
はじめに
株式会社 WinTicket でネイティブアプリエンジニアをしている長田卓馬(@ostk0069)です。
本記事は 12/7 に行われた社内イベント 「CA BASE CAMP 2022」で登壇した資料を記事に起こしたものです。「CA BASE CAMP」は、サイバーエージェントのエンジニア・クリエイターに向けたカンファレンスで、2018 年に第 1 回が開催され、今回で 4 回目を迎えます。
目次
1. SRE for Mobile って?
まず、 SRE とは Site Reliability Engineering の略で Google 社が提唱したものです。サービス運用の方法論であり、スケーラブルで信頼性の高いソフトフェアシステムを構築することを指します。
モバイルアプリ開発は考えなければならない要素がたくさんあります。それが下記のスライドの項目になります。

SRE for Mobile では SRE の考えに加えて、モバイルアプリ特有の要素を考慮する必要があります。WINTICKET ではアプリチーム内に SRE チームを誕生させ、モバイルアプリの信頼性や開発体験の向上を目的に動いています。
2. SRE チームを作った経緯
SRE チームを誕生させたのには理由が 2 つあります。
- Flutter での Android/iOS アプリのリプレースによる障害を最小限に抑えるため
- Android/iOS アプリのリプレース後にアプリの信頼性を向上させるため
前者の「Flutter での Android/iOS アプリのリプレースによる障害を最小限に抑えるため」に関しては、以下をご覧ください。
- Flutter リプレースの難易度と取り組んだこと | CA BASE NEXT – CyberAgent Developer Conference by Next Generations
