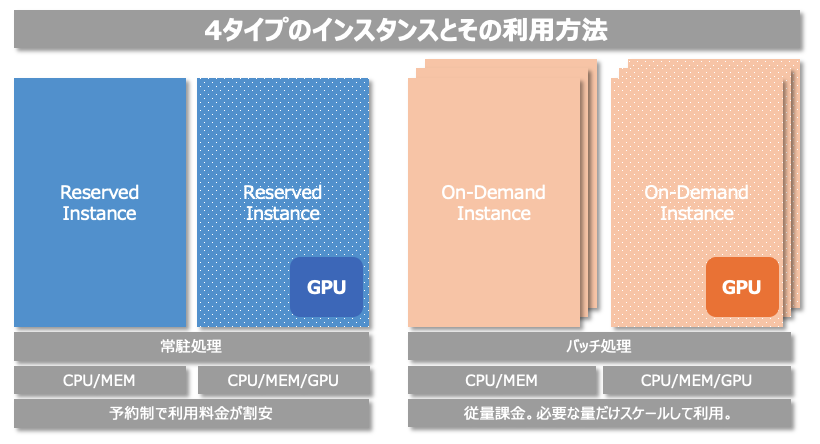
我々の環境では大きく分けて以下の4つの用途別にワーカーノードを用意して運用しています。
- 常駐処理 × CPU
- 常駐処理 × GPU
- バッチ処理 × CPU
- バッチ処理 × GPU
常駐処理は24/365で稼働し続けるので、時間あたりの料金ができる限り安くなることが望ましいです。一方バッチ処理は動いている時間だけ必要量のノードも動いていれば問題がなく、それ以外の時間は停止していることでコストを最低限に抑えることができます。そのために常駐処理用にはReserved(予約)インスタンスを購入し、ワーカーノードとして利用しています。一方バッチ処理用には従量課金のインスタンスを利用し、AutoScaling機能を活用することで必要な時にインスタンスを増強し、ジョブが完了したらスケールインする構成にしています。 またGPUを必要とするプロダクトも存在するため、GPUを搭載した常駐用、バッチ用の計4種類のノードを組み合わせてクラスターを構成しています。

ノードを使い分ける。
ノードを用意したら、今度はPodが適切にスケジュールされるように制御する必要があります。ノードのLabel/TaintとPodのAffinity/Torelationを利用しています。 事前にNodeには用途を識別できるラベルと、想定外のPodのスケジュールを防ぐTaintを付与しておきます。
| # | Nodeの種類 | Label | Taint |
|---|---|---|---|
| 1 | 常駐処理 × CPU | instance_type: reserved | n/a |
| 2 | 常駐処理 × GPU | instance_type: reserved | gpu=true:NoSchedule |
| 3 | バッチ処理 × CPU | instance_type: ondemand | n/a |
| 4 | バッチ処理 × GPU | instance_type: ondemand | gpu=true:NoSchedule |
これにより、上記4つの用途のノードを完全に使い分けることが可能になります。以下に常駐処理 × GPUのノードを必要とするDeploymentの設定例を記載しておきます。
apiVersion: apps/v1
kind: Deployment
<--- 一部省略 --->
template:
spec:
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- preference:
matchExpressions:
- key: instance_type
operator: In
values:
- reserved # 常駐処理のためReservedインスタンスにスケジュールされる様に設定。
weight: 1
containers:
<--- 一部省略 --->
resources:
limits:
cpu: 2500m
memory: 6Gi
nvidia.com/gpu: "1" # GPUをリクエストすることでGPU搭載のノードにスケジュールされる。
<--- 一部省略 --->
tolerations: # GPU不要のPodがスケジュールされないように付けたTaintを許容するよう設定。
- effect: NoSchedule
key: gpu
operator: Equal
value: "true"

リソース効率化(Alibaba Cloud向け)
cGPUの利用
AlibabaCloudが提供する GPU仮想化・共有技術 です。 1つのGPUを複数コンテナから利用する際のスケジューリング・分割ができるイメージです。
背景と課題
例えば画像判別などにおいて、GPUを用いた処理も行っています。これらの処理も、同じクラスタ内にGPUが利用できるノードプールを用意し、そのノードプールを利用するようにアプリケーションをデプロイすることで運用していました。 具体的には、manifest内のresourceで、GPUをリクエストすることで実現しています。 podごとに1GPUコア以上を割り当てる場合は問題ないですが、リクエストに波があったり、そこまでリクエストが多くない場合、GPUリソースの遊びができてしまいリソース効率が下がってしまいます。 なるべくリソース効率を高めるために、GPUリソースが利用されていない時間帯を減らす必要がありました。 また、マルチGPUでないインスタンスタイプを利用した場合、GPUのリクエストが増えるとその分インスタンスも起動されることになり、結果的にGPU以外のリソースも無駄に消費(アイドル状態)されている状態でした。
解決方法
Alibaba Cloudを利用していたため、cGPUを利用して実現することにしました。 GKEであれば、 タイムシェアリングGPU などで実現できるのかもしれません。(未検証です)
ノードプールのノードには、 ドキュメント に基づいて以下のラベルを設定しています。
| key | value | 説明 |
|---|---|---|
| ack.node.gpu.schedule | cgpu | GPUメモリ分離を有効化 |
| ack.node.gpu.placement | binpack | 使用率の高いGPUへ優先してPodを割り当てる |
GPUメモリは完全分離し、アプリケーションの実行に必要なメモリが確実に割り当たるようにしています。 また、リソース効率化を目的としているため、なるべく使用率の高いGPUに優先して割り当てて、全体として利用するGPU数を減少させることを狙っています。
計算能力については、 native scheduling を採用し、nvidiaドライバーによって割当を行っています。
manifestでは以下のように設定します。
# before(通常通りGPUを、1個まるごと要求する場合)
resources:
requests:
memory: 3Gi
cpu: 1000m
limits:
memory: 6Gi
cpu: 1000m
nvidia.com/gpu: 1 # 1GPUを要求
# after(cGPUを用いて、分割されたGPUを要求する場合)
resources:
requests:
memory: 3Gi
cpu: 1000m
limits:
memory: 6Gi
cpu: 1000m
aliyun.com/gpu-mem: 2 # GPUメモリを2GB要求(GPUコアは共有)
仮に複数GPUを利用する場合だとこのように記述しています。
spec:
template:
metadata:
labels:
aliyun.com/gpu-count: "2" # 2GPUを要求
resources:
limits:
aliyun.com/gpu-mem: 4 #トータルで使えるGPUmemory。この場合だと、4/2で、1GPUあたり2GB確保
結果
結論としては、要求性能を満たしたまま、ノード集約が可能となり、リソース削減できました。 GPUを共有することでもアプリケーションは期待した性能を満たすことができ、またデプロイするノードを集約することができました。 nvidia_smiで確認すると、メモリが分割されていることが確認できます。
通常通りGPUが割り当てられた場合