- WINTICKET アプリ Flutter リプレース戦略 | CyberAgent Developers Blog
この記事では後者の「Android/iOS アプリのリプレース後にアプリの信頼性を向上させるため」について紹介します。
リプレース後にて、以下の問題点を抱えていました。
- main ブランチの安定性が低く、リリースの直前になって不具合に気付く
- リリース時の不備による障害の発生
- 影響が不明な内部エラーが大量に存在している
これらをどのように改善していったのか紹介します。
3. 何を、どのように改善するか
はじめに、DevOps のフローに沿ってどのように改善できるかを考えてみました。DevOps とは、「開発(Development)」と「運用(Operations)」を組み合わせた造語です。「開発担当と運用担当が緊密に連携して、柔軟かつスピーディーにシステム開発を行う手法」を意味します。
開発プロセスをリリース前後で分割し、信頼性に関する既存の問題に対してどのようなアプローチがあるのかを考えました。
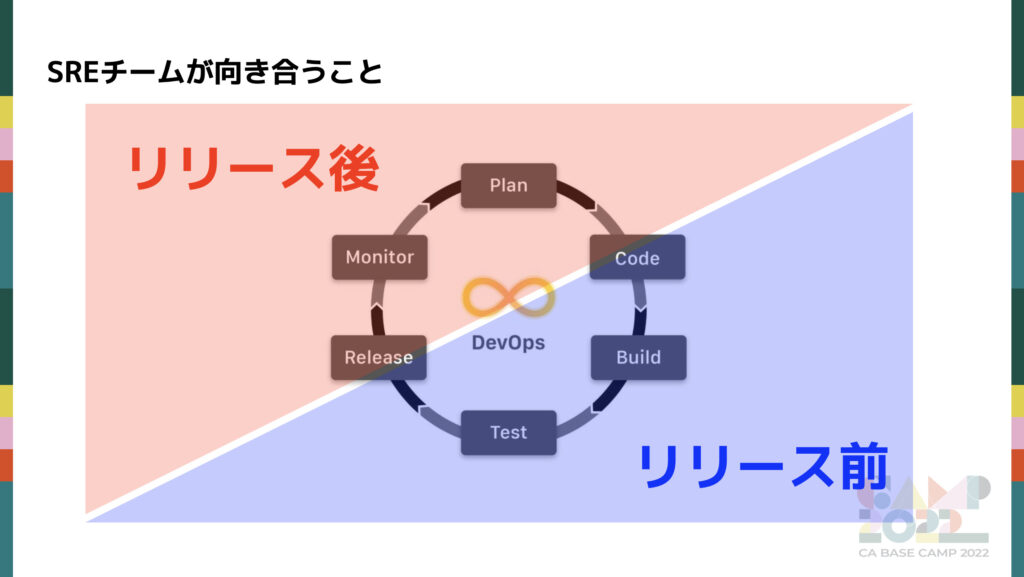
その中でSREチームとして取り組んだ箇所は以下になります。次のセクション以降でそれぞれの取り組みを紹介します。

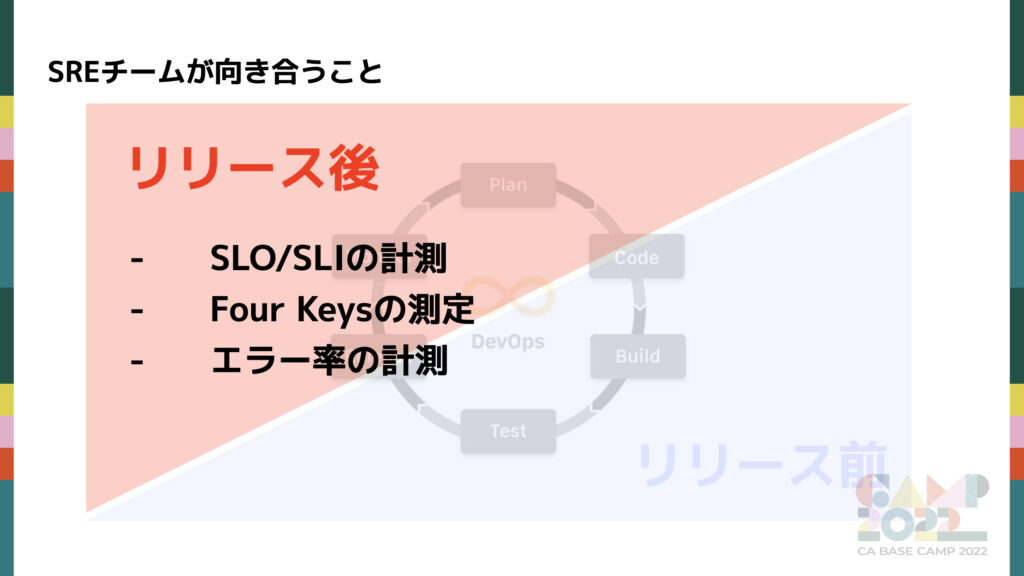
※エラー率: 1 セッションあたりのエラー発生率。
リリース前
リリース前は main ブランチの安定性とリリースによる故障率の改善に取り組みを行いました。

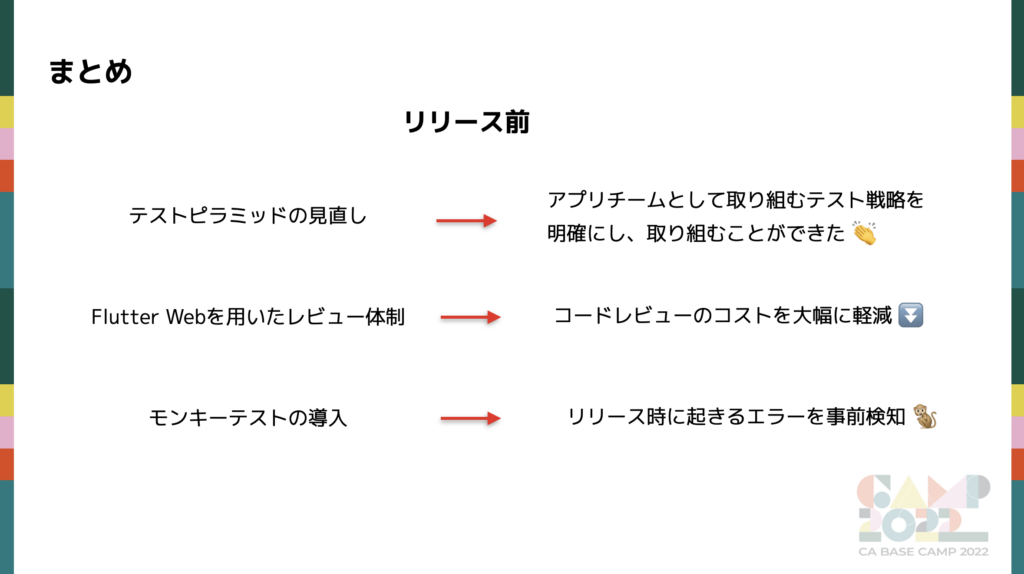
テストピラミッドの見直し
DevOps の Test に当たる箇所の改善。
既存のテスト戦略を見直すことでアプリケーションのデグレをより検知できる体制を作り、リリースによる故障率の改善に繋げる。
Flutter Web を用いたレビュー体制
DevOps の Code に当たる箇所の改善。
コードレビューのしやすさを強化し、 main ブランチの安定性に繋げる。
モンキーテストの導入
DevOps の Test に当たる箇所の改善。
検知が難しい潜在的なエラーを検知を可能にすることでリリースによる故障率の改善に繋げる。
テストピラミッドの見直し
左が理想の状態。右が当時のアプリチームの状態です。
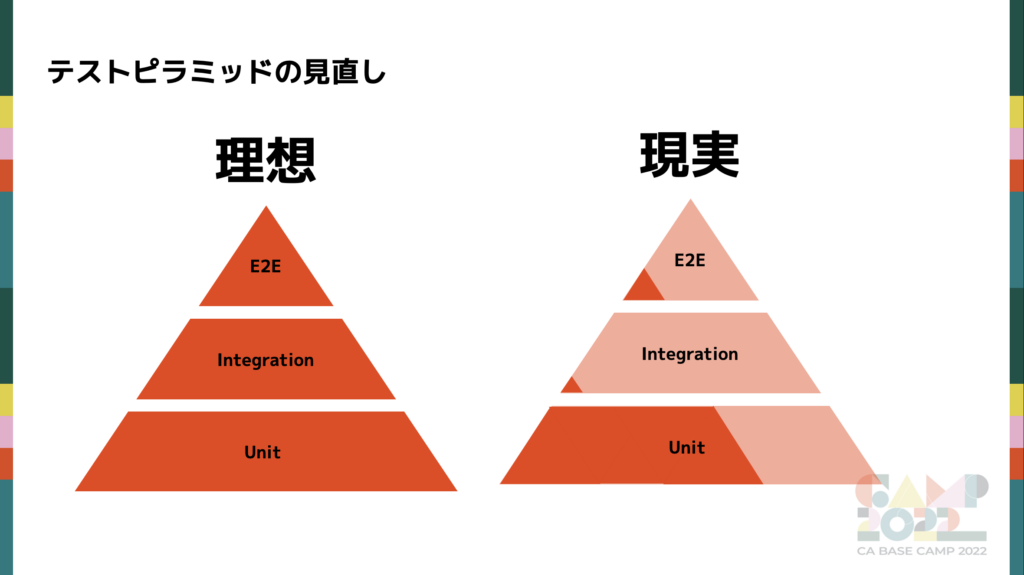
テストピラミッドとは Unit Test、Integration Test、End to End Test(以後、E2E Test)の3つをピラミッド状にしたものです。上に行くほどテストで担保できる要素が増えますが、メンテナンスコストと実行時間が増加します。
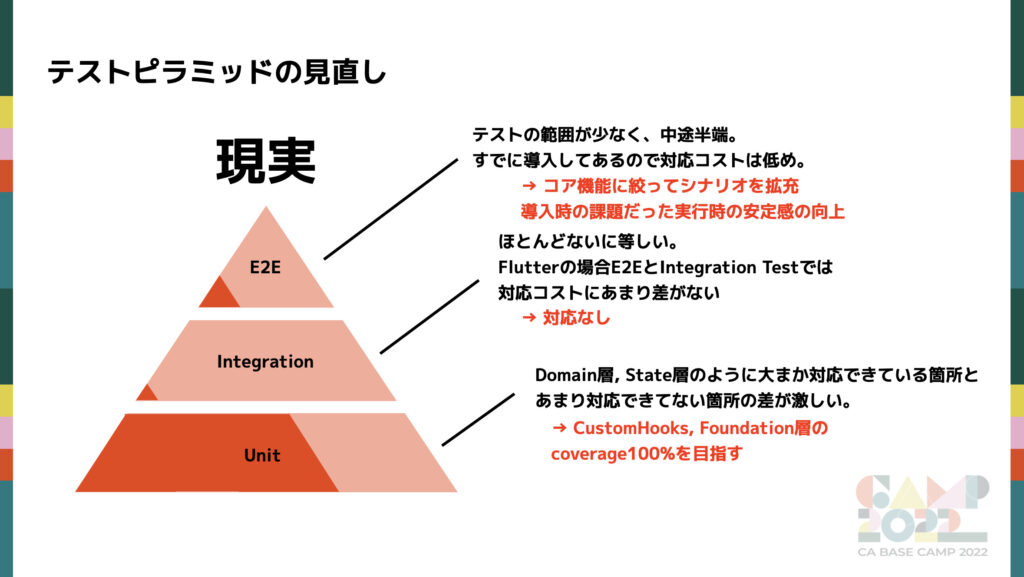
3 つのテストについて細かく見ていきます。
Unit Test
Unit Test は、クラスやメソッド単体の小さい範囲で機能の動作確認を行う手法です。実際の Unit Test の Test Coverage が下記になります。
- Test Coverage:
- Domain: 94.1%
- State: 77.1%
- CustomHooks, Foundation(Util や Extension などの汎用ロジック): 47.4%
- UI: 22.0%
- 課題: Domain 層や State 層に対して、 CustomHooks や Foundation が書けていない。いずれもアプリの大事なロジックが多くある箇所。
- 対策: CustomHooks や Foundation での Test Coverage の向上に努める