GPUを分割して共有した場合

更にGPUメモリを分割することで、アプリケーションがエラーとなりました。正しく(?)GPUメモリを少なく認識しています。
Traceback (most recent call last):
File "/opt/image_processing/car_type/api/app_car_type.py", line 184, in <module>
CLASS_LABELS_FILE, IMAGE_DIM, GPU_MODE, logger)
File "/opt/image_processing/car_type/api/car_type_caffe.py", line 21, in __init__
param = torch.load(pretrained_model_file)
File "/usr/local/lib/python3.6/dist-packages/torch/serialization.py", line 595, in load
return _legacy_load(opened_file, map_location, pickle_module, **pickle_load_args)
File "/usr/local/lib/python3.6/dist-packages/torch/serialization.py", line 774, in _legacy_load
result = unpickler.load()
File "/usr/local/lib/python3.6/dist-packages/torch/serialization.py", line 730, in persistent_load
deserialized_objects[root_key] = restore_location(obj, location)
File "/usr/local/lib/python3.6/dist-packages/torch/serialization.py", line 175, in default_restore_location
result = fn(storage, location)
File "/usr/local/lib/python3.6/dist-packages/torch/serialization.py", line 155, in _cuda_deserialize
return storage_type(obj.size())
File "/usr/local/lib/python3.6/dist-packages/torch/cuda/__init__.py", line 462, in _lazy_new
return super(_CudaBase, cls).__new__(cls, *args, **kwargs)
RuntimeError: CUDA out of memory. Tried to allocate 144.00 MiB (GPU 0; 1.05 GiB total capacity; 8.90 MiB already allocated; 120.00 MiB free; 22.00 MiB reserved in total by PyTorch)
上記の通り、複数コンテナでGPUリソースをシェアすることで、確保するGPUリソースを削減し、リソース効率アップ・コスト削減を実現しています。
仮想ノードを利用したサーバレス化
AlibabaCloudが提供するマネージドKubernetesサービスであるAlibaba Cloud Container Service for Kubernetes(以下ACK)では、クラスター内に仮想ノードを追加できます。これにより、Alibaba Cloud Elastic Container Instance(以下ECI)とKubernetesを接続し、より効率的なPodのスケジューリングを可能にします。仮想ノードとECIの詳細については こちら から。 これによって以下の問題が解決しました。
-
ノードリソースの最適化
ECIにはPodの要求によって必要な分だけのリソースが割り当てられます。仮想サーバインスタンスによって構成されるノードを利用する場合、Podは要求するリソースに対して、十分なリソースを持ったノードにスケジュールされますが、このときノードのリソースを使いきれず、余剰分にまで課金が発生しているというケースはよくあると思います。ECIではPodの要求に必要な分だけリソースを割り当ててくれるのでリソースの最適化が可能となります。
-
オートスケールの高速化と要求リソースの削減
ECIはサーバレスコンテナであり、スケールアウトが仮想サーバのそれと比較し非常に高速です。これにより、Podのスケールアウトに伴うサーバのスケールアウトによるオーバーヘッドを無視できるようになりました。また仮想ノードのコンテナイメージをキャッシュすることができるのでPodの再作成時にもイメージプルにかかる時間が大幅に短縮しました。結果として負荷が高まった時にすぐにスケールアウトできる余裕ができたため、Pod1台が要求するリソースを削減することができました。 具体的にどのくらい高速化するのかはケースによって異なりますが、我々のアプリケーションではスケールにかかる時間が約1分30秒から10秒弱まで短縮することができました。これによって、Podの要求するCPUもおおよそ50%削減することができました。
Podスケジュール高速化
前の項目でも少し触れましたが、Podの立ち上がりを高速化することによってPodに持たせるリソースを小さくできるなど良い副作用を得られる場合があるので意外に重要です。ここでは高速化に寄与する2つの技術を紹介します。
加速イメージの利用
Alibaba Container Registry(以下ACR)には加速イメージという機能があります。これはPodの立ち上がりを短縮するために提供されています。詳細については こちら をご覧ください。 この機能によって、公称値では最大90%の起動時間削減が可能とありますが、我々のユースケースだと約150秒かかっていた立ち上がりが2秒に短縮されたこともあり、なかなか侮れない機能です。
Swiftサーバ
Swiftサーバは一度作成された後、スケールインによって停止されても削除まではされないというインスタンスになります。これにより、スケールアウト時に一からインスタンスを立て直すよりも高速にインスタンスの用意が完了します。Swiftモードのノードを利用することでPodのスケールアウトに伴って発生するノードのスケーリングも高速になり、結果的にPodの立ち上がりまでの合計時間が短縮できることになります。一点注意点としては、Swiftモードのインスタンスは停止後も削除されないため、停止時にもディスク分の料金がかかります。
今後
ここまで我々のKubernetesの運用方法についてご紹介させていただきましたが、今後は以下のようなことにも取り組んでいく予定です!
- 仮想ノードでGPUを利用したバッチ処理を実装
- 仮想ノードで構築したアプリの監視を実装(サードパーティ製品のサポート待ちみたいな部分はありますが)
- CronJobの実行監視実装
紹介させていただいた手法もまだまだ改善の余地があるものも多く今後も進化し続けると思うのでまたノウハウが溜まってきたらこちらで共有させていただければと思います。
ここまで読んでいただきありがとうございました。本記事は以上です。

クラウドエンジニア
舛谷友一
2022年9月リクルート入社。DTL部アーキG所属。趣味はコーヒー。晩飯に炭水化物を抜き中。

アーキG グループマネージャー
松田徹也
自信を持って趣味だと宣言できるレベルの趣味を探したい!
この記事をシェア