UI 層 の Test Coverage が低いのは、Unit Test ではなく Visual Regression Testing によって担保しているためです。Visual Regression Testing は、Widget の状態ごとにスクリーンショットを撮影し、Pull Request ごとに行う回帰テストのことです。チームのコーディングルールで、 Widget ファイルとその Widget の各状態を表示する story ファイルを 1 対 1 で作成することを徹底しており、ほぼすべての Widget の Visual Regression Testing を行っています。
Integration Test
Integration Test は、複数のモジュールを結合させモジュールを跨いだ動作検証を行う手法です。E2E Test との違いは Database や API のアクセスはモック化されている点や 1 つのテストケースで担保する領域が限定されることにあります。
- Test Coverage: 0-5% (計測できないので参考程度の数値です)
- 課題: なし。Test Coverage は低いが E2E Test を強化することでカバーする。
- 対策: なし
E2E Test
E2E Test は、ユーザーのタスクやプロセスの種類を問わずデータフローが適切に機能することを確認する手法です。
- Test Coverage: 10-20% (計測できないので参考程度の数値です)
- 課題: 導入自体はしているもののシナリオ数が少なく、うまくテストとしての効果を発揮できていない状態
- 対策: コア機能に絞った E2E のシナリオの拡充、実行時の安定面の向上
E2E Test の詳細
E2E Test についてより深ぼった説明をします。
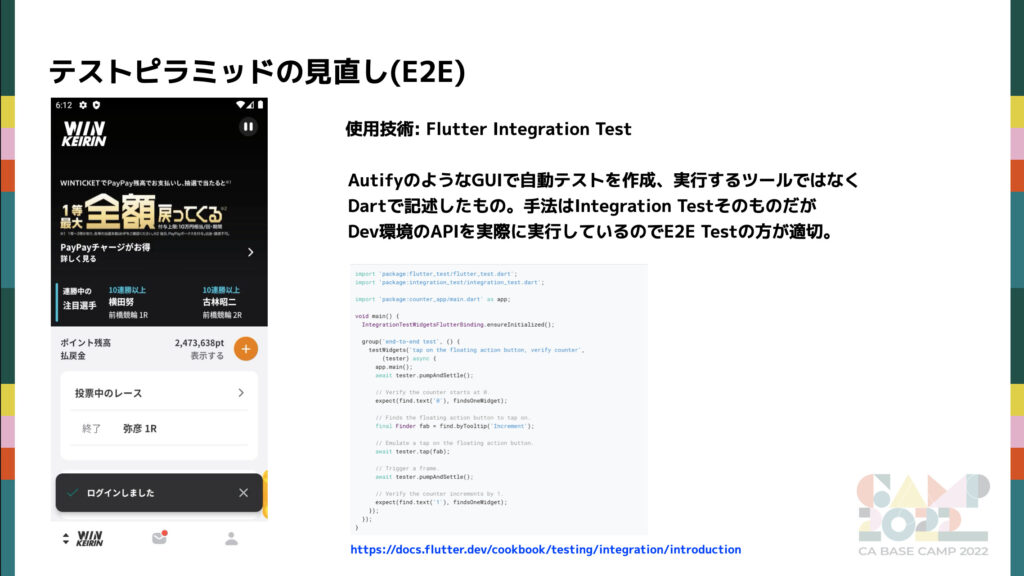
E2E Test と聞くと Autify のような GUI でテストシナリオを生成できる自動テストツールをイメージする方もいるかもしれません。Flutter Integration Test は上の画像のように コードベースで各ステップを記述します。下記が実行のサンプルの動画です。
動画では問題なく動いている E2E Test ですが様々な問題を抱えていました。課題とその対策をまとめて紹介します。

シナリオ数が少なく中途半端
認証、投票、会員登録などのコア機能に絞ってシナリオを9つに増やしました。今後も費用対効果が高いシナリオから順次増やしていきたいと考えています。
E2E Test を書くコストが高い
E2E Test のコードの作成において、デザインパターンの Robot パターンを導入しました。Robot パターンにより、UI 操作や検証ロジックと、テスト対象要素の情報を分離できるため、再利用性と保守性が向上しました。また、E2E Test のコードを書く際に、fzyzcjy/flutter_convenient_test を参考に Sandbox 環境を準備し、Hot Restart を可能にして、開発体験を向上させました。
CI での実行が安定しない
CI 実行の具体的な問題としては以下のものがありました。
- Emulator の立ち上げが CI 上だと安定しない
- Emulator のスペックが低く、重たい処理の動作が安定しない
そのため、様々なツールを調査し、Firebase Test Lab に完全に移行しました。
Flutter Web を用いたレビュー体制
アプリチームでは、iOS/Android のアプリを Flutter Web としてデプロイし、Web アプリとして利用しています。主な用途は、コードレビュー時にビルドをすることなくアプリの動作を簡易的に確認できるプレビュー環境として利用しています。
Dev 環境の実行動画がこちらです。
導入することで以下のような場面で活躍しています。
- コードレビュー時の UI の確認
- コードレビュー時の動作確認
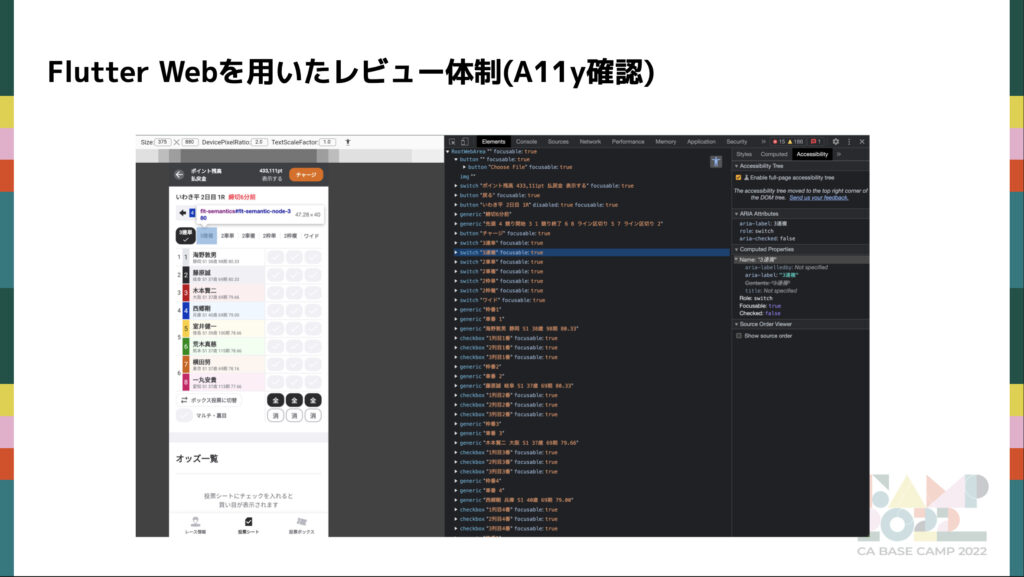
- アクセシビリティの確認
- Google Tag Manager でのログ発火確認の簡略化
(「Google Tag Manager でのログ発火確認の簡略化」については詳細は省略します)
モンキーテストの導入

モンキーテストにはいろいろな手法がありますが、今回紹介するのは自動でランダムにタップやスクロール、入力するループテストです。Firebase Test Lab の Robo Test が近い存在としてあります。リリース時に数時間 Dev 環境で実施し、リリース前のチェックの限られた時間やリソースでは検知が難しい潜在的なエラーを検知できます。
Dev 環境の実行動画がこちらです。
リリース後
次にリリース後です。

いずれも DevOps の Monitoring の 改善になります。リリース後は課題への対策というよりも、今後アプリが良くなるためやアプリの現状を理解するための測定がメインになります。SLI/SLO は現在取り組んでいる段階なので詳細はスキップし、Four Keys の測定、エラー率の計測と改善について紹介します。
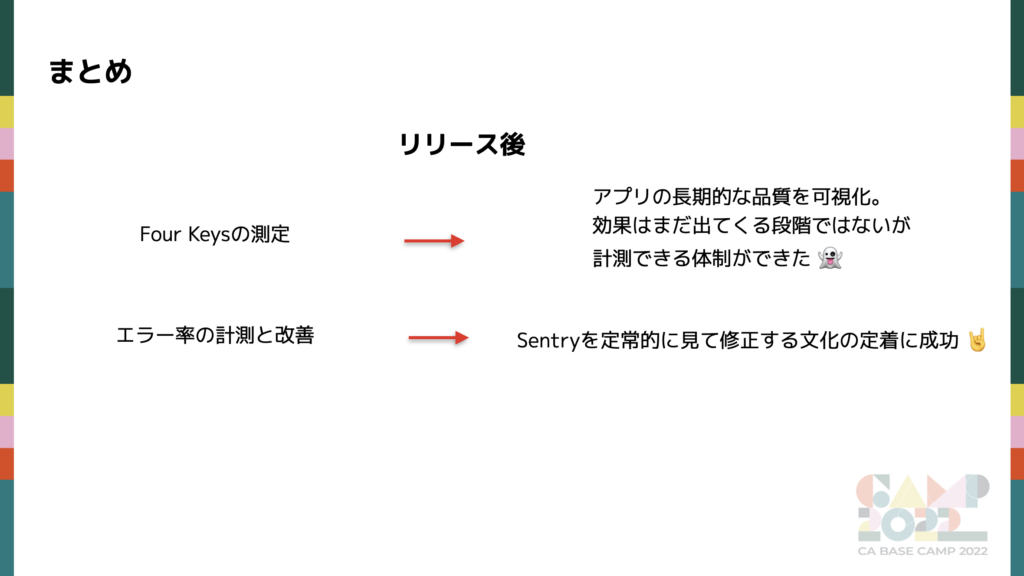
Four Keys の測定
Four Keys を紹介する前にアプリチームの現状と今後は以下のようにしていきたいと考えています。
- リリース頻度、変更リードタイムは現状維持
- 平均修復時間は SLI/SLO を決める際に制定
- 変更障害率を 5%に抑える

計測項目については、まずはミニマムで導入することを優先し、先行して変更障害率のみ計測しています。
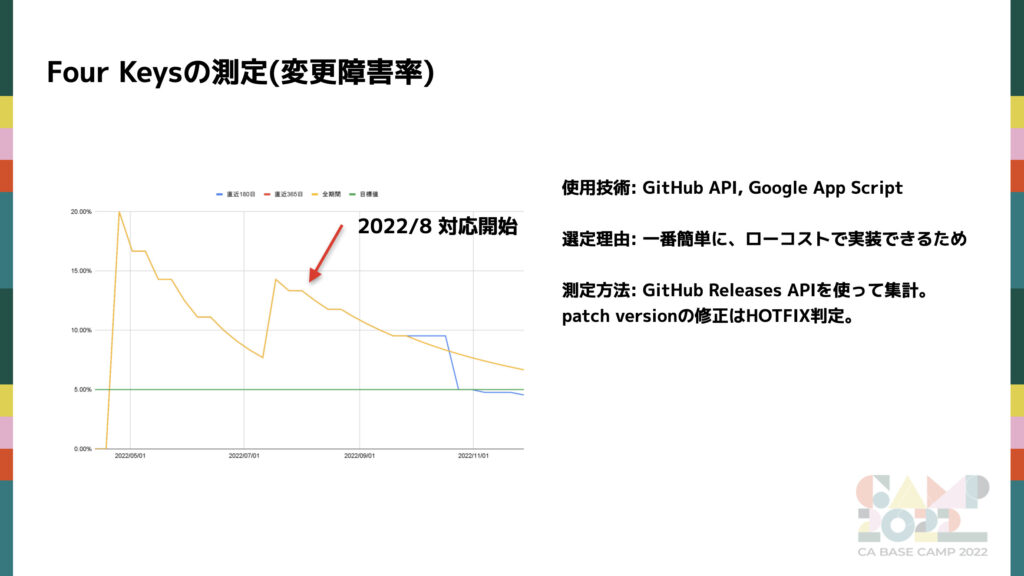
これが変更障害率のグラフです。
180 日、365 日、全期間別で集計しており、目標値の 5%を緑で表示しています。
測定方法に関しては、障害発生時に HOTFIX を行う場合に限り Patch Version を更新しており、障害の数を Patch Version のリリース数として算出し、全リリース数で割ることで障害率を算出しています。GitHub API からリリースの情報を取得し、 Google App Script を使って集計・可視化をしています。まずはミニマムで早く実践したかったのでこちらの技術を採用しました。
エラー率の測定と改善
エラーの解消は 2 つのことを行っています。
- ワークショップ形式でのエラー解消
- セッションあたりのエラー率(※)を可視化
※エラー率は、期間中のエラー件数をその期間のセッション数で割ったものです。サービスの特性上、大きなイベントの有無によって WAU が大きく変動することがあります。そのため、エラー件数だけで評価すると正確な評価ができない場合があるので、セッション数で割った値を使用してエラー率を算出しています。
改善をワークショップ形式で行い、また現状把握のために可視化も行なっています。
1. ワークショップ形式でのエラー解消

WINTICKET ではエラーレポーティングツールに Sentry を採用しています。
ワークショップは3つの流れで行なっています。
- 火曜日:ランダムにアサインされたチームメンバーが Sentry にログインし、ワークショップで解決する必要のあるエラーを GitHub の Issue として起票する
- 水曜日: ワークショップを実施。ワークショップは 90 分確保し、アプリチームの半分が週 1 で参加する。(隔週で参加)
以下が実際のワークショップの流れです。- 1. 作成された GitHub の Issue の中からアサインを決める
- 2. 個人で調査と解消の方針を決める
- 3. そのチームで調査内容や方針のお互いにレビューし合う
- 4. 最後に実装する必要があれば実装する
- 木曜日: 申請作業を行う。それに間に合うまでに含めるように実装対応を行う。
ワークショップ形式を採用する背景には以下があります。
- Sentry を使うことに慣れていないメンバーが多いので半強制的に使う機会を作る
- エラーへの対応力がメンバー間でばらつきがあったため、相互にレビューし合うことで対応力の底上げをする
- エラー対応は通常タスクと比べて優先度をどうしても低くしてしまう傾向があったので、定常的に時間を確保する
セッションあたりのエラー率を可視化
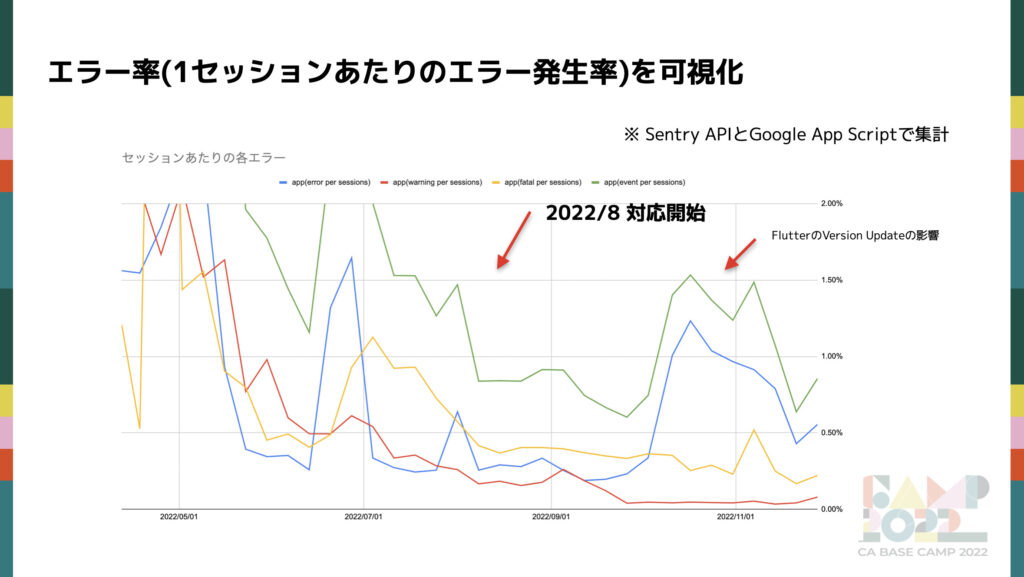
次に計測についてです。エラー解消による影響や解消すべきエラーの量などを知るために可視化は重要です。Sentry では週次で詳細に変化を見ることはできないので、 Sentry API と Google App Script で可視化しています。Fatal、Error、Warning のエラーレベルごとにまとめて計測しています。今までの推移を見てみると、明らかにワークショップを始めてからエラー率が低下しているのが分かります。一度 Flutter の Version 更新の影響で再び数値が上昇していますが、その後は減少しているためワークショップの成果が出ていることが分かります。
まとめ
リリース前
リリース前は具体的な品質担保のための対策を多く行いました。いずれも品質を担保する上で、今後大きく繋がってくると考えています。
リリース後
リリース後は主に計測です。計測することで自分達のアプリの立ち位置を把握し、振り返りや今後に繋げられたと考えています。
今後
紹介できなかった SLI/SLO はもちろんのこと、エラー解消のワークショップもチームに定着してきたので、より良い効果と効率を求めて見直していきたいと考えています。また、証明書や秘密鍵、トークンの管理などセキュリティの向上についても検討予定です。
WINTICKET の Flutter アプリは依存しているプラグインの数が多いため、その変更に強い体制作りも検討しています
